🖇 차원 축소
🖇 차원 축소 전 처리: 스케일링
🖇 PCA
🖇 Incremental PCA
🖇 Sparse PCA
🖇 Kernel PCA
🖇 Truncated SVD
비지도학습은 정답(label) 없이 주어진 데이터를 학습하는 방식이다. 지도학습처럼 정답을 기준으로 예측 모델을 만드는 것이 아니라, 데이터 안에 숨어 있는 패턴이나 구조를 스스로 찾아내는 것에 초점을 둔다. 대표적인 비지도학습 방법에는 군집화(Clustering)와 차원 축소(Dimensionality Reduction)가 있다.
군집화(Clustering)는 데이터 간 유사성을 기반으로 비슷한 데이터들을 그룹으로 묶는 방식이다. 예를 들어, 고객 데이터를 나이와 구매 패턴을 기준으로 군집화하면 유사한 성향의 고객 그룹을 찾을 수 있다.
차원 축소(Dimensionality Reduction)는 데이터의 특성(feature) 수를 줄이면서도 중요한 정보는 최대한 보존하는 방식이다.
이 글에서는 차원 축소에 집중하여 다양한 기법을 소개하고 그 의미와 활용 목적을 함께 정리해 보았다.
자세한 실습 과정 및 출력 결과는 GitHub repository에서 확인할 수 있다.
🖇 차원 축소
차원 축소는 말 그대로 데이터의 차원을 줄이는 작업이다.
여기서 차원이란 데이터의 특성(feature) 수를 의미한다. 예를 들어, 어떤 데이터셋이 10개의 변수로 구성되어 있다면 이 데이터는 10차원 공간에 존재한다고 볼 수 있다.
차원 축소는 이런 고차원 데이터를 2차원, 3차원 등 더 낮은 차원으로 줄이면서 정보 손실을 최소화하는 방식으로 변환하는 것이 핵심이다.
왜 차원 축소가 필요한가?
데이터의 차원이 높아질수록 다음과 같은 문제가 생길 수 있다.
-
과적합 위험이 커진다. 모델이 학습해야 할 변수 수가 많아지면 데이터에 포함된 잡음(noise)까지 학습하게 되는 경우가 많다.
-
계산 비용이 증가한다. 고차원 데이터는 연산량이 많아져 학습 속도가 느려지고 리소스 소모가 커진다.
-
시각화가 어려워진다. 사람이 직관적으로 이해할 수 있는 시각화는 대부분 2차원이나 3차원 수준이기 때문에 고차원 데이터는 시각적으로 구조를 파악하기 어렵다.
차원 축소는 이러한 문제를 완화하고, 데이터의 구조를 더 잘 이해할 수 있도록 도와준다.
🖇 차원 축소 전 처리: 스케일링
차원 축소를 적용하기 전에는 데이터의 스케일을 맞추는 것이 중요하다.
변수마다 값의 범위가 다르면 분산 기반으로 계산되는 차원 축소 결과가 왜곡될 수 있기 때문이다. 만약 어떤 변수는 0~1 사이의 값을 가지는데 다른 변수는 0~1000의 범위를 가진다면, 후자의 영향이 지나치게 커질 수 있다.
이처럼 특성별로 데이터 스케일이 다를 경우 머신러닝 모델이 원활하게 작동하는 데 어려움을 겪을 수 있어 데이터 스케일링을 통해 데이터 값의 범위나 분포를 같게 만들어줘야 한다.
따라서 평균을 0, 표준편차를 1로 맞추는 표준화(Standard Scaling) 작업을 먼저 진행한다.
데이터 로드 및 확인
# 라이브러리 불러오기
import pandas as pd
# 와인 데이터 불러오기
from sklearn.datasets import load_wine
dataset = load_wine()
data = pd.DataFrame(dataset.data, columns=dataset.feature_names)
# 데이터 샘플 확인
print(data.shape)
data.head()스케일링
스탠다드 스케일링은 데이터 스케일링의 한 종류로서 데이터가 표준 정규 분포를 갖도록 스케일링한다.
# 스탠다드 스케일링
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data = scaler.fit_transform(data)
data[:3]
# 데이터 복사
df = data.copy()🖇 PCA
PCA는 데이터의 분산을 기준으로 가장 중요한 축을 찾아 데이터를 그 축에 투영함(선형 투영 기법)으로써 차원을 줄이는 방식이다.
