💡 Correcting Chinese Spelling Errors with Phonetic Pre-training
Abstract
- 기존 SOTA 방법은 사전 학습된 언어 모델만 사용하거나 음운 정보를 외부 지식으로 통합
- 우린 강력한 사전 학습 및 파인 튜닝 방법을 활용해 phonetic feature를 언어 모델에 통합하는 새로운 end-to-end CSC 모델 제안
- 기존 방식인 마스킹 대신 음성 특직광 그 소리과 유사한 단어로 대체
- 통합된 프레임워크에서 철자 오류 감지 및 수정을 공동으로 함슥하기 위한 adaptive weighted 제안
- 이 모델이 SIGHAN dataset에서 상당한 개선, 이전 SOTA보다 성능 뛰어남
1. Introduction
- 기존 CSC 방식은 언어 모델을 통해 철자가 틀린 문자를 감지하고 후보를 생성한 다음, 음성 모델이나 규칙을 사용해 잘못된 후보 필터링
- CSC 성능 향상 위한 연구는 주로 1) 언어 모델 개선 2) 음운 유사성에 대한 외부 지식 활용

- 언어 모델은 유창한 문장을 생성하는 데 사용되며 음성 특징을 통해 모델이 원래 단어의 발음과 다른 예측을 생성하는 것을 방지
- Figure 1과 같이 원래의 틀린 문장에는 "(de, of)"이라는 잘못된 단어 포함
- CSC모델은 "(de, of)"를 "(ying, English)"로 대체하여 그럴듯 하지만 잘못된 문장 생성
- 이 두단어의 발음은 완전히 다름. 모델은 음성적 특징을 무사하기 때문
- Soft-BERT은 BERT의 mask 매커니즘을 수정해 end-to-end CSC모델 제안.
- 하지만 이 모델은 단어 유사도 탐색에 중요한 음운 정보 사용X
- 본 논문에선 중국어 철자 교정을 위한 새로운 end-to-end 모델 제안
- 이 모델은 음성 정보를 언어 모델에 통합하고 사전 학습 및 파인 튜닝 프레임워크 활용
- 구체적으론 먼저 사전 학습된 masked language model의 learning task를 수정
- [MASK]로 대체하는 대신, 병음(중국어의 로마자 표기법의 하나) 또는 유사한 바음 문자로 대체
- 이를 통해 언어 모델이 문자와 병음 사이의 유사성 탐색 할 수 있음
- 그런 다음 두 개의 네트워크 모델로 오류 수정 데이터 파인 튜닝
- 탐지 네트워크는 각 단어의 철자 오류 확률을 예측
- 수정 네트워크는 단어 임베딩과 병음 임베딩을 융합해 입력된 확률로 수정 데이터 생성
- 통홥된 프레임워크에서 탐지 및 수정 네트워크를 공동으로 최적화
요약하자면
- 음성학적 특징을 language representatio에 통합하는 새로운 end-to-end CSC모델을 제안. 이 모델은 shared space에서 한자와 병음 토큰을 인코딩
- 음운 정보의 통합은 CSC를 용이하게 함. 벤치마크 SIGHAN 데이터셋에 대한 실험 결과는 우리의 방법이 이전의 SOTA방법보다 훨씬 뛰어난 성능을 발휘한다는 것을 보여줌
2. Related work
- Soft-BERT는 먼저 각 단어의 철자 오류 확률을 예측한 다음, 그 확률을 사용해 수정을 위한 soft mask word embedding을 수행하는 soft-masked BERT제안. 음성 정보 사용X
3. Methods
- 중국어 철자 교정 task는 철자 오류가 있을 수 있는 시퀀스 를 correct sequence 로 매핑
- 탐지와 수정 두 구성요소로 구성된 end-to-end CSC 모델 제안
- 탐지 모듈은 를 입력하여 각 문자의 철자 오류 확률 예측
- 수정 모델은 의 임베딩과 해당 병음 시퀀스 의 조합을 입력으로 받아 올바른 시퀀스 y를 예측
- 철자 오류의 확률을 가중치로 사용해 와 임베딩을 융합하는 방법 제안
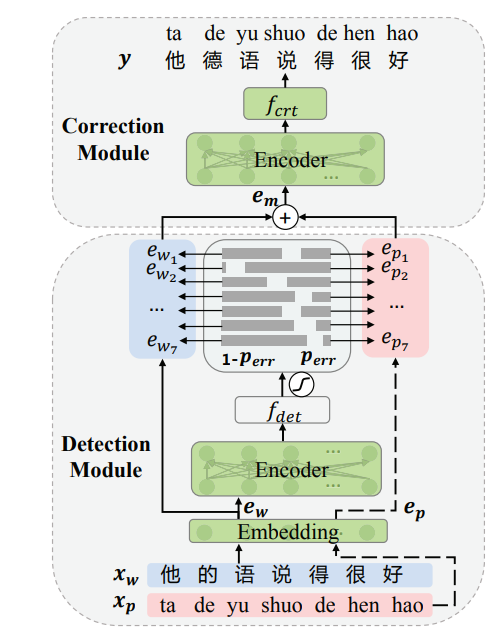
Figure 2: CSC모델 그림. 입력 단어 시퀀스 가 주어지면 먼저 탐지 모듈이 모든 문자에 대한 오류 확률 을 예측.
