Abstract
새로운 오류 유형 분류 가이드라인을 사용해 한국어 문법 오류교정을 위한 Korean Neural Grammatical Correction Test set(K-NCT)라는 gold-standard test set를 제안
사실성과 신뢰성을 확보하기 위해 상용화 시스템과 인적 평가를 활용한 정략적 분석 수행
실험 결과, 제안한 문법 오류 수정 테스트셋이 균형 잡히고 다양하며 정확한 가이드라인을 가지고 있음을 입증
1. Introduction
제시된 오류 유형은 띄어쓰기, 문장부호, 숫자, spelling과 grammatical 오류로 크게 4가지
이는 다시 균형성, 다양성, 사실성과 관련된 23개의 하위 범주로 나뉨
언어 전문가 자문을 통한 인적 평가와 공개된 상용화 시스템을 통해 정성적 분석을 진행해서 사실성과 신뢰성을 확보
3. K-NCT
특정 유형만 포함된 pseudo-parrel 말뭉치를 쓰면 정확한 성능 측정 불가
K-NCT는 다양한 도메인, 방법론, 음절 수 등을 고려 100% 사람이 구축한 고품질 데이터셋
a. Considering the Balance
오류 유형, 음절 길이, 텍스트 스타일, 도메인이 균형 있게 포함되어 있음
띄어쓰기 500개, 구두점 500개, 숫자 오류 500개 공정하게 구성
맞춤법 및 문법 오류의 세부 오류 유형은 단일 언어 1312개, 다중 언어 200개, 맞춤법 800개, 구문 411개, 의미론 200개, 신조어 100개로 구성
b. Considering the Diversity
글쓰기, 말하기, 대화 스타일도 고려
여러 오차 유형을 통해 모델에서 어떤 오차 유형이 강세인지 약세인지 판단할 수 있음
c. Considering the factuality
사실성은 사람이 판단하기에 자연스럽거나 사실에 가까운 것이기 때문에 사람의 평가를 거침
오류 유형 분류는 크게 4가지(띄어쓰기, 구두점, 숫자, 맞춤법 및 문법 오류)를 기준으로 23개의 세부 오류 유형으로 분류
맞춤법 및 문법 오류는 1차 오류와 2차 오류로 구분해서 세부적으로 분석
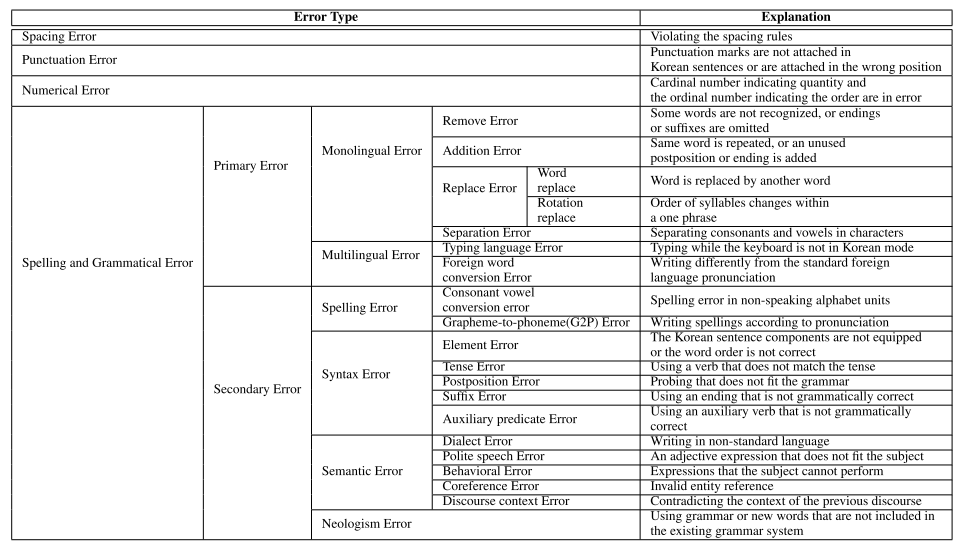
띄어쓰기 오류
타이핑 잘못이나 습관
구두점 오류
문장 안에 문장 부호가 첨가되지 않거나 잘못 배치되었을 때 발생
수치오류
기수가 수량을 나타내고 서수가 순서를 나타낼 때 발생. 예를 들어 "한 시 일 분"을 잘못 쓰면 "하나 시 일 분" 또는 "일시 일분"으로 표기
맞춤법 및 문법 오류
1차 오류로 분류하고 2차 오류를 하위 분류
- remove error: 일부 단어가 인식되지 않거나 끝이나 조사가 생략될 때 발생. 흔하게 저지르는 실수 중 하나
- addition error: 같은 단어가 반복되거나, 조사가 사용되지 않거나, 끝이 추가될 때 발생