PCA의 작동 원리
- 첫 번째 주성분(PC1)은 데이터의 분산이 가장 큰 방향을 의미한다.
- 두 번째 주성분(PC2)은 첫 번째 축과 직교하면서 분산이 두 번째로 큰 방향이다.
- 이 과정을 원하는 차원 수만큼 반복한다.
결과적으로, 원래의 변수 공간을 서로 직교하고 분산을 잘 설명하는 새로운 축(주성분) 공간으로 바꾸는 것이다.
데이터의 차원이 증가할 수록 거리가 증가하고, 오버피팅 가능성이 커진다는 것에 주의해야 한다.
# 라이브러리 불러오기
from sklearn.decomposition import PCA
# PCA
pca = PCA(n_components=2)
# PCA 변환
df = pca.fit_transform(df)
# 데이터 크기 확인
df.shape
# 샘플 데이터 확인
df[:3]PCA(2차원) 시각화
# 시각화 라이브러리 불러오기
import matplotlib.pyplot as plt
# 데이터 프레임 변환
df = pd.DataFrame(df)
df.head()
# scatter
plt.scatter(df.iloc[:, 0], df.iloc[:, 1])
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.show()
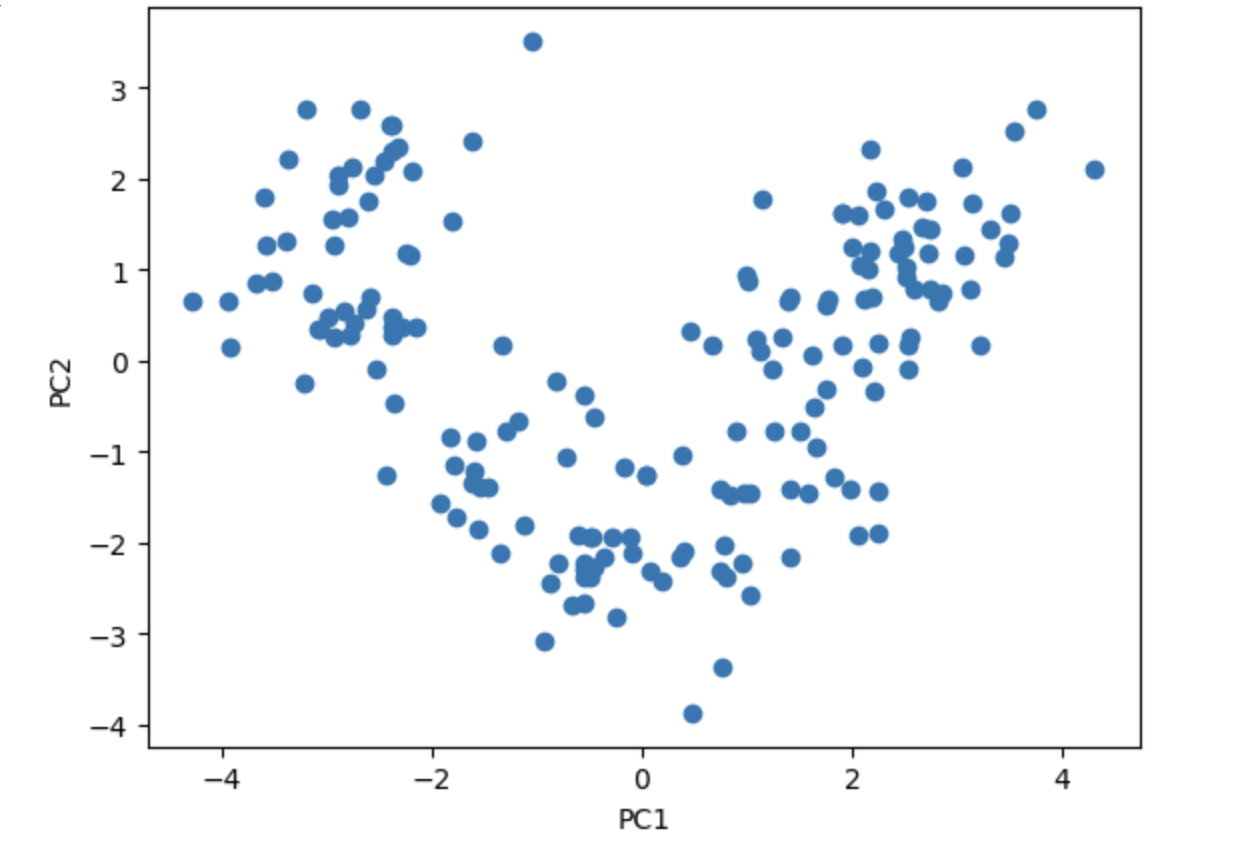
PCA 결과에서 주성분의 부호(+, -)는 라이브러리나 계산 방식에 따라 달라질 수 있다. 이는 해석에 영향을 주는 것은 아니다. 양의 방향이든 음의 방향이든 동일한 축으로 간주하며 설명하는 분산은 똑같기 때문이다.