수정 모듈은 단어 임베딩 와 병음 임베딩 를 embedding fused 에 결합해 전송해서 final correction y를 생성.
임베딩, 인코더 및 의 매개 변수는 음성 특징이 있는 사전 학습된 언어 모델에 의해 초기화.
두 인코더의 구조와 파라미터는 동일
- 먼저 비슷한 발음의 문자와 병음에서 문자를 예측하는 학습을 통해 masked language model인 MLM-phonetics를 사전 학습.
- 그런 다음 파인 튜닝을 통해 탐지 및 수정 모듈을 공동으로 최적화
3.1 Model Architecture
- Figure 2의 밑에 부분이 error detection, 위에 부분이 correction이고 트랜스포머 기반
Detection Module
- source sequence 가 주어질 떄, detection module의 목푠 character 가 올바른지 아닌지를 확인 하는 것
- class 1과 0을 사용해 각각 철자가 틀린 문자와 맞은 문자에 레이블 지정
dtection module 식
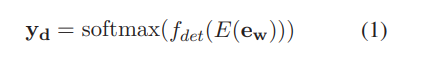
- 여기서 는 의 word embedding이고, 는 사전 학습된 인코더, 는 문장 representation을 이진 시퀀스 에 매핑하는 fully-connected layer이다
- 문자가 틀린 확률을 나타내기 위해 사용
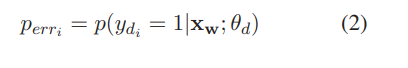
- 여기서 는 detection modul의 파라미터
Correction Module
- correction module은 detection module의 출력을 기반으로 정확한 문자 생성
- 입력에 word embedding을 사용할 뿐만 아니라 병음 임베딩을 사용해 음성 정보 통합
- 구체적으론 PyPinyin3 tool을 사용해 병음 시퀀스 생성
- 임베딩 레이어에서 병음 임베딩 를 가져와 선형 조합을 통해 단어 임베딩 와 융합(fuse)
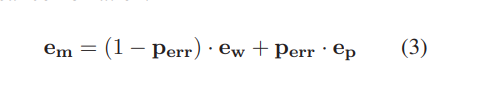
- 이 조합은 detection module에서 예측한 오류 확률을 가중치로 사용해 의미적 특징(character embedding)과 음성적 특징(병음 임베딩)의 중요도를 균형 있게 조정
두 가지 특별한 경우:
1. 인 경우, 문자가 올바른 것으로 감지되어 모델이 에 포함된 해당 단어만 사용함을 나타냄
2. 이면, 문자가 잘못된 것으로 감지되어 모델이 해당 병음 임베딩을 사용함을 의미
- 마지막으로, correction result y는 fully-connected layer 를 통해 예측
- embedding, encoder E, correction network 의 파라미터는 MLM-phonetics에 의해 초기화
- 사전 학습에서 MLM-phonetics는 일반적으로 혼동되는 문자와 병음에서 올바른 문자를 재구성하도록 학습되므로 fused embedding을 통해 변환할 수 있음
3.2 Jointly Fine-tuning
- 우리 모델의 두 가지 목표는 detection parameter 을 학습하고 최적의 균형을 이루도록 탐지 및 수정 모듈을 조정하는 것
- 이를 위해 detecion loss 와 correction loss 를 공동으로 최적화(optimize)
