🖇 F-분포란?
🖇 ANOVA (분산분석)
🖇 사후검정: 어떤 그룹이 다른가?
데이터 분석에서는 “그룹 간 평균이 서로 다른가?”라는 질문이 자주 등장한다.
두 집단을 비교할 때는 t-test를 사용하지만, 세 집단 이상이라면 어떨까?
이럴 때 사용하는 것이 ANOVA(Analysis of Variance)이다.
아래의 블로그들에서 관련 개념을 이해하는 데 도움을 받아 남겨 본다.
카이제곱분포와 검정과 F분포와 분산분석
분산 분석(ANOVA): feat.(SST,SSE,SSB)
일원 분산분석(One-way ANOVA) (1) - 총편차, 집단 간 편차, 집단 내 편차(SST, SSB, SSW)
🖇 F-분포란?
F-분포는 두 집단의 분산을 비율로 다루는 방법으로, 두 개의 카이제곱을 나눈 비율에 대한 분포로 정의한다.
그룹 간의 차이(분산)와 그룹 내의 변동(분산)을 표현하며
ANOVA(분산 분석), 회귀 분석 등에 사용한다.
이미지는 위에서 언급한, 기초통계를 가르쳐 주신 임정 강사님의 블로그에서 가져온 이미지이다.
F 통계량
본격적으로 들어가기 전에 헷갈리기 쉬운 용어의 의미를 정리해 보았다.
| 기호 | 용어 | 의미 | |
|---|---|---|---|
| SSB | Sum of Squares Between | 그룹 간 제곱합 | 각 그룹 평균과 전체 평균 간 차이 |
| SSW | Sum of Squares Within | 그룹 내 제곱합 | 각 데이터와 소속 그룹 평균 간 차이 |
| MSB | Mean Square Between | 그룹 간 평균제곱 | SSB ÷ 그룹 자유도 |
| MSW | Mean Square Within | 그룹 내 평균제곱 | SSW ÷ 오차 자유도 |
- n: 전체 데이터 개수
- k: 그룹 개수
SST
/ \
SSB SSW
(그룹 간) (그룹 내)
↓ ↓
MSB = SSB / (k - 1) → 그룹 간 평균제곱
MSW = SSW / (n - k) → 그룹 내 평균제곱
⇒ F = MSB / MSW
자유도에 따른 F-분포
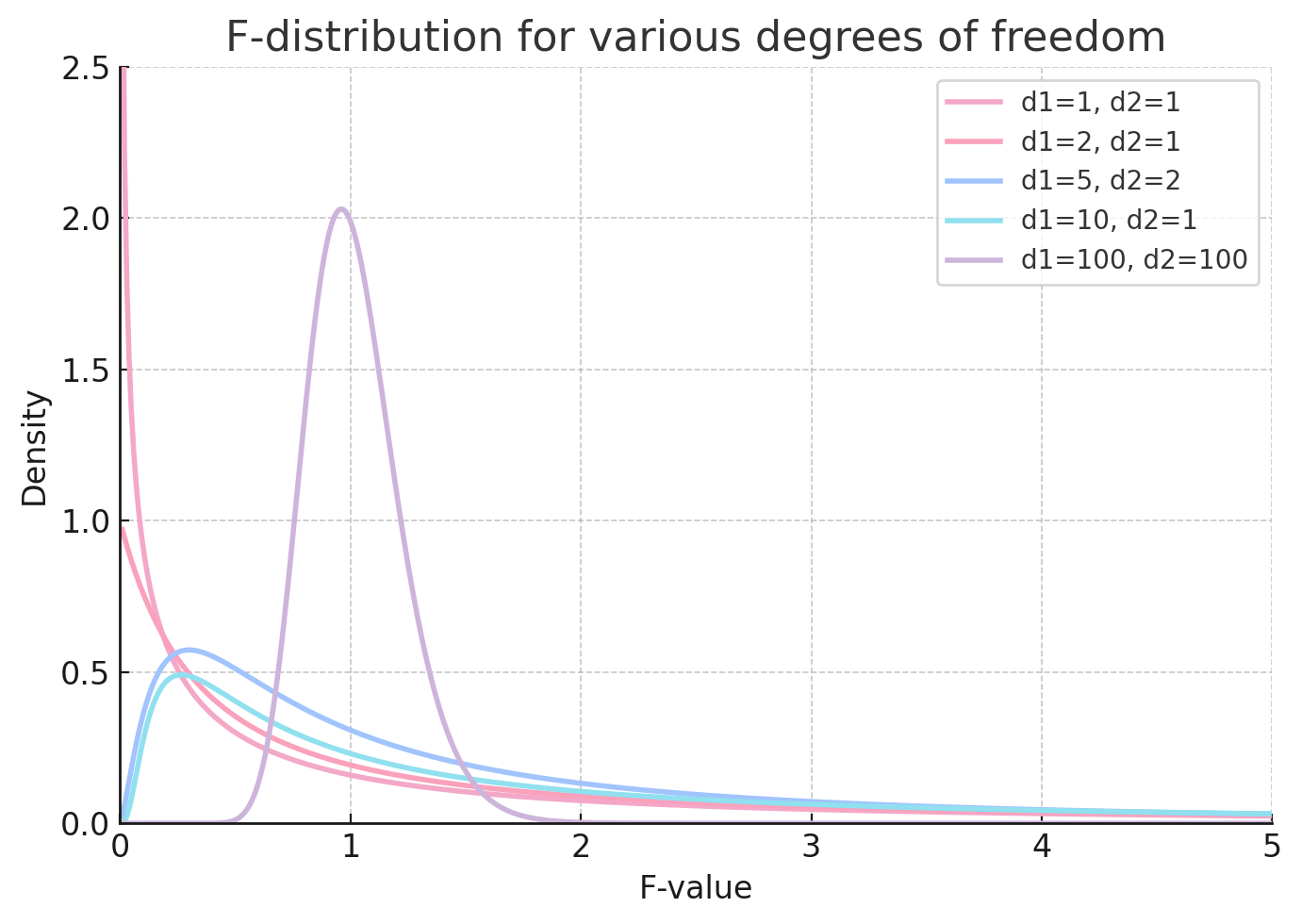
위 확률 밀도 함수 그래프는 자유도 (d1, d2)에 따른 F-분포의 모양을 보여준다.
