앞선 글에서 모평균의 신뢰도를 구하기 위해 중심극한정리(CLT, Central Limit Theorem) 를 이해해야 한다고 언급했다.
중심극한정리란 모집단의 분포가 어떤 형태이든 간에, 표본 크기 n이 충분히 크다면 그 표본들의 평균은 정규분포를 따르게 된다는 통계 이론이다.
이 글에서는 이 개념을 직접 데이터를 생성하고 시각화하면서 왜 CLT가 중요한지, 그리고 어떻게 정규성에 수렴하는지를 직접 확인해 보았다.
1. 모집단 데이터 생성: 다양한 분포로부터의 샘플 생성
중심극한정리에서 중요한 건 "모집단의 분포가 정규분포가 아니어도 된다"는 점이다.
이를 실험으로 확인하려면 정규분포와는 거리가 먼 분포를 포함시켜야 의미가 있다.
- 이항분포 (Binomial): 이산형 비대칭 분포
- 균등분포 (Uniform): 비정규적이고 납작한 분포
- 정규분포 (Normal): 본래부터 정규성을 가진 분포
우선 scipy.stats를 활용하여 서로 다른 분포로부터 1,000개의 데이터를 생성해보자.
import matplotlib.pyplot as plt
import seaborn as sns
import random
import numpy as np
from scipy import stats
from scipy.stats import binom, uniform, norm
np.random.seed(42)
# scipy를 통한 샘플 생성
sample_size = 1000
binomial_data = binom.rvs(n=10, p=0.5, size=sample_size) # 동전을 10번 던졌을 때 성공 횟수
uniform_data = uniform.rvs(loc=0, scale=10, size=sample_size) # 0~10 사이의 균등 분포
normal_data = norm.rvs(loc=0, scale=1, size=sample_size) # 평균 0, 표준편차 1인 정규분포
print(f'이항분포 데이터의 예시 {binomial_data[:5]}')
print(f'균등분포 데이터의 예시 {uniform_data[:5]}')
print(f'정규분포 데이터의 예시 {normal_data[:5]}')
이항분포 데이터의 예시 [4 8 6 5 3]
균등분포 데이터의 예시 [1.85132929 5.41900947 8.72945836 7.32224886 8.06561148]
정규분포 데이터의 예시 [-0.87798259 -0.82688035 -0.22647889 0.36736551 0.91358463]이제 중심극한정리를 실험할 세 가지 서로 다른 분포의 "모집단" 데이터를 확보했다.
다음으로 이 데이터들이 실제로 어떤 분포를 가지고 있는지를 먼저 시각적으로 확인해 보자.
2. 모집단 히스토그램 시각화
중심극한정리가 말하는 "어떤 분포라도"가 실제로 얼마나 다양한지를 시각적으로 보여줄 필요가 있다.
이를 통해 나중에 정규분포로 수렴되는지 비교할 기준선을 만든다.
import matplotlib.pyplot as plt
plt.figure(figsize=(15, 5))
plt.subplot(1, 3, 1)
plt.hist(binomial_data, bins=20, color='blue', alpha=0.7)
