💡 PLOME: Pre-training with Misspelled Knowledge for Chinese Spelling Correction
Abstact
- CSC는 중국어 맞춤법 검사와 교정 데이터셋
- PLOME는 BERT에서처럼 고정된 토큰 [MASK]가 아닌 confusion set에 따라 유사한 문자로 선택된 토큰을 마스킹
- 문자 예측 외에도 발음 예측을 도입해 음성 수준에서 철자가 틀린 지식 학습
- 게다가 이 task에선 phonological(음운론적)과 시각적 유사성 지식이 중요
- GRU 네트워크를 활용해 character의 phonics와 strokes를 기반으로 이러한 지식을 모델링
1. Introduction
- 중국어에서 맞춤법 오류는 크게 음운 오류와 시각 오류 두 가지 유형으로 나뉨
- 다른 기존 논문들의(Soft-masked BERT, SpellGCN) 언어 모델은 CSC 작업에서 독립적으로 사전 학습
- 결과적으로 사전 학습 중에 작업 관련 지식을 학습X, 이러한 접근 방식의 언어 모델은 CSC에 최적화X
- character간의 유사성에 대한 지식은 이 작업에 매우 중요
- 일부 작업은 이러한 정보를 합하기 위해 confusion set, 즉 유사한 문자 집합을 활용
- 근데 confusion set은 일반적으로 휴리스틱 규칙이나 수동 주석에 의해 생성되서 적용 범위가 제한적
- 이러한 문제를 극복하기 위해 character의 strokes(문자의 획)과 phonics를 기반으로 유사도 계산
- 규칙을 통해 측정됨
- vanila BERT보다 PLOME이 효과적
- confusion set 기반 masking 전약 제안, BERT에서처럼 고정된 토큰 [Mask]가 아니라 confusion set에 따라 선택된 각 토큰을 유사한 문자로 무작위 대체.
PLOME은 사전 학습 동안 의미와 철자 오류 지식을 공동으로 학습. - 제안된 모델은 각 문자의 획과 음소를 입력으로 사용해 PLOME이 문자 간 유사성을 모델링 할 수 있음
- PLOME은 마스킹된 토큰에 대한 실제 문자와 음운을 공동으로 복구해서 문자와 음운 수준 모두에서 철자가 틀린 지식 학습
- SIGHAN 벤치마크 데이터셋 사용
- PLOME이 Soft-masked BERT와 SpellGCN을 포함해서 성능 능가
3. Approach
