구글 코랩(Google Colab) 환경에서 캐글 필사를 진행하기 위한 환경 설정을 정리해 보았다.
글의 마지막 부분에는
세션이 끊기거나, 다음 날 다시 Colab에서 작업할 때 효율적으로 이어서 필사할 수 있도록 세팅을 자동화한 코드 템플릿도 제작하여 남겨두었다.
작성하고 보니 서론이 긴 글이 되었지만, 혹시 구글 코랩 사용이 낯설거나 캐글 데이터를 처음 다뤄본다면 도움이 될 수 있을 것 같다.
해당 캐글 필사는 이유한님이 공유해주신 캐글 커널 커리큘럼 중 타이타닉 튜토리얼를 참고하여 Titanic - Machine Learning from Disaster의 노트북을 필사하였다.
여러 가지 방법으로 캐글 데이터를 사용할 수 있지만, 그 중에서 아래와 같은 방식을 택했다. 이 글은 해당 방식을 선택한 이유와 구체적인 프로세스를 남겨두기 위해 작성하게 되었다.
구글 코랩 환경 + Kaggle API로 데이터 다운로드 + Drive 저장
Kaggle에서 제공하는 Notebook이 아닌 구글 코랩을 선택한 이유
결론부터 이야기 하자면 구글 코랩 환경에서 작업해야 GitHub 연동 및 관리가 용이하기 때문이다 :)
Kaggle Notebook은 해당 대회의 데이터셋이 자동으로 연결되어 있기 때문에 별도 다운로드, 업로드, 경로 설정 없이 아래처럼 바로 사용 가능하다는 장점이 있다.
두 노트북을 비교하여 구글 코랩을 선택한 이유를 정리해 보았다.
| 항목 | Google Colab | Kaggle Notebook |
|---|---|---|
| 자유도 높은 환경 설정 | 필요에 따라 어떤 라이브러리든 설치 가능 | 일부 패키지 제한 있음 |
| Google Drive 연동 | 완전 자동화 가능 (/content/drive) | 지원 안 함 |
| GitHub 연동 및 관리 용이 | 직접 push/pull 가능 | 제한적, 불편함 |
| 오프라인 연동 | 로컬 PC에서 Drive 연동하여 작업 가능 | 전혀 불가능 |
| 세션 시간 더 넉넉함 | Pro 사용 시 24시간까지 | 무료 기준 세션 짧음 (~90분) |
| 인터페이스 | 완전한 Jupyter 스타일 + 한글 UI 등 | 제한적인 UI |
따라서 이와 같은 이유로 구글 코랩에서 캐글 필사를 진행하기로 결정하였다.
그 전에
아직 구글 코랩 환경이 익숙하지 않아, 세션 시간에 대해 더 알아볼 필요를 느꼈다.
세션 종료 후, 사라지는 것들 vs 유지되는 것들
| 항목 | 세션 종료 후 | 설명 |
|---|---|---|
train, test, model 변수 등 | 사라짐 | RAM 상 변수는 전부 사라짐 |
/content/에 저장된 파일 | 사라짐 | 임시 저장소라서 초기화됨 |
| Google Drive에 저장한 파일 | 유지됨 | 드라이브는 클라우드에 저장되어 안전함 |
노트북 코드(.ipynb) | 자동 저장됨 | Drive에 저장되는 Colab 파일은 그대로 유지 |
-
모든 노트북(.ipynb)은 Drive에 저장됨 → 걱정 없음
-
데이터셋도 Drive에 보관 → 재다운로드 필요 없음
-
분석 중간 산출물은 Drive에 저장 → 모델, 시각화 결과물 등
-
다음 날 이어서 작업 시 초기 셀만 다시 실행하면 OK
개발 환경 설정 과정에서 프레임워크 등을 꼼꼼하게 비교하지 않고 구축한 적이 있었는데.. 이로 이해 발생한 에러 해결에 많은 시간과 에너지를 쏟는 것이 비효율적임을 느꼈기 때문에 이렇게까지 정리해 보았다..
따라서 아래의 프로세스로 분석 환경을 설정하기로 했다.
- Kaggle API로 Drive에 kaggle.json 저장
- Drive에 데이터 저장
- Colab 템플릿으로 반복 사용
Drive에 kaggle.json 저장함으로써, 매번 파일을 새로 받을 필요가 없게 된다.
