🖇 자연어 처리
🖇 자연어 처리 시 주의사항
🖇 자연어 처리 기초
🖇 감성 분석
🖇 자연어 전처리
자연어 처리(NLP, Natural Language Processing)는 컴퓨터가 인간의 언어를 이해하고 활용할 수 있도록 만드는 기술이다.
텍스트나 음성과 같은 비정형 데이터를 수치화하고 구조화하여 기계가 해석하고 판단할 수 있는 형태로 전환한다. NLP은 챗봇, 음성 인식, 자동 번역, 감정 분석 등 실생활 서비스 전반에서 사용되고 있기 때문에 기초적인 원리를 이해하는 것이 필요하다.
이 글에서는 자연어 처리의 개념과 흐름을 이해하는 데 중점을 두었다.
형태소 분석, 단어 벡터화 기법인 CountVectorizer와 TfidfVectorizer, 감성 분석을 위한 머신러닝 모델 적용, 그리고 텍스트 전처리 기법을 다루고 있다. 모델 성능 향상을 위해 한국어 자연어 처리에서 실제로 고려해야 할 전처리 방식도 정리해 보았다.
자세한 실습 과정 및 출력 결과는 GitHub repository에서 확인할 수 있다.
🖇 자연어 처리
자연어 처리(NLP, Natural Language Processing)는 인간이 사용하는 언어(자연어)를 컴퓨터가 이해하고 처리할 수 있도록 하는 기술이다.
텍스트나 음성과 같은 자연어 데이터를 구조화하고 분석 가능하도록 만들며, 이를 통해 사람과 기계 간의 상호작용을 가능하게 하는 분야이다.
자연어 처리는 언어학(Linguistics)과 컴퓨터 과학, 머신러닝이 결합된 분야로 문장 구조 분석부터 의미 해석, 문맥 이해, 감정 인식 등 폭넓은 작업을 포함한다. 최근에는 챗봇, 음성 비서, 자동 번역기, 추천 시스템 등 실생활에서 NLP 기술이 매우 광범위하게 활용되고 있다.
자연어 처리가 필요한 이유
-
비정형 데이터 활용:
대다수의 데이터는 구조화되어 있지 않다. 웹 문서, 댓글, 리뷰, 이메일, 뉴스 기사 등은 모두 텍스트 형태의 비정형 데이터이다. 이를 분석 가능한 형태로 가공하기 위해서는 자연어 처리가 필수이다. -
의미 이해와 자동화:
사용자의 질문에 자동으로 응답하거나 문서 분류, 의도 분석 등을 수행하려면 텍스트의 의미를 이해하는 능력이 필요하다. 규칙 기반으로 처리하기 어렵기 때문에 통계적 방법이나 머신러닝 기반 NLP 기술이 활용된다. -
기계 학습과 언어의 연결:
텍스트를 숫자로 변환하는 과정이 있어야 기계가 학습하고 예측할 수 있다. NLP는 텍스트를 벡터로 표현하는 다양한 기법들을 포함한다.
🖇 자연어 처리 시 주의사항
자연어 처리는 언어의 의미와 맥락을 고려해야 하는 정교한 작업이다.
본격적으로 자연어 처리 과정을 살펴보기 전에 주의사항을 먼저 짚어보았다.
-
언어 특성 고려
: 한국어처럼 조사, 어미 변화가 많은 언어는 형태소 분석기의 정확도가 분석 성능에 큰 영향을 미친다. -
과도한 벡터 차원
: 불필요한 단어까지 포함되면 학습 데이터가 희소해지고 오히려 모델 성능이 떨어질 수 있다. -
불용어 처리의 적절성
: 모든 불용어가 항상 제거 대상은 아니다. 문맥상 중요한 역할을 하는 경우도 존재하므로 사전 정의가 중요하다. -
전처리 기준의 일관성
: 띄어쓰기, 맞춤법, 이모티콘 처리 등은 분석 목적에 따라 조정해야 하며, 학습-예측 시 일관되게 적용되어야 한다. -
모델 해석 가능성 유지
: 단순한 벡터화 모델에서도 결과 해석 가능성을 염두에 두고 전처리와 특성 구성을 진행하는 것이 좋다.