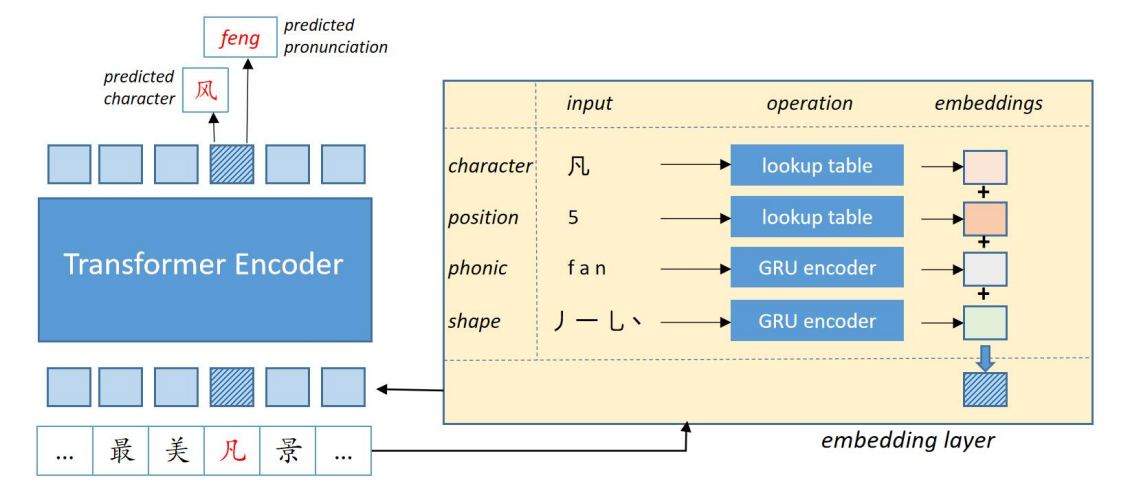 Figure 2: PLOME 프레임워크에서 빨간색으로 표시된데 마스킹된 토큰. Left: 모델의 전반적인 아키텍처. 입력 문자는 트랜스포머 인코더에 의해 처리되서 의미 표현 벡터를 얻음. Right: 트랜스포머 인코더의 final embedding을 얻기 위해 각 문자에 대해 다른 유형의 임베딩 수집
Figure 2: PLOME 프레임워크에서 빨간색으로 표시된데 마스킹된 토큰. Left: 모델의 전반적인 아키텍처. 입력 문자는 트랜스포머 인코더에 의해 처리되서 의미 표현 벡터를 얻음. Right: 트랜스포머 인코더의 final embedding을 얻기 위해 각 문자에 대해 다른 유형의 임베딩 수집
- 제안 모델은 pretraining&fine-tuning 패러다임을 따름
3.1 Confusion Set based Masking Strategy
- PLOME을 학습시키기 위해 입력 토큰의 일부를 무작위로 마스킹한 다음 복구
- [MASK] 대신 유사한 문자로 대체. 유사한 문자는 음운론적으로 유사하고 시각적으로 유사한 문자를 포함하는 공개적으로 사용 가능한 confusion set에서 얻음
- 음운 오류가 시각 오류보다 2배 더 자주 발생해서 마스킹 중에 선택될 확률이 다르게 할당
- 15%를 마스킹. dynamic masking 사용
- 항상 confusion set에서 대체하면 두 가지 문제 발생
-
사전 학습동안 예측할 모든 토큰들이 '잘못'되었기 때문에 모든 입력에 대해서 수정할게 있다고 결정하는 경향
이 문제를 방지하기 위해 선택한 토큰의 일부 비율은 변경X -
confusion set의 크기는 제한, 실제 텍스트에서 문자 쌍의 오용으로 인해 철자 오류가 발생할 수 있음
일반화 능력을 향상시키기 위해, 선택된 토큰의 일부를 무작위 문자로 대체

i번째 토큰이 선택되면 다음 확률로 대체
1. 음운론적으로 유사한 무작위 문자로 60%
2. 시각적으로 유사한 무작위 문자로 15%
3. 변경되지 않은게 15%
4. vocab에 포함된 무작위 토큰으로 10%
3.2 Embedding layer
- Figure 2와 같이, 각 문자의 final embedding은 character embedding, position embedding, phonic embedding, shape embedding 합. 앞의 두개는 BERT-base와 동일
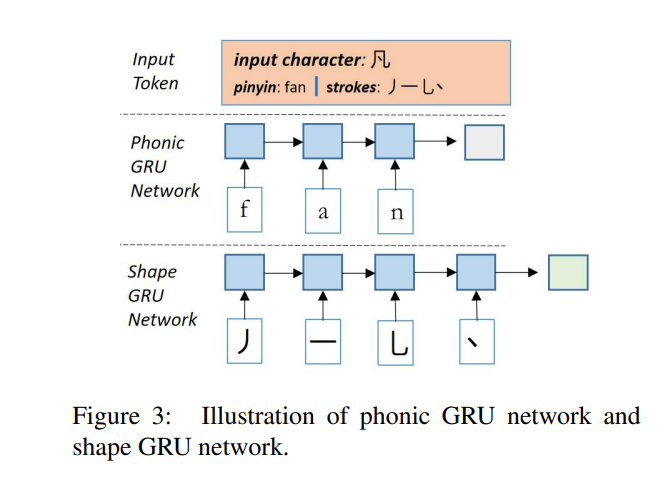
Phonic Embedding
- 문자 간의 음운 관계를 모델링하기 위해 각 문자의 음소 문자를 1-layer GRU네트워크에 공급해 유사한 음소 임베딩을 가질 것으로 예상되는 음소 임베딩 생성.(Figure 3의 중간 부분)
