앞선 글에서 카이제곱 검정을 이해한 후, 통계적 사고력과 분석 능력을 키우기 위해 직접 시뮬레이션해 보았다.
다음과 같은 흐름으로 시행하였다.
- 카이제곱 분포 재현
- 적합도 검정
- 독립성 검정
- 동질성 검정
- 카이제곱 검정으로 헤드라인 클릭률 비교
본격적으로 들어가기 전에, 왜 카이제곱 검정이 필요한지 생각해 보았다.
데이터 분석을 하다 보면 두 범주형 변수 간의 관련성 여부나, 특정 분포가 기대한 비율과 일치하는지를 판단해야 할 때가 있다.
예를 들어
남성과 여성의 흡연 여부가 독립적인지, 광고 문구에 따라 클릭률에 차이가 있는지, 고객 방문 비율이 우리가 예상한 비율과 얼마나 유사한지를 알고 싶은 경우가 이에 해당한다.
이때 사용하는 대표적인 통계 기법이 카이제곱 검정(Chi-Square Test)이다.
카이제곱 검정은 크게 다음 세 가지 상황에 사용된다.
- 적합도 검정(Goodness of Fit): 관찰된 분포가 기대 분포와 유사한지 검정
- 독립성 검정(Test of Independence): 두 범주형 변수 간의 관련성 검정
- 동질성 검정(Test of Homogeneity): 여러 집단 간의 분포가 같은지 비교
이 글에서는 위 세 가지 검정의 이론적 배경을 간단히 짚은 뒤, 직접 코드를 통해 카이제곱 검정을 구현하며 각 단계의 의미를 구체적으로 정리해 보았다.
1. 카이제곱 분포 재현하기
카이제곱 분포는 정규분포를 따르는 확률변수의 제곱합으로 정의된다.
이 성질을 직접 확인해보며 카이제곱 분포가 어떻게 구성되는지 시각적으로 재현해 보자.
정규 분포를 따르는 난수를 생성한 후, 제곱하여 더하면 자유도(df)에 따른 카이제곱 분포를 얻을 수 있다.
# scipy.stats.norm.rvs: 정규 분포 자료 생성 함수
# scipy.stats.chi2.pdf: 카이제곱 분포 생성 함수
import random
import pandas as pd
import numpy as np
import matplotlib.pylab as plt
from scipy import stats정규 분포 샘플 생성 및 카이제곱 분포 재현
# 샘플 수 설정
n_samples = 10000
# 정규분포 샘플 생성 (loc=0, scale=1인 표준 정규분포)
z1 = stats.norm.rvs(loc=0, scale=1, size=n_samples)
z2 = stats.norm.rvs(loc=0, scale=1, size=n_samples)
z3 = stats.norm.rvs(loc=0, scale=1, size=n_samples)
# z의 제곱을 통해 자유도별 카이제곱 통계량 생성
chi2_1 = z1**2
chi2_2 = z1**2 + z2**2
chi2_3 = z1**2 + z2**2 + z3**2이때 생성한 chi2_1, chi2_2, chi2_3는 각각 자유도가 1, 2, 3인 카이제곱 분포를 나타낸다.
