Abstract
- 다국어 grapheme(문자소: 의미를 나타내는 최소 문자 단위)-to-phoneme(음소: 어떤 언어에서 의미 구별 기능을 갖는 음성상의 최소 단위)로의 변환에 대한 SIGMORPON 2020 shared task에 대한 설계와 결과를 설명
- 참가자들은 일련의 자소를 사용하고 15개 언어 중 하나로 해당 자소의 발음을 나타내는 일련의 음소를 출력하는 시스템을 제출하도록 요청받음
- 9개 팀은 총 23개의 시스템을 제출하여 강력한 neural sequence-to-sequence baseline에 비해 단어 오류율(언어에 대한 macro 평균)에서 18%의 상대적 감소를 달성
- 오류 분석을 용이하게 하기 위해 SIGMORPON 워크샵에서 최초로 모든 시스템에 대한 전체 출력 공개
1. Introduction
-
자동 음성 인식 및 test-to-speech 합성과 같은 음성 기술은 쓰여진 단어와 발음 사이의 매핑이 필요
-
end-to-end 시스템을 통해 명시적인 발음 모델을 없애려는 최근의 시도들도 이러한 종류의 암묵적인 매핑을 유도해야 함
-
open-vocabulary 프로그램의 경우, 이러한 매핑은 보이지 않는 단어로 일반화되어야 하므로 자소 시퀀스(예: glyphs)와 음소(예: 소리) 간의 매핑으로 표현되어야 함
phoneme(음소)라는 용어가 언어 이론에서 잘 정의된 대상이며, 사본의 요소를 음소로 지칭하는 것은 주어진 발음 사전에 적합하지 않을 수 있는 강력한 존재론적 약속을 만듬
따라서 다음의 내용에서 우린 문자 기호를 참조하기 위해 사전 이론적인 의미에서 phone(음소)라는 용어 사용 -
일부 언어의 경우, 이 매핑은 글을 읽고 쓸줄 아는, 언어적으로 정교한 화자가 필요한 규칙을 간단히 열거할 수 있을 정도로 충분히 욀관성이 있음
-
이 규칙의 순서는 finite-state transducer(유한 상태 변환기)로 컴파일할 수 있음
Weighted Finite-State Transducers
Concept
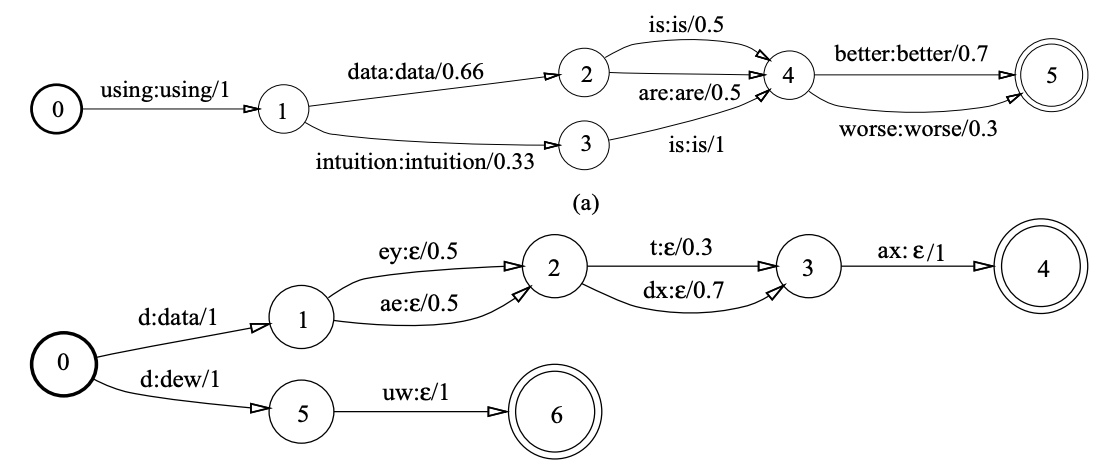
- WFST는 노드와 엣지로 구성돼 있는 그래프
- 노드가 상태(state)-> 시점(time), 엣지 위에 적힌 정보는 "입력 레이블: 출력레이블/스코어"
- 상태들이 유한(finite)개이며 가중치 정보가 포함돼 있다는 취지에서 WFST
- 그림의 상단은 언어 모델을 WFST로 나타냄.