Shape Embedding
- 한자의 획이 쓰이는 순서를 나타내는 획순서 사용
- 문자 간의 시각적 관계를 모델링하기 위해 각 문자의 획 순서를 또 다른 1-layer GRU 네트워크에 입력해서 shape embedding 생성.(Figure 3 아래 부분)
3.4 Output Layer
- Figure 2에서, 각 선택된 character에 대해 두 가지 예측
Character Prediction - BERT와 비슷하게, PLOME는 마지막 트랜스포머 레이어에서 생성된 임베딩을 기반으로 각 마스킹된 토큰의 원래 문자를 예측
Pronunciation Prediction - 실제 철자 오류의 약 80%는 phonological임
- PLOME는 phonic(음성, 발음) 수준에서 철자가 틀린 지식을 학습하기 위해 각 마스크 토큰에 대한 실제 발음을 예측하며, 발음은 분음 부호 없이 phonics로 표시
3.6 Fine-tuning Procedure
Training
- 다음을 제외하면 사전 학습과 유사
- 마스킹X
- 사전학습에서 처럼 선택된 토큰만 예측하는게 아니라 모든 입력 문자 예측
Inference
- PLOME은 각 마스킹된 토큰에 대한 character 분포와 발음 분포를 모두 예측
4. Experiments
4.3 Baselines Models
Hybird: BiLSTM 기반 모델
PN: point network를 통합한 Seq2Seq모델
FASPell: DAEDecoder 패러다임을 채택하고 노이즈 제거 자동 인코더로 BERT사용
SKBERT: 오류 탐지 성능 향상위해 BERT에 Softmasking 전략 도입
SpellGCN: confusion set에서 문자 간의 관계를 모델링 하기 위해 GCN 네트워크와 BERT결합
- 입력 및 인코더 레이어가 BERT-base의 레이어와 동일한 baseline model인 cBERT(confusion set 기반 BERT)를 구현
- 출력 레이어는 PLOME와 유사하지만 문자 예측만 수행
- confusion set기반 마스킹 전략을 통해 사전 학습
4.4 Main Results
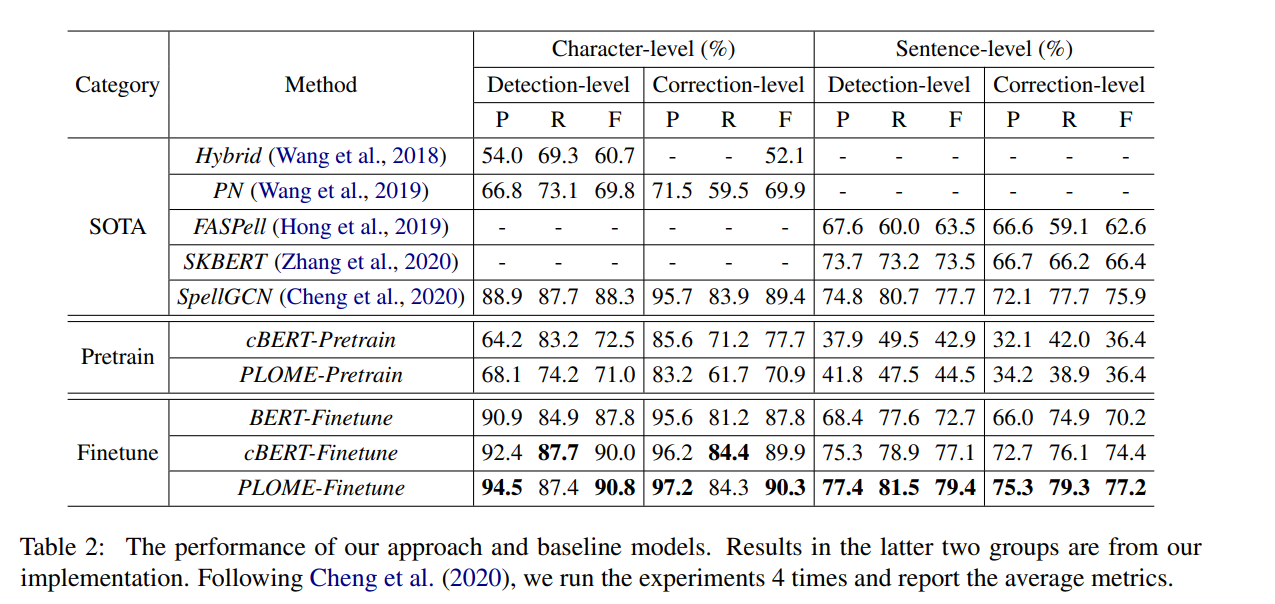
1. fine tuning없이 사전학습만된 모델은 상대적으로 좋은 결과, 심지어 supervised 접근 방식 PN을 능가
이는 confusion set기반 마스킹 전략을 통해 모델이 사전 학습 중에 작업별 지식을 학습할 수 있음