시각화에서만 방향을 맞추고 싶다면 부호만 반전시키면 된다.
# scatter (c=target)
plt.scatter(df.iloc[:, 0], df.iloc[:, 1], c=dataset.target)
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.show()# 데이터 설명(%)
print(pca.explained_variance_ratio_) # PC1 PC2
print(pca.explained_variance_ratio_.sum()) # 설명력 합[0.36198848 0.1920749 ]
0.5540633835693526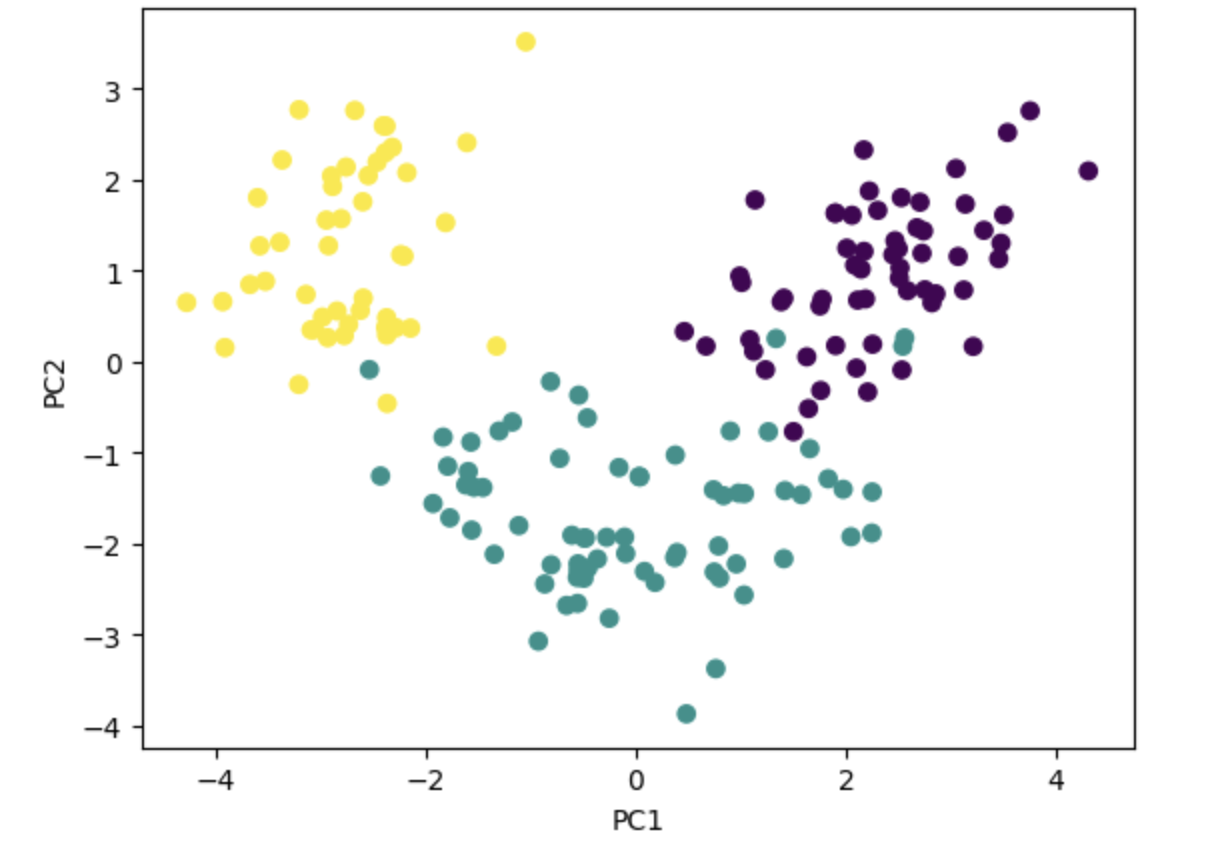
PCA 전후 비교 (vs 지도 학습)
PCA를 적용하여 피처 수를 줄인 뒤에도 모델의 예측 성능이 유지되는지를 확인할 수 있다.