- 자유도가 작을수록 분포가 비대칭적이고 꼬리가 길다.
- 자유도가 클수록 정규분포에 가까운 형태를 보인다.
- 특히
d1=100, d2=100의 경우 매우 정규분포에 근접한 분포를 나타낸다.
F값이 1보다 크면 그룹 간 분산이 더 크다는 것이다.
즉, 도출된 F 값이 클수록 그룹 간 평균의 차이가 크며 유의미한 차이를 보낸다.
SSB: 그룹 간 분산
각 그룹 평균이 전체 평균과 얼마나 차이가 나는지를 측정한다.
- : 번째 그룹의 번째 관찰 값
- : 번째 그룹의 평균
- : 번째 그룹의 관찰 값 수
그룹 간 자유도()는 전체 표본 갯수 - 1 이된다.
전체 평균을 알고 데이터를 알면 나머지 1개를 자연스럽게 알 수 있기 때문이다.
💡 Q. 그룹의 크기를 곱하는 이유
더 큰 그룹일수록 전체 평균에 더 많은 영향을 미치기 때문에, 그룹의 크기를 고려한 가중치를 부여하는 의미이다.
SSW: 그룹 내 분산
각 그룹 내부에서 개별 값들이 해당 그룹 평균에서 얼마나 벗어나는지를 측정한다.
그룹 내 자유도는()는 전체 데이터에서 그룹 수를 뺀 값이다().
그룹의 평균을 알고 나머지 데이터를 알면 나머지 1개를 알게되며 이를 나머지 그룹 모두 적용할 수 있기 때문이다.
🖇 ANOVA (분산분석)
ANOVA는 이렇게 계산된 F-통계량을 이용해 세 개 이상의 그룹의 평균 차이를 분산을 이용하여 유의미한지를 검정하는 방법이다.
- H₀: 집단 간 분산의 차이가 없다.
- H₁: 집단 간 분산의 차이가 있다.
Python에서는 sstats.f_oneway에 구현되어 있다.
🖇 사후검정: 어떤 그룹이 다른가?
ANOVA 결과가 유의미하다고 하더라도, 어떤 그룹 간에 차이가 있는지까지는 알려주지 않는다. 그래서 사후 검정(Post-hoc test) 이 필요하다.
사후검정은 ANOVA에서 평균의 차이가 있음을 검증한 후 어떤 그룹 간의 차이가 있는지 확인하는 방법이다.
Tukey’s HSD
Tukey’s HSD (Honestly Significant Difference) Test는 대표적인 사후검정 방법으로, 각 그룹 간 평균을 하나씩 비교하면서 차이를 검정한다.
- H₀: 두 그룹 간 평균이 동일
- H₁: 두 그룹 간 평균이 다르다
t-test와 사후 검정의 차이점
t-검정을 세 번(A-B, B-C, A-C) 반복하면 오류의 누적 확률이 커지는 문제가 있다.
- 1종 오류 누적 확률:1−(1−α)n=1−0.953≈14.3
t검정은 오류의 누적확률이 증가하는 문제가 있다.
A,B,C 그룹이 있을 때 A-B / B-C / A-C 3가지 조합에 대해서 t 검정을 시행하면 각 시행마다의 1종 오류(귀무가설이 사실인데 기각하는 오류)가 발생한다.
이를 유의수준 0.05로 관리해 왔지만, t 검정을 반복하게 되면 실제 오류율은 0.05보다 높아진다.
(n= 3일 때, 누적 오류율 약 14.3%)
누적된 1종 오류율:
- 𝑛: 검정 시행수
이 때문에 사후검정에서는 여러 검정을 동시에 고려하여 누적 오류를 통제하는 방식이 사용된다.
사후검정 구현을 위한 라이브러리
Tukey’s HSD는 scipy가 아니라 statsmodels 라이브러리에서 제공된다.
from statsmodels.stats.multicomp import pairwise_tukeyhsd
💡 statsmodels는 Sklearn과 달리 회귀, 분산분석 등 통계 분석을 위한 정교한 결과를 제공한다.
우리가 분석하고자 하는 대부분의 현상은 단일 비교보다도 복수 그룹 간의 차이를 파악해야 하는 경우가 많다. 세 집단 이상을 비교하는 상황에서 F 통계량의 해석과 사후 검정의 필요성을 자주 마주치게 될 것이라 확실히 이해하고 넘어가기 위해 정리해 본다. 더 공부하면서 알게된 사실이 생기면 이 글에 추가하거나 새로운 글로 남겨 보겠다.
F분포와 ANOVA를 이해함으로써 p-value만 보는 것이 아닌, 왜 그런 값이 나왔는지 그 의미를 해석하고 다음 분석 방향을 제시할 수 있게 되어야 한다.
