🖇 클러스터링 알고리즘이란?
🖇 1. 구매하는 제품의 다양성
🖇 2. 평균 구매 주기
🖇 3. 구매 취소 경향성
🖇 빅쿼리에서 csv 파일 추출하기
앞서 고객을 “얼마나 자주, 얼마나 최근에, 얼마나 많이 구매했는가”라는 기준으로 세그먼테이션했다. 하지만 이것만으로 고객의 전체적인 쇼핑 성향을 완벽히 이해하긴 어렵다.
이번에는 고객의 구매 습관과 성향을 더욱 깊이 있게 파악할 수 있는 추가 feature들을 추출해 보려고 한다.
이제는 고객이 “무엇을, 얼마나 다양하게, 어떤 패턴으로” 구매했는지까지 분석해 보자.
왜 추가 feature가 필요할까?
이전 글에서
RFM 지표로 보면 같은 Frequency와 Monetary 값을 가진 고객이라도 쇼핑 성향이 완전히 다른 경우를 생각해 볼 수 있었다. 또한, 구매한 상품의 범위가 넓은 고객은 향후 다양한 상품을 재구매할 가능성이 높다는 점 등도 고려해야 한다.
이처럼 RFM 분석에는 한계가 있다. 고객의 다양성, 습관성, 충성도 등을 더 정교하게 이해하기 위해선, 추가 feature 추출이 꼭 필요하다.
이번 단계에서 추출할 주요 feature들을 먼저 설명하겠다.
- 제품 다양성 (unique_products)
- 고객이 구매한 고유한 상품의 수
- 다양한 상품에 관심 있는 고객일수록 재구매 가능성이 높습니다.
- 평균 구매 간격 (average_interval)
- 고객의 평균 구매 주기 (일 단위)
- 구매 사이의 텀이 짧을수록 더 충성도가 높은 고객일 수 있습니다.
- 취소 거래 비율 (cancel_rate)
- 전체 거래 중 취소된 거래의 비율
- 취소율이 높은 고객은 서비스 만족도가 낮거나 변덕스러운 특성을 가질 수 있습니다.
이 세 가지 feature를 통해, 단순 거래 수나 금액만으로는 알 수 없었던 쇼핑 패턴의 깊은 면을 확인할 수 있을 것이다.
🖇 클러스터링 알고리즘이란?
이제 다양한 feature가 준비되었으니, 고객을 자동으로 분류해주는 알고리즘, 클러스터링을 적용해볼 수 있다.
클러스터링은 데이터 내에 숨겨진 패턴을 찾아 비슷한 특성을 가진 고객들끼리 묶는 기술이다.
다음과 같은 사례에서 활용할 수 있다.
- 고객 세그먼테이션: 구매 성향이 비슷한 고객을 그룹화 → 타겟 마케팅 가능
- 이상탐지: 일반적인 패턴과 다른 고객을 탐지 → 보안/품질 이슈 선제 대응
- 의료 진단: 유사한 진단/패턴을 가진 환자 그룹 추출
- 문서 분류, 이미지 그룹화 등 다양한 분야에 활용
우리는 이 중에서도 가장 널리 사용되는 K-Means 클러스터링을 사용할 예정이다.
그 전에, 방금 정리한 추가 feature들을 추출하고, 적절히 전처리한 후 본격적으로 클러스터링 분석을 수행할 것이다.
🖇 1. 구매하는 제품의 다양성
이 단계에서는 고객이 얼마나 다양한 제품에 관심을 가졌는지, 즉 구매한 상품의 고유 개수를 살펴볼 것이다.
이 정보는 개인 맞춤형 마케팅 전략을 수립하거나, 상품 추천 알고리즘을 설계할 때 유용하게 활용된다.
예를 들어,
- 다양한 제품을 구매한 고객은 관심사가 넓고 탐색적 성향이 강한 유저일 가능성이 있다.
- 반대로 소수의 제품만 반복적으로 구매한 고객은 충성 고객일 수도 있다.
