
Abstract
- Mistral 7B은 Llama2(13B)보다 모든 평가 벤치마크에서 능가했고 Llama1(34B)보다 reasoning, mathmatics, code generation 부분에서 능가
- 더 빠른 추론을 위해 grouped-guery attention(GQA)릃 활용하고, 추론 비용을 줄이면서 임의의 길이의 시퀀스를 효과적으로 처리하기 위해 sliding window attention(SWA)와 결합
1. Introduction
- Mistral은 효율적인 추론을 유지하면서도 높은 성능을 제공
- grouped-query attention(GQA)와 sliding window attention(SWA)를 활용
- GQA는 추론 속도를 향상시키고, 디코딩 시 메모리 요구량을 줄여 실시간 어플리케이션에 중요한 요소인 더 큰 배치와 높은 처리량을 가능하게 함
- 또한, SWA는 더 긴 시퀀스를 더 효과적으로 처리하도록 설계되어 LLM의 일반적인 한계를 완화
2. Architectural details
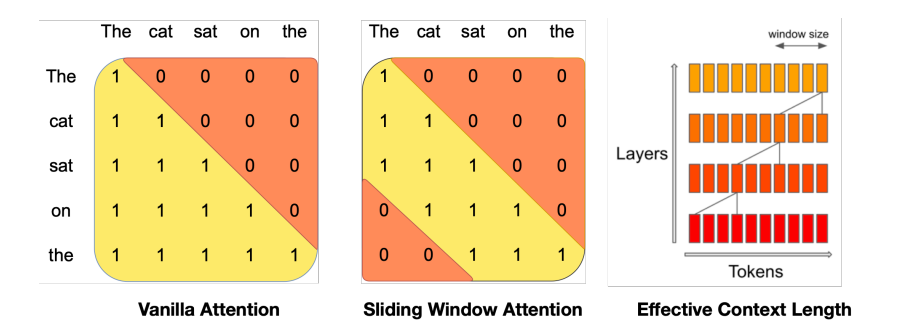 그림1: Sliding Window Attention. vanila attention에서 연산 수는 시퀀스 길이에 따라 2차적으로 증가하며, 메모리는 토큰의 수에 선형적으로 증가. 추론 시에는 캐시 가용성 감소로 인해 지연 시간이 길고 처리량이 감소. 이 문제를 완화하기 위해 sliding window attention을 사용하는데, 각 토큰은 이전 레이어에서 최대 W개의 토큰(여기서 W=3)에만 attention. 슬라이딩 윈도우 외부 토큰은 여전히 다음 단어 예측에 영향을 미침. 각 attention layer에서 정보는 W 토큰만큼 앞으로 이동할 수 있음. 따라서 k개의 attention layer 이후ㅡ, 정보는 최대 k * W 토큰만큼 앞으로 이동할 수 있음
그림1: Sliding Window Attention. vanila attention에서 연산 수는 시퀀스 길이에 따라 2차적으로 증가하며, 메모리는 토큰의 수에 선형적으로 증가. 추론 시에는 캐시 가용성 감소로 인해 지연 시간이 길고 처리량이 감소. 이 문제를 완화하기 위해 sliding window attention을 사용하는데, 각 토큰은 이전 레이어에서 최대 W개의 토큰(여기서 W=3)에만 attention. 슬라이딩 윈도우 외부 토큰은 여전히 다음 단어 예측에 영향을 미침. 각 attention layer에서 정보는 W 토큰만큼 앞으로 이동할 수 있음. 따라서 k개의 attention layer 이후ㅡ, 정보는 최대 k * W 토큰만큼 앞으로 이동할 수 있음
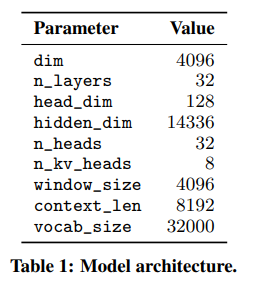
- Mistral은 transformer를 기반으로하고 메인 파라미터는 표1에 요약. 라마와 비교하여 몇 가지 변화 소개
sliding Window Attention
SWA는 transformer의 쌓인 레이어를 활용하여 window size W를 초과하는 정보에 어텐션
layer k의 위치 i에 있는 hidden states 는 이전 레이어에서 위치 i-W와 i사이에 있는 모든 hidden stats에 attention을 줌
그림 1과 같이 는 재귀적으로 최대 W * k 토큰까지 액세스 거리를 확장할 수 있음
마지막 레이어에서 W = 4096 크기의 window size를 사용하면 이론적으로 약 131K 토큰까지 attention할 수 있음
