🖇 이상치란?
🖇 Z-Score를 활용한 이상치 분석
🖇 왜 임계값 3이 일반적인가?🧐
🖇 이상치 탐지 및 제거
🖇 이상치 분포 시각화
SQL로 전처리해 준 데이터를 바탕으로 클러스터링을 진행하기에 앞서, 이상치(Outlier) 제거는 필수적인 전처리 과정이다.
클러스터링은 데이터 간의 거리 기반으로 유사한 그룹을 찾기 때문에 하나의 튀는 값(이상치)이 전체 결과에 큰 영향을 미칠 수 있기 때문이다.
여러 개 컬럼을 가지고 있는 user_data에서 이상치를 찾아야 하기 때문에, 다차원 공간에서 이상치를 감지할 수 있는 알고리즘 Z-Score를 사용한 이상치 감지 방법을 적용할 것이다.
다차원 고객 데이터에서 이상치를 식별하고 제거해 보자.
🖇 이상치란?
이상치는 데이터셋 내의 다른 값들과 크게 차이가 나는 데이터 포인트를 의미한다.
예를 들어, 초등학생 키 데이터를 클러스터링할 때 키가 190cm인 학생이 있다면?
→ 이 학생은 일반적인 그룹에서 멀리 떨어진 이상치가 되며 클러스터링을 왜곡시킬 수 있다.
→ 혼자만의 클러스터를 형성하거나, 나머지를 모두 하나로 묶는 결과를 초래할 수도 있다.
이렇게 이상치 데이터는 클러스터링에서 다른 데이터 포인트들을 크게 벗어나는 값으로 작용하게 하여, 정확한 그룹 형성을 어렵게 만들 수 있다.
따라서 더 의미 있는 클러스터링을 형성하고 정확한 결과를 얻기 위해 이상치를 적절하게 처리하는 것이 중요하다.
🖇 Z-Score를 활용한 이상치 분석
앞서 이야기했듯이 여러 개 컬럼을 가지고 있는 user_data에서 이상치를 바로 찾기 위해 Z-Score 를 사용한 이상치 감지 방법을 적용할 것이다.
이 알고리즘은 다차원 데이터에 적용하기 용이하며 계산도 효율적으로 한다.
Z-Score란?
Z-Score는 각 값이 평균으로부터 몇 개의 표준 편차만큼 떨어져 있는지를 나타내는 값이다.
공식은 다음과 같다:
𝑥: 해당 특성의 값
𝜇: 평균
𝜎: 표준 편차
-
각 특성(feature)의 평균과 표준 편차를 계산한다.
-
각 데이터 포인트의 해당 특성 값에서 평균을 뺀 값을 표준 편차로 나눈다. 이 값이 평균과 표준 편차로 표준화된 값이다.
Z-Score는 평균이 0, 표준 편차가 1인 표준 정규 분포(Standard Normal Distribution) 를 기준으로 한다.
: 평균보다 큼
: 평균보다 작음
: 이상치 가능성 높음
Z-Score는 이처럼 데이터의 표준화(standardization)를 통해, 서로 다른 특성을 동일 기준으로 비교할 수 있게 도와준다.
[참고] 표준화는 평균을 중심으로 데이터 분포를 정규화시켜, 비교 가능한 형태로 바꾸는 과정이다.
Z-Score를 사용한 이상치 감지는 각 특성의 값들을 표준화하여 해당 데이터 포인트가 각 특성의 평균에서 얼마나 표준 편차만큼 떨어져 있는지를 통해 알 수 있다.이때 이상치는 특정 임계값(threshold)을 초과하는 경우로 정의된다.