plt.title('Binomial Distribution')
plt.subplot(1, 3, 2)
plt.hist(uniform_data, bins=20, color='green', alpha=0.7)
plt.title('Uniform Distribution')
plt.subplot(1, 3, 3)
plt.hist(normal_data, bins=20, color='red', alpha=0.7)
plt.title('Normal Distribution')
plt.tight_layout()
plt.show()
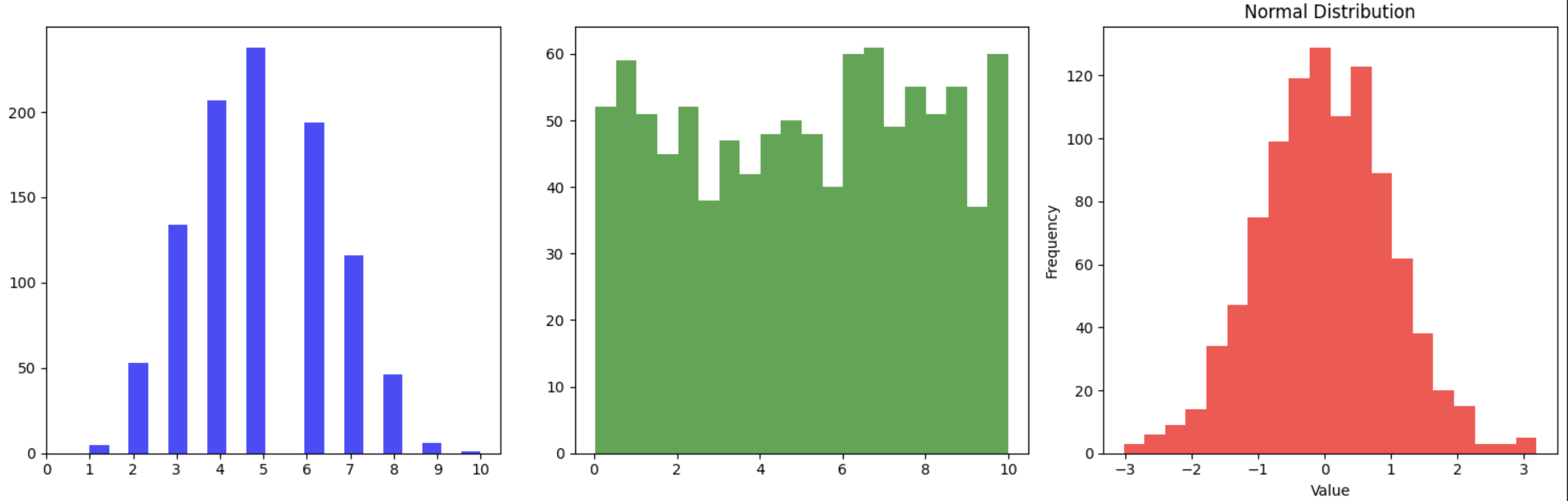
세 가지 서로 다른 분포를 시각화해 보면, 정규분포를 제외한 두 분포는 정규성과 거리가 있는 모양임을 확인할 수 있다.
이제 이들 분포에서 데이터를 뽑아 평균을 낸 결과가 정말 정규성을 띠는지 실험해 보자.
3. 표본 평균 생성: 중심극한정리 실험
CLT는 모집단이 아니라 “표본 평균의 분포”에 대한 정의이다.
이제 각 분포에서 30개의 데이터를 복원추출해서 평균을 계산하는 과정을 500번 반복해 보자.
# 표본 추출할 횟수와 자료형(sample_mean)정의
num_samples = 500
sample_means = { # DataFrame으로 관리하기 용이
'Binomial': [],
'Uniform': [],
'Normal': []
}
#numpy.choice을 통해 샘플의 평균을 구하여 sample_means 딕셔너리 자료형에 각각 저장
for _ in range(num_samples):
sample_means['Binomial'].append(np.mean(np.random.choice(binomial_data, size=30, replace=True)))
sample_means['Uniform'].append(np.mean(np.random.choice(uniform_data, size=30, replace=True)))
sample_means['Normal'].append(np.mean(np.random.choice(normal_data, size=30, replace=True)))
print(f'이항분포 표본에서 30개씩 뽑아 평균을 낸 값 {sample_means}')
이항분포 표본에서 30개씩 뽑아 평균을 낸 값 {'Binomial': [np.float64(5.2), np.float64(4.733333333333333), np.float64(5.066666666666666), np.float64(5.233333333333333), ...np.random.choice(..., replace=True)는 복원추출로, CLT에서 일반적인 조건이다.- n=30은 통계학에서 정규성 수렴을 기대할 수 있는 일반적인 기준 중 하나로, 경험적으로 정규성 수렴이 나타나기 시작하는 표본 크기이다.
이제 각 분포에서 생성한 500개의 표본 평균이 준비되었다.
이 표본 평균 분포들이 실제로 정규분포를 따르게 되는지, 히스토그램으로 시각화해서 확인해보자.
4. 표본 평균 분포 시각화: 정규성 확인
지금까지 다양한 분포에서 표본을 뽑아 평균을 냈다.