이러한 주의사항을 고려한 전처리와 벡터화 작업이 있어야 모델의 신뢰성과 해석 가능성을 높일 수 있을 것이다.
이 내용을 되새기면서 자연어 처리 과정의 기초부터 살펴보자.
🖇 자연어 처리 기초
자연어 처리를 위해 먼저, 언어를 분해하고 구조화하는 작업이 필요하다.
이때 형태소 분석기를 사용한다.
형태소 분석기(Okt)
형태소는 의미를 가지는 최소 단위이다. 한국어와 같이 어미 변화가 풍부한 언어에서는 형태소 분석이 특히 중요하다.
Python에서는 KoNLPy 라이브러리에서 제공하는 Okt 형태소 분석기를 주로 활용한다.
morphs(): 입력 문장을 형태소 단위로 분해한다.nouns(): 명사만 추출한다.pos(): 형태소와 품사 정보를 함께 반환한다.
형태소 분석기를 통해 문장을 단어 단위로 나누고, 불필요한 정보를 제거하거나 분석 대상 단어만 선별할 수 있다.
# 라이브러리 불러오기
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
# konlpy 설치
!pip install konlpy
# 라이브러리 불러오기 (okt)
import konlpy
from konlpy.tag import Okt
tokenizer = Okt()
# 토큰화 (형태소 단위)
text = "..."
tokenizer.morphs(text)
# 토큰화 (명사만 추출)
tokenizer.nouns(text)
# 토큰화 (품사 태깅)
tokenizer.pos(text)CountVectorizer
CountVectorizer는 텍스트 데이터를 단어의 출현 빈도 기반으로 수치화하는 벡터화 기법이다. BOW(Bag of Words) 방식이라고도 한다.
텍스트를 단어들의 순서 정보 없이 각 단어가 얼마나 등장했는지만 고려한다. CountVectorizer는 아래의 흐름으로 작동한다.
-
전체 문장에서 등장하는 단어 목록(어휘 사전)을 만든다.
-
각 문장을 해당 단어 목록 기준으로 인코딩한다.
-
각 문장은 단어별 등장 횟수로 구성된 벡터가 된다.
이 방식은 간단하지만 직관적이며 머신러닝 모델에 입력으로 활용할 수 있는 기본적인 수치형 벡터를 생성한다. 다만, 자주 등장하는 일반적인 단어가 중요하게 반영될 수 있어 가중치 조정이 필요할 수 있다.
# CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer
vect = CountVectorizer()
# 단어 토큰화 (Okt)
words = tokenizer.morphs(text)
# 데이터 학습
vect.fit(words)
# 학습된 어휘
vect.get_feature_names_out()
# 단어 사전
vect.vocabulary_
# 단어 사전 크기
len(vect.vocabulary_)
# 인코딩
df_t = vect.transform(words)
# 인코딩된 데이터 Matrix
df_t.toarray()
# 어휘와 피처 (데이터 프레임)
pd.DataFrame(df_t.toarray(), columns=vect.get_feature_names_out())
# test
test = "..."
# 단어 토큰화 (Okt)
words = tokenizer.morphs(test)
words
# 인코딩된 데이터 Matrix
test_t = vect.transform(words)
test_t.toarray()
# 어휘와 피처 (데이터 프레임)
pd.DataFrame(test_t.toarray(), columns=vect.get_feature_names_out())TfidfVectorizer
TfidfVectorizer는 TF-IDF (Term Frequency - Inverse Document Frequency) 방식을 기반으로 한 벡터화 기법이다.
단순 출현 빈도보다 특정 문서에서 중요하게 등장하는 단어에 더 높은 가중치를 부여한다.