-
고객별로 구매한 상품의 고유 개수를 계산한
COUNT(DISTINCT StockCode)를 사용하여 고객마다 몇 종류의 상품을 구매했는지 계산- 이 값을
unique_products라는 새로운 컬럼으로 생성
-
기존의 RFM 정보가 저장된
user_rfm테이블과 JOIN- 고객의 구매 다양성을 기존의 RFM 데이터에 통합하여 더 풍부한 분석이 가능
-
최종적으로
user_data라는 이름의 테이블로 저장- 이 테이블은 이후 분석의 핵심 테이블이 되며, 클러스터링 등의 모델링에 직접 사용
-- (3) user_data 테이블로 저장
CREATE OR REPLACE TABLE project_name.dataset.user_data AS
WITH unique_products AS (
-- (1) 고객별 구매한 고유 제품 수 계산
-- -> 고객이 얼마나 다양한 제품을 구매했는가?를 알려주는 지표
SELECT CustomerID,
COUNT(DISTINCT StockCode) AS unique_products
FROM project_name.dataset.data
GROUP BY CustomerID
)
-- (2) 기존 user_rfm 테이블과 JOIN
SELECT ur.*, -- user_rfm 테이블의 모든 컬럼
up.* EXCEPT (CustomerID) -- unique_products 테이블의 CustomerID 제외한 나머지 컬럼
FROM project_name.dataset.user_rfm AS ur
JOIN unique_products AS up
ON ur.CustomerID = up.CustomerID;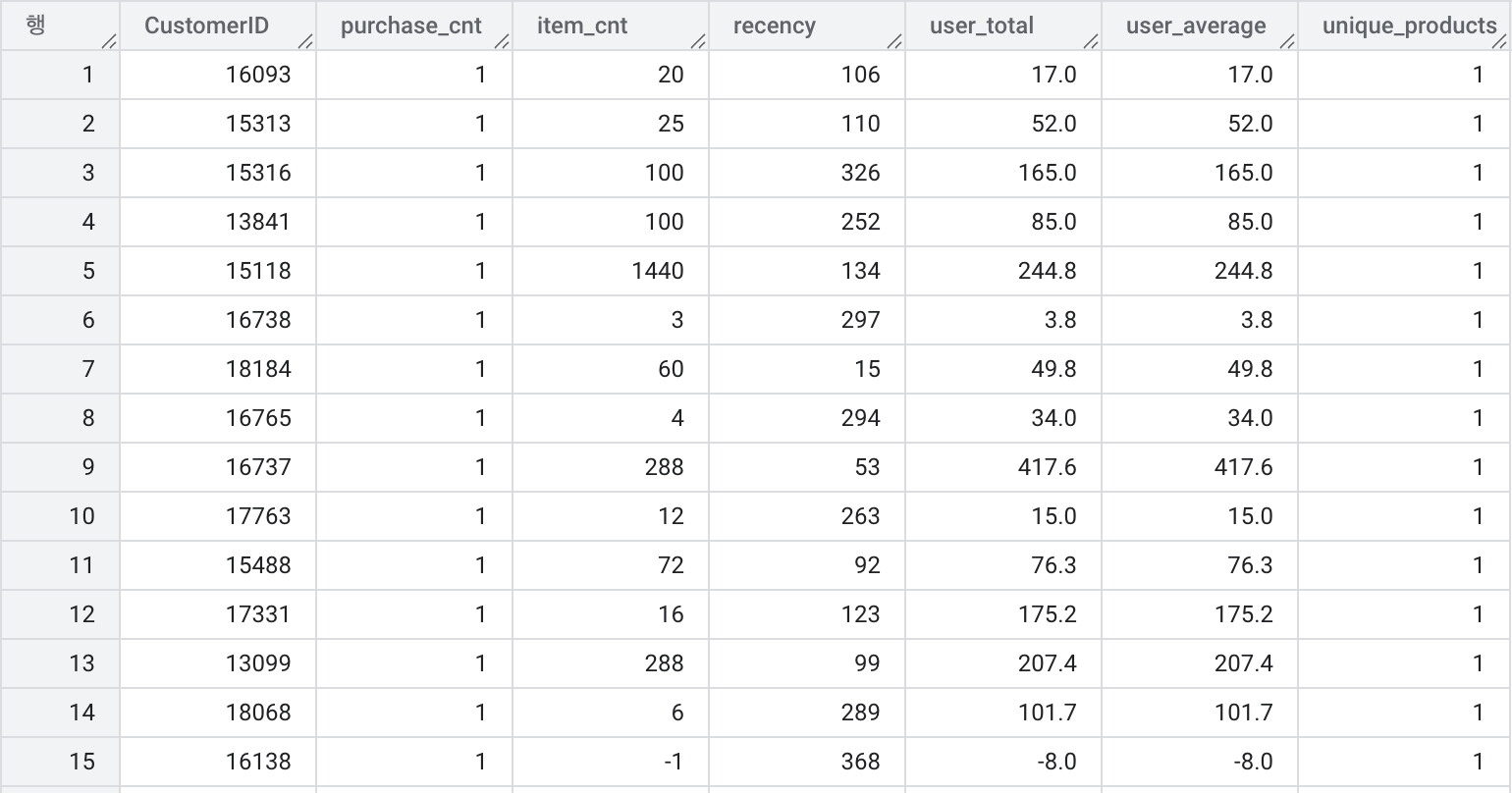
🖇 2. 평균 구매 주기
이 단계에서는 고객들의 쇼핑 패턴을 이해하는 것을 목표로
고객의 쇼핑 주기, 즉 재방문 주기를 분석하였다.
