딥러닝 학습 중 EarlyStopping 콜백 동작에서 의문이 하나 생겼다.
" 같은 모델, 같은 학습 조건인데 ..
Adam을 쓰면 중간에 멈추고,
SGD를 쓰면 끝까지 100 epoch 다 돌아버리네? "
이 글에서는 왜 이런 차이가 발생하는지, 왜 SGD에서는 EarlyStopping이 작동하지 않는 것처럼 보이는 건지 (아니면 혹시 정말 작동하지 않는 건지)
이를 확인하고 이해하는 과정을 기록해 보았다.
EarlyStopping이란?
EarlyStopping은 모델이 더 이상 성능이 좋아지지 않는 시점에서 학습을 멈추는 전략이다.
과적합을 막고, 학습 시간을 단축하는 데 유용하게 작용한다.
from tensorflow.keras.callbacks import EarlyStopping
"""
- monitor: 모니터링 대상 (보통 'val_loss' 또는 'val_accuracy')
- patience: 개선되지 않아도 기다릴 epoch 수
- restore_best_weights: 가장 성능 좋았던 시점의 가중치 복원
"""
early_stopping_cb = EarlyStopping(
monitor='val_loss',
patience=10,
restore_best_weights=True
)문제 상황 요약
같은 모델, 같은 데이터, 동일한 EarlyStopping 설정을 사용했는데도 Adam은 중간에 학습이 멈추고, SGD는 유독 끝까지 학습이 진행되는 것을 볼 수 있었다. 겉으로 보기엔 Adam에서는 EarlyStopping이 작동하고, SGD는 무시하는 것처럼 보일 수 있지만 실제로 그런 건 아닐 것 같아 확실하게 짚고 넘어가고자 했다.
결론부터 이야기하자면,
EarlyStopping은 Adam과 SGD 모두 동일한 기준으로 동작한다. 다만, 그 조건을 누가 더 빨리 만족시키느냐의 차이라는 것을 알 수 있었다.
- Adam은 파라미터별로 학습률을 자동 조절(adaptive learning rate)하며, 모멘텀까지 활용해 빠르게 수렴한다. validation loss가 빠르게 줄고 plateau를 형성하면서 EarlyStopping이 쉽게 트리거된다.
- 반면 SGD는 학습률이 고정되어 있고 초기 수렴이 느리다. validation loss는 천천히 감소하거나 출렁거리면서, EarlyStopping이 감지할 수 있을 만큼 충분히 안정적인 개선 패턴을 보이지 않는다.
EarlyStopping이 작동하지 않는 게 아니라 멈출 만한 조건이 만들어지지 않았을 뿐이다.
아래에서 실제 로그와 그래프를 분석하여 이를 확인해 보았다.
Adam vs SGD
Adam과 SGD는 자주 사용되는 대표적인 옵티마이저다. 이 둘의 학습 특성은 EarlyStopping이 작동하는 방식에 큰 영향을 준다.
-
학습률
- Adam: 학습률을 파라미터별로 자동 조절. 초반부터 빠르게 손실 감소.
- SGD: 학습률 고정. 일반적으로 낮게 설정됨. 한 번의 업데이트 크기가 작고 수렴 속도도 느림.
-
초기 수렴 속도
- Adam: 몇 epoch만에 빠르게 손실 감소, plateau 상태 도달이 빠름.
- SGD: 느리게 손실 감소. plateau에 도달하려면 더 많은 epoch 필요.
-
Validation Loss 패턴
- Adam: 손실이 급격히 줄고, 이후 plateau 상태 또는 진동 발생. EarlyStopping이 감지하기 쉬움.
- SGD: 손실이 서서히 줄고, 진동도 적음. 개선 폭이 작아 변화가 없는 것처럼 보이기도 함.
-
EarlyStopping 반응
- Adam: plateau가 뚜렷해서 EarlyStopping 기준을 쉽게 만족함.
- SGD: 손실이 계속 조금씩 줄거나 출렁여서, 기준을 충족하지 못할 수 있음.
왜 SGD는 EarlyStopping이 잘 안 되는 것처럼 보일까?
1. 수렴이 느림
SGD는 고정된 학습률로 매 epoch 이동하므로 수렴이 느리다. val_loss가 감소해도 그 속도가 느려서 patience 조건을 충족하지 못할 수 있다.
2. 진동이 적음
SGD는 모멘텀이 없으면 최솟값 근처에서 진동이 크지 않다. 오히려 줄어드는 듯한 패턴을 유지해서 EarlyStopping이 작동하지 않을 수 있다.
3. 작동은 하지만 티가 안 남
기술적으로는 EarlyStopping이 동작하고 있다. 단지, val_loss가 개선되지 않은 상태가 계속되지 않아서 트리거가 안 되는 것뿐이다.