일반적으로 원본 데이터보다 약간 낮은 성능을 보일 수 있으나, 그만큼 모델이 단순해지고 과적합 위험도 줄어든다.
# PCA 후 데이터로 머신러닝 (피처 2개)
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
model = RandomForestClassifier(random_state=2022)
score = cross_val_score(model, df, dataset.target, scoring='accuracy', cv=5)
print(score.mean())0.9492063492063492# PCA 전 데이터로 머신러닝 (피처 13개)
score = cross_val_score(model, data, dataset.target, scoring='accuracy', cv=5)
print(score.mean())0.9553968253968254- 원본 데이터(13개 피처)를 사용했을 때의 분류 정확도: 약 95.5%
- PCA를 통해 2개 피처로 줄였을 때의 분류 정확도: 약 94.9%
정확도의 차이가 크지 않고 모델은 더 단순해졌으며, 시각화나 해석이 쉬워졌다는 점에서 PCA는 충분히 가치가 있다.
PCA(3차원) 시각화
2차원으로는 구조가 잘 드러나지 않는 경우 PCA를 통해 3차원으로 축소한 후 시각화하는 방식도 있다.
특히 클래스 간 경계가 명확한 데이터라면 3차원 시각화를 통해 데이터의 분포와 군집 구조를 더 잘 이해할 수 있다.
# 새 데이터 복사
df = data.copy()
# PCA (n_components=4)
pca = PCA(n_components=3)
# PCA 변환
df = pca.fit_transform(df)
# 데이터 프레임 변환
df = pd.DataFrame(df)
# 시각화 (3차원)
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(df.iloc[:, 0], df.iloc[:, 1], df.iloc[:, 2], c=dataset.target)
plt.show()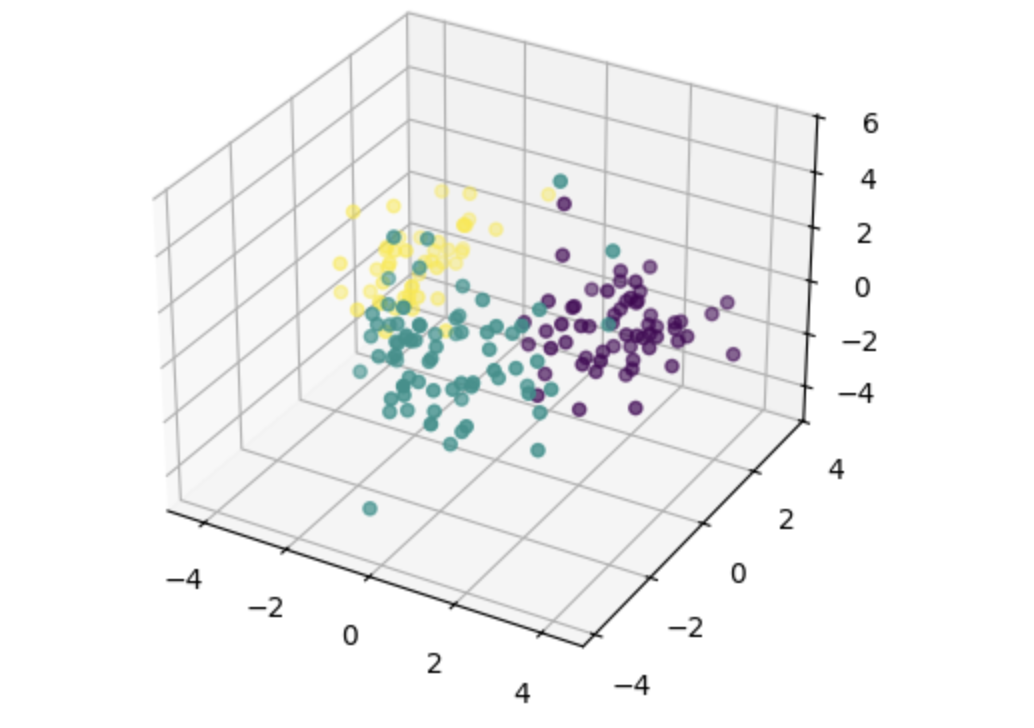
PCA 외에도 데이터 특성과 목적에 따라 사용할 수 있는 다양한 차원 축소 기법들이 존재한다.
