
Abstract
- 협업 다국어 온라인 사전인 Wiktionary에서 발음 데이터를 추출하기 위한 오픈 소스 command-line tool인 WikiPron 소개
- 이 tool을 확장하여 165개 언어에서 170만 발음의 자동 생성 데이터베이스를 생성하는데 직면한 문제 논의
- 발음 데이터베이스를 사용해 일반적인 grapheme-to-phoneme model을 학습하고 평가함으로써 검증
Keywords: speech, pronunciation, grapheme-to-phoneme, g2p
1. Introduction
- 음성 기술은 phones(음소)로 표시되는 단어의 철자 형식과 발음 사이의 매핑에 의존
- 매핑은 디지털 발음 사전을 사용해 구성되며, OOV 단어의 경우, 이러한 사전에서 학습된 grapheme-to-phoneme로 변환 모델 사용
- 발음 사전을 만들고 유지하는데 비용이 많이 들고, 무료로 제공되는 대규모 고품질 사전은 소수의 언어로만 제공
1.1 Prior work
- 크라우드 소싱을 통해 한 것중 협업 다국어 온라인 사전인 Wiktionary가 있음
- Wiktionary는 형태학적 패러다임의 다국어 데이터베이스인 UniMorph를 포함한 많은 자연어 자원을 위해 만들어짐
1.2 Contributions
-
본 논문에성 Wikitionary에서 발음 데이터를 마이닝하기 위한 오픈 소스 tool인 Wikipron을 소개
-
이 tool을 사용해 마이닝한 165개 언어(현재 실존하는 언어와 죽은언어, 자연어와 구성어)로 된 170만 단어/발음 쌍 데이터베이스 설명
-
데이터베이스 사용해서 G2P 모델링 실험 수행
-
단어-발음 쌍이 100개 미만인 언어 생략, cross-lingual projection❌
1.3 Wiktionary pronunciation data

- Wiktionary 영문판에는 900개 이상의 언어에 대한 발음 항목 있음
- 그 중에는 현존하는 고대 언어(이집트어), 구축 언어(에스페란토어), 재구성 언어(오스트로네시아조어)도 있음
- 발음은 IPA(국제 음성 문자)로 제공되며, 많은 언어에서 Wiktionary 기여자를 위한 표기 가이드라인 제공
2. Using WikiPron
pip install wikipron- 프랑스어(ISO 639 code:fra)에 대한 발음 데이터
wikiporn fra- WikiPron의 출력은 UTF-8로 인코딩된 단어/발음 쌍의 목록이며, 각 쌍은 자체 line에 있고 단어와 발음은 tab문자로 구분

- 샘플 출력
- 단순한 출력 형식은 다양한 상황에서 사용할 수 있을만큼 충분이 일반적
3. The massively multilingual database
- G2P modeling에 대한 이전 연구의 대부분은 대규모 발음 데이터베이스를 공개적으로 사용 가능한 소수의 고자원 언어로 제한
- Wikipron 저장소는 100개 이상의 발음을 사용할 수 있는 165개의 Wiktionary 언어의 발음 데이터베이스 호스팅
- 데이터베이스를 자동으로 생성하고 업데이트하는 코드도 포함
- 이 설계를 통해 연간 데이터베이스의 버전 릴리스를 신속하게 생성
3.1 Summary statistics
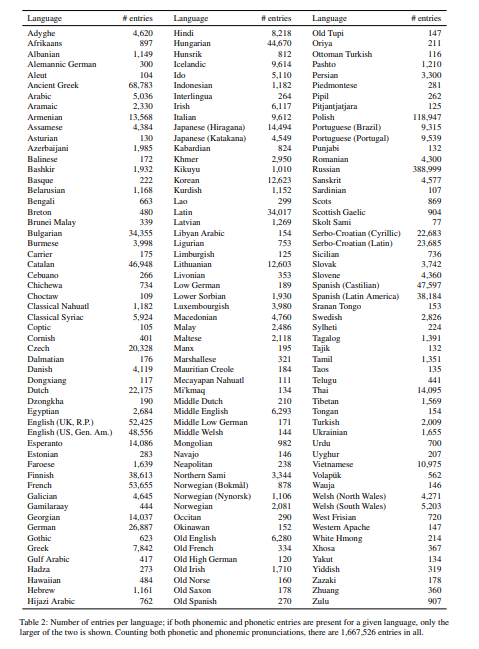
- 표2는 현재 지원되는 165개 언어, 방언 및 스크립트의 발음 항목 수