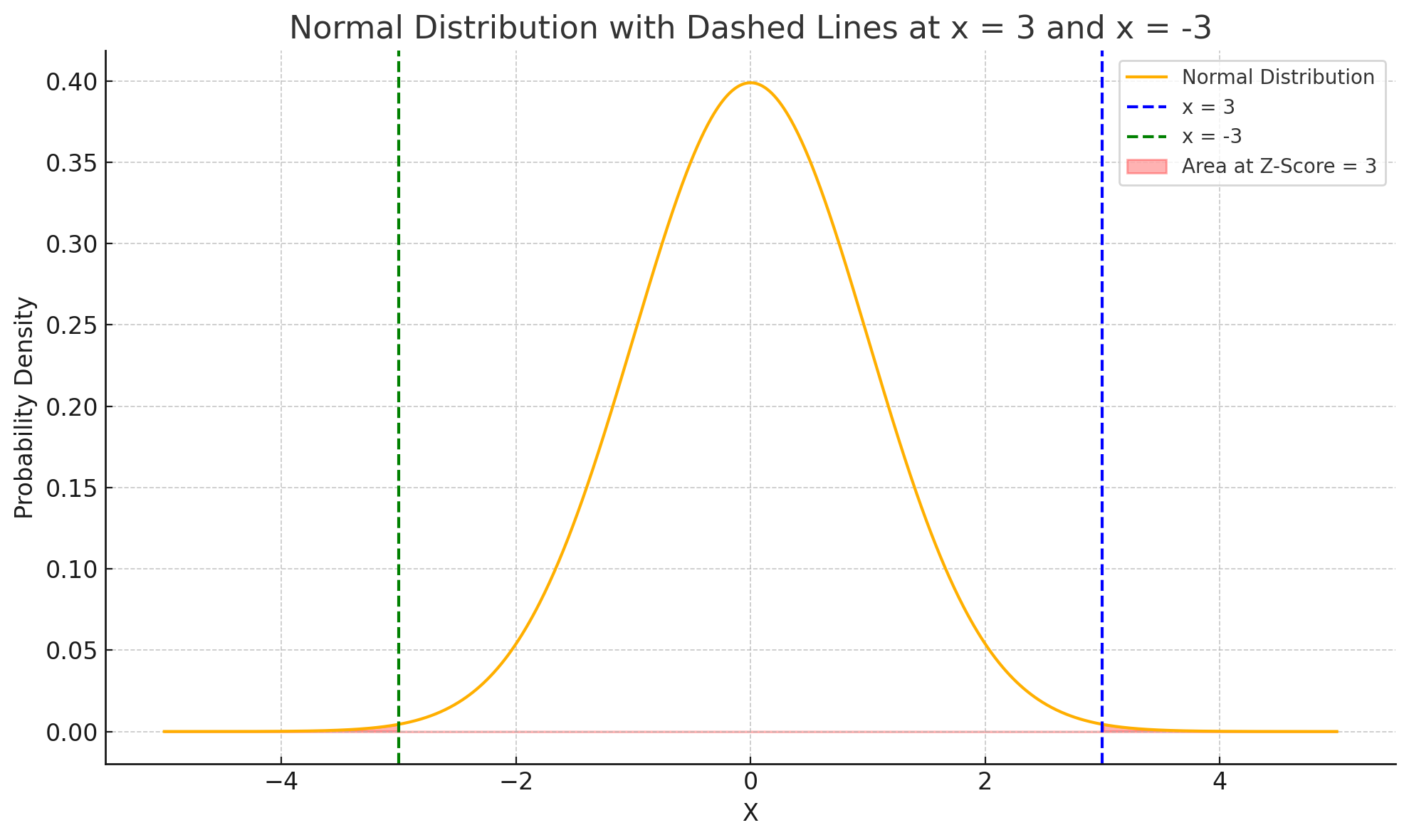
🖇 왜 임계값 3이 일반적인가?🧐
이상치 감지를 위해 통상적으로 임계값을 3으로 설정하고 이를 초과하는 Z-Score를 가지는 데이터 포인트는 이상치로 간주된다.
이때 임계값을 왜 하필 3으로 설정하는 것인지 의문이 들어 정리해 보았다.