이 평균들이 정규분포를 따르는지를 히스토그램을 통해 직접 확인해 보자.
plt.figure(figsize=(15, 5))
plt.subplot(1, 3, 1)
plt.hist(sample_means['Binomial'], bins=20, color='blue', alpha=0.7)
plt.title('Sample Means - Binomial')
plt.subplot(1, 3, 2)
plt.hist(sample_means['Uniform'], bins=20, color='green', alpha=0.7)
plt.title('Sample Means - Uniform')
plt.subplot(1, 3, 3)
plt.hist(sample_means['Normal'], bins=20, color='red', alpha=0.7)
plt.title('Sample Means - Normal')
plt.tight_layout()
plt.show()
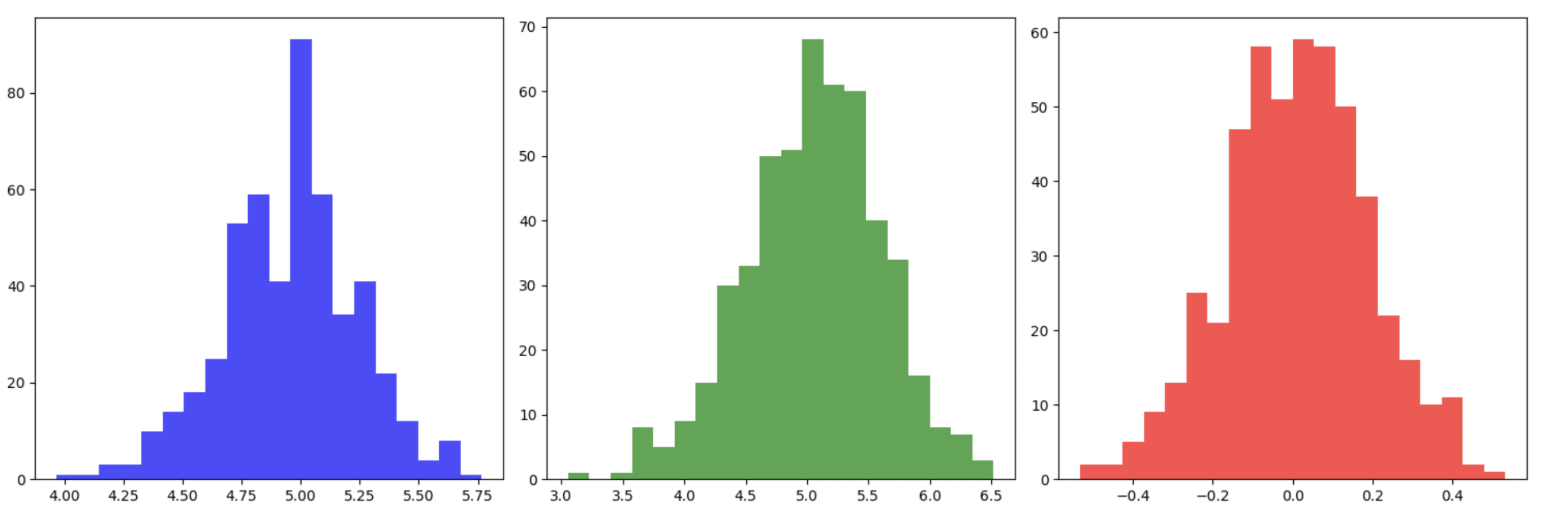
모집단 분포가 어떤 형태였든, 표본 평균의 분포는 모두 종 모양의 정규분포에 수렴하고 있다는 것을 확인할 수 있다.
특히 이항분포와 균등분포처럼 비정규적인 분포조차도, 반복적으로 표본평균을 구하면 정규성을 띤 분포가 형성된다.
이것이 바로 중심극한정리의 핵심이다.
이번 실험을 통해 중심극한정리(CLT)가 단순히 이론이 실제 데이터를 통해 관찰 가능한 통계 법칙임을 확인할 수 있었다.
어떤 분포에서 표본을 추출하더라도, 그 평균의 분포는 정규성을 갖게 된다.
따라서 신뢰구간 추정이나 가설검정에서 정규분포를 가정할 수 있는 근거가 생긴다.