- 평균 구매 소요 일수를 계산하고, 그 결과를
user_data에 통합
CREATE OR REPLACE TABLE `project_name.dataset.user_data` AS
WITH purchase_intervals AS (
-- (2) 고객 별 구매와 구매 사이의 평균 소요 일수
SELECT CustomerID,
# 구매 건수가 한 건뿐인 고객은 이전 구매일이 없기 때문에
# 평균 간격이 계산되지 않으므로 예외 처리
CASE WHEN ROUND(AVG(interval_), 2) IS NULL THEN 0
ELSE ROUND(AVG(interval_), 2)
END AS average_interval
FROM (
-- (1) 구매와 구매 사이에 소요된 일수
SELECT CustomerID,
DATE_DIFF(InvoiceDate, LAG(InvoiceDate) OVER (PARTITION BY CustomerID ORDER BY InvoiceDate), DAY) AS interval_
FROM project_name.dataset.data
WHERE CustomerID IS NOT NULL
)
GROUP BY CustomerID
)
SELECT u.*, pi.* EXCEPT (CustomerID)
FROM project_name.dataset.user_data AS u
LEFT JOIN purchase_intervals AS pi
ON u.CustomerID = pi.CustomerID;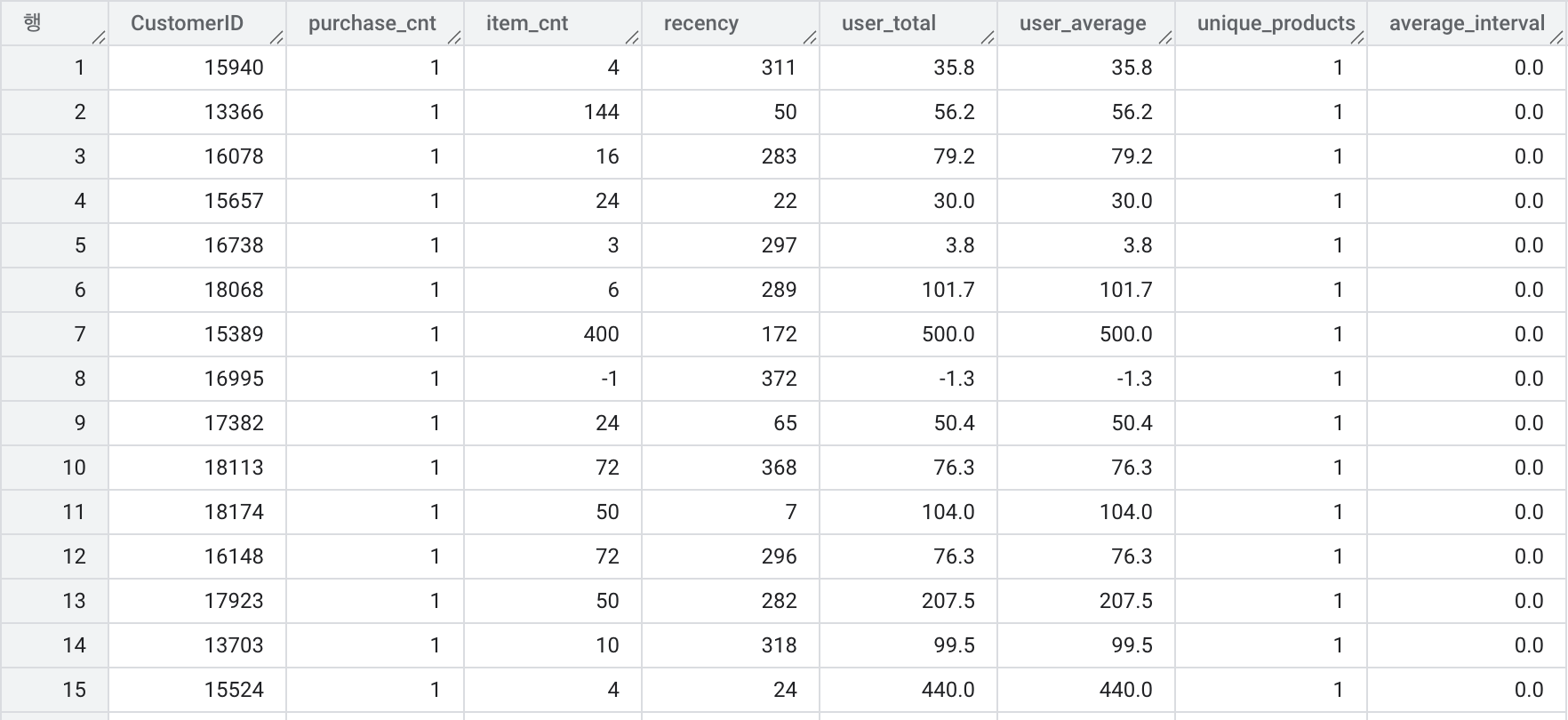
🖇 3. 구매 취소 경향성
이 단계에서는 고객의 취소 패턴을 더 깊이 있게 파고 들어 고객을 세그먼테이션할 때 사용하려고 한다.