-
fine-tuning된 모델과 비교하여 cBERT는 모든 메트릭에서 BERT능가. 특히 문장 수준 평가의 F score가 절대 점수가 4점 이상 향상. 대략의 학습 데이터(281K 텍스트)로도 좋은 성과로, 제안한 마스킹 전략이 필수적인 지식을 제공하고 fine tuning으로는 학습할 수 없음을 나타냄
-
phonic과 shape embeddingㅇ르 통합한 PLOME-Finetune은 문장 수준 탐지 및 수정에서 cBERT-Finetune을 2.3% 및 2.8% 절대적인 성능 향상. 이는 character의 phonics와 획이 유용한 정보를 제공
-
SpellGCN과 동이하게 confusion set을 썼지만, 그 안에 포함된 지식을 학습하는 데는 다른 전략. SpellGCN은 이 정보를 모델링하기 위해 GCN 네트워크를 구축. PLOME은 사전 학습 중에 대규모 데이터로부터 정보 학습.
💡 Deep Learning-Based Context-Sensitive Spelling Typing Error Correction
Abstract
- 영어에는 두 가지 유형의 철자 오류 있음: non-word spelling error, 문맥에 따른 맞춤법 오류
- Non-word 맞춤법 오류는 문장의 단어와 사전에 있는 단어를 일치시키는 것만으로도 감지할 수 있어서 수정이 간단한데, 문맥에 따른 오류는 수정할 단어와 주변 문맥의 관계를 알아야 해서 수정의 난이도가 올라감
- 맞춤법 오류는 텍스트 정보를 사용하는 모든 분야에서 노이즈로 간주, 최소화하기 위해선 문서 수정을 통한 전처리가 필요.
- 문맥에 따른 맞춤법 오류는 동음이의어 오류(소리는 같은데 철자가 다른 단어), 오타 오류(키보드의 잘못 누름), 문법 오류(사용자가 올바른 문법 규칙을 모를때), 단어 간 띄어쓰기가 잘못되어서 발생하는 단어 간 경계 오류 등
- 딥러닝 기반 교정 방식은 단어 임베딩 정보, 문맥 임베딩 정보, auto-regressive(AR) 언어 모델, auto-encoding(AE) 언어 모델 등 크게 네 가지로 나뉨
- 본 논문에선 AE가 가장 우수한 성능
1. Introduction
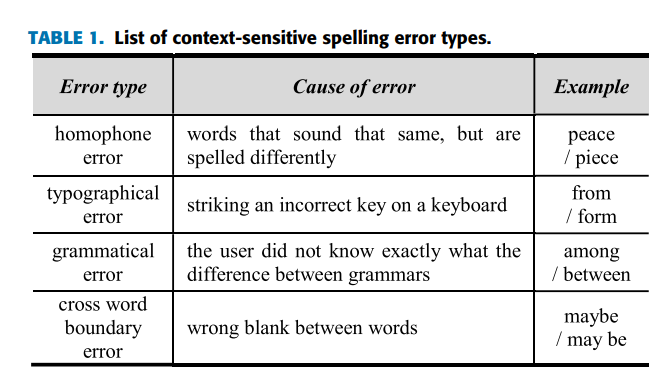
- 동음이의어 오류, 오타 오류, 문법 오류, 단어 간 경계 오류가 있음
- 본 연구에선 타이핑 에러
- 사전에 수정된 영어 문서에서 문맥에 따른 맞춤법 오류가 전체 맞춤법 오류의 30~40% 차지.