Z-Score에서 보통 임계값을 3으로 설정하는 이유는 정규 분포의 통계적 특성과 관련이 있다.
앞서 살펴봤듯 Z-Score는 표준 정규 분포를 기준으로 계산된다.
이 분포는:
평균
표준 편차
을 가지며, 다음과 같은 확률 분포를 보인다.
| Z-Score 범위 | 포함되는 데이터 비율 |
|---|---|
| -1 ~ 1 | 약 68.3% |
| -2 ~ 2 | 약 95.5% |
| -3 ~ 3 | 약 99.7% |
즉, Z가 ±3을 넘는 값은 전체 데이터의 약 0.3%밖에 되지 않는다.
따라서 아래와 같은 이유로 통상적으로 임계값을 3으로 설정하게 된다.
이유 1: 극단값 감지
- Z-Score가 ±3을 넘는 값은 통계적으로 매우 드문 값이다.
- 일반적인 데이터 분포에서 극단적인 이상치로 간주하기에 적절한 기준이다.
이유 2: 실용성과 균형
- ±3을 기준으로 하면 대부분의 정상 데이터는 유지하면서, 노이즈는 제거할 수 있다.
- ±2를 기준으로 하면 이상치가 너무 많아지고, ±4는 너무 엄격해서 이상치를 놓칠 수 있다.
- 그래서 "3"은 실용성과 안정성 사이의 균형점으로 널리 사용된다.
꼭 3이어야 하냐면, 그건 아니다.
데이터의 성격, 도메인 지식, 실험 결과에 따라 ±2.5, ±2, ±4 등의 값으로 조정할 수 있다. 예를 들어, 금융 데이터처럼 극단값이 더 많거나 중요한 경우는 기준을 다르게 설정하기도 한다.
임계값을 조절하면 얼마나 많은 데이터 포인트를 이상치로 처리할지 조정할 수 있다. 이렇게 이상치로 감지된 데이터 포인트는 주로 특별한 조치가 필요한 경우로 처리되게 된다.
💬 “Z-Score가 ±3 이상이면 전체의 0.3% 수준이므로, 통계적으로 ‘이상치’라고 판단하기에 충분히 이례적이다.”
그래서 많은 분석가와 데이터 과학자들이 기본적으로 Z-Score = 3을 임계값으로 사용하는 것이라는 것을 알게 되었다.