-
TF (Term Frequency)
: 특정 단어가 문서 내에서 얼마나 자주 등장했는지를 나타낸다. -
IDF (Inverse Document Frequency)
: 전체 문서에서 해당 단어가 얼마나 희귀한지를 나타낸다.
Tfidf는 특정 문서에서 자주 등장하지만 다른 문서에는 잘 나타나지 않는 단어에 높은 가중치를 주어, 단어의 분류적 중요도를 반영할 수 있게 한다.
CountVectorizer보다 분류 성능이 개선되는 경우가 많고 대부분의 텍스트 분류 및 감성 분석에 자주 사용된다.
# tf-idf
from sklearn.feature_extraction.text import TfidfVectorizer
# tf-idf 활용 어휘 사전 구축
vect = TfidfVectorizer()
words = tokenizer.morphs(text)
vect.fit(words)
vect.vocabulary_
# 인코딩된 데이터 Matrix
vect.transform(words).toarray()🖇 감성 분석
감성 분석(Sentiment Analysis)은 문장이나 문서가 긍정적인지 부정적인지 등 정서적 태도를 자동으로 분류하는 작업이다.
이 글에서는 네이버 영화 리뷰 데이터를 활용하여 문장의 감성 레이블(0: 부정, 1: 긍정)을 예측하는 분류 모델을 간단하게 학습해 보았다.
분석 흐름
-
데이터 로딩
: 감성 라벨이 포함된 텍스트 데이터를 불러온다. -
결측치 제거 및 전처리
: 비어 있는 문장 제거, 길이 확인 등 기본적인 정리 작업을 수행한다. -
형태소 분석 및 벡터화
: 문장을 형태소 단위로 분해한 후CountVectorizer를 사용해 수치화한다. -
모델 학습 및 평가