- replace error: 다른 단어가 단어를 대체하는 단어 대체와, 한 구 내에서 음절 순서가 바뀌는 회전 대체로 세분화
- separation Error: 문자의 자음과 모음이 분리될 때 발생
- Typing language error: 안녕->dkssud
- Foreign word conversion error: 수프->스프
- consonant vowel conversion error(자음 모음 변환 오류): non-speaking 철자 오류, 이제 곧 갑니다->이제콘 갑니다
- Grapheme-to-phoneme error: 발음에 따라 철자 쓰는거, 이제콘 갑니다 -> 이제 곧 갑니다
- element error: 한국어 문장 요소가 단어 순서에 맞지 앟음. (주어, 목적어, 동사)가 정해져 있고, 목적어가 필요한 타동사가 있음
- tense error: 시제와 일치하지 않는 동사 사용
- postposition error: 문법에 맞지 않는 조사. 한국어는 응집 언어라 동사의 사용이 중요,
- suffix error: 맞지 않는 어미 사용
- auxiliary predicate error: 문법에 맞지 않는 조동사
- dialect error: 모델이 의도한 방언을 생성하지 못하면 오류로 판단, 저자의 의도를 오류 판단 기준
- polite speech error: 주제에 맞지 않는 정중한 말투
- behavioral error: 사과가 바나나를 먹는다와 같은 주체가 수행할 수 없는 것
- coreference error: 잘못된 엔티티 참조
- discourse context error: 이전 담화 맥락과 모순
- neologism error: 기존에 문법 체계에 없는 철자나 새로운 단어 사용. 방언과 마찬가지로 신조어 오류는 저자의 의도를 오류 판단 기준

d. Construction process
data selection
AI-hub의 한국어-영어 번역(병렬)말뭉치에서 추출
글쓰기, 말하기, 대화 스타일이 모두 포함된 파일로, 글쓰기 스타일은 격식있는 언어, 말하기와 대화는 비공식적이고 자연스러운 언어에 해당
쓰기, 대화, 말하기는 각각 80만개, 10만개, 40만개로 구성
세 언어 스타일에서 각각 1000개의 문장을 무작위로 추출해서 3000개의 문장으로 데이터셋 수집
Pre-processing
1. 음절의 신뢰성을 고려한 문장 정렬 수행
2. 띄어쓰기, 구두점, 숫자, 단일 언어, 다국어, 맞춤법, 구문, 의미, 신조 오류를 미리 정의된 비율에 따라 무작위로 태깅
Post-processing
오류 조건에 맞지 않는 올바른 문장을 대상으로 후처리 수행
Error Injection
정답 문장에 포함된 오류 유형은 3단계(데이터 선택, 전처리, 후처리)를 통해 정렬
오류 주입은 정답 문장에 정렬된 오류 유형을 포함한 오류 문장을 생성
