통계적으로 의미 있는 차이가 있는지를 확인하기 위해 가설 검정(hypothesis testing)이 필요하다.
가설 검정은 모집단에 대한 주장을 표본 통계량을 이용해 검토하고, 그 주장을 기각할지 유지할지를 결정하는 통계적 추론 방법이다. 쉽게 말하면, 수집된 데이터를 바탕으로 어떤 가설이 타당한지를 검정하는 절차다.
가설 검정의 기본 구조
1.1 가설 설정
통계적 가설검정은 모집단의 특성에 대한 주장을 가설을 세우고 표본에서 얻은 정보를 통해 가설이 옳은지 판정하는
과정이다.
가설은 귀무가설과 대립가설로 구분한다.
- 귀무가설 (H₀): 현재 믿어지고 있는 가설, 실험과 연구를 토해 기각하고자 하는 가설
- 대립가설 (H₁): 새로운 주장 또는 차이가 있다는 가설
예를 들어, “학생들의 평균 성적이 70점이다” 가 H₀라면, “70점이 아니다” 는 H₁이 된다.
통계학은 일단 귀무가설을 지지하며 전개하다가 모순이 나오면 기존의 가설을 폐기하는 식으로, 귀류법으로 논리를 전개한다.
1.2 검정통계량(Test Statistics)
표본의 평균과 귀무가설 하의 평균 간 차이가 표본 오차 수준에서 얼마나 벗어나는지를 수치화한 값으로, 가설을 검정할 목적으로 정의하는 통계량이다.
검정통계량은 z검정과 t검정 중 상황에 따라 달라진다.
1.3 유의수준 (Significance level, α)
귀무 가설이 참 인데도 잘못 기각할 오류를 범할 최
대 허용 한계로, 일반적으로 5%를 사용한다.