실험: val_loss 시각화
이 그래프는 동일한 모델 구조와 학습 조건에서 Adam과 SGD만 바꿔 학습시킨 결과를 시각화한 것이다. validation loss의 변동을 시각화하여 EarlyStopping의 작동을 확인하고자 하였다.
import matplotlib.pyplot as plt
def plot_val_loss(history_adam, history_sgd):
plt.figure(figsize=(10, 5))
plt.plot(history_adam.history['val_loss'], label='Adam - val_loss', color='blue')
plt.plot(history_sgd.history['val_loss'], label='SGD - val_loss', color='orange')
plt.xlabel('Epochs')
plt.ylabel('Validation Loss')
plt.title('EarlyStopping Behavior: Adam vs SGD')
plt.legend()
plt.grid(True)
plt.show()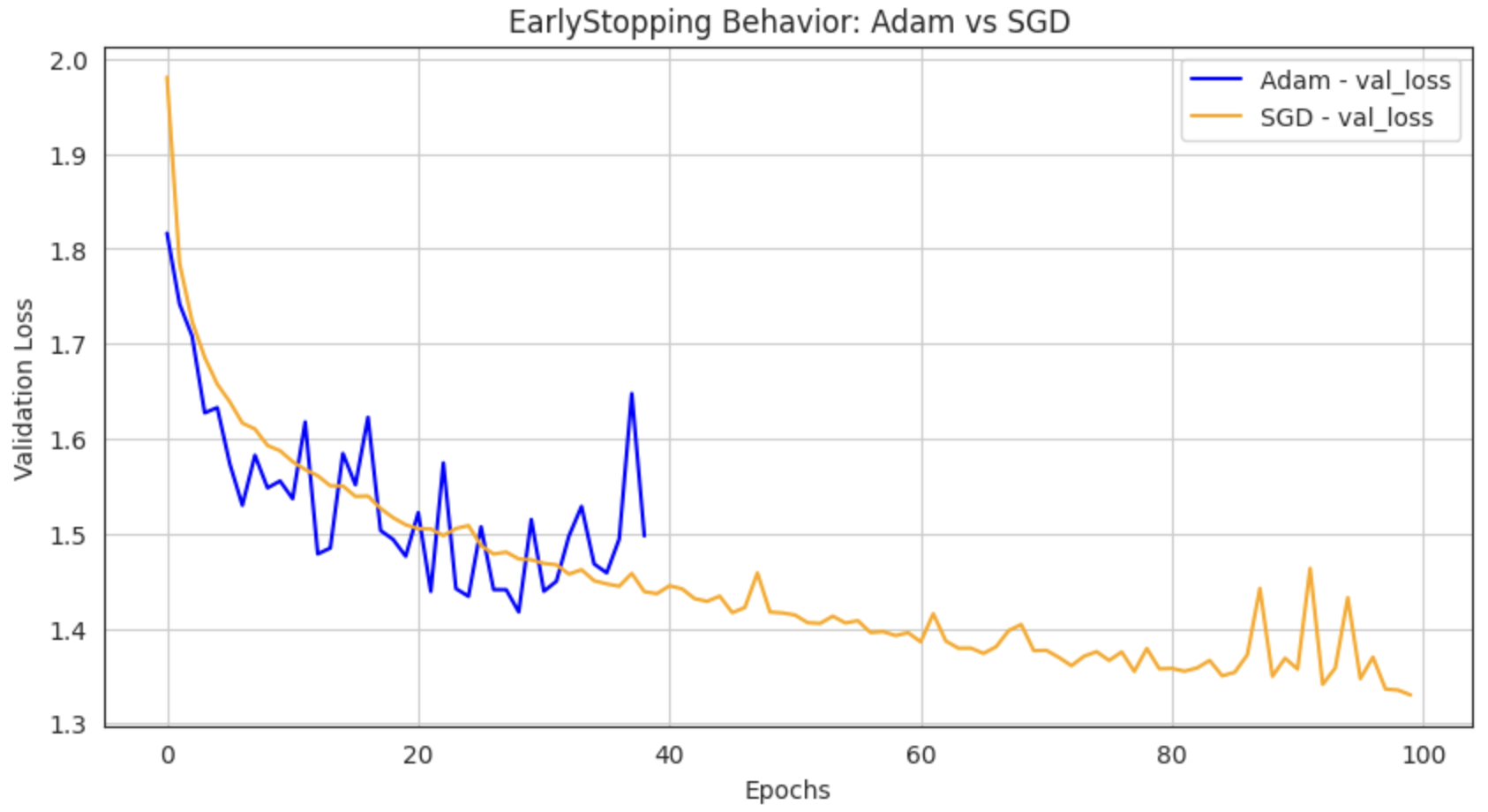
그래프 해석
실제 학습 로그와 (길어서 따로 첨부하진 않음)
그래프를 분석하여 val_loss와 EarlyStopping 작동 관계를 해석해 보았다.