🖇 Incremental PCA
일반 PCA는 한 번에 모든 데이터를 메모리에 올려야 하는데, Incremental PCA는 데이터를 배치(batch) 단위로 처리할 수 있어 대용량 데이터셋에 유리하다.
설명력은 일반 PCA보다 다소 낮지만 대용량 데이터를 처리할 때 활용도가 높다.
# 라이브러리 불러오기
from sklearn.decomposition import IncrementalPCA
# 데이터 복사
df = data.copy()
# 점진적 PCA
pca = IncrementalPCA(n_components=2, batch_size=16)
# 점진적 PCA 변환
df = pca.fit_transform(df)
# 시각화
df = pd.DataFrame(df)
plt.scatter(df.iloc[:, 0], df.iloc[:, 1], c=dataset.target)
plt.show()
# 데이터 설명(%)
print(pca.explained_variance_ratio_)
print(pca.explained_variance_ratio_.sum())[0.3400206 0.15239134]
0.4924119400154383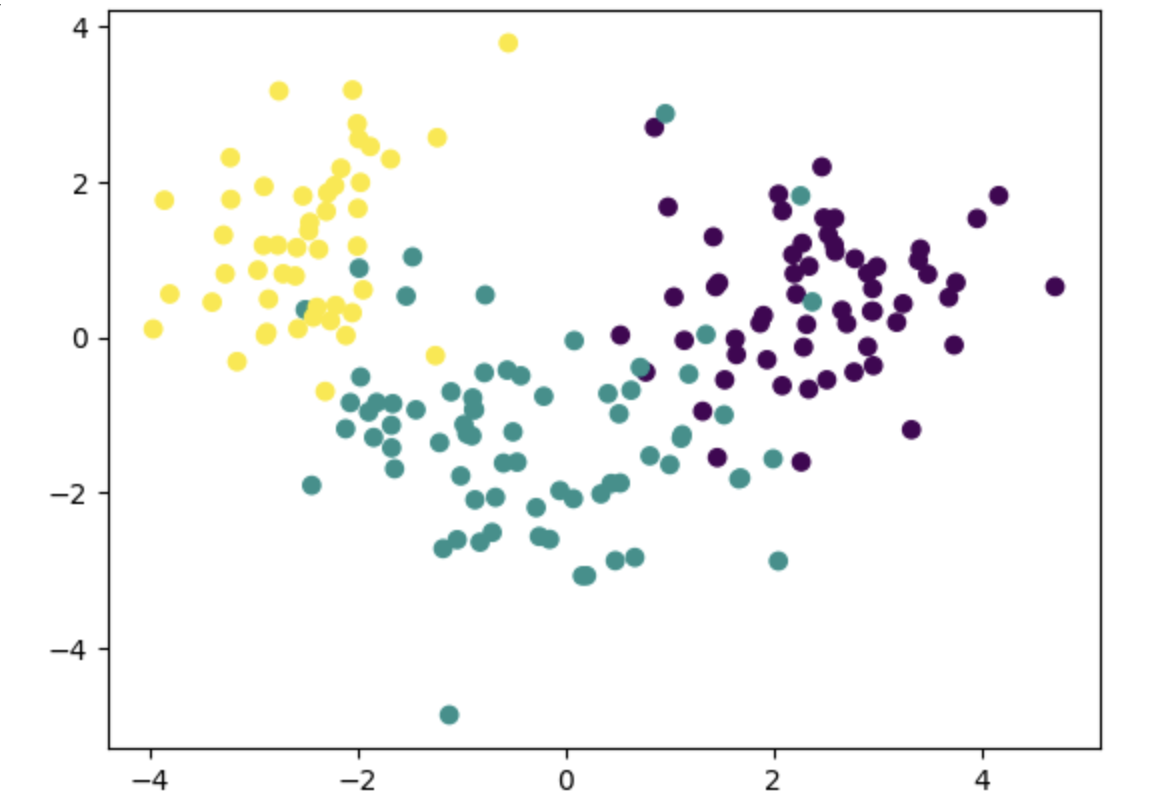
설명력이 조금 떨어지 것을 확인할 수 있다.