또, 코드를 템플릿화 하여 Colab에서 바로 이어서 필사가 가능하고, GitHub에도 쉽게 올릴 수 있는 캐글 필사 환경을 만들 수가 있다.
Kaggle API 외에도 구글 코랩에서 캐글 데이터를 사용할 수 있는 방법에는 여러 가지가 있지만, 재현성과 확장성, 효율성 면에서 최적의 방법이라고 생각되었기 때문에 해당 방법을 택했다.
🖇 구글 코랩에서 캐글 데이터 불러오기
아래와 같은 순서로 캐글 데이터를 사용할 수 있는 환경을 구축하였다.
1) 구글 코랩에서 폴더-파일 생성
폴더 구조는 아래와 같이 구성하였다.
/drive/MyDrive/kaggle_replica/
└── titanic/
├── titanic_analysis.ipynb
├── train.csv
└── test.csv✓ 대회/프로젝트별로 정리하면 나중에 관리가 쉽다.
다른 대회도 kaggle_replica/house_prices/ 이런 식으로 깔끔하게 분리 가능
✓ Google Drive 내에 정리된 상태로 저장되므로 재사용, 공유, 업로드할 때 폴더 단위로 관리가 가능함
✓ titanic_analysis.ipynb와 train.csv 등 관련 파일이 같은 경로에 있어야 코드가 경로 문제 없이 실행됨
2) 캐글에서 API 토큰 발급받기
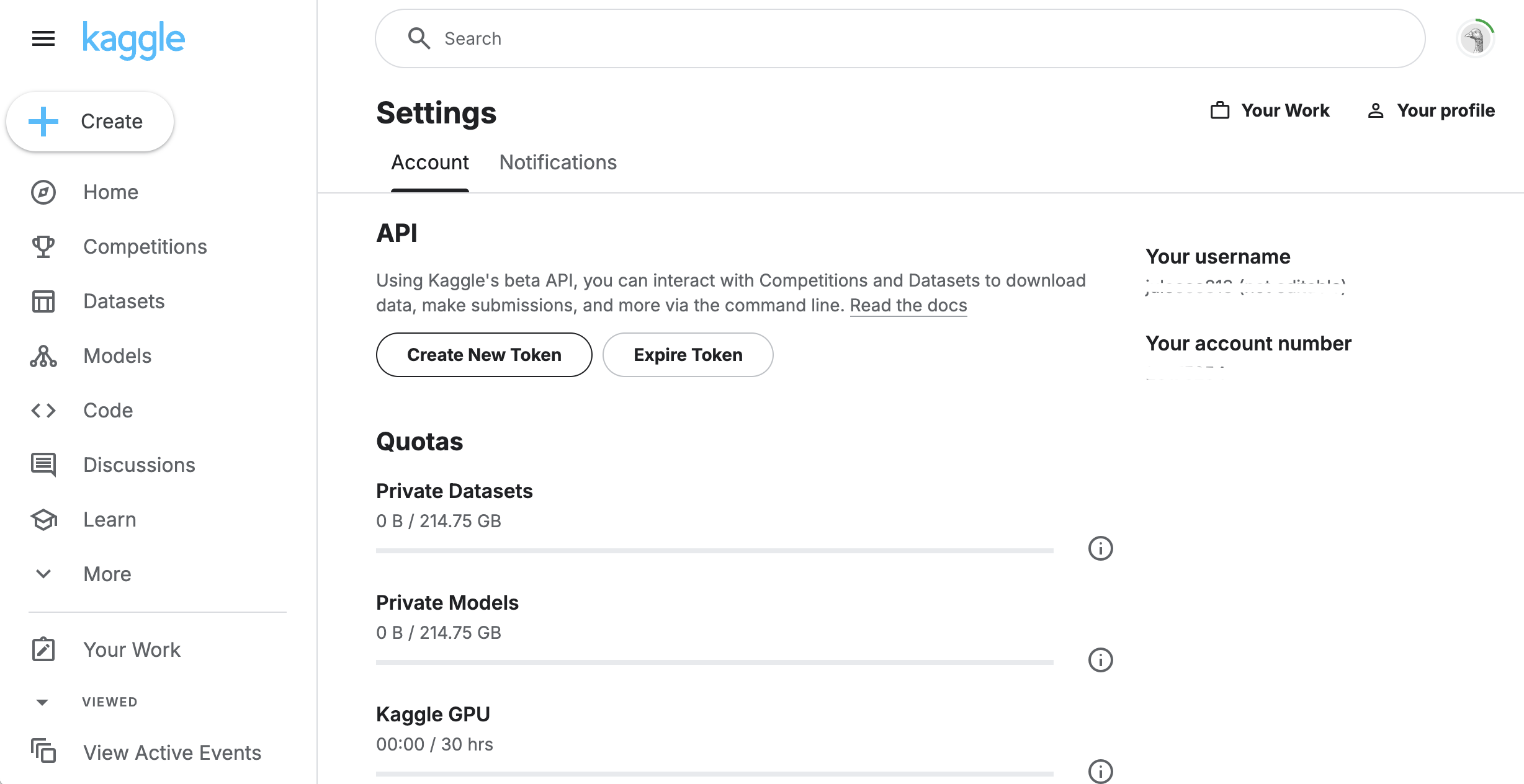
Kaggle API 토큰을 발급받는 방법을 찾고 싶어서 구글링해 보았는데, UI가 바뀌었는지 Create New Token 버튼이 해당 위치에 없어서 이미지로 첨부해 보았다.