: 분류 모델(RandomForest)을 학습하고, 교차 검증을 통해 f1-score 또는 accuracy를 계산한다.
이러한 방식으로 단순한 문장 패턴만으로도 분류 성능을 일정 수준 이상 확보할 수 있으며, 전처리 전략에 따라 성능이 달라질 수 있다.
데이터 출처: NSMC – Naver Sentiment Movie Corpus (e9t)
# 라이브러리 불러오기
import pandas as pd
# 데이터 불러오기
df = pd.read_csv('https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt', sep='\t')EDA 및 데이터 전처리
# 데이터 샘플
df.head()
# 데이터 크기
df.shape
# 타겟 확인
df['label'].value_counts()
# 결측치
df.isnull().sum()
# 결측치 제거
print(df.shape)
df = df.dropna()
print(df.shape)
# 피처 엔지니어링 (문장의 길이)
df['len'] = df['document'].apply(len)
df.head()# len 시각화 (label == 0)
import matplotlib.pyplot as plt
df[df.label==0]['len'].plot(kind='hist')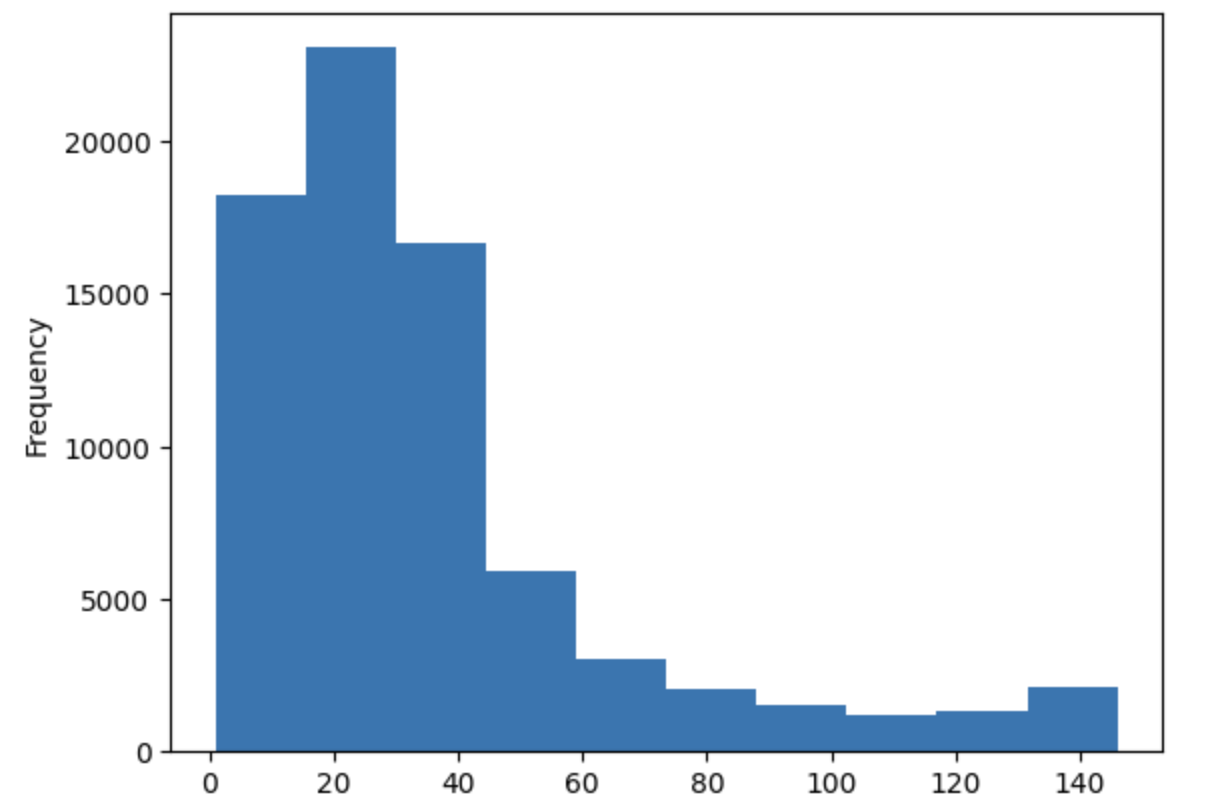
# len 시각화 (label == 1)
df[df.label==1]['len'].plot(kind='hist')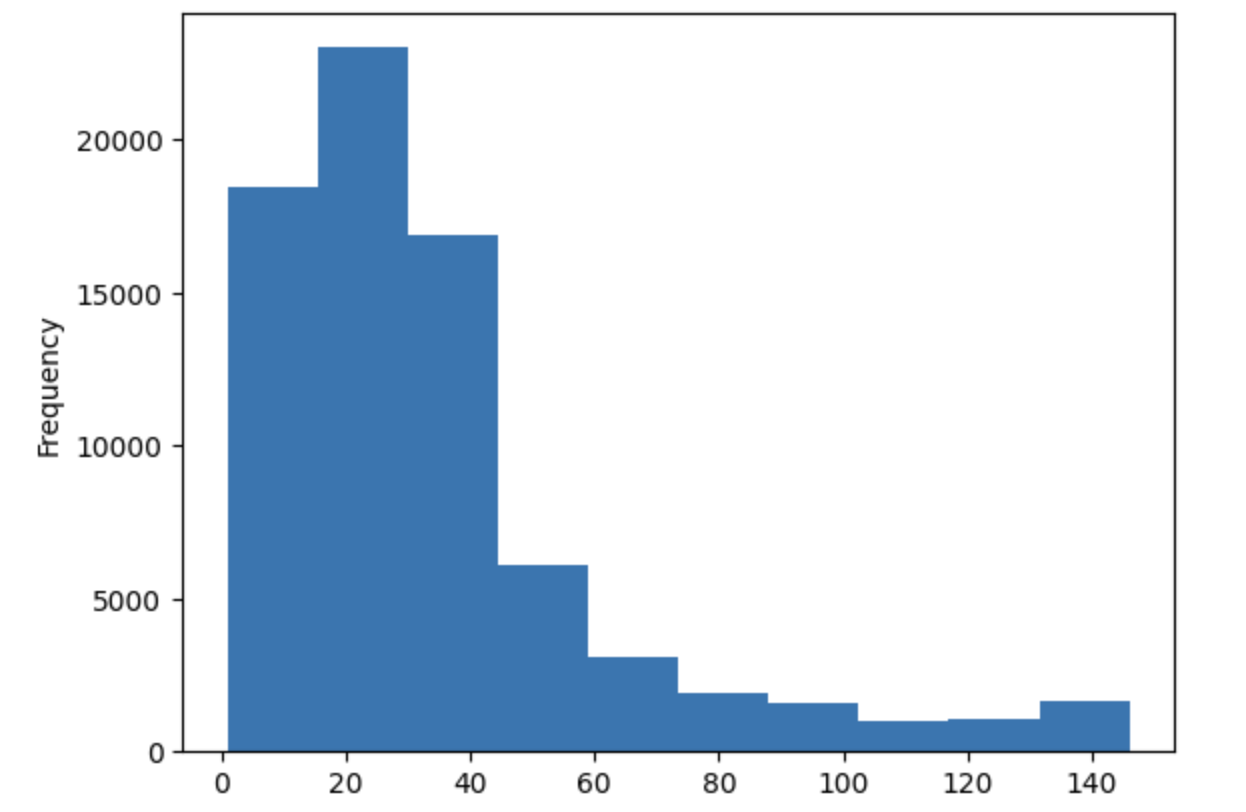
# 데이터 샘플링 df[:1000]
df = df[:1000]
df.shape
# 토큰화 + 인코딩
import konlpy