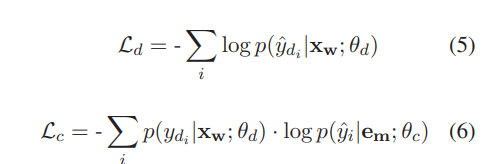
- 와 는 각각 deteciont과 correction module의 파라미터
- 는 ground truth detection result이고 는detection module에 의한 예측이며, 둘 다 0또는 1의 이진 값
- 특히 correction loss는 detecion result의 확률에 가중치를 부여한 negative log likelihood 확률인 이다
- 이는 두 작업의 책임을 구분하기 위한 것
- detection modul이 낮은 신뢰도의 예측을 주면, 즉 가 0.5에 가까워 지면, 은 의미적 특징과 음성적 특징을 비슷한 가중치로 융합(fuse)
- 하지만 detection modul이, 가 1에 가까워져(옳고 그름을 명확히 판단) 이 의미적 특징이나 음성적 특징 중 하나가 우세하길 바람
- 이 경우 오류 단어의 수정은 의 의미적 특징에 의해 간섭받지 안으며 그 반대의 경우도 마찬가지
- 따라서, detecion modul이 낮은 신뢰도를 주면 예측에 페널티 부여
- 구체적으로 detecion result의 확률이 낮으면 가 감소하고 모델은 를 최적화하는데 더 집중하게 됨
- detecion 확률이 높으면 모델은 와 를 균형 있게 최적화
- adaptive weighting 목푠 두 손실 함수의 합으로 모델을 공동으로 학습할 수 있게 함
3.3 Pre-training MLM-phonetics
- 1) 음성 feature를 통합하고 2) CSC 아키텍처에서 standard masked language를 사용할 때 발생하는 문제를 해결하는 사전 학습된 언어 모델인 MLM-phonetics 소개
- 분류나 qa같은 task는 사전학습과 동일한 분포를 보이지만, CSC의 입력 문장은 사전 학습 샘플과 다른 오류를 가짐
- 지금까지 일부 작업들은 사전 학습된 모델에 오류 문장을 직접 입력하지 않음으로 써 입력 편차를 피함
- 예를 들어, Soft-BERT는 BERT 기반 수정 네트워크 이전에 오류 감지를 위해 양방향 GRU 사용
- 사전 학습 기법을 활용하기 위해 사전 학습 작업 수정
- 입력 차이를 방지하고 음성 특징을 통합하기 위해 두 가지 사전 학습 대체물인 confused-Hanzi와 noisy-pinyin 제안. Figure 3을 통해 이러한 대체를 설명
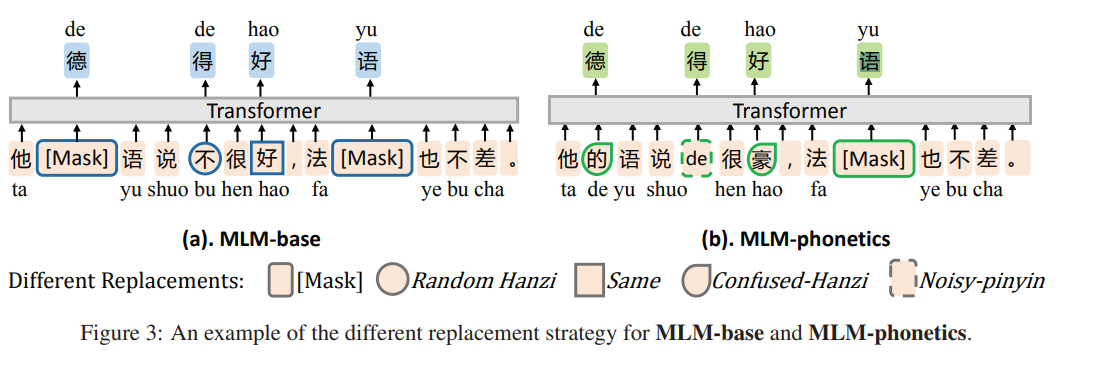
- [Mask] replacement는 문맥에 따라 마스크된 문자만 복원해 언어 모델의추런 능력 학습
- 무작위한 한자 교체(Random Hanzi replacement)는 MLM-base가 무작위 단어에서 단어를 수정하도록 학습(예: "不(bu)"에서 "得(de)"를 예측한다)
이는 발음이 비슷한 문자로 부터 정정하는 거에 비해 더 어려운 작업. 그러나 입력 분포가 다르기 때문에 이 전략은 CSC에 거의 도움X - 동일한 변경을 사용하면 MLM-base가 입력 문자(예: 대체 "好(hao))를 복사하도록 권장
- Confused-Hanzi(혼동 한자)는 replacement는 confusion set에서 일반적으로 혼동되는 문자로 단어를 수정하도록 MLM-phonetics 학습(예: "豪(hao)"에서 "好(hao)"로 예측).
