분석을 하다보면 아래처럼 "그룹 간 차이"를 검정해야 하는 경우가 있다.
신약 A, B, C가 혈압에 미치는 효과에 차이가 있는가?
웹페이지 A, B, C의 체류시간이 의미 있게 다른가?
이처럼 3개 이상의 그룹 평균 차이를 검정할 때, 단순한 t-검정을 반복하는 대신 ANOVA를 사용한다.
ANOVA는 아래의 핵심 요소로 작동한다.
- 그룹 간 분산 (SSB): 그룹 평균과 전체 평균 사이의 차이
- 그룹 내 분산 (SSW): 각 그룹 내부의 데이터 분산 정도
이 두 값을 비율로 나눈 F-통계량을 통해 “집단 간 차이”가 우연인지 통계적으로 유의미한지를 판단할 수 있다.
F-통계량 = 그룹 간 평균제곱(MSB) / 그룹 내 평균제곱(MSW)
⇒ MSB = SSB / (k - 1)
⇒ MSW = SSW / (n - k) 분자가 클수록, 분모가 작을수록 (= 그룹 간 차이가 클수록, 그룹 내 일관성 높을수록)
ANOVA 통계량은 커지고 귀무가설( "모든 그룹 평균이 같다"는 것 )이 기각될 확률이 높아진다.
이 글에서는 ANOVA로 집단 간 차이를 검정하고 사후분석까지 수행한 과정을 정리한다.
ANOVA: 신약 A, B, C의 혈압 감소 효과 비교
# 예시 데이터: 각 그룹에서 혈압 감소량 (mmHg)
group1 = [5, 7, 8, 6, 7] # 신약 A
group2 = [8, 9, 7, 10, 9] # 신약 B
group3 = [7, 6, 5, 8, 7] # 신약 C
# 세 그룹의 데이터를 리스트로 묶기
data = [group1, group2, group3]
# ANOVA 수행
f_statistic, p_value = stats.f_oneway(*data)
# 결과 출력
print(f"F-statistic: {f_statistic:.3f}")
print(f"P-value: {p_value:.3f}")
# 결론 도출
alpha = 0.05 # 유의수준
if p_value < alpha:
print("귀무가설 기각: 신약 간에 혈압 감소 효과에 차이가 있다.")
else:
print("귀무가설 채택: 신약 간에 혈압 감소 효과에 차이가 없다.")F-statistic: 5.128
P-value: 0.025
귀무가설 기각: 신약 간에 혈압 감소 효과에 차이가 있다.유의수준 0.05보다 작기 때문에 귀무가설을 기각한다.
⇒ 세 신약 중 적어도 하나는 혈압 감소 효과에서 통계적으로 차이를 보인다.
사후검정: 신약약물 간 검정
ANOVA 결과만으로는 어떤 그룹 간 차이가 있는지 알 수 없다.
따라서 사후검정(Tukey’s HSD)을 통해 구체적인 그룹 간 차이를 확인한다.
from statsmodels.stats.multicomp import pairwise_tukeyhsd
# DataFrame으로 변환
data = pd.DataFrame({
'혈압감소량': group1 + group2 + group3,
'그룹': ['A']*len(group1) + ['B']*len(group2) + ['C']*len(group3)
})
# ANOVA 결과
f_statistic, p_value = stats.f_oneway(group1, group2, group3)
print(f"F-statistic: {f_statistic:.3f}")
print(f"P-value: {p_value:.3f}")
# 사후검정 (Tukey's HSD)
tukey_res = pairwise_tukeyhsd(endog=data['혈압감소량'], groups=data['그룹'], alpha=0.05)
# 결과 출력
print(tukey_res)
tukey_res.plot_simultaneous()
plt.title("Tukey's HSD Test - Multiple Comparison")
plt.show()
# 결론 도출 (사후검정 결과를 참고하여 해석)
alpha = 0.05
if p_value < alpha:
print("귀무가설 기각: 신약 간에 혈압 감소 효과에 차이가 있다.")
else:
print("귀무가설 채택: 신약 간에 혈압 감소 효과에 차이가 없다.")