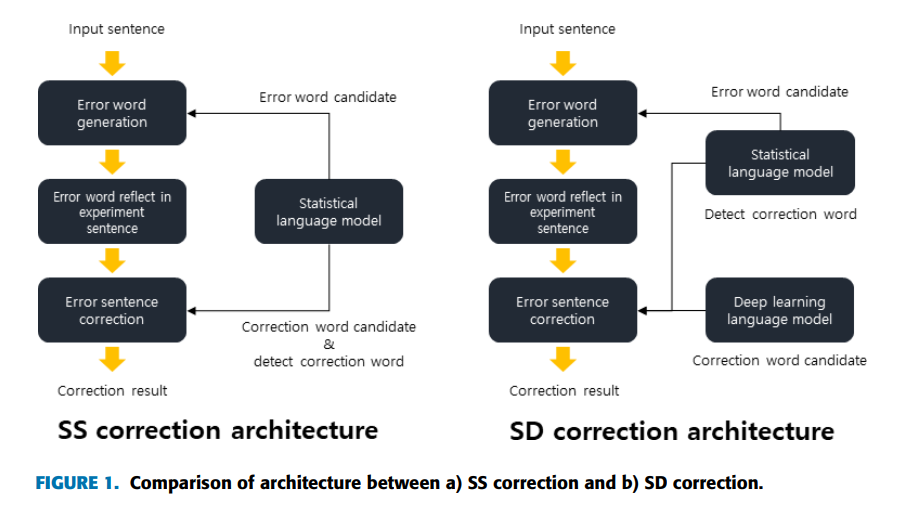
- 딥러닝 기반 수정은 규칙 기반 및 통계 방법과 같은 형태학적 접근 방식 뿐만 아니라 문맥에 대한 깊은 의미론적 이해를 얻기 위해 적용될 수 있음.
- Figure 1은 3단계로 진행되는 보정 실험의 예
- 먼저 오류 없는 문서를 입력 후, 문서에 있는 문장을 써서 정답 단어로 대체되는 오류 단어를 생성
- 그런 다음 정답 단어 대신 생성된 오류 단어를 문장에 포함해서 오류 문서 생성
- 마지막으로 오류 문서를 실제로 수정하고 성능을 측정
- 실험 문서의 생성 단계에선 오류 단어가 생성
- 수정 단계에선 오류 단어 검색, 수정 후보 단어 생성 및 최종 수정
- Figure 1(b)는 통계와 딥러닝 결합
- 통계 언어 모델은 오류 단어 생성 및 오류 단어 검색 작업 수행, 딥러닝은 오류 단어의 최종 수정 작업
- Figure 1과 같이 통계적 방법 기반 오류 검출 모델(SS),과 딥러닝 기반 수정 모델(SD)은 모두 통계적 언어 모델을 사용해 오류 단어 검색, 이는 딥러닝 언어 모델을 사용해 문서 내 오류를 검색하기 어렵기 때문
- 통계 언어 모델은 오류 검색 대상 단어의 동시 발생 단어에 대한 후보 단어만 생성해 비교
- 반면 딥러닝 모델은 대상 오류 단어를 검색할 때 딥러닝 언어 모델에서 학습한 모든 단어 고려
- 수정 문서의 전체 단어를 오류 단어로 판단해 수정을 실행해서 속도 느리고 정확도 낮음
- 본 연구에선 최근 개발된 다양한 딥러닝 언어 모델을 문맥에 따른 맞춤법 오류 교정에 적용하고, 교정 실험의 방향 제시
- 맞춤법 오류에 대한 보정 실험을 진행, 타이핑 에러 세분화 모델 성능 측정
...