- 언어 모델은 단어 수준에서 학습됐기 때문에 입력 레이블과 출력 레이블 모두 단어로 같고 각 상태에서 다음 상태로 전이할 스코어를 모두 더하면 합이 1이 됨(즉 각 스코어는 확률)
- 상단의 WFST가 허용하는 입력 경로(path)는 "using data is better", "using data are better", ..., "using intuition is worse" 등 12가지
- WFST는 단어 시퀀스를 입력 받아 그에 대응하는 출력 레이블 시퀀스에 관련된 경로들의 확률합을 리턴
❗ WFST는 입력이 주어졌을 때 가능한 모든 출력 경로들에 관련된 확률들을 빠르고 효과적으로 계산 해 주는 것이 목적
- 그림1의 하단은 발음 사전을 WFST로 나타낸 것
- 출력 레이블은 "data"라는 단어에 대응되는 입력 레이블 시퀀스는 "d ey t ax"나 "d ey dx ax", "d ae t ax", "d ae dx ax"등 4가지
- 출력 레이블 "dex"라는 다너에 대응하는 입력 레이블 시퀀스는 "d uw"
- 첫번째 엣지가 이후 엣지 시퀀스의 디코딩 결과를 대변. 이와 관련해 두 번째 이후의 전이(transition)는 출력이 모두 ϵ(empty)임을 확인

- 수식1을 그림의 하단 예시와 연관지어 생각해보면
- π는 시작 상태 집합() 가운데 하나 혹은 여럿의 시퀀스로 시작해 종료 상태 집합() 가운데 하나 혹인 여럿의 시퀀스로 끝나되, 입력 시퀀스 와 출력 시퀀스 에 관게된 경로(path) 가운데 하나
- "d ey t ax", "d ey dx ax", "d ae t ax", "d ae dx ax" 각각이 π에 해당
- "d ey t ax"의 확률은 시작~종료에 이르는 전이 확률들을 모두 곱하면(⨂) 됨. 1 X 0.5 X 0.3 X 1
- 모든 가능한 경로들의 합(⨁)이 WFST의 최종 결과이므로 "d ey t ax", "d ey dx ax", "d ae t ax", "d ae dx ax" 네 가지 확률 값들을 모두 더해줌
- 그러나 규칙 기반 시스템은 개발 및 유지를 위해 언어적 전문성이 필요하며 취약하거나 부정확할 수 있음
- 따라서 현대 음성 엔진은 일반적으로 weighted-finite-state transducer로 표형된 생성 모델이나 conditional random fields, recurrent neural network(순환 신경망) 또는 transformers를 기반으로 하는 discriminative model을 사용해 grapheme-to-phoneme 변환을 기계 학습 문제로 처리
✔
- grapheme-to-phoneme 변환(or G2P) 작업은 음성 기술에 매우 중요하지만 발표된 연구의 대다수는 영어 또는 무료 발음 사전을 사용할 수 있는 다른 자원이 풍부한 글로벌 언어에 초점
- 한 가지 예외로 van Esch는 20개 언어에 대한 순수한 규칙 기반 시스템과 신경망 기반 sequnce-to-sequence 모델을 비교
- 안타깝게도 이 연구에 사용된 데이터는 독점적
- 다른 많은 종류의 언어 자원과 마찬가지로, 발음 사전은 만들고 유지하는 데 비용이 많이 들고, 최근까지 무료 고급 사전은 소수의 언어에서만 사용 가능
- 소수의 언어에 대한 이러한 제한은 아래에서 논의하는 것처럼, writing system이 언어 자체만큼이나 다양함
- 따라서 우리는 dataset, evaluation metrics 및 strong baselines이 있는 다국어 graphme-to-phoneme 변환 작업을 제시
- 이 점에서 우린 자유롭게 사용할 수 있는 발엄 사전 모음인 WikiPron 도움 받음
- 이러한 종류의 첫 번째 과제는 15개 언어와 스크립트의 데이터를 포함, 9개 팀으로부터 23개의 제출 받음
2. Data
- 다양한 스크립트 유형을 다루기 위해 15개의 언어/스크립트 쌍이 선택
- 10개는 페니키아어(이집트 상형문자)에서 유래한 것으로 알려진 알파벳 체계이며, 이들 중 7개는 라틴 문자의 변형