모델에 오타가 있는 샘플에 엑세스할 수 있는 방법을 제공 - noisy-pinyin(노이즈 병음) replacement는 confusion set에서 일반적으로 혼동되는 문자의 병음에서 원래 문자를 예측하도록 MLM-phonetics 학습(예: "드"에서 "得(드)" 예측).
이는 비슷한 발음의 문자를 해당 병음 토큰과 함꼐 클러스터링하는데 도움
- 처음 세 가지 replacement는 표준 MLM 기반을 사전 학습하는 데 사용되며 마지막 두 개는 문자와 병음 토큰 간의 유사성을 모델링하기 위해 제안
- MLM-phonetics의 사전 학습에서 data generator는 학습 샘플에서 토큰 위치의 20%를 무작위로 선택.
- i번째 토큰이 선택되면 (1) [MASK] 토큰으로 40%, (2) noisy-pinyin으로 30%, (3) confusion-set의 혼동 한자로 30% 대체
- 그런 다음 MLM-phonetics는 대체된 문장에서 원래 문장을 예측하도록 학습
3.4 Novelty of out method
- 우리 방법은 soft-bert와 비슷하지만 다른면이 있다
- 우리 모델은 병음과 문자의 임베딩을 결함해서 정보 손실을 방지하는데, 이는 문제가 있는 단어의 발음으로 교정을 예측하는 인간의 교정 과정과 유사
soft-bert는 최종 수정을 내보내기 전에 residual connection을 추가해야 하며, 그렇지 않으면 [MASK]와 임베딩을 결함한 후 오류 단어의 음성 정보를 잊어버림 - 새로운 사전 학습 task를 제안하여 탐지 및 수정에서 사전 학습된 인코더를 공유
soft-bert는 사전 학습과 파인 튜닝 사이의 입력 차이를 피하기 위해 탐지 할 때 사전 학습되지 않은 양방향 GRU 사용 - 오류 탐지 및 수정을 공동으로 학습할 때 adaptive weighting 정책을 제안
모델이 명확한 탐지 결과를 생성하도록 장려하여 융합 임베딩이 사전 학습 작업에 가까운 의미적 또는 음성적 특징에 의해 지배되도록 함
반대로 soft-bert는 탐지 및 수정 손실을 고정 하이퍼파라미터와 선형적으로 결합할 것을 제안
4. Experiments
4.1 Data Processing
training set
1) 0.3 bilion 개의 중국어 문장으로 구성된 사전 학습 corpus
2) 281K개의 문장 쌍으로 구성된 CSC 학습 코퍼스
- 첫 번째 corpus는 MLM-phonetics를 사전 학습하는 데 사용
- 두 번째는 MLM-phonetics로 초기화된 CSC 모델을 fine-tuning하는 데 사용
- 사전 학습 코퍼스의 경우, 검색 엔진에서 백과 사전, 기사, 뉴스, 과학 논문, 영화 자막등 다양한 데이터 수집
4.2 Model Settings
FASPell
사전 학습된 MLM을 통해 입력 문장의 각 문자에 대한 후보를 생성한 다음 시각적 및 음성적 특징을 가진 필터링 모델을 사용해 최적의 후보 선택
Pointer Networks
각각의 올바른 단어가 오류 문자의 confusion set에 포함되어 있다는 제약 조건에 기반한 seq2seq 시스템