- 오른쪽 상단 프로필 이미지 > Settings 에서 아래로 스크롤해 보면
- API - Create New Token을 찾을 수 있다.
- 토큰을 발급받으면 kaggle.json을 다운로드하게 된다.
[주의] GitHub 연동 시, kaggle.json 같은 개인 키/토큰 파일은 .gitignore 처리하거나 업로드하지 않도록 주의해야 한다.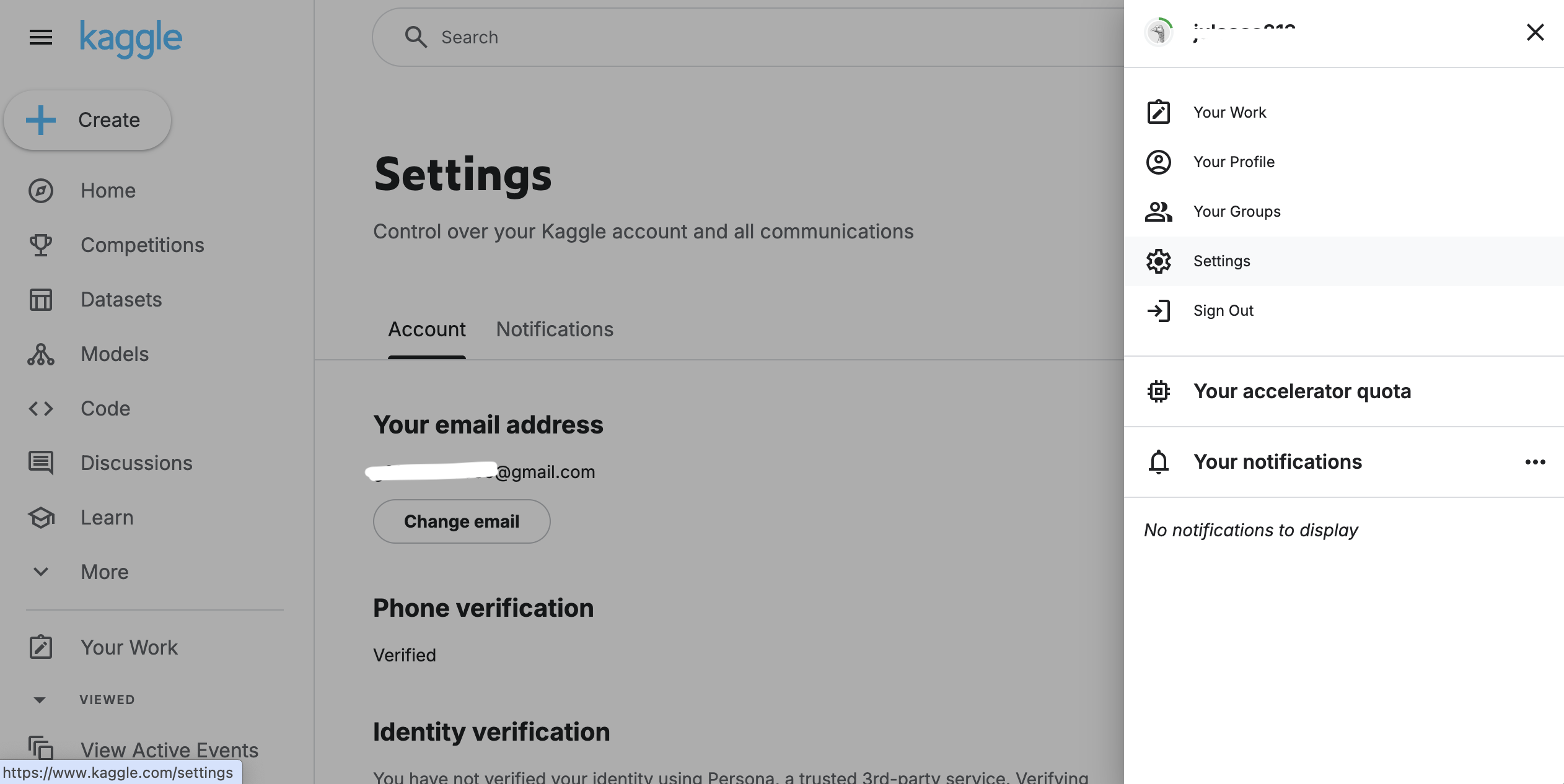
 참고로 kaggle.json은 여러 번 발급할 수 있으며, 새로 발급하면 이전 키는 자동으로 무효화된다.