- 아르메니아어 aybuben(아이부벤)과 조지아어 mkhedruli(므크헤둘리)는 기원을 알 수 없는 알파벳 문자이지만 그리스어를 모델
- 힌두어를 쓸 때 사용되는 devanagari(데바나가르) 문자는 대부분 glyphs(전통적으로 아카라)가 자음과 자음-모음 순서를 나타내는 알파벳 문자
- 모음(또는 모음의 부재)은 주로 분음(diacritics) 부호로 표시
- 이것 역시 페니키아의 후손이라고 생각
- 히라가나는 일본어를 쓸 때 사용되는 여러 문자 중 하나로, 대부분의 문자는 음절 전체를 의미
- 히라가나와 마찬가지로 한글도 음절문자. 이 문자는 devanagari(데바나가르)의 먼 사촌격인 티베트 문자인 'phags-pa'에서 영감을 받았을 수 있음
✔
- 중요한 것은 언어와 이를 작성하는 데 사용되는 스크립트는 grapheme-to-phoneme 변환을 위한 affordance가 매우 다름
- Writing system은 언어학적 분석의 핵심이며, 때로는 매우 naive하지만 그들이 쓰는 언어의 음운론적, 음성학적 구조의 세부 사항을 명시적으로 인코딩
- 그러나 이러한 매핑의 정확한 세부 사항은 밀적하게 관련된 언어 및/또는 스크립트 간에도 그케 다를 수 있음
- 관련 언어들이 수천 년에 걸쳐 문법적 특징을 유지하는 반면, 수십 개의 언어들은 지난 세기에 갑자기 한 스크립트에서 다른 스크립트로 바뀌었는데, 이는 언어적 문제보다 정치적인 문제에 대한 반응
- 따라서 Bjerva와 Augustenstein은 G2P 시스템을 학습함으로써 유도된 grapheme embedding이 전체 음운론적 유형과 낮은 상관관계가 있으며 'polyglot(다언어)' G2P 모델에 대한 실험에서 애매한 결과가 나옴
- language families를 선택할 때 특별히 주의를 기울이진 않았지만, 그 중 9개가 인도-유럽어(두 개는 밀접한 관련이 없지만)이고 나머지 6개 언어(아디게어, 조지아어, 헝가리어, 일본어, 한국어)는 서로 유전적으로 관련이 없음에 주목
3. Methods
- shard task에 대한 기본 데이터는 온라인 다국어 사전인 Wiktionary에서 추출한 대규모 다국어 graphme-phoneme 쌍 리소스인 WikiPron에서 파생
- 언어와 스크립트에 따라 이러한 발음은 언어별 발음 지침에 따라 사람이 수동으로 입력하거나 server-side 스크립팅 루틴을 사용하여 생성할 수 있음 - 일부 언어(불가리어, 프랑스어 등)는 두 가지 접근법을 혼합
- WikiPron은 적절한 경우 case-folding(대, 소문자 구분없이 모두 대문자나 소문자로 변경)을 적용
- segments library를 사용하여 강세 및 음절 경계 마커와 국제 음성 문자로 인코딩된 발음 문자열 제거
- 이 작업을 위해 동음이의어(homographs와 자유 발음 변형 모두)는 제외되었는데, 이러한 단어의 발음은 종종 다른 절차에 의해 선택되기 때문 : local context에 따라 조건화된 classifiers를 사용하여 발음 세트에서 선택
- 10개 언어('개발' 언어)에 대한 학습 및 평가 데이터는 작업 시작 시 공개되었으며, 5개 'surprise' 언어에 대한 동등한 데이터는 평가 단계 시작 1주일 전에 공개
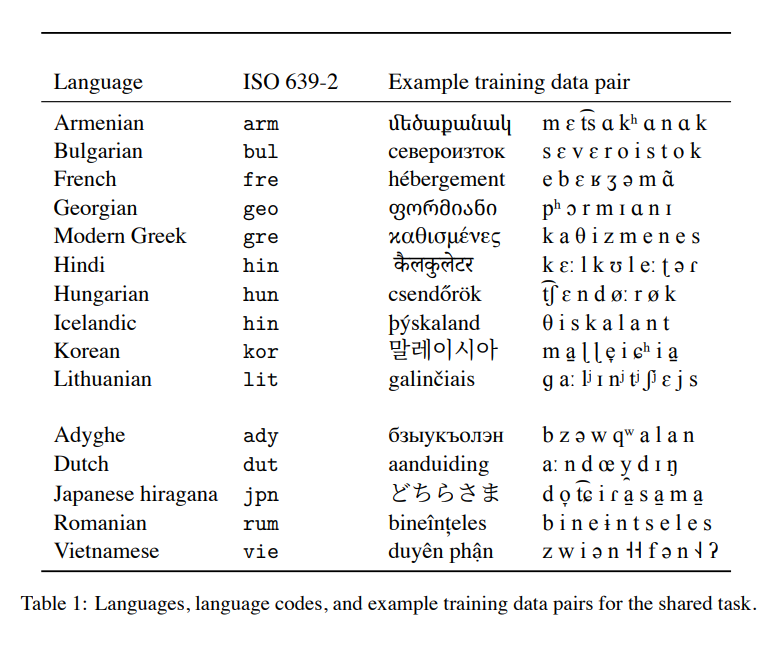
- 표1은 평가 및 깜짝 언어에 대한 샘플 학습 데이터 쌍을 제공
- 주어진 언어에 대해 사용 가능한 예제의 수에 상당한 차이가 있기 때문에 각 언어의 데이터는 4,500개의 예제로 다운샘플링
- 이 작업에 대해 'medium-resource'설정으로 간주. 예를 들어, 이러한 데이터셋은 van Esche등이 사용하는 독점 G2P 데이터보다 몇 배 작음
- 다른 공유 작업의 유사한 절차에 따라, 해당 언어에 대해 사용가능한 가장 큰 Worthschatz 말뭉치의 빈도에 따라 단어를 샘플링
- 이러한 빈도는 모든 WikiPron 항목의 빈도에 0.3 pseudo-count를 추가함으로써 smoothed