Soft-Masked BERT
문장의 각 토큰에 대해 해당 토큰의 임베딩과 [MASK]의 임베딩을 선형적으로 결합하고, 파인튜닝된 마스크 언어 모델을 기반으로 오류 문자 예측
SpellGCN
graph convolutional network를 통해 두 개의 유사도 그래프를 사전 학습된 sequence-labeling 모델에 통합. 두 그래프는 confusion set에서 파생되며 발음 및 모양 유사성에 해당
ERNIE
CSC 학습 데이터에서 표준 mask 언어 모델을 직접 파인 튜닝
MLM-phonetics
음성적 특징을 가진 사전 학습된 언어 모델을 기반으로 하는 end-to-end 시스템 사용
- Pointer Network는 인코더와 디코더 모두 LSTM 사용
- 다른 모든 방법은 사전 학습된 12-layer transformer encoder를 사용하는 시퀀스 태깅 문제로 CSC 사용
- FASPell, Soft-BERT는 사전 학습된 BERT를 사용하고, ERNIE와 MLM-phonetics는 초기화를 위해 사전 학습된 ERNIE사용
- 문장 수준과 F1-score를 사용해 시스템 평가
- 문장 수준에선 문장의 모든 오류가 감지되거나 수정된 경우에만 예측이 올바른 걸로 간주되서 점수가 낮음
4.3 Overall Results
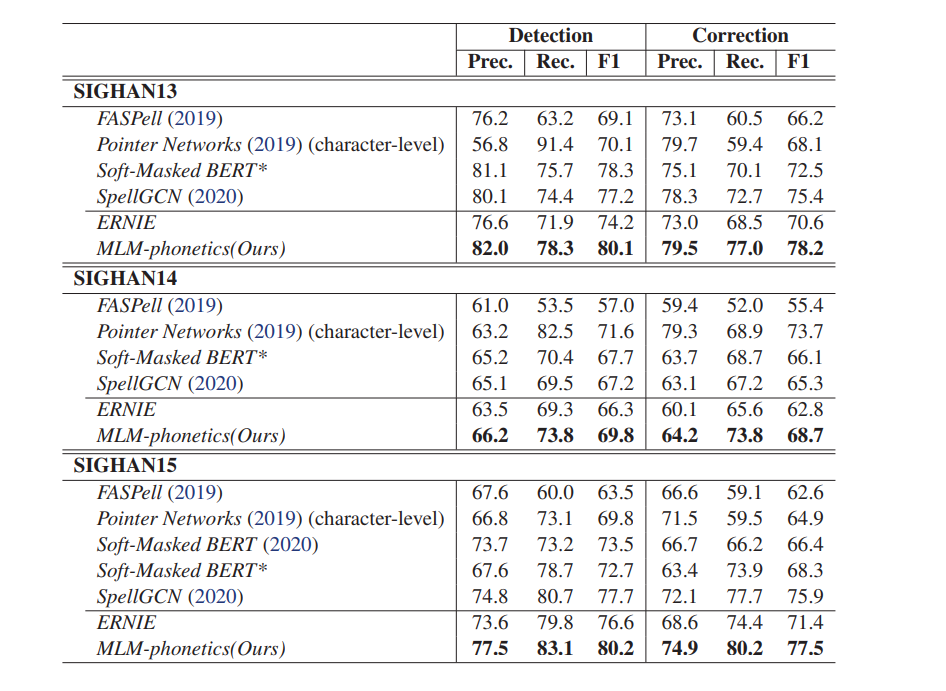
- 세 가지 SIGHAN 테스트셋에 대한 detection, correction 성능
- 문자 수준에서 결과를 제공하는 Pointer Network를 제외한 모든 방법은 문장 수준의 결과 제공
- MLM-phonetics가 다른 시스템보다 훨씬 뒤어난 성능
- SIGHAN15의 경우, Detection F1 score는 기존 최고 방법인 SpellGCN보다 2.5점 Correction F1 score는 1.6점 개선
- Correction F1 score에서 ERNIE보다 6점 이상 향상되어 사전 학습 전략 효과 입증
- Pointer Network를 제외한 모든 방법은 초기화를 위해 사전 학습된 모델을 사용하지만, FASPell, SpellGCN 및 우리의 방법만 음성 정보를 고려
- FASPell은 분리된 음성 기능과 언어 모델을 사용하기 때문에 성능이 저하 될 수 밖에 없음
- SpellGCN은 BERT 위에 graph convolutional network를 구축해 음성 지식을 언어 모델에 통합
- 효과적임은 입증되었지만 그래프는 준비된 confusion set에서 파생. 따라서 모델의 성능은 이 셋의 완성도에 따라 달라짐
- Table1에서 볼 수 있듯이 SpellGCN의 정확도는 MLM-phonetics에 가깝지만 recall에는 상당한 격차
- 추가 Pinyin token의 도움을 받아 우리의 방법은 단어 임베딩에 음성 기능을 통합하여 모델의 일반화를 높임
- Soft-BERT는 음성 특징 없이 문장을 교정. 탐지 및 수정 성능이 우리보다 떨어짐