실제로, 시퀀스 길이가 16K이고 W = 4096인 경우, FlashAttention 및 xFormers에 대한 변경으로 바닐라 어텐션 베이스라인 대비 2배의 속도 향상이 이루어짐
 그림2. 캐시는W=4의 고정된 크기를 갖는다. 위치 i에 대한 key, value는 캐시의 위치 에 저장. 위치 i가 W보다 클 때, 캐시 내의 과거 값들은 덮어쓰기 된다. 가장 최근에 생성된 토큰에 해당하는 hidden state가 주황색으로 표시
그림2. 캐시는W=4의 고정된 크기를 갖는다. 위치 i에 대한 key, value는 캐시의 위치 에 저장. 위치 i가 W보다 클 때, 캐시 내의 과거 값들은 덮어쓰기 된다. 가장 최근에 생성된 토큰에 해당하는 hidden state가 주황색으로 표시
Rolling Buffer Cache
고정된 attention 범위는 rolling buffer cache를 사용하여 캐시 크기를 제한할 수 있음
캐시는 고정된 크기인 W를 가지며, 시간 간격 i에 대한 key와 value는 캐시의 위치 에 저장
따라서 위치 i가 W보다 크면 캐시의 과거 값은 덮어쓰게 되고 캐시 크기는 더 이상 증가X
그림 2에서 W=3을 예로 들어 설명
시퀀스 길이가 32K 토큰일 경우 모델 품질에 영향을 주지 않으면서 캐시 메모리 사용량을 8배까지 줄일 수 있음
Pre-fill and Chunking
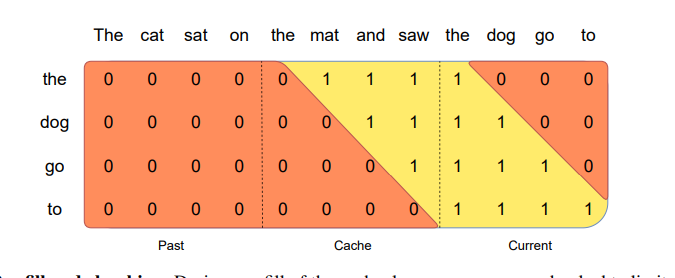 그림3: Pre-fill and chunking. 캐시를 미리 채우는 동안, 긴 시퀀스는 메모리 사용량을 제한하기 위해 chunk된다. 우리는 "The ct sat on", "the mat and saw", "the dog go to"의 세 개의 청크로 시퀀스를 처리한다. 그림은 세 번째 청크"the dog go to"에 대해 어던 일이 일어나는지 보여준다.세 번째 청크는 causal mask(가장 오른쪽 블록)을 사용하여 스스로 attend하고, sliding window(가운데 블록)를 사용하여 캐시에 attend, sliding window(왼쪽 블록) 밖에 있는 과거 토큰에 대해서는 attend X
그림3: Pre-fill and chunking. 캐시를 미리 채우는 동안, 긴 시퀀스는 메모리 사용량을 제한하기 위해 chunk된다. 우리는 "The ct sat on", "the mat and saw", "the dog go to"의 세 개의 청크로 시퀀스를 처리한다. 그림은 세 번째 청크"the dog go to"에 대해 어던 일이 일어나는지 보여준다.세 번째 청크는 causal mask(가장 오른쪽 블록)을 사용하여 스스로 attend하고, sliding window(가운데 블록)를 사용하여 캐시에 attend, sliding window(왼쪽 블록) 밖에 있는 과거 토큰에 대해서는 attend X
시퀀스를 생성할 때 각 토큰은 이전 토큰에 따라 조건이 달라지기 때문에 토큰을 하나씩 예측해야 함
그러나 프롬프트는 미리 알고있으므로 (k, v) 캐시에 프롬프트를 미리 채울 수 있음
프롬프트가 매우 큰 경우, 프롬프트를 작은 조각으로 나누고 각 조각으로 캐시를 미리 채울 수 있음
이를 위해 window size를 청크 크기로 선택할 수 있음
따라서 각 청크에 대해 캐시 및 청크에 대한 attention를 계산해야 함
그림 3은 캐시와 각 청므 모두에서 attention mask가 어떻게 작동하는지 보여줌