F-statistic: 5.128
P-value: 0.025
Multiple Comparison of Means - Tukey HSD, FWER=0.05
====================================================
group1 group2 meandiff p-adj lower upper reject
----------------------------------------------------
A B 2.0 0.0415 0.0762 3.9238 True
A C 0.0 1.0 -1.9238 1.9238 False
B C -2.0 0.0415 -3.9238 -0.0762 True
----------------------------------------------------
귀무가설 기각: 신약 간에 혈압 감소 효과에 차이가 있다.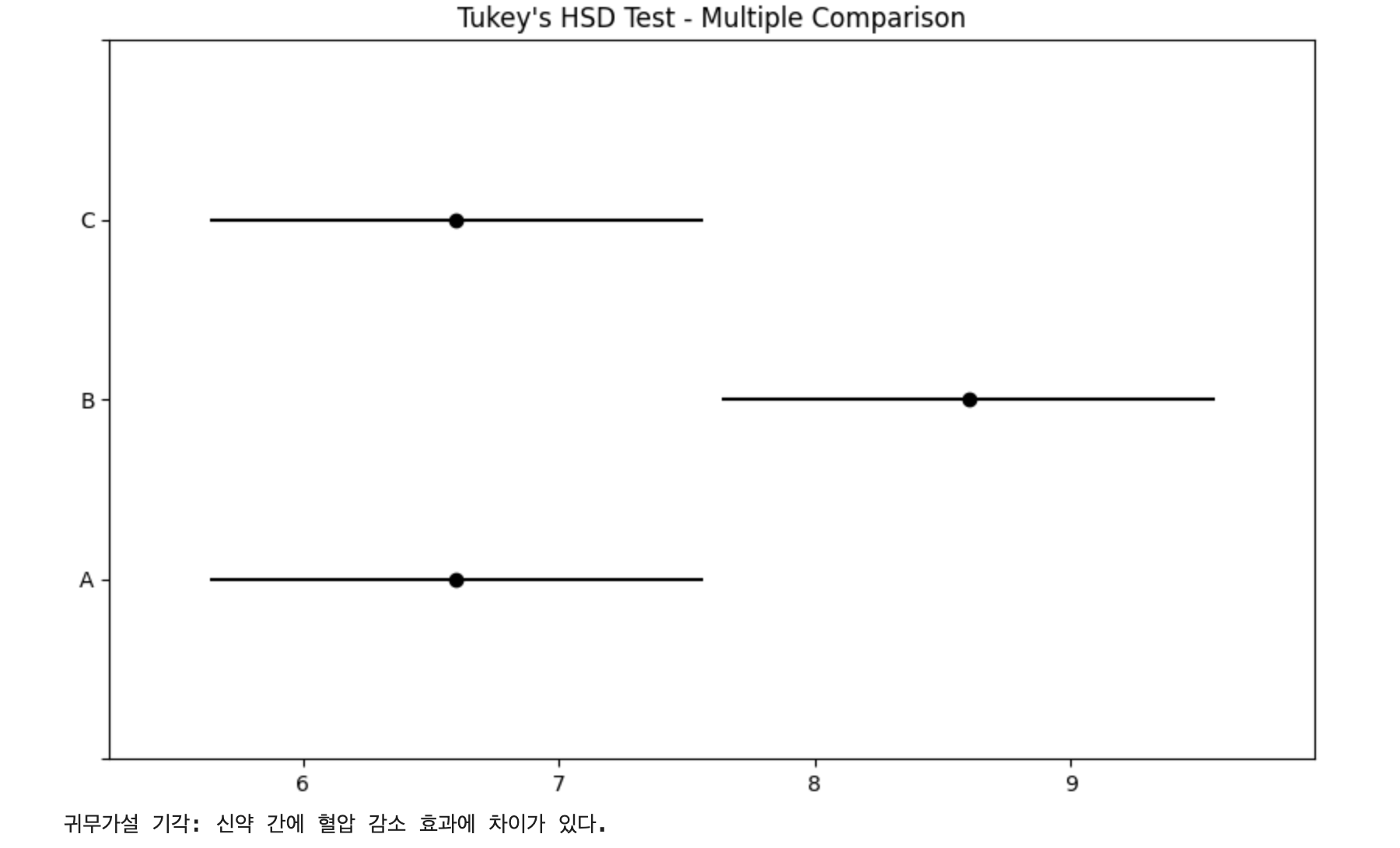
A vs B, B vs C 약물 간 차이가 통계적으로 유의하다.
결과적으로, B 약물이 이 고혈압 감소에 가장 효과적이라는 것을 입증한다.
ANOVA: 페이지 A, B, C, D 체류 시간 비교
각 페이지의 평균 체류 시간을 비교할 때도 ANOVA를 사용할 수 있다.