- 이는 부분적으로 음운 유사성이 부족하고 모델 아키텍처가 다르기 때문일 수 있음
- 또한 우리 방법의 MLM-phonetics의 학습 데이터는 Point Network, SpellGCN, ERNIE의 학습 데이터와 일치하지만 Soft-masked BERT와 FASPell은 다른 학습데이터를 사용한다는 점도 주목
4.4 Pre-training Tasks
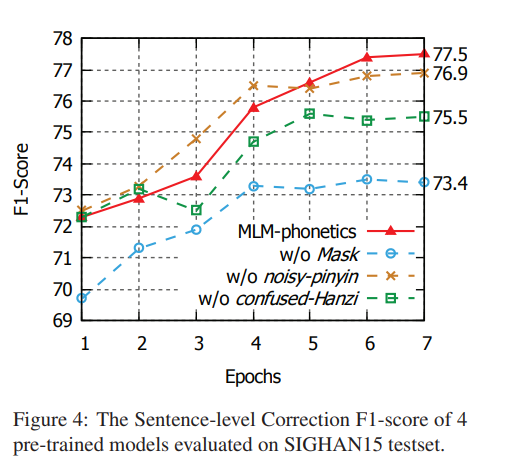
- MLM-phonetics의 사전 학습에서 세 가지 대체 task([MASK], 헷갈리는 한자, 노이즈 병음)의 효과를 분석하기 위해 세 가지 과제 중 두 가지 과제만 동일한 확률로 학습한 세가지 모델을 비교 대상으로 삼음
- 파인 튜닝 중 SIGHAN15의 테스트 곡선을 Figure 4에 표시
- MLM-phonetics는 7번 째 epoch에서 f1-score 77.5점을 달성해 최고의 성능 보여줌
- 처음에 Noisy-pinyin을 사용하지 않고 사전 학습한 모델보다 성능이 떨어짐
- 이는 사전 학습과 파인 튜닝의 불일치로 인해 발생
- noisy-pinyin이 없는 모델은 사전 학습에서 [MASK]와 헷갈리는 한자에서 원래 문자를 예측하는 것만 학습
- 그래서 병음 임베딩은 파인 튜닝 전까지 초기화되지 않음
- 따라서 병음 임베딩은 파인 튜닝 단계의 임베딩 융합에서 노이즈로 볼 수 있음
- 이러한 임베딩은 사전 학습 입력 분포에 가깝기 때문에 노이즈 병음이 없는 사전 학습된 모델은 처음에 좋은 성능을 보임
- 반면 MLM-phonetics는 사전 학습에서 한자 임베딩 또는 병음 임베딩을 기반으로 단어를 재구성하도록 학습
- 그러나 파인 튜닝에서 두 가지를 융합하여 예측해야 하므로 적응을 위한 더 긴 학습 시간이 필요
- 학습이 계속됨에 다라 모델은 임베딩 융합의 이점을 얻고 최종적으로 노이즈 병음 없이 사저 학습된 모델보다 0.6점 개선(76.9->77.5)된 결과 달성
- 게다가, 다른 두 개의 사전 학습된 모델은 상대적으로 낮은 성능
- Confused-Hanzi가 없는 사전 학습 모델은 사전 학습 및 라인 튜닝에서 입력 편차가 발생
- 이 모델은 파인 튜닝단계까지 철자 오류에서 단어를 수정하도록 학습X
- w/o [MASK]는 성능이 최악으로 의미 이해도를 높이기 위해 [MASK] 예측을 사용하는 게 중요하다
4.5 Balance the objective of detection and correction
- 파인 튜닝에서 두 가지 목표의 균형을 맞추는 가주이 전략의 영향 살펴보기
- CSC 모델에선 탐지와 수정 모두 sequence labeling task
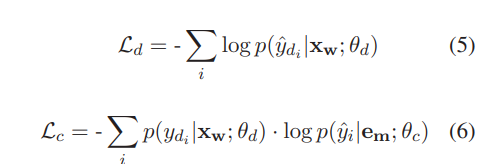
- 식 6과 같이 탐지 확률을 사용해 두 작업의 균형을 맞춤
- 반대로 Soft-BERT는 고정된 하이퍼 파라미터로 두 작업의 균형을 맞춤: 는 가중치가 없는 correction의 negative log-likelihood
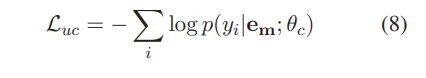