Phonetic versus phonemic transcription
Wiktionary 사전 항목(언어내 또는 언어간)은 phonetic(음성) 또는 phonemic(음소) 표기가 제공되는지 여부에 따라 다양함
일관성을 위해, phonemic(음소)와 phonetic(음성) 표기 분리
다행히 언어 문헌에서 표준으로 사용되는 대괄호(phonetic 표기) 또는 슬래시(phonemic 표기)를 사용함으로써 나타남
WikiPron에선 사용자가 명령줄 플래그를 통해 phonemic 또는 phonetic 표기 선택
phonetic: 입에서 나는 소리, 자세한 단위까지 음성을 분석, 정밀 표기법 []
phonemic: 귀로 들리는 소리, 언어에 필요한 최소한의 단위(음소) 분석, 간략 표기법 //
Wiktionary에서 'phonemic'과 'phonetic' 표기의 구분이 언어적 개념과 반드시 일치하지는 않는다는점 유의
특히, 일부 언어에 대한 'phonemic' 표기는 예측 가능한 allophone(이음)(예:바보에서 두개의ㅂ은 다른소리지만 같은 소리로 인식) 포함
예를 들어, 독일어 "phonemic" 표기법은 [ç] versus [x]가 오랫동안 단일 phoneme의 이음으로 간주되었음에도 불구하고 둘 다 포함
Wiktionary의 "phonemic"과 "phonetic" 표기법은 각각 "braod(넓다)" 와 "narrow(좁다)"로 설명
Dialect specification
Wiktionary의 발음은 그림1과 같이 dialectal specification(방언 설명서?) 쌍을 이룸
specification을 무시한다면, 각 단어에 대해 많은 발음 변형이 생김
WikiPron은 사용자가 명령줄 플래그를 통해 방언 사양으로 쿼리를 제한
IPA segmentation
모델링 목적을 위해 IPA 발음 기호를 호스트 음성 기호와 결합하고 수정하거나 타이 바를 사용하여 표시된 contour(윤곽) segment를 보존하는 방식으로 발음을 분할하는 것이 바람직
예를 들어, 영어 단어 cat의 음성 표기인 [kæt]
각 유니코드를 코드포인트를 분리하는 naive 분할은 [k]와 원하는 릴리스를 분리해서 <k, , æ, t> 제공
WikiPron은 segments library를 사용해 IPA 문자열을 segment화
이것은 [kæt]을 <k, æ, t>로 올바르게 구분
segment의 한게는 수정할려는 phone앞에 오는 분음 부호를 제대로 분할❌
예를 들어, 페로어 단어 kokusnøt/ ko∶υsnø∶t/ 'coconut', 은 2개의 사전 흡인 팔염음을 포함, 앞 모음에 흡인음이 잘못 부착된 상태에서 <k, o∶, k, υ, s, n, ø∶, t>로 분할
마지막으로 명령줄 플래그를 사용해 IPA 분할을 비활성화할 수 있음
Suprasegmentals
WikiPron에는 사용자가 선택적으로 단어 강세 표시나 음절 경계를 제거할 수 있는 명령줄 플래그도 있음
G2P 모델링 작업에서 강세 및 음절 경계가 생략되기 때문에 대규모 다국어 데이터베이스에 대해 이 옵션 사용 가능
Special orthography and pronunciation extraction
Wiktionary의 대부분의 언어는 동일한 기본 HTML 구조를 사용하며, 대규모 다국어 발음 마이닝을 가능하게 하는 핵심 기능
몇몇 언어들은 특별한 처리가 필요하며, IPA 표기버 또는 올바른 철자 형태를 목표로 하는 것은 기술적으로 어려울 수 있음