유의 수준이 5%라는 것은 대부분의 경우 95% 귀무가설을 채택하여 본래 이론을 유지한다는 것이다. 5%경우 에만 대립가설 채택한다.
1-4. P-value
P-value는 H₀ 이 옳다는 가정 하에서 실제의 관측치 또는 그 이상으로 극단적인 관측치의 값을 얻을 확률이다.
- P-value가 0.05보다 크다면 -> 귀무가설 채택, 대립가설 기각
- P-value가 0.05보다 작다면 -> 귀무가설 기각, 대립가설 채택
가설 설정 절차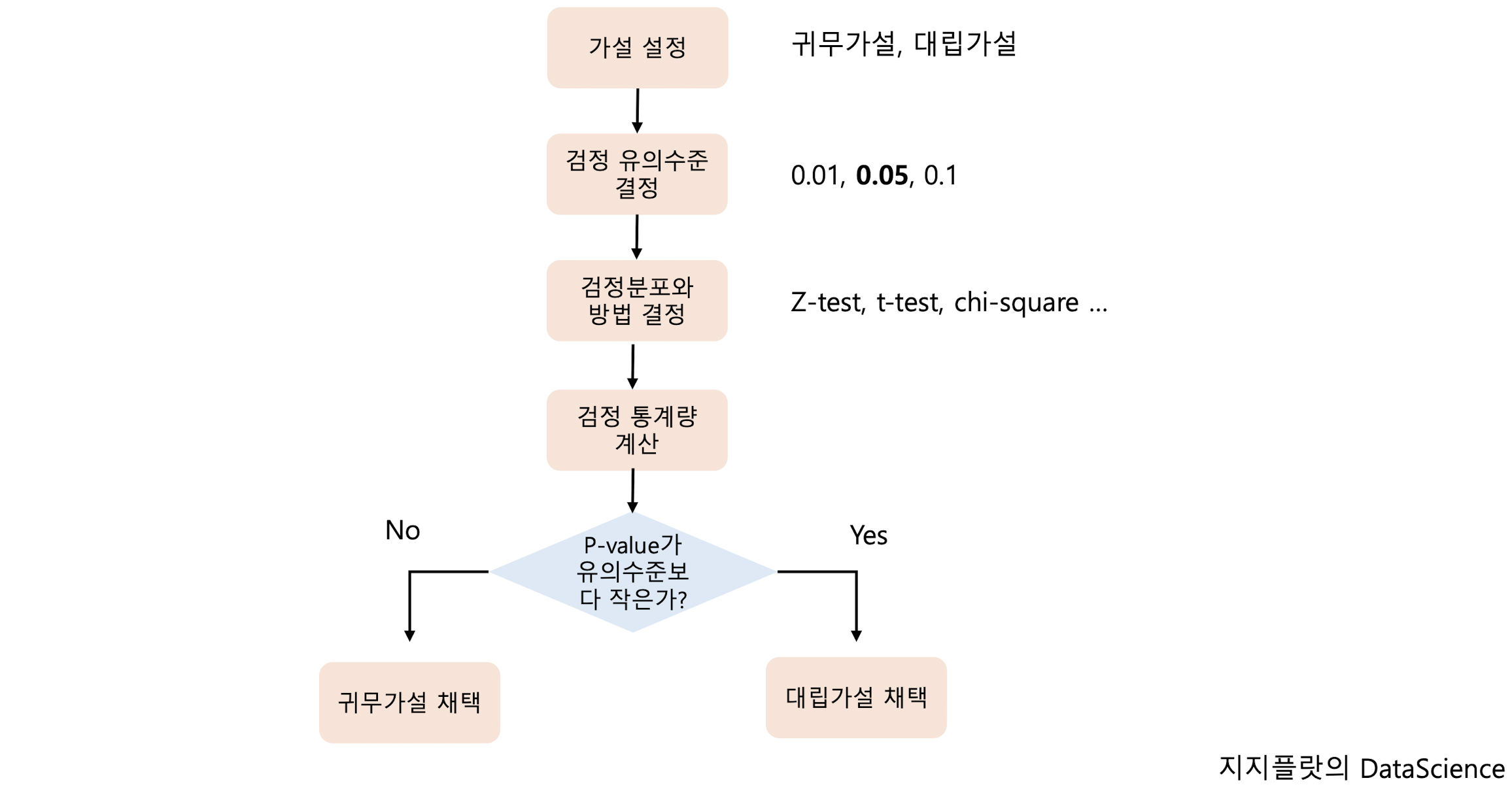
상황에 따른 검정방법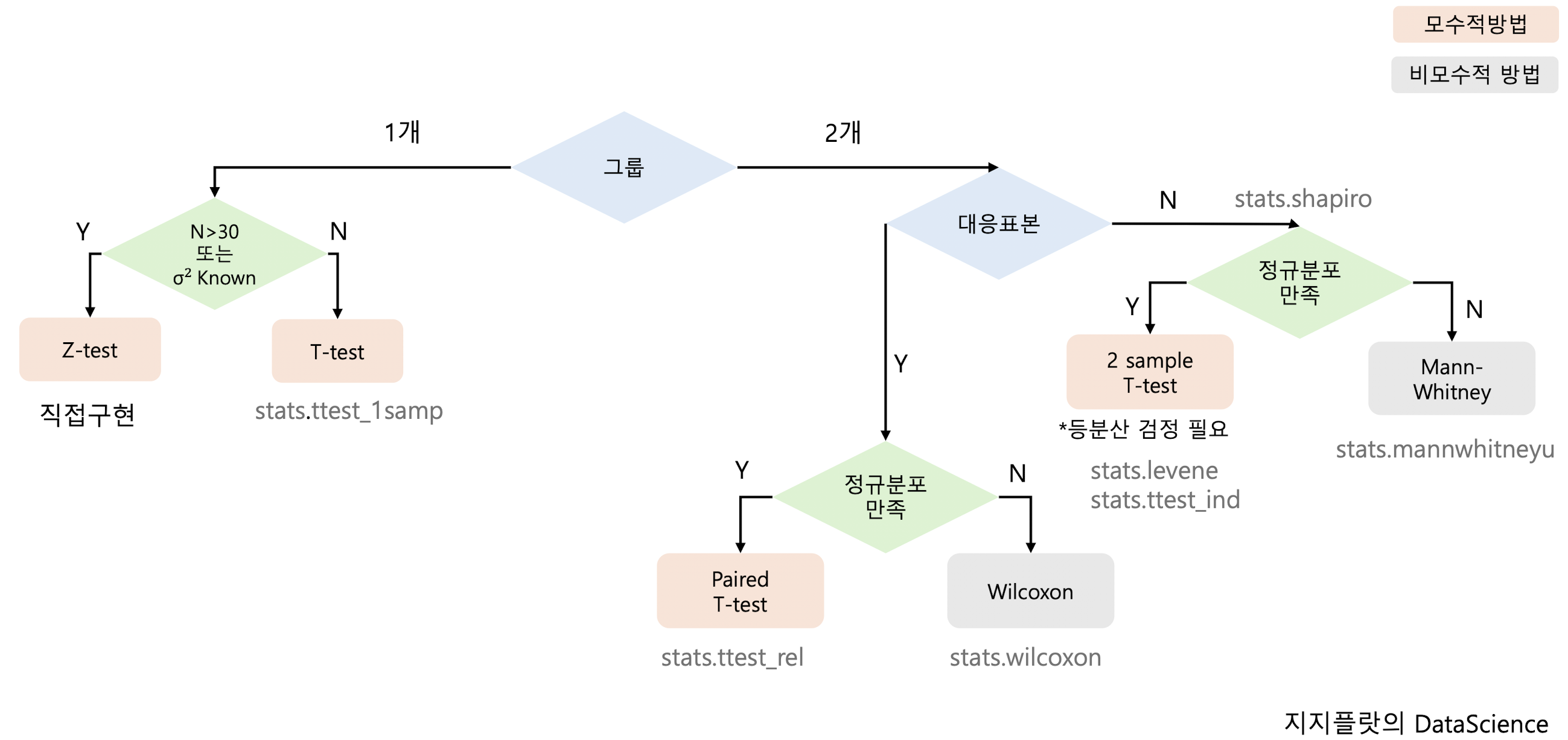
Scipy-status 모듈
## scipy.stats 구조 및 기능 설명
scipy
└── stats # 통계 분석과 확률 분포 관련 함수 제공
├── norm # 정규분포 관련 함수 (PDF, CDF, 랜덤 샘플링 등)
├── uniform # 균등분포
├── bernoulli # 베르누이 분포
├── binom # 이항분포
├── ttest_ind # 독립 두 표본에 대한 t-검정
├── ttest_rel # 대응표본 t-검정
├── mannwhitneyu # Mann-Whitney U 비모수 검정
├── chi2_contingency # 카이제곱 독립성 검정
├── shapiro # Shapiro-Wilk 정규성 검정
├── kstest # Kolmogorov-Smirnov 검정 (분포 적합성 검정)
├── probplot # Q-Q plot 생성 (정규성 시각화)