1. Adam 해석
- Epoch 1~7: val_loss가 1.81 → 1.52까지 빠르게 감소
- Epoch 8~12: 일시적으로 증가하거나 진동하는 구간
- Epoch 13~29: 다시 감소해 최저점 1.4175 도달
- Epoch 30~39: val_loss가 다시 증가 또는 정체 →
patience=10조건 만족 → EarlyStopping 작동
→ Adam은 빠르게 수렴하고 이후 일정 구간에서 개선이 없는 상태가 이어져 조기 종료됨
2. SGD 해석
- Epoch 1~20: val_loss가 1.98 → 1.50 수준까지 점진적으로 감소
- Epoch 21~40: 감소세가 유지되며 1.43대까지 도달함
- Epoch 41~60: 미세한 진동과 함께 1.39~1.41 수준 유지
- Epoch 61~100: 최저점 1.33 수준까지 계속 개선됨 → EarlyStopping 작동 조건 미충족
→ SGD는 전체 학습 내내 val_loss가 조금씩 줄어들며 plateau 없이 미세 개선이 지속됨
→ EarlyStopping은 조건이 충족되지 않아 작동하지 않았음
EarlyStopping 로그로 확인하기
EarlyStopping로 작동 여부를 확인할 수 있다.
이 글에서는 SGD를 적용했을 때 작동하지 않는 것처럼 보이는 원인을 알고 싶었던 것이기 때문에 간단하게 설명하고 넘어가겠다.
early_stopping_cb = EarlyStopping(
monitor='val_loss',
patience=10,
verbose=1, # 학습 중 중간 로그 출력
restore_best_weights=True # 성능이 가장 좋았던 에폭의 가중치로 자동 복원 + 로그 출력
)학습 중 다음 메시지가 보이면 EarlyStopping이 실제로 작동한 것이다.
Epoch 30: early stopping
Restoring model weights from the end of the best epoch: 20.이 로그가 없다면 조건이 충족되지 않았다는 뜻이다.
즉, EarlyStopping은 항상 작동 중이며 조건을 기다리고 있는 중이다.
다른 옵티마이저는 어떨까?
지금까지 대표적인 두 옵티마이저인 Adam과 SGD의 EarlyStopping 작동 차이에 초점을 맞추어 비교해 보았다.
추가적으로 RMSprop, Adagrad, Nadam 등의 옵티마이저는 Adam처럼 빠른 수렴을 유도하기 때문에 대부분 EarlyStopping이 잘 작동하는 편이다. 고전적인 SGD는 세밀한 튜닝 없이는 조건을 만족시키기 어려워 조기 종료가 잘 되지 않는 것처럼 보일 수 있는 것이다.
그 사이의 성격을 지닌 옵티마이저와 특징을 간단하게 정리해 보았다.
| 옵티마이저 | 특징 | EarlyStopping 반응 가능성 |
|---|---|---|
| RMSprop | Adam의 전신, 학습률 자동 조정 | 빠르게 수렴 → 잘 작동 |
| Adagrad | 희소 데이터에 유리, 학습률 빠르게 감소 | plateau 빨리 오면 작동함 |
| Nadam | Adam + Nesterov 모멘텀 | 빠르고 진동 적음 → 잘 작동 |
| SGD + momentum | 진동 완화, 일반화 성능 높임 | 튜닝하면 잘 작동 가능 |
💡 EarlyStopping이 작동하는지는 옵티마이저 자체보다는 수렴 특성과 손실 곡선 형태에 더 큰 영향을 받는다.
💡 옵티마이저를 선택할 때는 정확도 외에도,
학습 곡선의 형태와 EarlyStopping이 정상 작동할 수 있는지까지 고려하는 것이 중요하다.
인사이트 및 회고
EarlyStopping은 Adam, SGD 구분 없이 항상 작동하는데, 옵티마이저의 차이는 작동 조건을 얼마나 빨리 만족시키느냐에 있다는 것을 알 수 있었다.
Adam은 수렴이 빠르고 손실의 진동이 커서 조건을 조기에 만족시키는 경우가 많고, SGD는 손실이 완만하게 감소하기 때문에 조건을 만족시키지 못한 채 계속 학습되는 것처럼 보일 수 있는 것이다.
EarlyStopping이 작동하지 않는다고 무조건 문제라고 단정 짓지 말고, 그 작동 메커니즘을 이해하고 해석하는 시각을 갖추는 것이 중요하다는 생각이 들었다.
결국 모델 학습의 효율성을 높이려면 EarlyStopping을 비롯한 설정을 학습 과정의 피드백으로 활용하는 능력이 필요하겠다.