크메르어와 태국어 같은 특정 언어는 발음을 목표로 하는 맞춤형 추출 기능이 필요한 반면, 일본어와 같은 다른 언어는 발음과 맞춤법 형식을 목표로 하는 특수 추출 기능 필요
일본어 Wiktionary의 표제어는 한자, 히라가나, 가타가나
한자 항목은 해당 가타가나 형식을 제공하며 모든 항목은 페이지의 다른 곳에 해당하는 로마자로 나열
모델링 목적으로 히라가나와 가타가나 형태를 모두 추출한 다음, 후처리 단계로 히라가나와 가타가나 데이터 분리
세르보크로아티아에서도 비슷한 문제
키릴 문자로 작성된 세르비아어 표제어와 라틴 문자로 작성된 크로아티아어 표제어 포함
따라서 사후 처리 단게로 세르보-크로아트 데이터를 두 개의 구성 스크립트로 분리
마지막 문제는 라틴어
현대 라틴어 학자들은 긴 단음절을 나타내기 위해 마크롱 구분 기호를 사용하지만, 마크롱은 Wiktionary에 없음
'homographs'의 수많은 사례 만듬
예를 들어, malus라는 표제어는 malus [malus] '불쾌한' 또는 mālus [ma∶lus] '사과나무'로 발음될 수 있음
적절한 graphemic 형식을 추출하기 위해 언어별 HTML 구문 분석 필요
4. Experiments
- WikiPron 데이터를 검증하기 위해, G2P modeling 실험
- 15개 언어에서 WikiPron 데이터 샘플 구성
- 밀접한 관련이 있는 두 언어❌, 대부분 라틴어가 아닌 문자 사용
- 각 언어에 대해 단일 grapheme 또는 단일 phone 및 여러 발음이 있는 단어로 구성된 항목 제거
4.1 Models
2개 타입 모델 실험
4.1.1 Pair n-gram model
- baseline은 pair n-gram model형태
- 이 접근법은 Taylor가 G2P에 대해 제안한 hidden Markov model 접근법과 관련있지만, higher-order 모델을 훨씬 빠르게 학습
Training
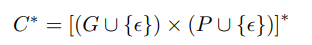
G를 grapheme의 집합, P를 phone의 집합, 그리고 ∊는 빈 문자열
×가 cross-product 연산자이고 * 가 Kleene star인 unigram aligner finite-state transducer를 구성
resulting transducer는 G2P의 unigram model의 topolgy를 가지며, 이는 임의의 grapheme이 임의의 phone에 정렬되도록 허용하고 임의의 phone이 임의의 grapheme에 정렬되도록 하고, grapheme과 phone 모두 아무것도 정렬할 수 없는 것은 ∊로 표기
다음으로, 수렴할 때까지 학습 데이터의 확률의 최대화하기 위해 Viterbi 학습 (?, 293)사용
25를 random initialization하고, 병렬로 실행하며, 학습 데이터 복잡성을 최소화하는 모델 선택
그런 다음, Viterbi 알고리즘을 사용하여 학습 데이터에 대한 best-probability 정렬 계산
각 정렬이 () 쌍과 일치하는 finite-state acceptor가 되도록 정렬을 인코딩
...
4.1.2 Neural sequence model
- neural 모델이 미국 여어 발음의 대규모 데이터베이스인 CMUDict에서 pair n-gram 모델을 능가한다고 보고
Training