from konlpy.tag import Okt
from sklearn.feature_extraction.text import CountVectorizer
tokenizer = Okt()
vect = CountVectorizer(tokenizer=tokenizer.morphs)
vectors = vect.fit_transform(df['document'])머신러닝
# 머신러닝 -> 교차검증(f1)
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
model = RandomForestClassifier(random_state=2022)
cross_val_score(model, vectors, df['label'], scoring='f1', cv=5).mean()🖇 자연어 전처리
한국어 자연어 처리에서 전처리는 결과에 매우 큰 영향을 미친다.
아래의 5가지 관점에서 한국어 자연어 전처리 방법을 알아보자.
- 어휘 사전 구축
- 불용어(stopword)
- 띄어쓰기
- 반복되는 글자 정리
- 맞춤법 검사
1) 어휘 사전 구축
너무 자주 등장하는 단어 너무 적게 등장하는 단어를 필터링하여 불필요한 노이즈를 제거한다.
max_df
- 너무 자주 등장하는 단어를 제거한다.
- 지정된 비율 또는 정수 이상으로 등장한 단어를 무시한다.
→ 너무 흔해서 의미 없는 단어: "the", "is", "and" 등 일반적인 단어를 제거할 때 사용됨
min_df
- 너무 드물게 등장하는 단어를 제거한다.
- 지정된 비율 또는 정수 미만으로 등장한 단어는 무시한다.
→ 오타, 고유명사, 의미 없는 희귀 단어를 제거할 때 사용됨
어휘 사전 구축 시 적절한 단어 수 조절을 통해 모델 성능을 안정적으로 유지할 수 있다.