├── pearsonr # Pearson 상관계수 계산
├── spearmanr # Spearman 순위 상관계수 계산
└── describe # 기술 통계량 제공 (평균, 표준편차 등)z검정
모집단이 정규분포를 만족하고, 모집단의 분산(σ²)을 알고 있을 때 사용하는 검정 방법이다.
-
양측검정
• 귀무가설: 모집단 평균(𝜇)이 특정 값(𝜇0)과 같을 것이다.
• 대립가설: 모집단 평균(𝜇)이 특정 값(𝜇0)과 같지 않을 것이다. -
단측 검정
• 귀무가설: 모집단 평균(𝜇)이 특정 값(𝜇0)보다 클 것이다.
• 대립가설: 모집단 평균(𝜇)이 특정 값(𝜇0)보다 작을 것이다.
검정통계량
- : 표본 평균
- : 귀무가설에서의 모평균
- : 모집단의 표준편차
- : 표본 수
t검정
모집단이 정규분포를 만족하지만, 모집단의 분산을 모를 경우 사용하는 방법으로, 두 그룹의 평균을 비교하는 경우 사용한다.
→ 따라서 표본 표준편차(s)를 이용하여 검정통계량을 계산한다.
표본의 분산으로 모집단의 분산을 추정하며, 자유도(df) = n - 1인 t분포를 사용한다.
• 귀무가설: 두 집단의 평균이 같다.
• 대립가설: 두 집단의 평균이 다르다.
두 그룹의 등분산성, 정규성에 따라 검정 방법이 다르다.
- A/B test는 동일한 모집단에서 랜덤하게 배정하므로 등분산성을 만족한다.
- N >= 30 경우 일반적으로 정규성이 만족하다고 알려져 있다.
따라서, 대부분 독립 이표본 t-test를 적용한다.