웹사이트 운영 중 여러 랜딩 페이지(Page 1~4)를 실험하고 있을 때, 각 페이지의 체류 시간에 유의미한 차이가 있는지 확인해 보자.
데이터 불러오기 및 확인
# 데이터 불러오기 및 확인
url = "https://raw.githubusercontent.com/gedeck/practical-statistics-for-data-scientists/master/data/four_sessions.csv"
four_sessions = pd.read_csv(url)
four_sessions.head(3)
페이지별 평균 체류 시간 확인
# 페이지별 평균 체류 시간 확인
four_sessions.groupby(['Page'])['Time'].mean()
Page 1 172.8
Page 2 182.6
Page 3 175.6
Page 4 164.6
Name: Time, dtype: float64
Page 2의 체류 시간이 가장 길고, Page 4가 가장 짧은 것을 볼 수 있다.
하지만 이것이 통계적으로 유의한 차이인지는 아직 알 수 없다.
히스토그램으로 Page 1과 Page 2 비교
# 히스토그램으로 Page 1과 Page 2 비교
import seaborn as sns
sns.histplot(x='Time', data=four_sessions[four_sessions['Page'] == 'Page 1'])
sns.histplot(x='Time', data=four_sessions[four_sessions['Page'] == 'Page 2'])
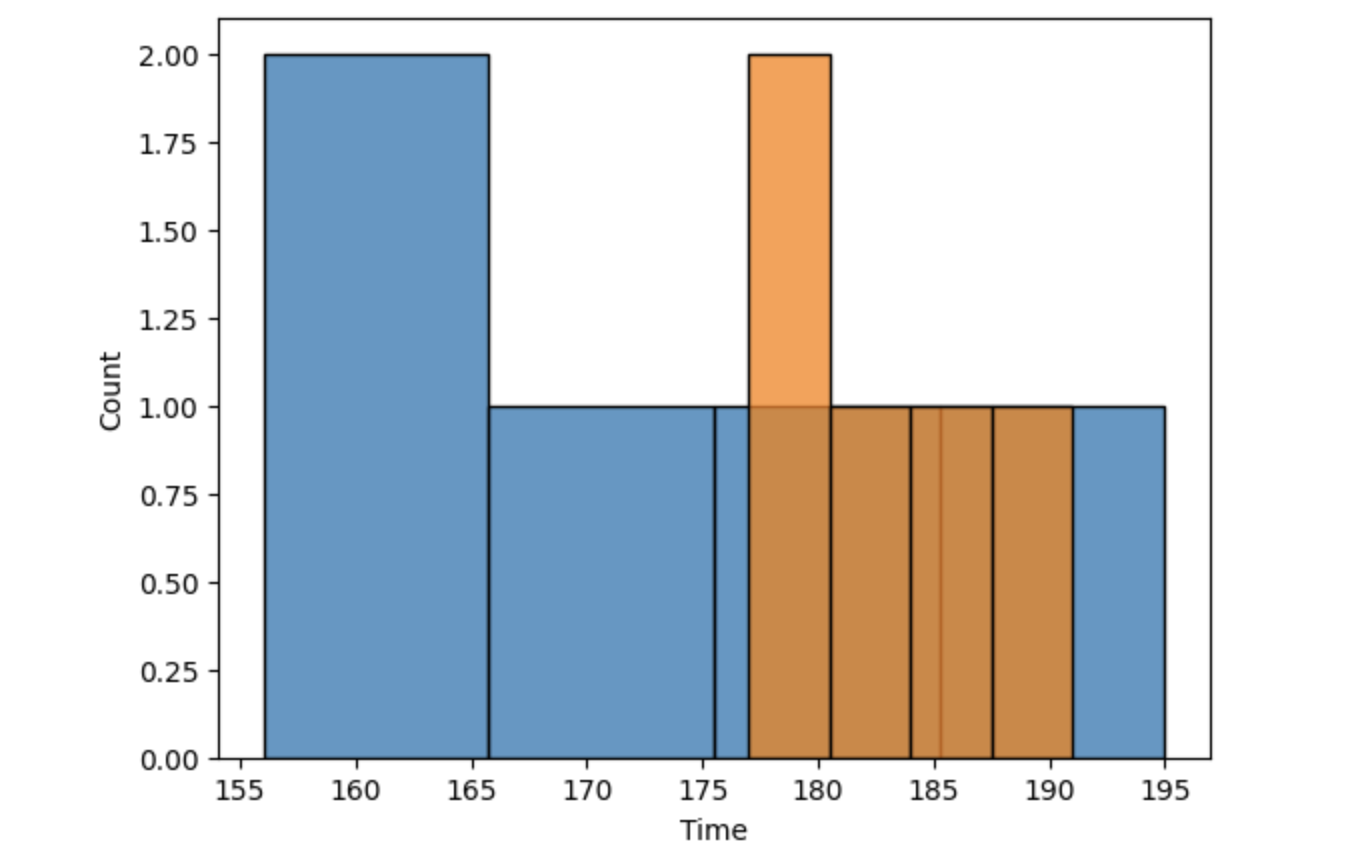
두 그룹의 체류 시간이 겹치는 구간도 있고, 분포의 모양에도 차이가 있는 것을 확인할 수 있다.