참고로 kaggle.json은 여러 번 발급할 수 있으며, 새로 발급하면 이전 키는 자동으로 무효화된다.
3) Google Drive 마운트
Colab 세션이 초기화될 때마다 다시 마운트해야 한다.
from google.colab import drive
drive.mount('/content/drive')
실행하면 Google 계정 인증 요청이 뜨고,
승인하면 /content/drive/MyDrive/ 아래에 내 드라이브가 연결된다.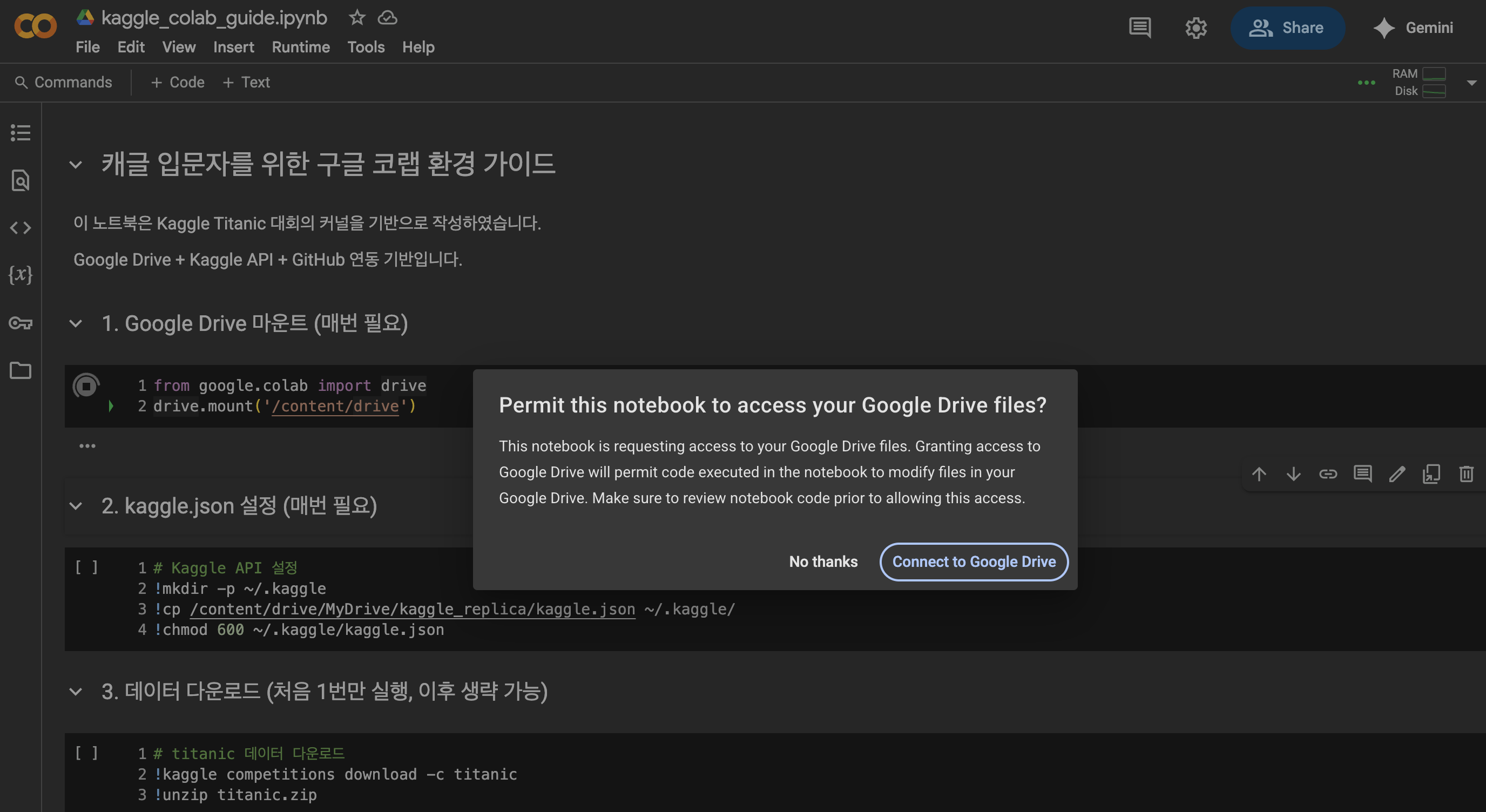
4) kaggle.json 설정
이제부터는 매번 Colab에 kaggle.json을 업로드하지 않아도 되도록,
Google Drive에 kaggle.json을 저장해두고 Colab에서 자동으로 불러오도록 설정해 보자.
매번 /content 내부가 초기화되기 때문에 kaggle.json 복사가 필요하다.
Tip) titanic 폴더 바깥에 두는 것이 여러 대회에서 재사용하기 좋다 :)
# chmod 600은 보안 설정이다. Kaggle API가 요구하는 권한이다.
!mkdir -p ~/.kaggle
!cp /content/drive/MyDrive/kaggle_replica/kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.json
5) 데이터 다운로드
# titanic 데이터 다운로드
!kaggle competitions download -c titanic
!unzip titanic.zip
!mv train.csv /content/drive/MyDrive/kaggle_replica/titanic/
!mv test.csv /content/drive/MyDrive/kaggle_replica/titanic/
!mv gender_submission.csv /content/drive/MyDrive/kaggle_replica/titanic/
이제 kaggle.json을 업로드하지 않아도 된다.
Colab 초기 셀에 위 코드를 넣어두면 매번 자동으로 사용할 수 있다 😊
캐글 필사를 효율적으로 진행하기 위해, 지금까지의 프로세스를 정리하여 아래에 템플릿화 해보았다.