하지만 매우 큰 데이터를 활용할 때는 굉장히 유용하게 작용할 수 있다.
🖇 Sparse PCA
일부 주성분의 값이 0이 되도록 유도한다.
이렇게 하면 해석이 쉬워지고 과적합 방지에도 효과적이다.
alpha 파라미터를 조정하여 희소성 정도를 설정할 수 있다.
# 라이브러리 불러오기
from sklearn.decomposition import SparsePCA
# 데이터 복사
df = data.copy()
# 희소 PCA
pca = SparsePCA(n_components=2, alpha=0.01)
# 희소 PCA 변환
df = pca.fit_transform(df)
# 시각화
df = pd.DataFrame(df)
plt.scatter(df.iloc[:, 0], df.iloc[:, 1], c=dataset.target)
plt.show()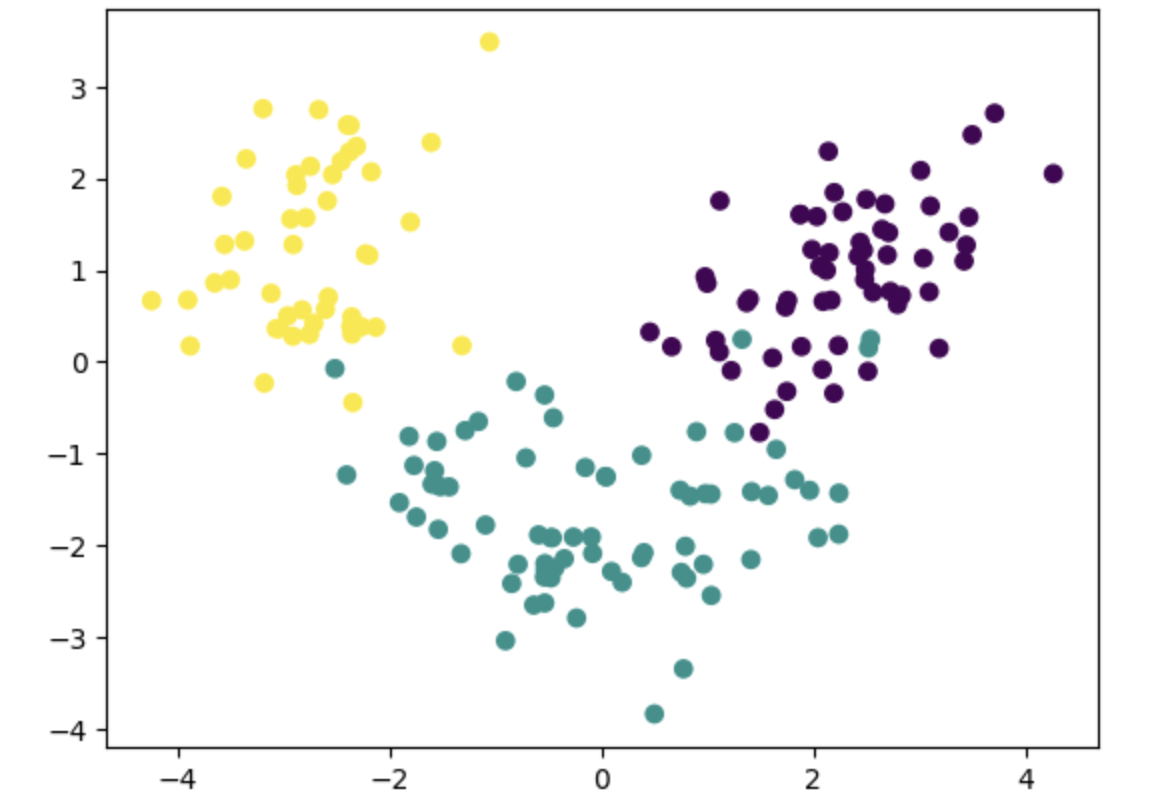
🖇 Kernel PCA
일반 PCA는 선형적인 관계에만 적합하다.