- 우리 방법이 고정 하이퍼 파라미터 결봐 보다 나음
- 고정된 하이퍼 파라미터를 가진 세 시스템 중 λ=0.8이 가장 높은 correction F1-score 달성, λ=0.5인 시스템이 가장 높은 detection f1-score 달성
- detection f1-score는 detection module의 예측이 아닌 수정 결과(즉, 수정된 문자만 감지된 것으로 간주)를 기반으로 평가. 따라서 λ =0.2로 설정하면 탐지 비용이 많이 들지만 detection f1-score가 가장 낮다는 것은 이상한 일이 아님
- 이는 또한 감지와 수정을 조절해야 한다는 힌트 제공
- λ =0.2로 설정하면 detecion module의 성능은 향상될 수 있지만 correction module이 좋지 않으면 최종 detecion 성능이 저하
...
4.6 Error Analysis
- 예측 오류를 분석하기 위해 잘못 예측된 샘플 수집해 두 가지 클래스로 분류
Detecion Error
감지 모듈이 오류 예측 생성(예: )
Correction Error
감지 모듈이 올바른 예측을 생성하지만 수정 모듈이 올바른 문자를 생성X (예:,
- SIGHAN15 테스트셋의 두 클래스를 요약하면 오류와 수정 오류의 비율은 각각 83.6%와 16.4%, 이는 잘못된 예측의 대부분이 감지 오류임을 나타냄
- 낮은 탐지 성능은 주로 많은 오류를 감지할 수 없기 때문일까요(false negative error), 아니면 탐지 모듈이 오류를 잘못 예측하기 때문일까요(false positive error)?
83.6%의 탐지 오류를 두 가지 유형으로 분류한 결과, false negative error, false positive error가 각각 41.1%, 42.5%를 차지 - 두 오류 유형의 비율은 거의 동일, 가능한 이유는 "的", "地", "得" 같은 일부 동음이의어가 구별X
- 세 글자 모두 '드'라는 발음을 가지고 있으며 음성적으로나 의미론적으로 많은 문장에서 이러한 후보 중 하나를 사용하는 것이 합리적
- 이는 구별 불가능성을 줄이기 위해 추가 파인튜닝이 필요
- 이 경우 탐지 모듈은 ground-truth results와 다른 많은 예측을 생성해 탐지 성능에 영향을 미침
5. Conslusion
- 본 논문에선 음성 사전 학습을 통해 CSC용 end-to-end 프레임워크 제안
- 기존 파이프라인 시스템에서 영감을 얻은 이 모델은 문자의 음성 정보를 사전 학습에 통합
- 먼저 음성 특징이 있는 마스크 언어 모델을 사전 학습해 철자가 틀린 문장을 이해하는 모델의 능력을 향상시키고 문자와 병음 토큰 간의 유사성을 모델링
- 또한 하나의 모델에 감지 및 수정 기능을 통합하는 end-to-end 프레임워크 제안
- 벤치마크 데이터셋에 대한 실험 결과, 저희 모델이 SOTA보다 훨씬 뛰어난 성능을 발휘하는 것으로 나타남
- 음성 특징이 있는 CSC 모델은 음성 인식 및 번역 시스템의 오류를 줄이는 데 사용할 수 있음