🖇 [템플릿] Google Colab에서 캐글 데이터 사용
[1] Google Drive 마운트 (매번 필요)
from google.colab import drive
drive.mount('/content/drive')
[2] kaggle.json 설정 (매번 필요)
!mkdir -p ~/.kaggle
!cp /content/drive/MyDrive/kaggle_replica/kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.json
[3] 데이터 다운로드 (처음 1번만 실행, 이후 생략 가능)
# 처음 실행할 때만 사용 (이미 다운로드되었다면 생략)
!kaggle competitions download -c titanic
!unzip titanic.zip
!mv train.csv /content/drive/MyDrive/kaggle_replica/titanic/
!mv test.csv /content/drive/MyDrive/kaggle_replica/titanic/
!mv gender_submission.csv /content/drive/MyDrive/kaggle_replica/titanic/
[4] 데이터 로드 (매번 필요)
# 필요한 라이브러리도 함께 불러오기
import pandas as pd
train_path = '/content/drive/MyDrive/kaggle_replica/titanic/train.csv'
test_path = '/content/drive/MyDrive/kaggle_replica/titanic/test.csv'
train_df = pd.read_csv(train_path)
test_df = pd.read_csv(test_path)
train.head()
이후부터는 그 아래 셀부터 이전에 하던 분석을 이어서 진행하면 된다.
또한, 다른 Kaggle 대회 필사에서도 Drive에 있는 kaggle.json을 그대로 활용하면 된다.
초기 셀에 항상 위 코드를 넣어두면 자동 세팅 템플릿이 완성된다 :)
본격적으로 필사를 진행하기에 앞서 다음을 염두에 두고 시작하자.
💡 분석은 자유롭게 진행하되,
각 셀에 주석을 꼼꼼히 달며 왜 이 작업을 하는지 설명하는 것이 "필사"의 핵심이다.