- Worschatz 빈도 데이터는 Adyghe에 대해 사용할 수 없었기 때문에 이 언어에서 균일한 샘플링이 사용
- 그런 다음 다운샘플링된 데이터를 학습(80%, 3600개의 예제), 검증(10%, 450개 예제), 테스트(10%, 450개 예제) 조각으로 랜덤하게 분할
- 일부 언어의 경우, 위키백과에는 lemma 발음(표제어, 인용 형태) 및 inflection variant 모두 포함 ; 다른 사람들의 경우 발음은 lemma에서만 가능
- 학습 데이터에 lemma의 inflectional variant가 있고 테스트 데이터에 다른 변형이 존재하는 경우(데이터가 무작위로 분할된 경우 발생할 수 있음) 전체 작업이 다소 쉬워질 것이라는 가설을 세움
- 이러한 가능성을 방지하기 위해 위키백과에서 추출한 UniMorph2 패러다임 테이블에 따라 지정된 lemma의 모든 inflectional variants이 단일 분할로 제한되도록 분할 절차가 제한
- 예를 들어, 프랑스어 단어 acteur 'actor'가 학습 분할에서 발생하기 때문에 복수형 acteurs도 나타나야 함
- 이 추가 제약은 UniMorph 데이터가 없는 일본어와 베트남어를 제외한 모든 언어에 적용
- 위키백과가 일반적으로 일본어의 inflectional variant에 대한 발음을 제공하지 않으며, 베트남어는 식별할 수 있는 굴절 시스템이 없는 고립된 언어이기 때문에 편향이 도입되었을 가능성이 낮다는 점에 주목
4. Evaluation
-
이 작업의 기본 메트릭은 word error rate(WER), 음소 오류율 (PER)
-
WER
- 가정된 표기 sequece가 gold 참조 표기와 동일하지 않은 단어의 백분율로 WER가 낮을수록 더 나은 성능
- 음성 연구의 일반적인 관행에 따라, WER에 100을 곱해 백분율로 표시
- G2P error가 아무리 작더라도 downstream 음성 응용 프로그램에 대한 주관적 품질이 크게 저하될 것이라고 가정하기 때문에 shared task에 대한 기본 메트릭으로 이것을 선택
-
PER
- 예측 표기와 참조 표기 사이의 정규화된 거리(삽입, 삭제 및 대체 횟수)를 측정하는 보다 관대한 척도
- 예측과 참조 표기 사이의 minimum edit distance를 합하고 참조 표기 길이의 합으로 나누어 계산됨
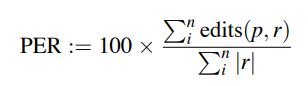
- 여기서 p는 예측된 발음 시퀀스, r은 참조 시퀀스, edit(p,r)은 둘 사이의 Levenshtein 거리
- 다시 한번, 100으로 곱하는데 이것은 100을 초과할 수 있기 때문에 실제 백분율은 100을 초과할 수 있음
- WER와 마찬가지로 PER이 낮을 수록 더 나은 성능
- 참가자들에게 두 개의 평가 스크립트가 제공
- 하나는 단일 언어에 대한 두 가지 메트릭을 계산하고, 다른 하나는 모든 언어에 걸쳐 메트릭을 macro 평균화
5. Baselines
-
작업을 시작할 때 3개의 baseline이 사용가능
-
몇개의 제출물들은 data augmentation 또는 ensemble 구성을 위해 baseline을 사용
-
Pair n-gram model
- 첫 번째 baseline은 pair n-gram 모델로 구성되며, graphemes를 나타내는 상태와 출력 phone(음소)를 나타내는 출력을 갖는 hidden Markov model의 finite-state 근사치로 생각할 수 있음
- 이 모델의 유일한 hyperparameter인 Markov model 순서는 평가셋을 사용하여 각 언어에 대해 별도로 조절
-
Encoder-decoder LSTM
- 두 번째 baseline은 attention mechanism을 사용하여 연결된 single-layer bidirectional LSTM encoder와 single-layer unidirectional LSTM decoder로 구성된 neural network sequence-to-sequence 모델