🖇 이상치 탐지 및 제거
1. 데이터 불러오기
데이터 처리 및 분석을 위해 pandas 라이브러리를 사용하겠다.
import pandas as pd
user_data = pd.read_csv('../user_data.csv')
# 상위 5개의 데이터로 결과를 확인한다.
user_data.head()

2. Z-Score 계산
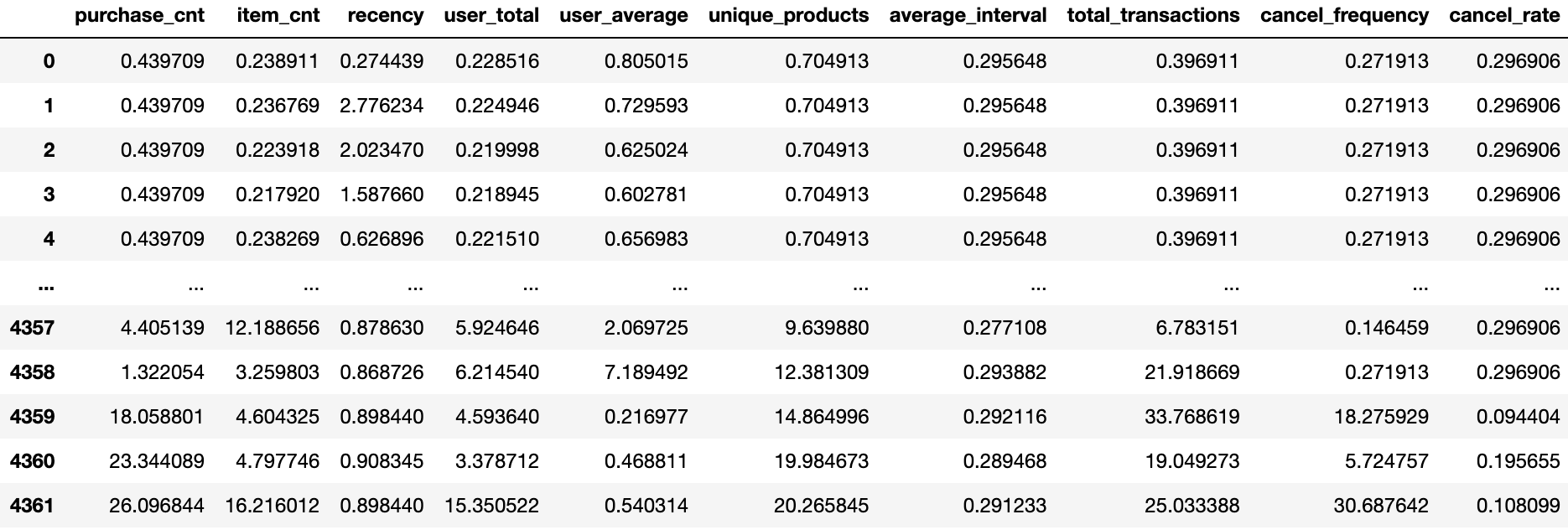
이상치를 찾아내기 위해 scipy 라이브러리와, 효율적으로 수치 연산을 수행하는 numpy도 불러온다.
CustomerID를 제외한 나머지 컬럼 안에 있는 값들을 정규화하여 Z-score를 계산하고, Z-score 값이 음수가 나오는 경우가 있기 때문에 절대값으로 변경해 주겠다.
from scipy import stats
import numpy as np
# CustomerID 제외, 정규화
z_scores = stats.zscore(user_data.iloc[:, 1:], axis=0)
z_scores = np.abs(z_scores)
# Z-score 출력
z_scores
3. 임계값 설정 및 이상치 식별
해당 프로젝트에서는 임계값 3을 정의하고,
Z-score가 3을 넘을 경우 이상치로 간주하여 outlier라는 새로운 컬럼으로 표시하였다.
# 임계값 설정
threshold = 3
# Z-Score 기준으로 이상치를 찾아내고
# outlier 컬럼에 이상치 여부 기입 (0: 정상, 1:이상치)
user_data['outlier'] = (z_scores > threshold).any(axis=1).astype(int)
user_data.head()

🖇 이상치 분포 시각화
점수의 분포, 그리고 모델에 의해 감지된 정상 데이터와 이상치의 수를 시각화해 보자.
시각화에 필요한 matplotlib 라이브러리를 사용하였다.
