
📌 사용 환경
Python 3.10.2
conda 24.9.0
JupyterLab 4.2.5
지난 CDA 심화 (1) 글에 이은 두 번째 글이다.
중간중간 흐름의 연결이 부드럽지 않으면 CDA 심화 (1) 글을 참고하자.
필요한 라이브러리를 먼저 import 해주고 시작하자.
import numpy as np
import pandas as pd
# 시각화
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rc("font", family="Malgun Gothic")
plt.rcParams["axes.unicode_minus"]=False
# 검증
import scipy.stats as stats1. 분석
이번에는 새로운 주제로 4가지의 주제를 진행한다.
- 직업별 월급 차이 - 어떤 직업이 월급을 가장 많이 받을지
- 성별 직업 빈도(연관분석) - 성별로 어떤 직업을 가장 많이 종사하는지
- 종교 유무에 따른 이혼율(연관분석) - 종교가 있으면 이혼을 덜 할지
- 지역별 연령대 비율(연관분석) - 어느 지역에 노년층이 많을지
📌 이제 각 주제에 대해 다음과 같은 절차를 거쳐서 진행한다.
1단계) DDA, 변수 검토 및 전처리
- 분석에 활용할 변수 전처리
- 변수의 특징 파악, 이상치와 결측치 정제 (i.g., 월급없는사람 날리기)
- 변수의 값을 다루기 편하게 바꾸기 (i.g., 성별 float형 -> 문자형)
2단계) EDA, 변수 간 관계 분석
- 변수 간 관계 분석
- 데이터 요약 표(groupby, pivot_table), 그래프 만들기
3단계) CDA, 통계적 가설 검정
- 가설 설정
- 가설 검증 절차
2.1. 직업별 월급 차이
⭐ 어떤 직업이 월급을 가장 많이 받을지
DDA: 분석에 활용할 변수(직업, 월급) 전처리
EDA: 변수 간 관게 분석
- 데이터 요약표: 직업별 월급평균표 만들기
- 그래프 만들기: x(직업(범주(문자))), y(월급(연속(숫자))) -> barplot
CDA: 검증
- x(직업(범주(문자))), y(월급(연속(숫자))): y, 월급은 비정규 -> 3집단 이상 Kruskal Wallis Test
2.1.1. 직업 변수 검토 및 전처리
직업코드 변수와 코드북의 직업분류코드 병합
이어서 직업별 월급 차이를 알아보자.
앞서 person.csv라는 파일로 컬럼명을 바꿔주고 저장했었는데, 그 파일을 가지고 진행한다.
person=pd.read_csv("./data/pandas/project/person.csv")
subject_five=person.copy()
subject_five.shape(14418, 7)subject_five.head()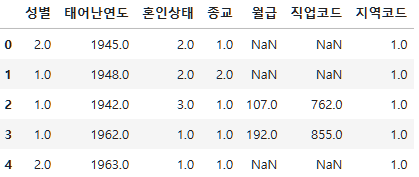
subject_five.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 14418 entries, 0 to 14417
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 성별 14418 non-null float64
1 태어난연도 14418 non-null float64
2 혼인상태 14418 non-null float64
3 종교 14418 non-null float64
4 월급 4534 non-null float64
5 직업코드 6878 non-null float64
6 지역코드 14418 non-null float64
dtypes: float64(7)
memory usage: 788.6 KB이를 보면 직업의 내용이 없다.
대신 직업코드만 있다.
subject_five["직업코드"].value_counts()직업코드
611.0 962
941.0 391
521.0 354
312.0 275
873.0 236
...
112.0 2
784.0 2
423.0 1
861.0 1
872.0 1
Name: count, Length: 150, dtype: int64따라서 코드북에 들어가서 시트 2번째에 있는 직종코드 부분의 내용을 가져오자.