# 토큰화(max_df) 0% 이상 나타나는 단어 무시 - N개 보다 큰 단어 수 무시
vect = CountVectorizer(tokenizer=tokenizer.morphs, max_df=10)
vectors = vect.fit_transform(df['document'])
model = RandomForestClassifier(random_state=2022)
cross_val_score(model, vectors, df['label'], scoring='accuracy', cv=5).mean()np.float64(0.643)# 토큰화(min_df) 최소 0개의 문장에만 나타나는 단어만 유지 - N개 보다 작은 단어 수 무시
vect = CountVectorizer(tokenizer=tokenizer.morphs, min_df=2)
vectors = vect.fit_transform(df['document'])
model = RandomForestClassifier(random_state=2022)
cross_val_score(model, vectors, df['label'], scoring='accuracy', cv=5).mean()np.float64(0.689)2) 불용어(stopword)
의미 없는 조사, 접속사, 감탄사 등을 제거하여 중요한 단어 위주로 모델이 학습되도록 한다.
- e.g., "은", "는", "이", "가", "그", "저기" 등
# stop_words
text = "함께 탐험하며 성장하는 AI 학교 AIFFEL"
stop_words = ['하며', 'ai']
vect = CountVectorizer(stop_words=stop_words)
words = tokenizer.morphs(text) # Okt
vect.fit(words)
vect.vocabulary_띄어쓰기
웹이나 SNS 데이터는 띄어쓰기가 잘못되어 있는 경우가 많다.
PyKoSpacing 등의 라이브러리를 활용해 올바르게 보정할 수 있다.
[참고] https://github.com/haven-jeon/PyKoSpacing
# Spacing 설치
!pip install git+https://github.com/haven-jeon/PyKoSpacing.git
# 띄어쓰기
from pykospacing import Spacing
spacing = Spacing()
text = "함께탐험하며성장하는AI학교AIFFEL"
spacing(text)반복되는 글자 정리
"ㅋㅋㅋㅋ", "ㅠㅠㅠㅠ"처럼 의미 없는 반복 문자 패턴을 정규화한다.
soynlp 라이브러리를 사용해 반복 횟수를 제한할 수 있다.
[참고] https://github.com/lovit/soynlp
# soynlp 설치
!pip install soynlp
# 댓글 데이터에 등장하는 반복되는 이모티콘 정리
from soynlp.normalizer import *
emoticon_normalize('하하하하하ㅋㅋㅋㅋㅋㅋㅋ호호호호호ㅠㅠㅠㅠㅠㅠ', num_repeats=3)맞춤법 검사기
오타나 비문을 사전에 수정함으로써, 형태소 분석의 정확도를 높일 수 있다.
hanspell 등의 외부 API를 통해 교정이 가능하다. (최근에는 정책 제한이 있음)
[참고] https://github.com/ssut/py-hanspell
# py-hanspell 설치
!pip install git+https://github.com/ssut/py-hanspell.git
# 맞춤법 검사
from hanspell import spell_checker
text = '알파고 이전, 2015년부터 만들 어진 최초의AI 커뮤니티 모두의연구소.학연, 지연, 모두연이라는 말이나올만큼 AI의 보금자리로서 중요한 역할을 하고있는 모두의연구소에서 만들었습니다. AI기술을 커뮤니티로 배우는 유일 한 기관 아이펠과 함께 밝은 미래를 만들어보세요.'
result = spell_checker.check(text)
result = spell_checker.check(text)
result.as_dict()
# 수정된 문장
result.checked인사이트 및 회고
지금까지 자연어 처리의 개념과 전반적인 처리 흐름을 중심으로 텍스트 분석의 주요 절차를 정리해 보았다.
자연어 처리에서 중요한 것은 언어라는 비정형 데이터를 수치화하고 구조화한다는 것이다. 단어의 빈도나 문맥을 고려하는 방식에 따라 해석과 성능에 큰 영향을 줄 수 있다는 점을 알 수 있었다.
자연어 처리의 전체적인 흐름과 고려해야 할 요소들이 어떻게 연결되는지를 파악하는 데 도움이 되었다.
앞으로 더 복잡한 딥러닝 기반 NLP 모델로 확장하기 전, 이와 같은 기초 흐름을 정확히 이해하는 것이 매우 중요하다고 생각된다.