import matplotlib.pyplot as plt
# 이상치 여부에 따른 확률 계산
# value_counts(): 열의 고윳값 개수를 반환하지만 normalize=True를 사용하면 열에 있는 값의 개수 비율(상대적 빈도)을 반환한다.
outlier_percentage = pd.value_counts(user_data['outlier'], normalize=True) * 100
# 시각화 자료 크기 조정
plt.figure(figsize=(3, 4))
# bar chart 시각화 - x축 값을 0과 1로 지정
bars = plt.bar(['0', '1'], outlier_percentage)
# 퍼센트(%) 표시
for bar in bars:
yval = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2, yval/2, f'{yval:.2f}%', fontsize=10, va='center', ha='center')
plt.title('Normal(0) vs Outlier(1)') # 표 제목
plt.yticks(ticks=np.arange(0, 101, 10)) # y축 표기 (0~100까지 10단위로 증가)
plt.ylabel('Percentage (%)') # y축 범례
plt.xlabel('Outlier') # x축 범례
plt.show() # 출력
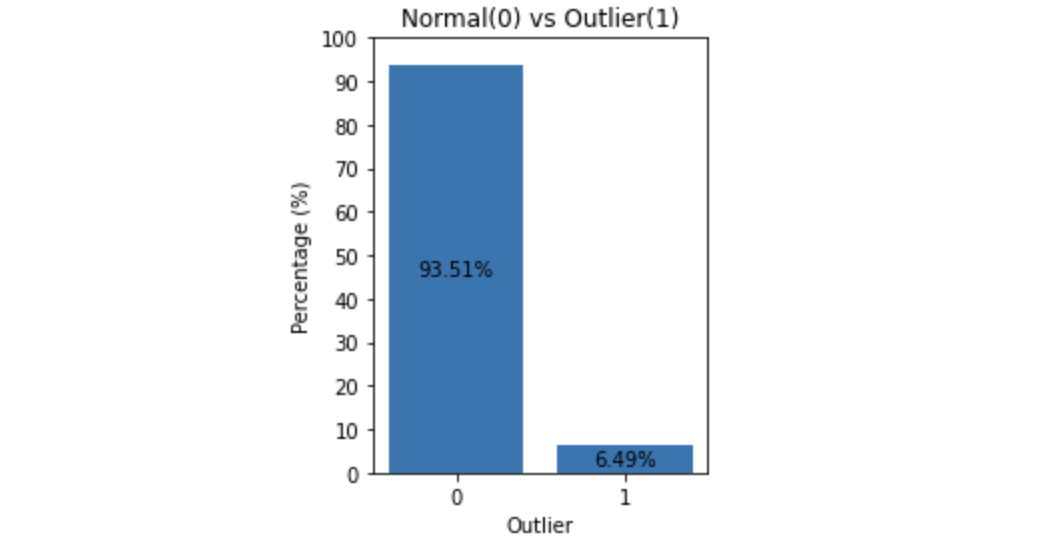 시각화 결과로부터 약 6%의 고객이 데이터셋에서 이상치로 식별되었음을 관찰할 수 있었다. 이 비율은 데이터의 중요한 부분을 잃지 않고, 잠재적으로 노이즈가 있는 데이터 포인트를 유지하기에 합리적인 비율로 보인다.
시각화 결과로부터 약 6%의 고객이 데이터셋에서 이상치로 식별되었음을 관찰할 수 있었다. 이 비율은 데이터의 중요한 부분을 잃지 않고, 잠재적으로 노이즈가 있는 데이터 포인트를 유지하기에 합리적인 비율로 보인다.
이상치 제거 및 데이터 정리
해당 프로젝트의 성격을 고려할 때, 이러한 이상치를 처리하여 군집의 품질에 미치는 영향을 방지하는 것이 중요하다.
따라서 이상치를 별도의 분석을 위해 분리하고, 군집화 분석을 위해 주요 데이터 셋에서 제거야 한다.
# 정상 데이터만 필터링하여 이상치 제거
user_data = user_data[user_data['outlier'] == 0]
# outlier 컬럼 삭제 및 인덱스 리셋
user_data = user_data.drop(columns=['outlier'])
# DataFrame의 인덱스를 리셋하고, 이전 인덱스를 컬럼으로 추가하지 않는다.
user_data.reset_index(inplace=True, drop=True)
user_data.head()

이상치를 성공적으로 제거하고, 클러스터링을 위한 정제된 고객 데이터셋이 준비되었다.
지금까지
Z-Score를 활용해 이상치를 식별하고, 시각화를 통한 분포 확인, 이상치 제거를 통한 데이터 정제하는 과정을 수행했다.
이제 이 정제된 데이터셋을 기반으로
Feature Scaling(특성 스케일링) 과 K-Means 클러스터링 등의 알고리즘을 적용해 고객 세그먼트를 구체화할 예정이다.
[해당 컨텐츠는 아이펠 캠퍼스 LMS에서 학습한 내용을 재해석한 것으로 무단 복제 및 사용을 금지합니다.]