만약 ab test가 아닌 일반적인 관찰연구라면, scipy.ttest_ind 함수 전달인자를 바꾸거나 적용되는 함수를 바꾸면 된다.
검정통계량
- : 표본 표준편차
t분포는 z분포보다 꼬리가 두껍고, 표본 수가 늘어날수록 z분포에 가까워진다.
정규성 가정과 등분산 가정
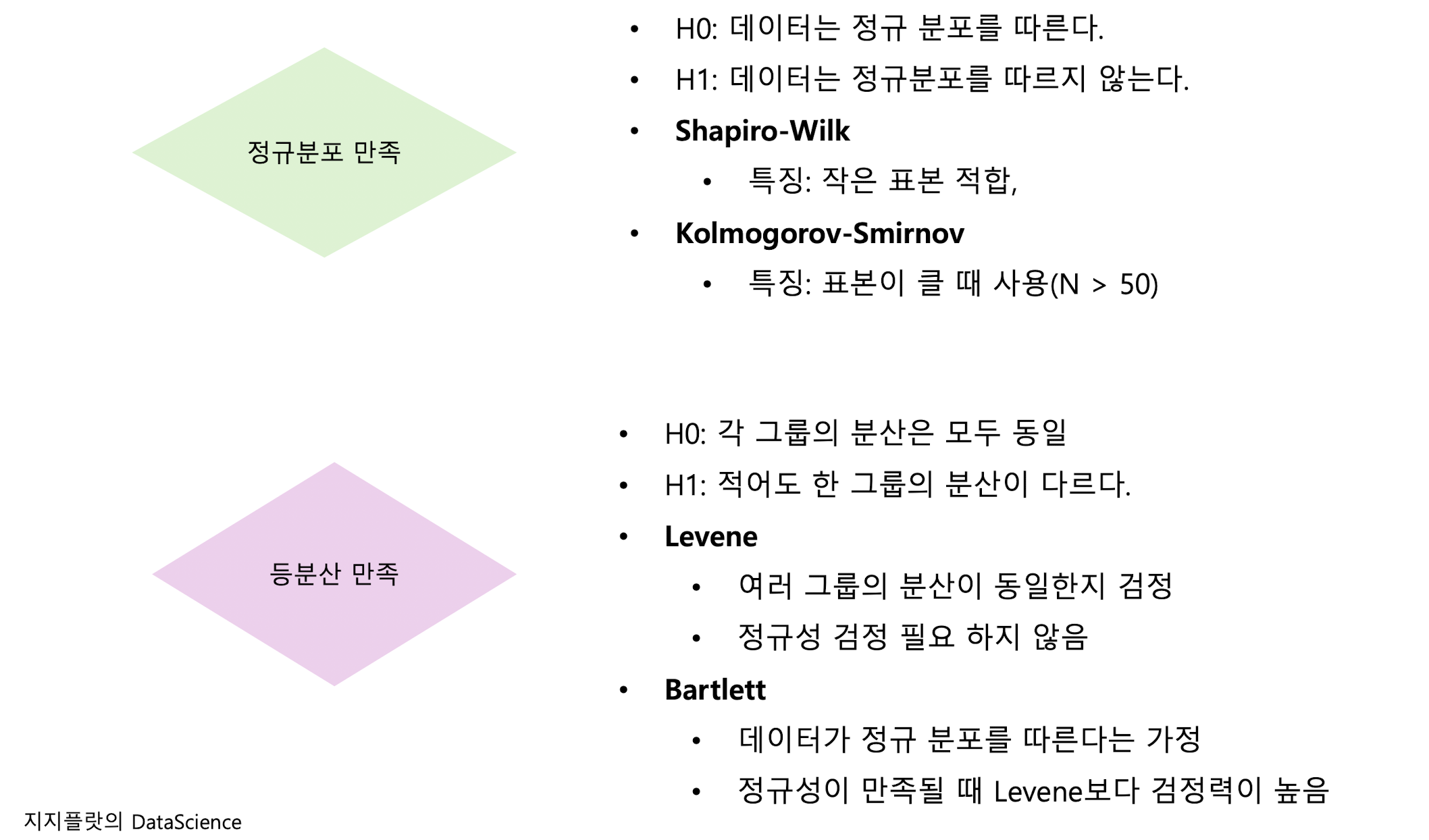
정규성 가정
z검정과 t검정 모두 모집단이 정규분포를 따라야 한다는 전제가 필요하다.