페이지별 평균 체류 시간 확인
# 페이지별 평균 체류 시간 확인
four_sessions.boxplot(by="Page", column="Time")
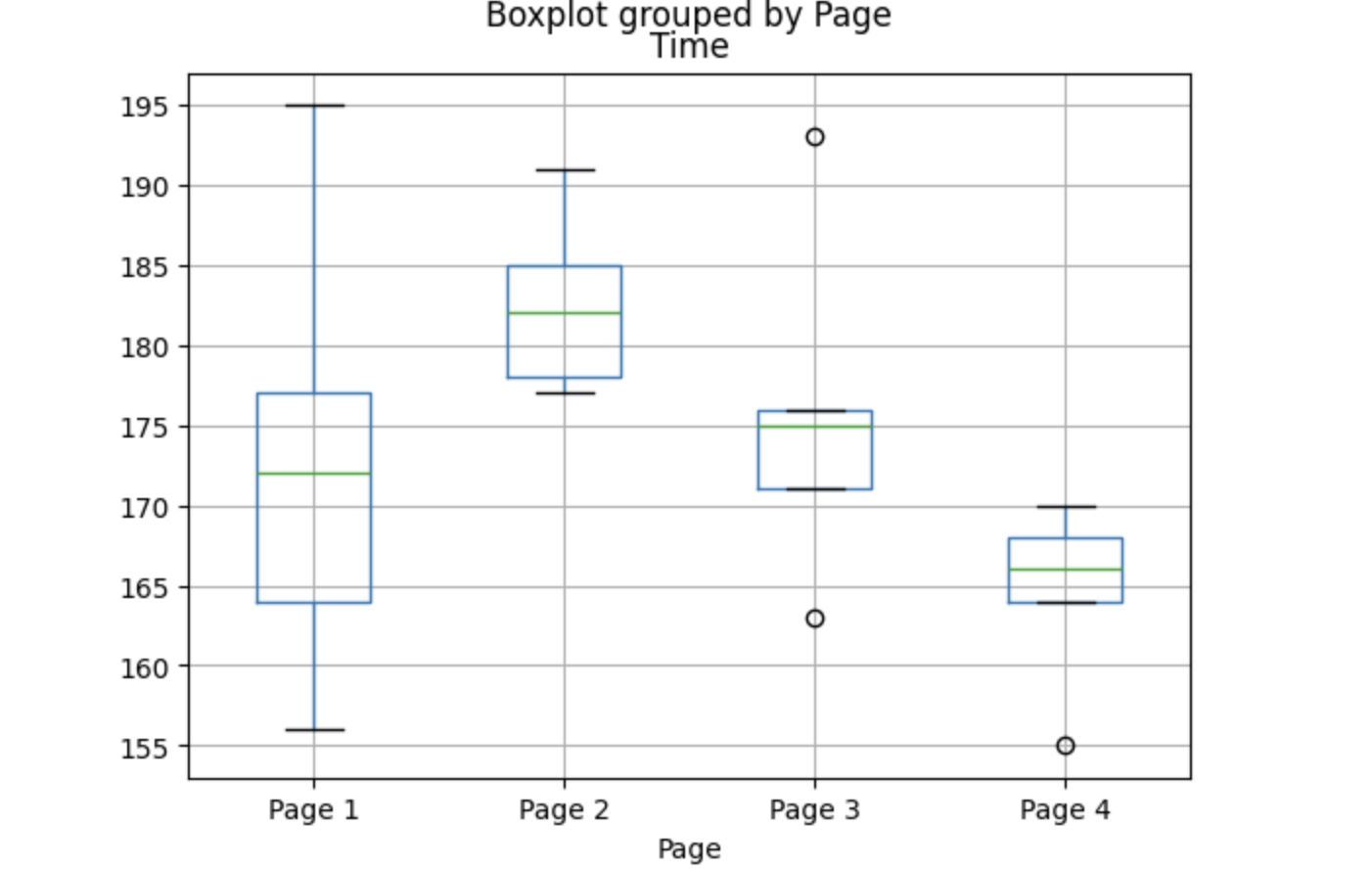
Page 2가 상대적으로 평균이 높고 이상치(outlier)도 적은 반면,
Page 4는 평균이 낮고 이상치가 존재한다.