2.1.1.1. 코드북의 직업분류코드
job=pd.read_excel("./data/pandas/project/Koweps_Codebook_2019.xlsx", sheet_name="직종코드")
job.shape(156, 2)job.head()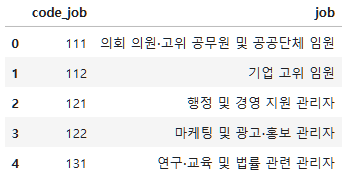
이렇게 코드를 기반으로 직업명이 적혀있다.
job.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 156 entries, 0 to 155
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 code_job 156 non-null int64
1 job 156 non-null object
dtypes: int64(1), object(1)
memory usage: 2.6+ KB이 컬럼명을 subject_five의 직업코드와 맞추기 위해 변경해주자.
job_list=job.rename(columns={"code_job" : "직업코드", "job" : "직무내용"})
job_list.head()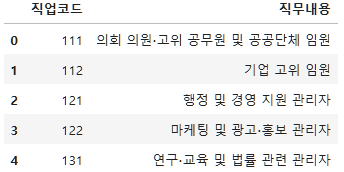
그리고 변경까지한 내용을 우선 저장해두자.
job_list.to_excel("./data/pandas/project/joblist.xlsx", index=False)2.1.1.2. 한국복지패널과 직업분류 코드 병합
어떤 직업이 월급을 가장 많이 받을까를 알아내기 위함이니까,
직업코드를 기준으로 subject_five 데이터프레임과 job_list 데이터프레임을 inner 조인한다.
subject_five
job_list
이제 merge를 진행하자.
subject_five_merge=subject_five.merge(job_list, on="직업코드", how="inner")
subject_five_merge.head()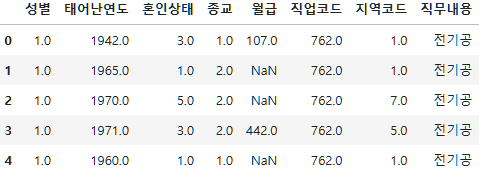
저번 subject_four까지는 다 제거되었지만 이번에는 person을 가져왔기 때문에 결측치들이 있다.
이제 결측치를 제거해주자.
subject_five_merge.dropna(inplace=True)
subject_five_merge.info()<class 'pandas.core.frame.DataFrame'>
Index: 4534 entries, 0 to 6877
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 성별 4534 non-null float64
1 태어난연도 4534 non-null float64
2 혼인상태 4534 non-null float64
3 종교 4534 non-null float64
4 월급 4534 non-null float64
5 직업코드 4534 non-null float64
6 지역코드 4534 non-null float64
7 직무내용 4534 non-null object
dtypes: float64(7), object(1)
memory usage: 318.8+ KBsubject_five_merge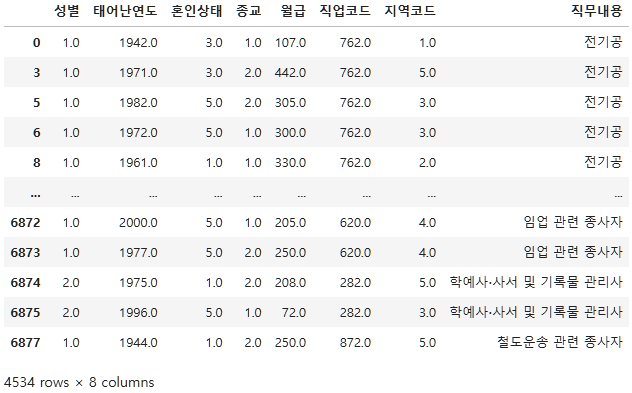
2.1.2. 직업과 월급 분석
직업별 월급 차이: 어떤 직업이 월급을 가장 많이 받을까?
시각화, 데이터 요약(직업별 월급 평균표)
이제 어떤 직업이 월급을 가장 많이 받을지 시각화를 해보고, 데이터를 요약하는 표인, 직업별 월급 평균표를 만들어보자.
sns.barplot(data=subject_five_merge, x="직무내용", y="월급")
아래 직무내용이 보이지 않는 이유는 직업이 너무 많기 때문이다.