커널 PCA는 데이터에 비선형 구조가 존재할 경우, 커널 트릭(kernel trick)을 이용해 비선형 공간으로 변환한 후 주성분을 찾는다.
복잡한 분포를 가진 데이터의 차원 축소에 적합하다.
# 라이브러리 불러오기
from sklearn.decomposition import KernelPCA
# 데이터 복사
df = data.copy()
# 커널 PCA
pca = KernelPCA(n_components=2)
# 커널 PCA 변환
df = pca.fit_transform(df)
# 시각화
df = pd.DataFrame(df)
plt.scatter(df.iloc[:, 0], df.iloc[:, 1], c=dataset.target)
plt.show()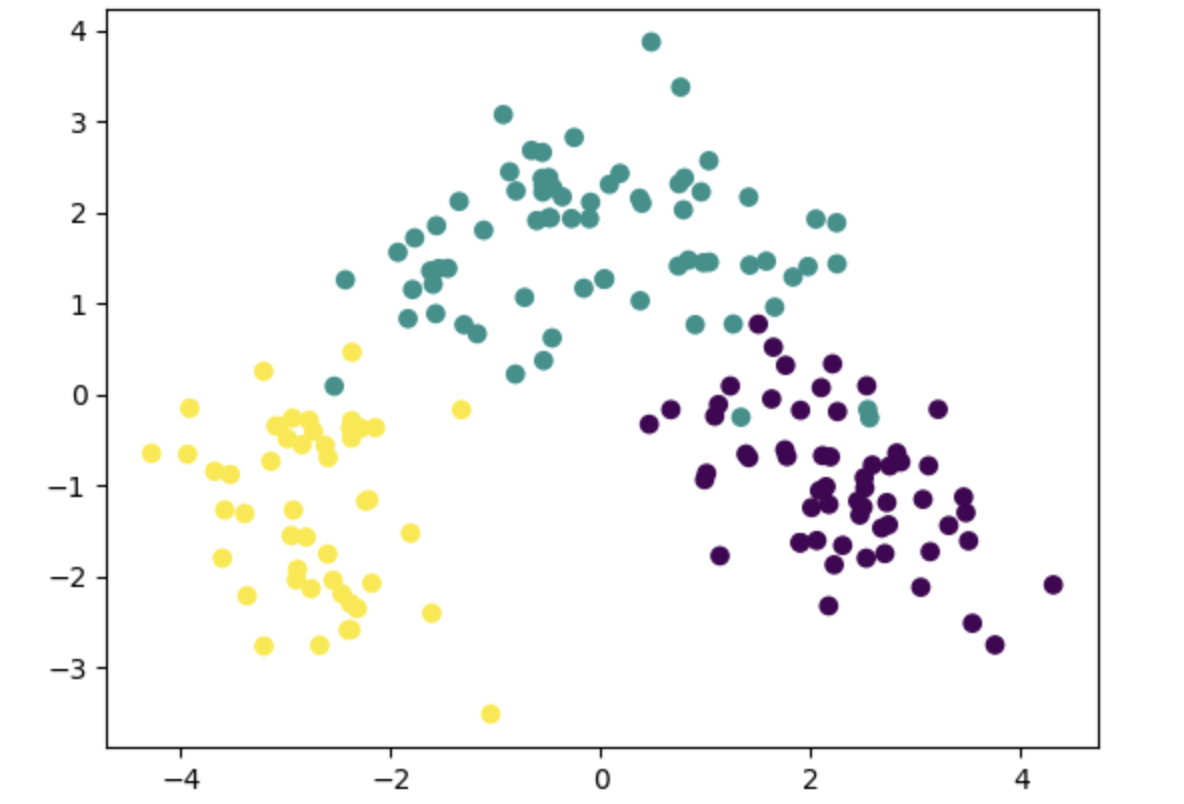
🖇 Truncated SVD
SVD(Singular Value Decomposition)는 행렬을 분해하는 방법이다.
Truncated SVD는 특히 희소 행렬(sparse matrix)이나 추천 시스템, 자연어 처리 등에서 유용하게 사용된다. PCA와 유사하지만 데이터 평균을 제거하지 않고 바로 분해를 수행한다는 차이점이 있다.