카이제곱 분포 시각화
plt.figure(figsize=(8, 5))
x = np.linspace(0, 15, 1000)
plt.xlim(0, 15)
# 정규분포 제곱 합으로 얻은 히스토그램
plt.hist(chi2_1, bins=100, density=True, alpha=0.6, label='Chi-square (df=1)', color='blue')
plt.hist(chi2_2, bins=100, density=True, alpha=0.6, label='Chi-square (df=2)', color='green')
plt.hist(chi2_3, bins=100, density=True, alpha=0.6, label='Chi-square (df=3)', color='red')
# 이론적인 카이제곱 분포 곡선 추가
plt.plot(x, stats.chi2.pdf(x, df=1), 'b--', label='Theoretical (df=1)')
plt.plot(x, stats.chi2.pdf(x, df=2), 'g--', label='Theoretical (df=2)')
plt.plot(x, stats.chi2.pdf(x, df=3), 'r--', label='Theoretical (df=3)')
plt.title('Chi-square Distribution for Different Degrees of Freedom')
plt.xlabel('Value')
plt.ylabel('Density')
plt.legend()
plt.grid()
plt.show()
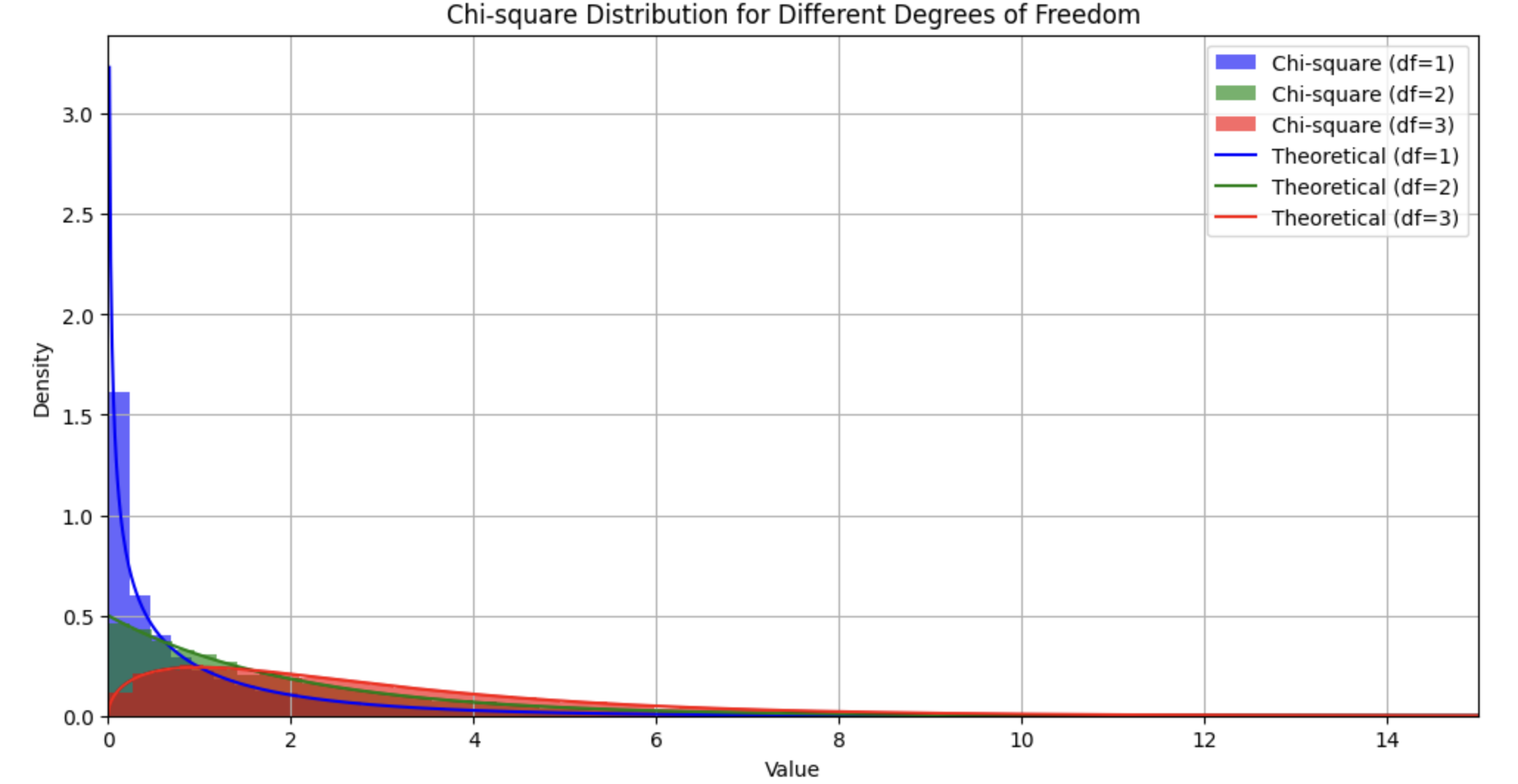
위 결과는 정규분포의 제곱합이 실제로 이론적인 카이제곱 분포와 잘 일치함을 보여준다.