우선 직업별 월급 평균표를 만들자.
subject_five_salary_mean=subject_five_merge.groupby('직무내용')['월급'].mean().reset_index(name='직업별평균월급')
subject_five_salary_mean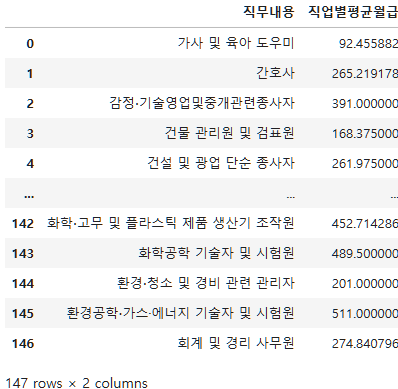
그렇다면 상위 10개의 직무와 하위 10개의 직무도 한번 보자.
top10=subject_five_salary_mean.sort_values("직업별평균월급", ascending=False).head(10)
top10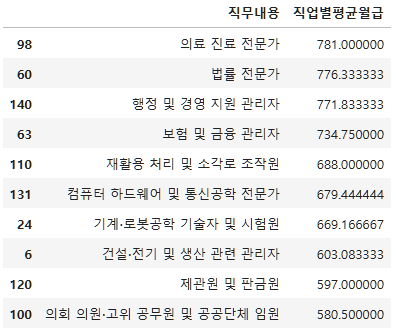
sns.barplot(data=top10, x="직업별평균월급", y="직무내용")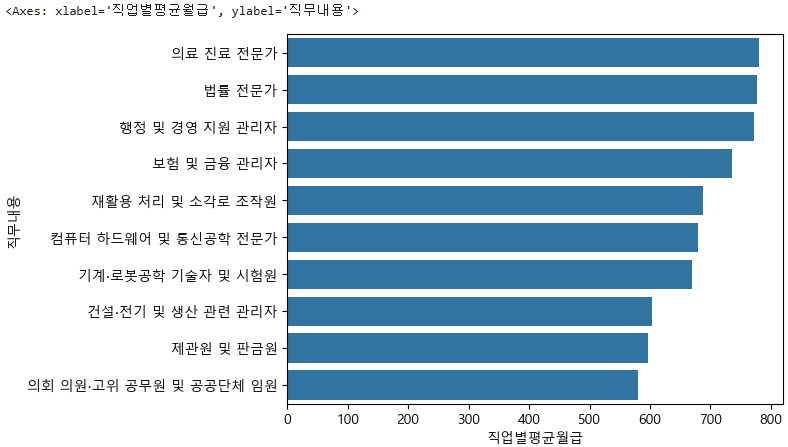
이번에는 하위 10개를 보자.
bottom10=subject_five_salary_mean.sort_values("직업별평균월급").head(10)
bottom10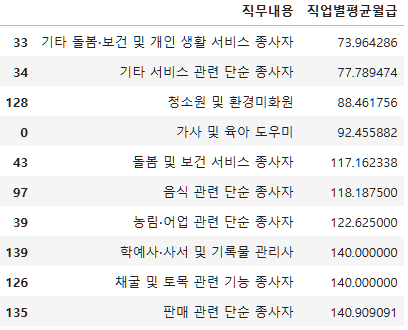
이때 subject_five_salary_mean.sort_values("직업별평균월급", ascending=False).tail(10) 도 가능하다.