ANOVA 수행
이제 실제로 네 개 페이지 그룹 간 평균 체류 시간의 차이가 유의미한지 검정해 보자.
- H0: 모든 페이지의 체류 시간은 같다.
- H1: 하나 이상의 페이지 체류 시간이 다르다.
from scipy.stats import f_oneway
group1 = four_sessions[four_sessions['Page'] == 'Page 1']['Time']
group2 = four_sessions[four_sessions['Page'] == 'Page 2']['Time']
group3 = four_sessions[four_sessions['Page'] == 'Page 3']['Time']
group4 = four_sessions[four_sessions['Page'] == 'Page 4']['Time']
group = [group1, group2, group3, group4]
f_oneway(*group)
F_onewayResult(statistic=2.7398, pvalue=0.0776)
p-value = 0.0776 > 0.05
⇒ 유의수준 0.05에서는 귀무가설을 기각하지 못한다. 즉, 통계적으로 유의한 차이라고 볼 수 없다.
하지만 p값이 0.1 이하로 낮은 편이기 때문에 사후검정을 진행하여 구체적인 차이를 살펴볼 수 있다.
사후검정 (Tukey's HSD)
from statsmodels.stats.multicomp import pairwise_tukeyhsd
tukey = pairwise_tukeyhsd(endog=four_sessions['Time'], groups=four_sessions['Page'])
print(tukey)
Multiple Comparison of Means - Tukey HSD, FWER=0.05
=====================================================
group1 group2 meandiff p-adj lower upper reject
-----------------------------------------------------
Page 1 Page 2 9.8 0.4379 -8.3984 27.9984 False
Page 1 Page 3 2.8 0.9706 -15.3984 20.9984 False
Page 1 Page 4 -8.2 0.5825 -26.3984 9.9984 False