주어진 문장과 오류 유형에 따라 오류 주입을 수행해 오류 문장을 생성
- 오류 유형을 정의하고 실제 예시 제시
- 인덱스의 음저 수를 수정해 자유도 제한
- 문장의 스타일 변경 제한
- 숫자 표현식은 문자를 제외한 통계 또는 날짜 표현식만 나타냄
- 맞춤법을 수정할 때는 키보드에서 두 개의 편집 거리 내에 있는 부분 사용
- 오류가 발생할 때 범위와 해당 오류 유형 나타냄
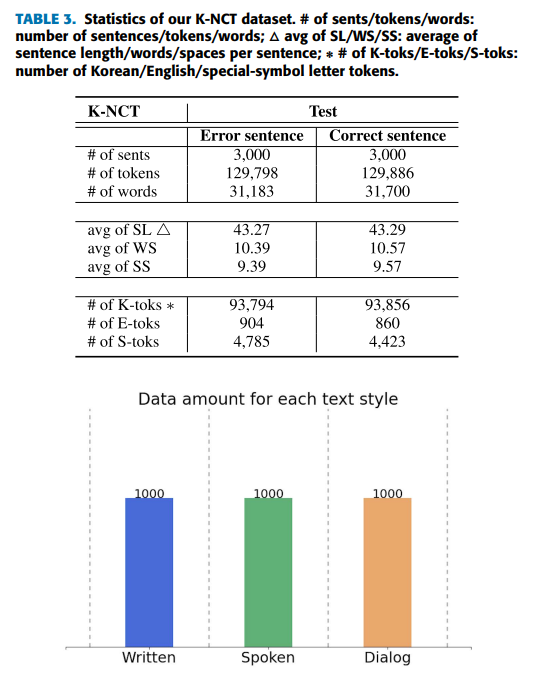
오류 문장의 평균 길이는 43.27, 평균 단어 수는 10.39, 평균 띄어쓰기 수는 9.39개, 정답 문장의 평균 길이는 43.29개, 평균 단어 수는 10.57, 평균 띄어 쓰기 수는 9.57
오류 문장에는 93,794개의 K-token, 904개의 E-token, 4,785개의 S-token이 포함
올바른 문장에는 93,56rodml K-token, 860개의 E-token, 4423개의 S-token이 포함
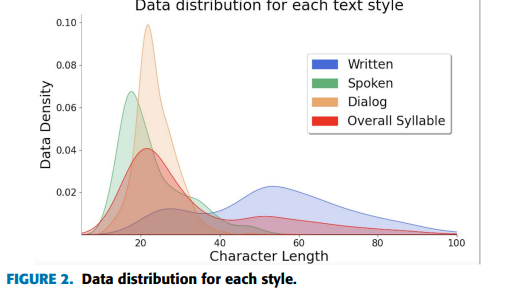
그림1과 그림2는 텍스트 스타일별 분포
그림1은 한국어 특성을 반영한 텍스트 스타일(글쓰기, 말하기, 대화)에 대한 데이터 양
각각 100개의 문장으로 구성
그림2는 음절 분포
글쓰기 스타일은 50~70음절, 말하기 스타일은 15~25음절, 대화 스타일은 20~30음절로 분포
K-NCT 모든 문장은 15~30 음절로 분포
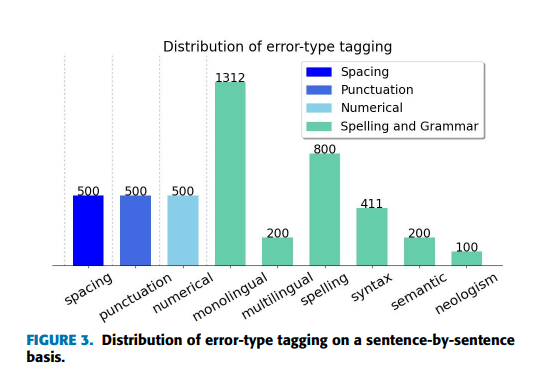
그림3은 오류 유형 태깅의 분포
세부 오류 유형에 대해 맞춤법 및 문법 오류는 1500개 문장에 태그를 지정하고, 나머지 유형은 각각 500개 문장에 태그를 지정
단일 언어 오류는 1312개 문장에 태그가 지정
철자 오류는 800개 문장, 다국어 및 의미 오류는 200개, 구문 오류는 411개, 신조어 오류는 100개
다양한 오류 유형이 균형있게 분포
Quantitative analysis
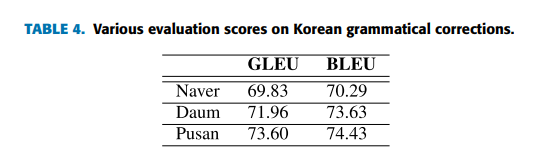
네이버, 다음, 부산 사용
딥러닝 기반 문법 교정 연구에서 평가 지표로 사용되는 BLEU, GLEU score로 측정
오류 유형 분류 기준에 따라 각 시스템의 강점과 약점 분석

가장 우수한 성능을 보이는 부산은 띄어쓰기에서 다른 모델에 비해 압도적으로 우수한 성능
구두점의 경우 다음 모델이 BLEU 69.16, GLEU 50.61
숫자의 경우 BLEU 기준으론 다음, GLEU기준으론 부산이지만 세 모델 모두 큰 차이는 없음
가장 중요한 성능인 맞춤법 및 문법의 경우 부산이 BLEU 75.07 GLEU 70.66으로 가장 우수
문장 쌍에 대한 오류 유형이 K-NCT로 레이블이 지정되어서 시스템에 대한 강점과 약점 분석 가능