sns.barplot(data=bottom10, x="직업별평균월급", y="직무내용")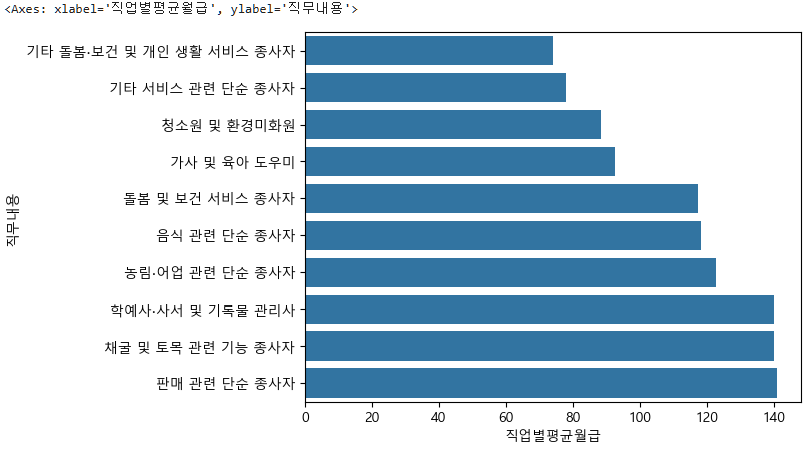
2.1.3. 통계적 가설 검정
직업별 월급의 차이가 있을지
다변수, x(직업(범주(문자))), y(월급(연속(숫자))): y, 월급은 비정규 -> 3집단 이상 Kruskal Wallis Test
가설:
- 귀무가설: 직업별 월급의 차이가 없다.
- 대립가설: 직업별 월급의 차이가 있다.
사람들의 직업은 겹치는 부분이 많기 때문에,
직무내용을 unique하게 뽑아와야한다.
job_group=[]
for job in subject_five_merge["직무내용"].unique():
# 4000개가 넘는 것들 중 unique한 것들만, 그러면 각 직종별 월급들을 다 가져온다.
# 원래는 다중 for문을 써야하는데, 필터링 기능을 써서 for문을 돌리지 않은거다.
job_salary=subject_five_merge[subject_five_merge["직무내용"] == job]["월급"]
#print(job, job_salary)
job_group.append(job_salary)
len(job_group)147이렇게 잘 뽑아왔으니 이제 검정을 진행하자.
그런데 이번에는 2집단, 3집단 이상을 다뤘었는데, 지금은 147개의 직업이다.
따라서, 아래와 같이 해줘야 한다.
stats.kruskal(*job_group)KruskalResult(statistic=2504.6045732554767, pvalue=0.0)이렇게 *job_group로 하면 된다.
이는 포인터라고 생각하면 된다.
그래서 이를 사용하면 리스트나 튜플 같이 반복 가능한 iterable 객체를 개별 인자로 전달하게 된다 즉 unpacking된다.
즉 앞서 kruskal(노년층["월급"], 중년층["월급"], 초년층["월급"])과 같이 넣었는데,
이게 147개니까 하나하나씩 넣어주지 않고, 포인터로 접근하여 unpacking 시키면 된다.
어찌됐든, pvalue 0.0 < 0.05 이므로 대립가설이 참이고, 직업별 월급의 차이가 있다.
이렇게하여 분석결과는 Kruskal Wallis Test를 통해 직업별 월급차이가 있다(통계량: 2504.6, pvalue < 0.05)가 나온다.
분석결과를 한장으로 요약하려면, 시각화한 사진, 직업별 월급평균비교표 사진, Kruskal Wallis 검정 결과 사진을 통해 직업별 월급의 차이가 있다는 것을 보여주면 된다.
2.2. 성별 직업 빈도수
⭐ 성별로 어떤 직업에 가장 많이 종사하는지
DDA: 분석에 활용할 변수(성별, 직업코드(->직무내용) 전처리
- 성별, 직업코드(->직무내용) 전처리
EDA: 변수 간 관게 분석
- 데이터 요약표: 성별 직업별 빈도수 분포표 만들기
- 그래프 만들기: 단일변수, 직무내용(범주(문자)) + hue(성별) -> countplot
CDA: 검증
- x(직무내용(범주(문자))), y(성별(범주(문자))): Chi Square Test
2.2.1. 직업 변수 검토 및 전처리
성별, 직업코드(->직무내용) 전처리
이제 필요한 변수들을 먼저 가져와야하는데, 성별과 직업코드, 직무내용을 가져올 것이다.