자유도가 증가할수록 분포가 오른쪽으로 이동하며 점점 정규분포와 유사해지는 모습도 확인할 수 있다.
2. 적합도 검정
적합도 검정은 실제로 관측된 빈도와 기대되는 비율(이론적 분포)이 일치하는지를 확인할 때 사용한다.
어떤 제품군에 대해 예상한 방문 비율이 있고, 실제 관찰된 비율이 이와 얼마나 일치하는지를 확인하고자 할 때 사용할 수 있다.
# 기대 비율 정의 (% 단위)
expected_ratios = np.array([10, 10, 15, 20, 30, 15])
total_visits = 200
expected_counts = (expected_ratios / 100) * total_visits
# 실제 관측된 방문 수
observed_counts = np.array([30, 14, 34, 45, 57, 20])
# 카이제곱 적합도 검정
chi2_stat, p_val = stats.chisquare(f_obs=observed_counts, f_exp=expected_counts)
# 결과 출력
print(f"Chi-squared Statistic: {chi2_stat:.3f}")
print(f"P-value: {p_val:.3f}")
# 결론 도출
alpha = 0.05 # 유의수준
if p_val < alpha:
print("귀무가설 기각: 관찰된 방문 비율은 주장하는 비율과 다르다.")
else:
print("귀무가설 채택: 관찰된 방문 비율은 주장하는 비율과 같다.")
Chi-squared Statistic: 11.442
P-value: 0.043
귀무가설 기각: 관찰된 방문 비율은 주장하는 비율과 다르다.P-value가 0.043으로 유의수준(0.05)보다 작으므로 귀무가설을 기각한다.
즉, 실제 방문 비율은 우리가 가정한 비율과 통계적으로 유의미하게 다르다.
3. 독립성 검정
두 범주형 변수의 독립성을 검정한다.
독립성 검정을 통해 흡연 여부와 성별이 서로 독립적인지를 확인해 보자.
# 관찰 데이터: 성별과 흡연 여부에 따른 빈도
data = np.array([
[40, 60], # 남성: 흡연자, 비흡연자
[30, 70] # 여성: 흡연자, 비흡연자
])
# 독립성 검정 수행
chi2_stat, p_val, dof, expected = stats.chi2_contingency(data, correction=True)
print(f"Chi-squared Statistic: {chi2_stat:.3f}")
print(f"P-value: {p_val:.3f}")
print(f"Degrees of Freedom: {dof:.3f}")
print("Expected frequencies:")
print(expected)
# 결론 도출
alpha = 0.05 # 유의수준
if p_val < alpha:
print("귀무가설 기각: 성별과 흡연 여부는 독립적이지 않다.")
else:
print("귀무가설 채택: 성별과 흡연 여부는 독립적이다.")
Chi-squared Statistic: 1.780
P-value: 0.182
Degrees of Freedom: 1.000
Expected frequencies:
[[35. 65.]
[35. 65.]]
귀무가설 채택: 성별과 흡연 여부는 독립적이다.P-value가 0.182로 유의수준보다 크므로 귀무가설을 기각하지 못한다.
즉, 성별과 흡연 여부는 유의미한 관련성이 없어 독립적이라고 판단할 수 있다.
4. 동질성 검정
동질성 검정은 여러 집단 간 분포가 동일한지를 비교하는 검정이다.
동질성 검정을 통해 세 학교에서 학생들이 선호하는 과목 분포가 동일한지를 확인해 보자.
# 관찰 데이터: 각 학교에서 학생들이 선호하는 과목의 빈도수
data = np.array([
[50, 60, 55], # 수학 선호
[40, 45, 50], # 과학 선호
[30, 35, 40] # 문학 선호
])
# 동질성 검정 수행
chi2_stat, p_val, dof, expected = stats.chi2_contingency(data)
print(f"Chi-squared Statistic: {chi2_stat:.3f}")
print(f"P-value: {p_val:.3f}")
print(f"Degrees of Freedom: {dof:.3f}")
print("Expected frequencies:")
print(expected.round(3))
# 결론 도출
alpha = 0.05 # 유의수준
if p_val < alpha:
print("귀무가설 기각: 각 학교에서 과목 선호도는 동일하지 않다.")
else:
print("귀무가설 채택: 각 학교에서 과목 선호도는 동일하다.")