Page 2 Page 3 -7.0 0.6943 -25.1984 11.1984 False
Page 2 Page 4 -18.0 0.0531 -36.1984 0.1984 False
Page 3 Page 4 -11.0 0.3416 -29.1984 7.1984 False
-----------------------------------------------------
tukey.plot_simultaneous()
plt.title("Tukey's HSD Test - Multiple Comparison")
plt.show()
이 그래프는 그룹 간 평균 차이의 신뢰구간을 시각화한 것이며, 0을 포함하지 않는 경우에만 해당 그룹 간 차이가 유의하다고 판단된다.
현재는 모든 구간이 0을 포함하고 있어, reject=False와 일치하는 시각적 결과를 보여준다.
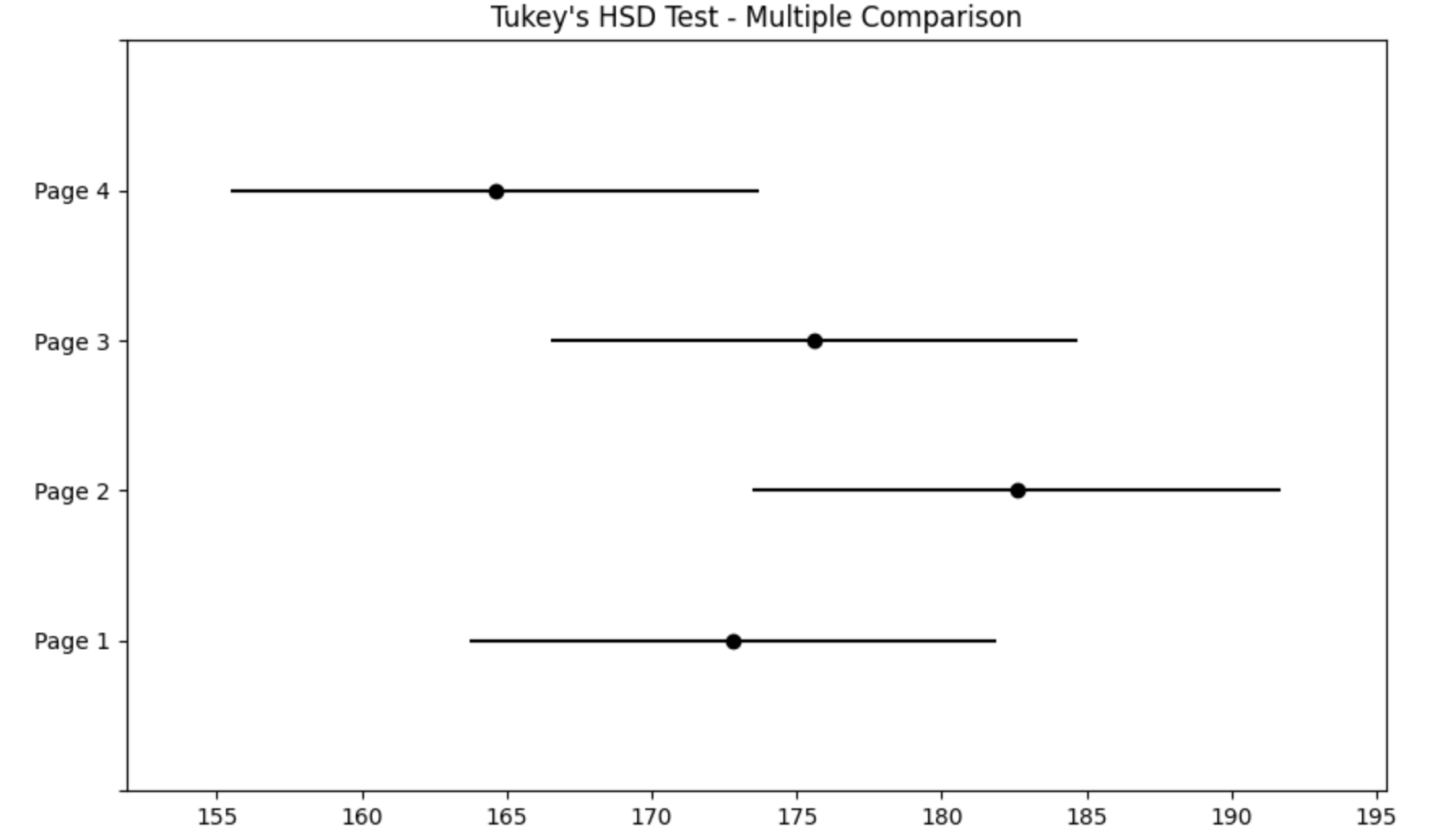
- 전체 ANOVA에서는
p = 0.0776으로 약한 유의성 - 사후검정에서도 모든 쌍에서
reject=False, 즉 통계적으로 유의한 쌍은 없음
하지만, Page 2와 Page 4 사이에는 주목할 만한 경향이 나타난다.
Page 2와 Page 4 간 평균 체류 시간의 차이에서 p = 0.0531로, 통계적으로 유의하다고 보긴 어렵지만(유의수준 0.05 기준), 유의미한 경향성은 나타났다.
특히 Page 2가 평균적으로 18초 더 높은 체류 시간을 보여, 해당 페이지의 콘텐츠나 구성에 대한 추가 분석도 가능하다고 본다.
왜 사후검정이 필요할까?
ANOVA는 여러 그룹 평균 비교에 효과적인 검정이다.
하지만 ANOVA는 전체 그룹 간 차이만 검정하기 때문에, 어떤 그룹 간 차이가 유의한지는 사후검정으로 확인해야 한다.
특히 여러 그룹 간 비교에서는 오류 누적 가능성 때문에 Tukey’s HSD 같은 사후검정을 사용해야 신뢰성 있는 해석이 가능하다.
지금까지 ANOVA와 사후검정 흐름을 직접 시뮬레이션해 보았다.
다수 그룹 비교를 할 때 불필요한 t-test 반복을 피할 수 있는 방법을 익히고, 사후검정을 통해 실제로 유의한 그룹을 명확히 식별하는 경험이 되었다. 시각화와 통계량 해석을 병행하는 것이 설명력과 해석력에 있어 중요하겠다.
앞으로 A/B/C 실험 진행할 때 단순히 평균만 비교하는 것이 아니라, 통계적 유의성과 시각화, 그리고 사후 해석까지 수행하는 습관을 가지고
통계적으로 신뢰할 수 있는 결론을 도출할 수 있도록 연습해야겠다.