이는 위 subject_five에서 merge를 진행한 데이터(subject_five_merge)를 가져오자.
subject_six_temp=subject_five_merge[["성별", "직업코드", "직무내용"]]
subject_six=subject_six_temp.copy()
subject_six["성별"]=np.where(subject_six["성별"]==1.0, "남", "여")
subject_six["성별"].value_counts()성별
남 2289
여 2245
Name: count, dtype: int64그런데 보면 바로 copy()를 하지않고 temp라는 임시공간에 저장한 후 copy를 했다.
만약 이런식으로 하지않는다면, 즉 바로 copy를 하여 merge를 건드리면 에러가 발생하곤하기 때문이다.
이제 성별 직업빈도수를 보자.
먼저 남성이다.
m=subject_six[subject_six["성별"]=="남"]
m["직무내용"].value_counts()직무내용
경영 관련 사무원 212
자동차 운전원 114
청소원 및 환경미화원 92
영업 종사자 91
건물 관리원 및 검표원 78
...
통계 관련 사무원 1
문화∙예술 관련 기획자 및 매니저 1
공예 및 귀금속 세공원 1
재활용 처리 및 소각로 조작원 1
철도운송 관련 종사자 1
Name: count, Length: 143, dtype: int64이제 시각화를 해보자.
sns.countplot(data=m, x="직무내용")
plt.title("남자 직업 빈도수")
(눈이 아파서 주피터 테마를 다크모드로 바꿈 👀)
그런데 이렇게 보니 내용이 너무 많으니까 위에서 value_counts()를 따로 담고, 10개만보자.
그리고 직무내용이 길기때문에 y로 옮겨주자.
m_count=m["직무내용"].value_counts().head(10)
sns.countplot(data=m, y="직무내용", order=m_count.index)
plt.title("남자 직업 빈도수")
plt.xlabel("인원수")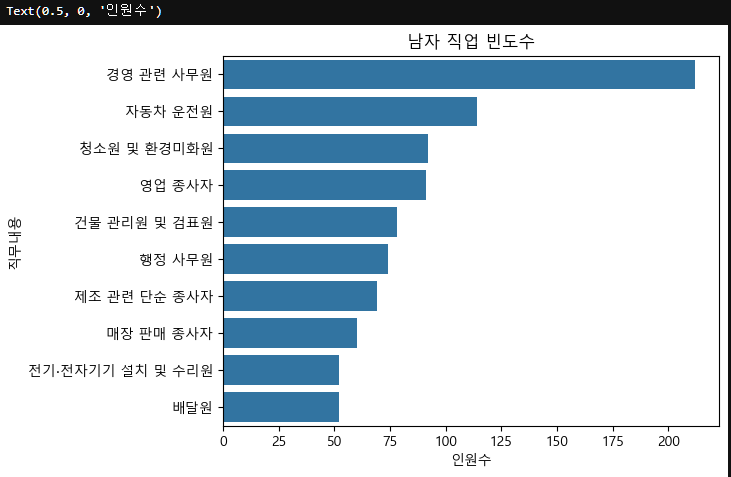
이제 여성의 직업빈도수를 보자.