아래와 같은 feature들을 추가하였다.
- 취소 빈도(
cancel_frequency)
취소 빈도는 고객 별로 취소한 거래의 총 횟수입니다.
- 취소 비율(
cancel_rate)
취소 비율은 각 고객이 한 모든 거래 중에서 취소를 한 거래의 비율입니다.
- 취소 빈도와 취소 비율을 계산하고 그 결과를
user_data에 통합하기
CREATE OR REPLACE TABLE project_name.dataset.user_data AS
WITH TransactionInfo AS (
SELECT CustomerID,
-- 고객별 전체 거래 수 계산
COUNT(InvoiceNo) AS total_transactions,
-- 고객별 취소 거래 수 계산
-- STARTS_WITH(): 정확하게 "시작하는지 여부"만 판단하는 함수
-- LIKE 'C%'를 사용하면 인덱스를 못쓰고 성능상 더 무거움
COUNTIF(STARTS_WITH(InvoiceNo, 'C')) AS cancel_frequency
FROM project_name.dataset.data
WHERE CustomerID IS NOT NULL
GROUP BY CustomerID
)
SELECT u.*,
t.* EXCEPT(CustomerID),
-- 취소 비율은 소수점 두번째 자리까지
ROUND(cancel_frequency / total_transactions, 2) AS cancel_rate
FROM project_name.dataset.user_data AS u
LEFT JOIN TransactionInfo AS t
ON u.CustomerID = t.CustomerID;💡 취소 빈도를 이해하면 거래를 취소할 가능성이 높은 고객을 식별할 수 있다.
취소 빈도는 불만족의 정도이거나 다른 문제에 대한 지표일 수 있다. 따라서 취소 빈도를 이해함으로써 거래 취소 횟수를 줄이고 고객 만족도를 높이기 위한 전략을 세울 수 있다.
💡 취소 비율은 특정 고객이 원래 취소를 잘 하는 고객인지 등의 고객 특징을 잡아내기 위한 지표이다. 이런 특성을 식별함으로써 고객의 쇼핑 경험을 개선하고 취소 비율을 감소시키기 위해 어떤 고객 대상군을 공략해야 할지를 생각해 볼 수 있다.
지금까지 추가적인 feature를 추출하기 위한 작업을 진행하였다.
다양한 컬럼들을 활용하여 고객의 구매 패턴과 선호도를 보다 심층적으로 이해할 수 있도록 최종적으로 user_data를 출력해 보자.