- fairseq libaray 사용하여 구현
- LSTM 기반 encoder-decoder 모델은 단일 언어 및 다국어 평가 모두에서 pair n-gram G2P 모델을 능가한다고 주장되었지만, 이러한 선행 연구는 이 작업에서 사용할 수 있는 것보다 훨씬 더 많은 학습 데이터를 사용
- 학습하는 동안 4,000번의 업데이트를 수행하여 label-smoothed crossentropy를 0.1의 smoothing rate로 최소화
- learning rate α = 0.001이고 weight decay 계수가 β = (0.9, 0.98) 및 clip norm이 1.0을 초과하는 Adam Optimizer를 사용
- 평가 셋을 사용해 각 언어에 대해 batch size (256, 512, 1024), dropout (.1, .2, .3), 인코더 및 디코더 모듈의 크기를 조절
- 모듈은 128차원 embedding layer와 512 unit hidden layer이 있을 때 'small'이고 256차원 embedding layer와 1024 unit hidden layer가 있으면 'large'라고 함
- 두 경우 모두, 디코더는 입력과 출력 모두에 대한 단일 임베딩 계층을 공유
-
Encoder-decoder Transformer
- 세 번째 baseline은 트랜스포머로, hidden layer 반복을 multi-head self-attention layer로 대체하는 neural sequence-to-sequence model
- fairseq를 사용하여 구현
- 여기서 모델은 4개의 인코더 레이어와 4개의 디코더 레이어로 구성되며, 둘 다 character0level task에 맞게 조정된 pre-layer normalization을 사용
- hyperparameter grid, tuning 절차 및 beam size는 1000회 update linear warm-up period 후 learning rate가 역 제곱근 스케줄에서 감소한다는 점을 제외하곤 위의 LSTM 모델과 동일
- 대부분의 참가자는 시스템 설명 논문의 LSTM이 아닌 transformer와 결과를 비교하기로 선택했지만 transformer는 hyperparameter 탐색 예산이 있는 대부분의 설정에서 LSTM baseline보다 성능이 우수
6. System descriptions
아래에선 shared task에 대한 제출에 대한 간략한 설명을 제공
- CLUZH
- 취리히 대학의 컴퓨터 언어학 연구소는 target 문자열 자체가 아닌 일련의 edit action을 출력하는 모방 학습 기반 transducer에 대한 단일 시스템을 제출
- 입력(grapheme) 및 출력(phone) 어휘가 있는 G2P 작업에 적응하기 위해 크게 분리되어 대체 작업을 추가(뭔소리?)
- 각 edit action의 비용은 weighted finite state transducer(WFST)에서 도출
- 저자들은 푸마, 어원(특히 차용) 및 형태론적 세분화와 같은 외부 어휘 정보가 시스템을 개선할 것이라고 제안
- 전처리 과정에서 한글 문자를 각각 대략 하나의 phoneme(음소)에 해당하는 jamo(자모)로 분해
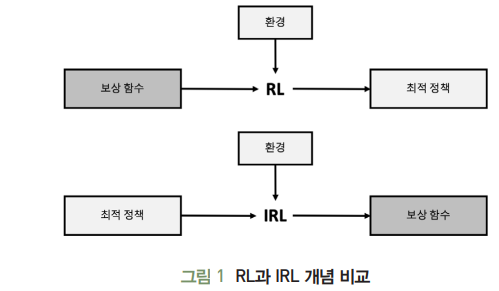
강화학습(RL)에선 에이전트(agent)가 어떤 상태(state)에서 행동(action)을 수행할 때마다 그 성능에 대한 피드백을 제공하는 보상함수(reward function)가 주어진다.
이 보상 함수는 최적 정책(optimal policy)를 구하는데 이용되며, 이때 예상되는 미래 보상 값이 최대가 됨
모방학습(역강화학습(IRL):Inverse Reinforcement Learning)은 에이전트의 정책이나 행동 이력을 통해 그 행동을 설명하는 보상 함수를 구하는 알고리즘
즉, 주어진 설정이 RL의 역이 되며, 에이전트가 최선의 행동을 선택했다는 가정하에 이 행동에 대한 보상 함수를 추정하는 학습 방식.