# 라이브러리 불러오기
from sklearn.decomposition import TruncatedSVD
# SVD 적용
df = data.copy()
pca = TruncatedSVD(n_components=2)
df = pca.fit_transform(df)
# 시각화
df = pd.DataFrame(df)
plt.scatter(df.iloc[:, 0], df.iloc[:, 1], c=dataset.target)
plt.show()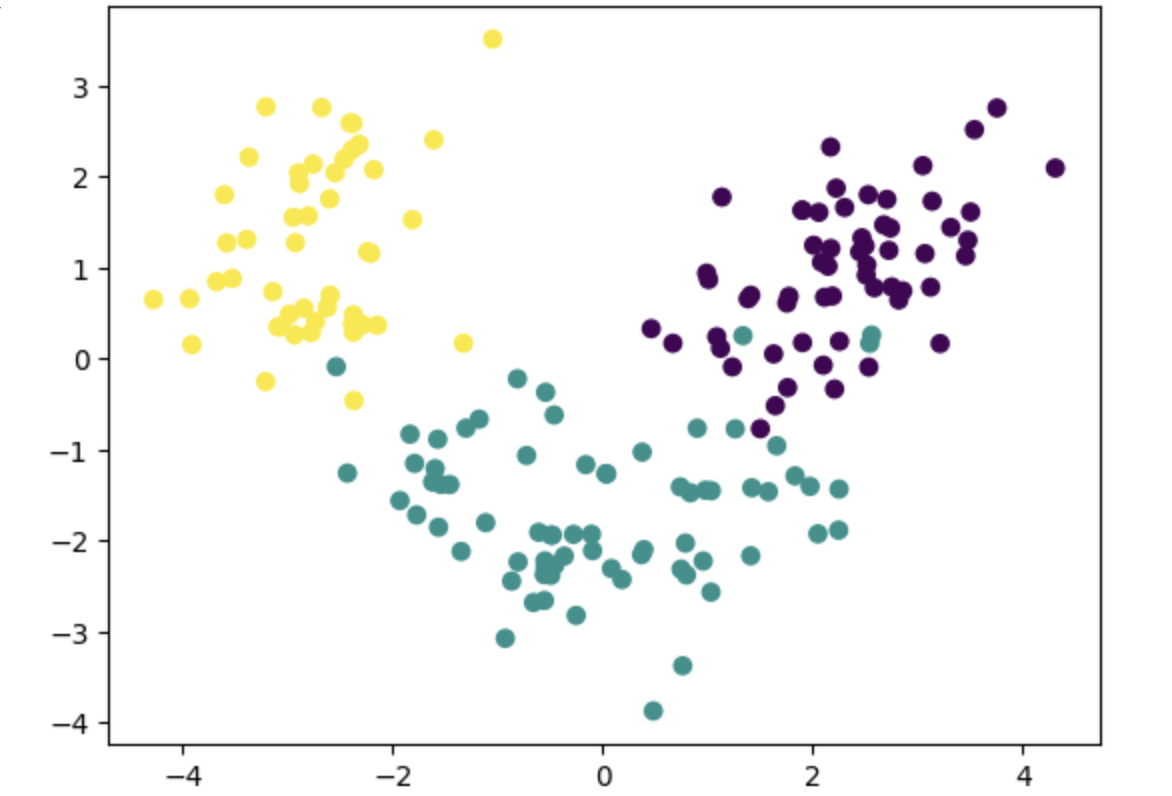
인사이트 및 회고
지금까지 대표적인 차원 축소 기법인 PCA를 중심으로 다양한 방식의 차원 축소 방법을 비교해 보았다.
고차원 데이터를 요약하면서도 핵심 정보를 유지할 수 있다는 점에서 차원 축소의 필요를 알 수 있었다. 시각화가 필요한 분석, 모델의 과적합을 줄이고 싶은 상황, 대용량 데이터 처리 등의 경우에 적절한 방법을 선택해 활용할 수 있다.
PCA는 단순하면서 효과적인 방법이며 Incremental PCA, Sparse PCA, Kernel PCA, SVD 등 각각의 데이터 특성과 목적에 따라 다양한 차원 축소 기법이 존재한다.
이처럼 차원 축소는 데이터의 구조를 올바르게 이해하고 해석하는 데 유용하다.