- standard attention mechanism으로 연결된 single bidirectional LSTM encoder layer와 single LSTM decoder layer로 구성
- 두 임베딩은 간단한 정규화 형식인 매개변수 공유
- 고정 learning rate으로 최대 50 epoch의 stochastic gradient desent 학습
Tuning
- 주어진 많은 데이터셋이 neural network G2P에 대한 이전 작업에서 사용된 것보다 훨씬 작다는 점을 고려할 떄, 간단한 hyperparameter 검색으로 제한
- 검증 셋을 사용해 early stopping 수행; 즉 매 epoch마다 checkpoint 생성해서 검증 셋의 perplexity를 최소화하는 checkpoint 저장
- 검증 셋을 사용해 인코더와 디코더, 소스 및 target embedding의 차원을 선택하고 {64, 128, 256, 512, 1024}의 값에 대한 lockstep sweeping
Decoding
- 디코딩하는 동안 early-stopping checkpoint를 사용하고 width 5 beam search
4.3 Results
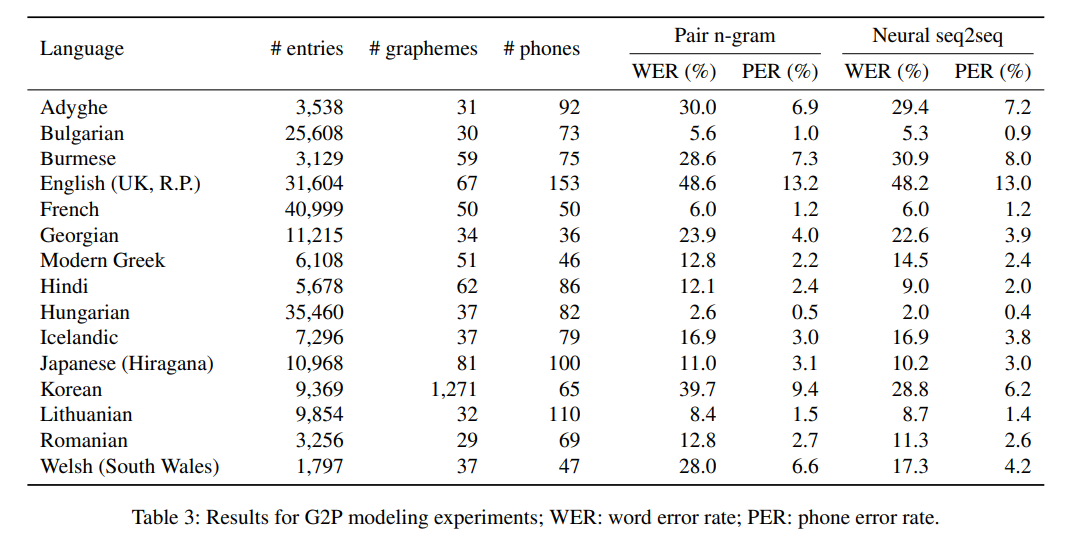
- 15개 언어 샘플에 대한 요약 통계 및 결과는 표3에 나와있음
- neural sequence model이 모든 언어는 아니지만 대부분의 언어에서 pair n-gram 모델을 능가
- Error rate은 상대적으로 일관되고 얕은 맞춤법과 더 큰 학습 셋 중 하나를 가진 헝가리어 가장 낮음
- Error rate이 가장 높은 언어는 영어
- 더 큰 데이터셋 중 하나이지만, 영어 맞춤법은 보수적이고 추상적
- 영어는 차용자이지만, 다른 라틴어 문자에서 차용한 단어의 철자를 거의 바꾸지 않음
- 영어 WikiPron 샘플의 153개의 고유한 phonemes가 다양한 영어의 phoneme 수에 대한 합리적인 추정치를 초과하여 일관성이 없거나 지나치게 좁은 표현이 있음을 암시
4.4 Error analysis
- 여러 언어에 대한 간단한 수동 오류 분석
- 프랑스어와 한국어의 맞춤법은 매우 추상적
- 프랑스어는 라틴 문자로 쓰여지고 한국어는 한글 음절로 쓰여지지만, 두 언어에서 관찰된 대부분의 오류는 철자에 표시되지 않은 phonological(음운론적) 규칙의 과소 또는 과다 적용으로 구성
- 한글에서 이러한 오류는 음절, 즉 grapheme 경계에 phonological rule(예: 비음화)을 적용하지 않은 경우가 많음
- 예를 들어 익명 [iŋmjᾼŋ]은 [ikmjᾼŋ]로 잘못 표기됨
5. Conclusion
- Wiktionary에서 발음 데이터를 마이닝하기 위한 소프트웨어 설명
- 이 소프트웨어를 사용하면 165개 언어의 발음 데이터베이스를 자동으로 생성하고 재생할 수 있음
- 자원이 적고 연구가 덜 된 언어를 위한 음성 기술, 특히 G2P 변환 엔진을 구축하고 평가하는 데 사용되길 바람
- 향후 연구에선, 데이터를 조사하기 위해 phonemic inventories의 다국어 데이터베이스인 Phoible을 포함한 외부 자원 활용 계획
- 궁극적으로 이러한 노력을 통해 Wiktionary 자체의 품질과 일관성이 향상되길 기대
- 또한 library를 지속적으로 개선하여 추가적인 언어, 방언, 스크립트, 특히 동아시아의 logographic 스크립트 지원할 것