따라서 RL과 달리 복잡한 상황에서 다양한 보상 요소를 반영하여 최적의 정책을 찾는데 용이
- CU
- 콜로라도 대학교 볼더의 한 팀은 다수 투표를 사용해 서로 다른 random seed로 만든 여러 transformer model을 ensembeld
- 그들은 또한 멀티태스킹 학습의 형태를 실험
- 'bidirectional' 모델을 학습시켜 grapheme-to-phoneme 그리고 phoneme-to-graphme로 예측
- CUZ
- 콜로라도 대학교 볼더의 두 번째 팀은 'slice-and-shuffle' data augmentation 전략을 사용
- 첫째, graphme와 phoneme 사이에 문자 수준의 일대일정렬을 수행
- 그런 다음 빈번한 subsequence 쌍을 서로 연결하여 임시 학습 예제를 만듬
- 제출물은 이 증강 데이터에 대해 학습된 양방향 인코더가 있는 LSTM모델
- DeepSPIN
- Superor Tecnico와 Unbabel의 연구원들은 sparse attention model을 기반으로 4개의 제출물을 제작
- 각 제출은 입력 시퀀스에 언어 식별 토큰을 추가하는 대신 별도의 학습된 '언어 임베딩'이 모든 인코더 및 디코더 상태에 연결되는 단일 다국어 신경 모델로 구성
- 제출물은 final layer에서 sparsity(희소성)을 시행하는 hyperparameter의 다른 값을 가진 LSTM 또는 Transformer 기반 인코더-디코더 sequence-to-sequence 모델을 사용
- CLUZH와 마찬가지로 한글 문자를 사전처리하여 각각 대략 단일 음소에 해당하는 자모로 분해
- IMS
- 슈투트가르트 대학의 연구소의 제출물은 self-training과 기존 baseline model의 ensembles
- 앙상블의 구성 요소는 유전자 알고리즘을 사용하여 선택
- 200개의 학습 에제를 사용하여 시뮬레이션된 저자원 설정을 제외하고는 데이터 증강이 성능에 크게 영향을 미치지 않는다고 보고
- 사전 처리 단계로 일본어와 한국어 텍스트를 로마자로 표기하고, 외부 단어 빈도 목록을 사용
- UA
- 앨버타 대학교의 제출물은 non-neural discriminative string transduction model(DTLM) 또는 transformer를 사용
- grapheme-to-phoneme 와 phoneme-to-grapheme 모델을 모두 활용하여 data augmentation을 위한 후보를 필터링하고 cyclic consistency constraint를 적용
- 또한 100개의 학습 예제를 사용하여 시뮬레이션된 저자원 시나리오에서 강력한 성능을 보여줌
- DTLM 시스템이 transformer보다 학습이 훨씬 빠름
- 6개의 제출물은 학습 데이터의 양을 다양하게 하고 DTLM, transformer 또는 data augmentation 기능이 있는 transformer를 사용
- UBCNLP
- 브리티시컬럼비아 대학교는 두 가지 시스템 제출
- 하나는 다국어 모델로, 입력 시퀀스에 언어 식별 토큰이 추가
- 또한 여러 개의 checkpoint를 ensemble