이는 특히 표본 수가 적은 경우 더 엄격하게 요구된다.
등분산 가정
독립표본 t검정에서는 두 집단의 분산이 동일하다는 등분산성 가정(homoscedasticity)이 필요하다.
이를 만족하지 않는다면 Welch의 t검정(이분산 t검정)을 사용해야 한다.
검정 방향
- 양측검정: 평균이 다르다
- 좌측 단측검정: 평균이 작다
- 우측 단측검정: 평균이 크다
기각 기준이 어느 쪽에 위치하는지를 유의수준에 따라 설정한다.
검정 방향에 따라 유의수준 분할 방식과 임계값 해석이 달라진다.
오류의 유형
1종 오류
일반적으로 귀무가설(H₀)은 믿어지고 있는 본래 사상, 주제이고 대립가설 (H₁) 은 새로운 주장이다.
귀무가설이 참 인데도 불구하고 귀무가설을 채택하지 않는 오류인 1종 오류를 관리하는게 일반적이다.
-
e.g., 고혈압 약 개발
-
이를 검정한 결과가 실제로는 고혈압약이 효능이 없었는데도 불구하고 시판하면 국민의 위해성이 걱정된다. 따라서 이를 관리하는 지표로 놓고 엄격하게 관리한다. 이를 유의수준(𝛼, significance level)이라고 한다.
2종 오류
2종오류는 실제로 효능이 있는데도 불구하고 효능이 없다 라고 판단하는 오류이다.
- 국민의 위해성에는 관련이 없기 때문에 1종오류보다 덜 엄격하게 관리한다. 사실 이 1종 오류, 2종 오류는 trade off가 있어서 둘 다 낮은 수준으로 관리할 수 없다.
- 새로운 고혈압약을 통계 검정한 결과가 실제로는 고혈압약이 있는데도 불구하고 거절하게 된다면 국민의 편익이 저해된다
| 오류 종류 | 설명 | 확률 기호 |
|---|---|---|
| 제1종 오류 | H₀가 참인데 기각함 | α |
| 제2종 오류 | H₀가 거짓인데 기각 못함 | β |
검정력 (Power of the Test)
검정력은 제2종 오류를 범하지 않을 확률, 즉 대립가설이 참일 때 귀무가설을 올바르게 기각할 수 있는 확률로 정의된다.
검정력이 높다는 것은 대립가설이 참일 때, 귀무가설을 정확히 기각할 수 있다는 뜻이다.
검정력을 높이는 방법
-
유의수준()을 높인다
-
표본 수()를 증가시킨다
-
효과 크기()를 키운다
-
표본의 표준편차를 줄인다
샘플 크기 산정 공식
몇 개의 데이터를 수집해야 하는가는 탐지하고자 하는 효과 크기, 유의수준, 검정력에 영향을 받는다.
일반적으로 유의수준(0.05), 검정력(80%)가 산업계표준. 따라서 탐지하고자 하는 크기를 결정하면 된다.
정규분포 가정 하에서, 유의수준과 검정력을 모두 고려해 필요한 표본 수를 계산하는 공식은 다음과 같다.
- 𝑍𝛼: 𝛼에 대응하는 정규분포 z-값
- 𝑍𝛽 : 𝛽에 대응하는 정규분포 z-값
- : 탐지하고자 하는 크기
정리해 보면, 실제 분석에서 검정을 적용하기 전 반드시 다음을 검정해 보아야 한다는 것을 알 수 있었다.
- 모집단은 정규분포를 만족하는가?
- 모집단의 분산을 알고 있는가?
- 등분산성을 가정할 수 있는가?
- 양측검정인가, 단측검정인가?
- 필요한 표본 수는 충분한가?
정성적인 부분도 있기 때문에 P-value를 맹신하면 안 되고, 다방면으로 고려해야 다른 차원에서도 살펴보고 판단해야 한다는 시야를 넓히게 되었다.
[이 글에서 사용된 이미지는 모두의 연구소에서 기초통계학 임정 강사님이 제공해 주신 유의성 검정과 절차, 통계방법론 정리 이미지로, 무단 복제 및 가공을 금지합니다.]