Chi-squared Statistic: 0.817
P-value: 0.936
Degrees of Freedom: 4.000
Expected frequencies:
[[48.889 57.037 59.074]
[40. 46.667 48.333]
[31.111 36.296 37.593]]
귀무가설 채택: 각 학교에서 과목 선호도는 동일하다.P-value가 0.936으로 매우 크기 때문에 귀무가설을 기각하지 못합니다.
즉, 세 학교의 과목 선호도는 통계적으로 동일하다고 판단된다.
A/B 헤드라인 클릭률 검정
이번에는 A/B 테스트 상황에서 세 개의 헤드라인 클릭률이 독립적인지 확인해 보자.
아래는 A,B,C 세가지 헤드라인을 비교하며, 각각 방문자 1000명에 대한 결과이다.
import pandas as pd
from scipy import stats
url = "https://raw.githubusercontent.com/gedeck/practical-statistics-for-data-scientists/master/data/click_rates.csv"
click_rate = pd.read_csv(url)
# 피벗 테이블 형태로 변환
clicks = click_rate.pivot(index='Click', columns='Headline', values='Rate')
display(clicks)
| Click | Headline A | Headline B | Headline C |
|-----------|------------|------------|------------|
| Click | 14 | 8 | 12 |
| No-click | 986 | 992 | 988 |
기대 값 계산
# 기대 값 테이블 생성 함수
def calculate_expected_values(contingency_table):
row_totals = contingency_table.sum(axis=1)
col_totals = contingency_table.sum(axis=0)
total = contingency_table.sum().sum()
expected_values = pd.DataFrame()
for row_label in contingency_table.index:
for col_label in contingency_table.columns:
expected_value = (row_totals[row_label] * col_totals[col_label]) / total
expected_values.loc[row_label, col_label] = expected_value
return expected_values
expected_values = calculate_expected_values(clicks)
print("기대 값 테이블:")
display(expected_values)
기대 값 테이블:
| Click | Headline A | Headline B | Headline C |
|-----------|------------|------------|------------|
| Click | 11.333333 | 11.333333 | 11.333333 |
| No-click | 988.666667 | 988.666667 | 988.666667 |
잔차 계산
# 잔차 계산 함수
def calculate_residuals(observed, expected):
residuals = (observed - expected) / (expected ** 0.5)
return residuals
residuals = calculate_residuals(clicks, expected_values)
display(residuals)
| Click | Headline A | Headline B | Headline C |
|-----------|------------|------------|------------|
| Click | 0.792118 | -0.990148 | 0.198030 |
| No-click | -0.084809 | 0.106012 | -0.021202 |
카이제곱 검정 실행
# 카이제곱 독립성 검정
chisq, pvalue, df, expected = stats.chi2_contingency(clicks)
print(f"chisq:{chisq:.3f}\npvalue:{pvalue:.3f}")
alpha = 0.05
if pvalue < alpha:
print("귀무가설 기각: 헤드라인과 클릭률에는 관련이 있다.")
else:
print("귀무가설 채택: 헤드라인과 클릭률에는 관련이 없다.")
chisq:1.666
pvalue:0.435
귀무가설 채택: 헤드라인과 페이지 클릭율에는 관련이 없다.p-value가 0.435로 유의수준보다 크기 때문에 귀무가설을 기각할 수 없다.
헤드라인 종류과 클릭률 간에는 통계적으로 유의미한 관련이 없으며, 방문자의 클릭 행동은 랜딩 페이지 제목과 무관하다고 판단할 수 있다.
지금까지 카이제곱 분포의 정의부터 적합도, 독립성, 동질성 검정을 완전히 체화하기 위해 직접 구현해 보았다.
특히 카이제곱 통계량과 P-value의 계산 과정을 직접 수행하며, 그 계산이 왜 그렇게 되는지, 해석은 어떻게 해야 하는지, 어떤 상황에서 쓰이는지를 익힐 수 있었다.
가설을 객관적으로 검토하고 판단하는 능력을 기르기 위해 꾸준히 들여다보고 연습하자.