- 두 번째 제출물은 위키피디아 텍스트에 대한 self-training을 추가
- 이 data augmentation이 점수를 향상시키지 않는다고 보고
- UZH
- 취리히 대학팀은 제출한 세가지 모두에 대해 모든언어에서 공유되는 단일 인코더-디코더 parameter 셋을 사용
- UZH-1은 large embedding, hidden layer 및 batch를 포함하고 dropout 확률이 높은 large transformer 모델
- UZH-2는 다른 6개 언어에 대한 WikiPron 데이터로 이 모델을 보강
- UZH-3은 이전 두 모델의 앙상블로, 두 구성 요소 모델의 예측에서 사후 확률이 더 높은 모델을 선택
- 앙상블은 대부분의 언어에서 구성 요소 모델을 능가
- 전처리 과정에서 한글을 자모로 분해
- 이 결과가 46%의 상대적인 단어 오류 감소를 가져온다고 보고
7. Results
7.1 Baseline results
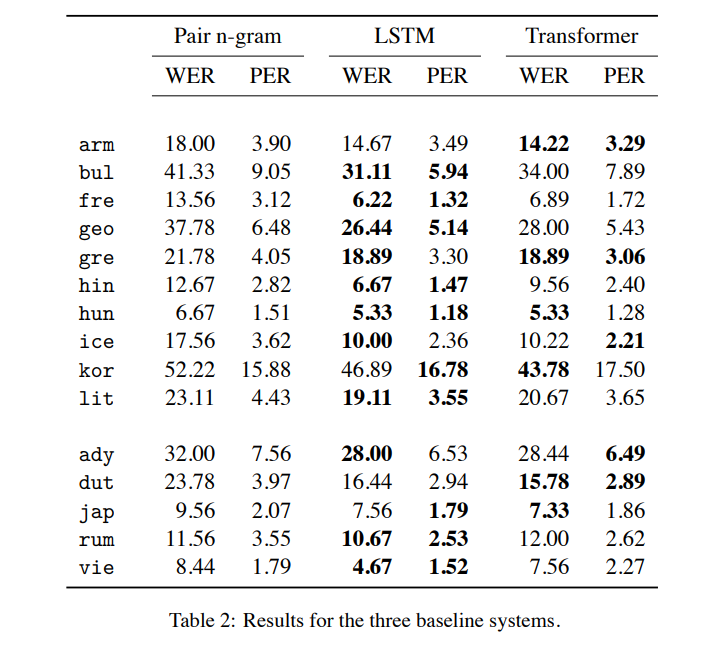
- encoder-decoder LSTM은 15개 언어 중 9개 언어에서 가장 우수한 성능
- transformer는 4개 언어에서 가장 강력했고, 나머지 2개 언어(현대 그리스어와 헝가리어)는 두 신경망 기준선 사이에 가상의 연결
- pair n-gram은 모든 언어의 neural baseline에서 불가리아어, 조지아어 및 한국어에서 10점 이상 높음
- 이는 이 모델이 적어도 이 medium-resource G2P 작업에서 더 이상 강력한 차별적인 neural 방법과 경쟁력이 없음을 시사
- 이 작업은 LSTM과 transformer sequence-to-sequence 모델을 비교하기 위해 명시적으로 설계되지 않았지만 LSTM모델의 이점을 제안
- 추가 학습 데이터 또는 더 generous한 hyperparamter tuning budget이 transformer model에 유리할 수 있다고 추측
- 실제로 아래의 결과를 예상하여 transformer와 LSTM 시스템을 직접 비교한 한 팀인 DeepSPIN은 transformer를 사용하여 전체적으로 3번쨰로 우수한 성능을 달성
- 또한 4애 언어의 경우, 두 메트릭이 나머지 11개 언어에 대해 동일한 one-best ranking을 산출하지만, best WER를 달성하는 baseline system은 best PER을 달성하지 못함
7.2 Submission results
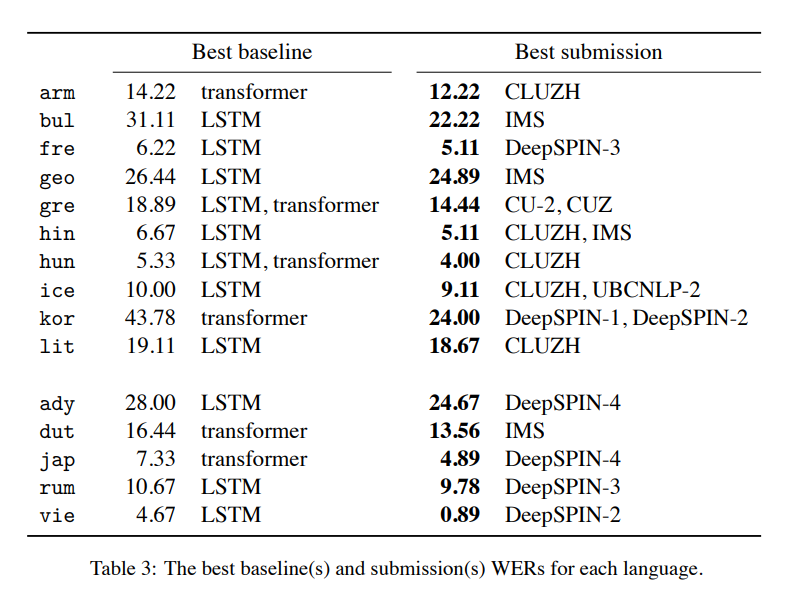
- 표3은 각 언어에 대해 best WER system과 best baseline WER을 달성한 시스템을 보여줌
- 15개 언어 모두에 대해, 최소 한 팀은 baseline을 능가했으며, 때로는 상당히 큰 설과를 거둠
- 9개 팀 중 6개 팀이 하나 이상의 언어에서 best WER을 달성
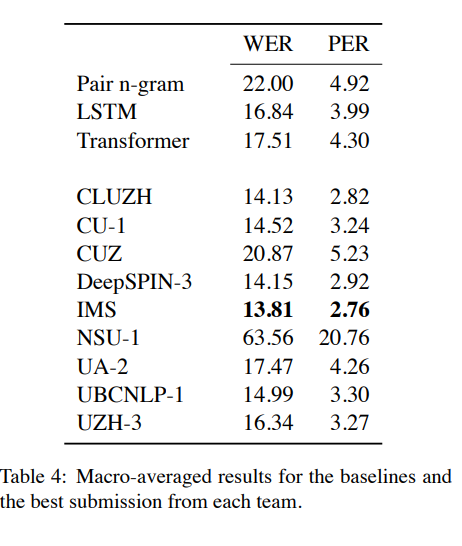
- 표4는 세 개의 baseline과 각 팀의 전체적인 best 제출에 대한 macro-averaged WER 및 PER를 제공