SELECT *
FROM capable-sled-456102-t0.modulabs_project.user_data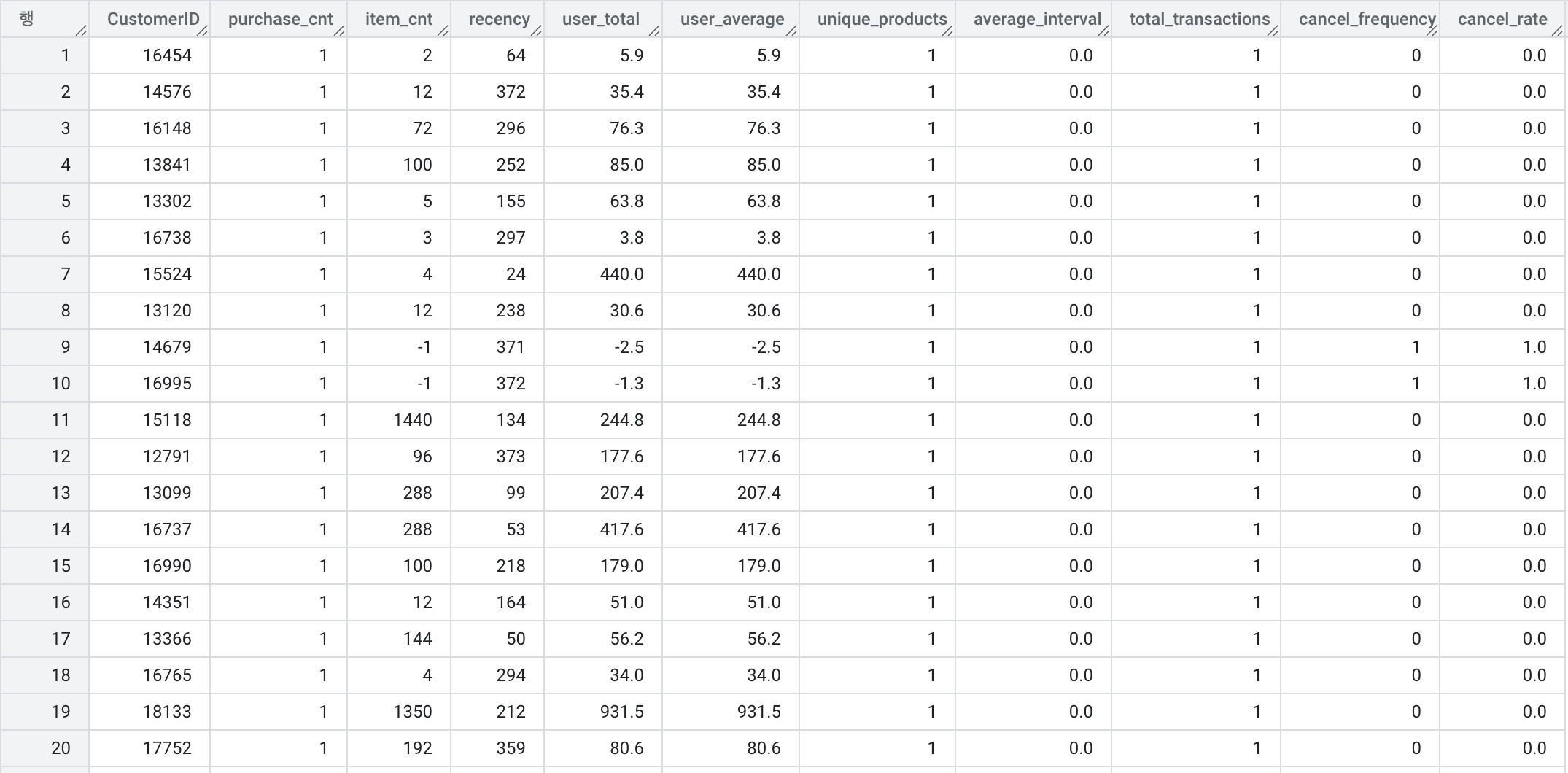
🖇 빅쿼리에서 csv 파일 추출하기
이제 SQL로 전처리한 데이터를 파이썬 환경에서 분석하기 위한 환경을 세팅해 보자.
왜 SQL로 전처리하고 Python에서 분석할까?
BigQuery는 대용량 데이터를 빠르게 처리하는 데에 특화된 클라우드 기반 데이터베이스이다.
하지만 데이터 시각화, 머신러닝 모델링 등 고급 분석은 Python(Pandas, Scikit-learn 등)을 활용하는 것이 더 유리하다.
그래서 대체로
SQL로 데이터를 정제 → 파이썬에서 분석 및 시각화
하는 방법을 많이 사용한다.
빅쿼리 결과 CSV 파일로 저장하기
-
쿼리 실행 후, BigQuery의 쿼리 결과 창에서
결과 저장 → CSV (로컬 파일)선택 -
저장된 파일은 이름이 랜덤하게 지정되어 있으므로,
user_data.csv로 이름을 변경하는 것이 좋다. -
이 CSV 파일을 파이썬 환경(Jupyter Notebook)에서 사용할 수 있도록 업로드한다.
Jupyter Notebook에서 CSV 불러오기
pandas로 데이터를 불러오고 미리보기하기 위해 Jupyter Notebook에서 CSV 파일을 불러오면 된다.
import pandas as pd
# 지금까지 정제한 최종 고객 데이터셋이 담기게 된다.
user_data = pd.read_csv('../user_data.csv')
user_data.head()
이제 데이터를 불러왔으니,
이어지는 글에서는 본격적으로 Python을 사용해 고객들을 다양한 그룹으로 분류하고 어떤 인사이트를 도출하였는지 정리해 볼 예정이다.
[해당 컨텐츠는 아이펠 캠퍼스 LMS에서 학습한 내용을 재해석한 것으로 무단 복제 및 사용을 금지합니다.]