- 예상대로 가장 강력한 baseline은 LSTM
- 모든 제출에서 IMS 팀은 LSTM 기준에 비해 쵲저 평균 WER, 절대적으로 3%(상대적으로 18%) 단어 오류 감소, 그리고 LSTM 기준에 비해 절대적으로 1%(상대적으로 31%) phone 오류 감소라는 최저 전체 PER를 모두 달성
- CLUZH와 DeepSPIN-3 제출물은 각각 2위와 3위를 달성. CU, UCBNLP 및 UZH 팀은 또한 LSTM 기준의 WER을 능가하는 시스템 제출
8. Discussion
- 이 과제가 처음 제안되었을 때, baseline 자체는 아니더라도 제출물들이 일부 언어에서 완벽하거나 거의 완벽한 성능을 쉽게 달성할 것이라는 우려가 있었지만 사실이 아님
- 가장 쉬운 언어에서도 best submission은 .89% WER이고, 3개 언어의 경우 20% 미만의 오류율을 달성한 제출물은 없음
- 동시에, 우린 언어에 걸쳐 광범위한 오류율을 관찰
- 단어 및/또는 phone 오류율이 실제로 난이도의 차이를 나타낸다고 추측하고 싶을 정도
- 이것이 정확하다면, Mielke가 언어를 '언어 모델링하기 어렵게 만드는 것'을 묻는 것과 유사하게 무엇이 언어를 '발음하기 어렵게'하는 가를 묻는 것으로 시작할 수 있음
✔
- 언어를 발음하기 어렵게 만드는 한 가지는 데이터 희소성
- 15개 언어 중 가장 높은 baseline 오류율을 가진 한국어의 경우를 생각해보면
- 한국어와 한글의 세 가지 특징이 이 작업을 특히 어렵게 만듬
- 한글은 음절문자이기 때문에 반드시 알파벳이나 alphasyllabary(아부기다: 음절 문자와 자모 문자의 특성을 모두 지닌 표기 체계)보다 더 큰 graphemic 목록을 가지고 있음
- 이 작업에 사용된 4,500개의 단어에 걸쳐 899개의 고유한 한글 문자가 나타남
그렇게 큰 음절문자는 거의 없음
예를 들어, 일본어 데이터에는 79개의 고유 히라가나 기호만 있지만, 한국어가 일본어보다 더 관용적인 음절 구조를 가지고 있단느 점에서 이러한 상대적인 크기 차이는 놀라운 일이 아님 - 한글은 상대적으로 심오하거나 추상적인 맞춤법이다; 한글은 대략 형태소 수준에서 작동하는 반면, 리투아니아어와 헝가리어는 대략 음소 수준에서 작동
- 한국어는 음절 경계를 넘나드는 음운론적 과정이 많음
- 이러한 과정의 효과는 매우 추상적인 형태 음소(morphophonemic) 철자법으로 나타내지 않기 때문에, 학습 중에 대상 음절 bigram을 관찰해야만 학습할 수 있음
- LSTM baseline과 유사한 한국 G2P 시스템의 수동 오류 분석을 수행하고 이러한 coda-onset(초성, 종성) cluster 규칙의 과소 적용으로 인해 발생하는 오류를 관찰
- 두 기술 모두 입력 어휘의 크기를 줄이기 때문에 여러 제출물이 사전 처리 중에 한글을 로마자로 만들거나 자모로 분해하여 상당한 이점을 달성한 것은 놀라운 일이 아님
✔
- 위에서 언급한 것처럼 상위 제출물은 전처리, data augmentation, 앙상블, multi-task learning(phoneme-to-grapheme 변환) 및 self training과 같은 기술 사용