f=subject_six[subject_six["성별"]=="여"]
f_count=f["직무내용"].value_counts().head(10)
f_count직무내용
청소원 및 환경미화원 261
회계 및 경리 사무원 151
돌봄 및 보건 서비스 종사자 151
제조 관련 단순 종사자 128
매장 판매 종사자 106
음식 관련 단순 종사자 101
기타 서비스 관련 단순 종사자 83
고객 상담 및 기타 사무원 74
조리사 72
간호사 70
Name: count, dtype: int64sns.countplot(data=f, y="직무내용", order=f_count.index)
plt.title("여자 직업 빈도수")
plt.xlabel("인원수")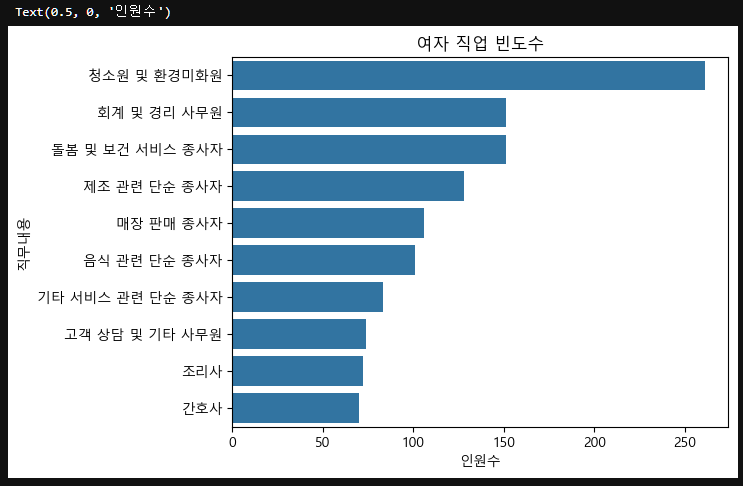
2.2.2. 성별과 직업 관계 분석
성별로 어떤 직업이 많은지
시각화, 데이터 요약표(성별 직업별 빈도수)
먼저 시각화를 해주자.
서브카테고리로 성별을 두어, 직업 빈도수 top10을 그래프로 그리고 그를 성별에 따라 다시 나누자.
top10=subject_six["직무내용"].value_counts().head(10) # 직무 빈도수 top10
sns.countplot(data=subject_six, y="직무내용", hue="성별", order=top10.index) # top의 index부분인 직무내용 가져오기
plt.title("남녀 직업 빈도수")
plt.xlabel("인원수")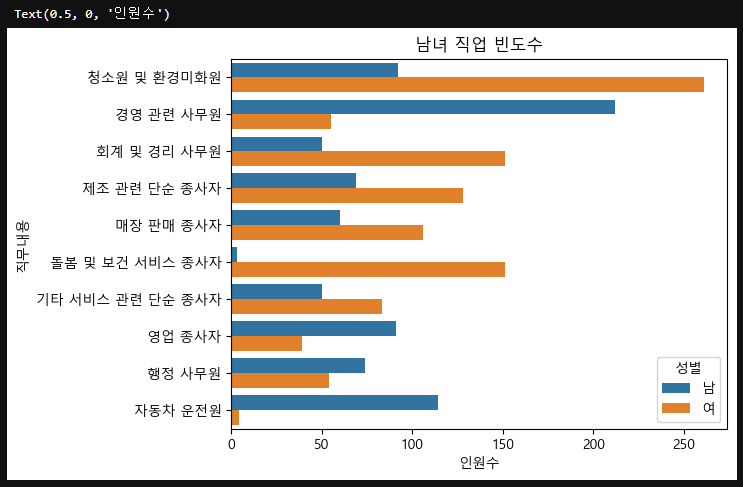
이번에는 직무내용을 그룹화하여 성별 요약표를 만들어보자.
subject_six_count=subject_six.groupby(["직무내용", "성별"])["성별"].count().reset_index(name="인원수")
subject_six_count.sort_values("인원수", ascending=False).head(10)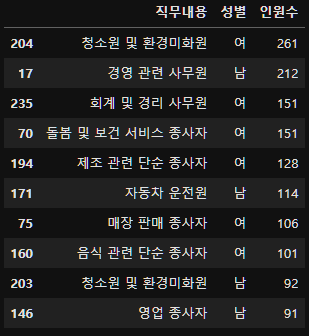
2.2.3. 통계적 가설 검정
성별에 따른 직업의 차이가 있는지
다변수, x(직무내용(범주(문자))), y(성별(범주(문자))): Chi Square Test
(숫자-숫자: 상관 / 문자-문자: 연관)
가설:
- 귀무가설: 성별에 따른 직무의 차이가 없다.
- 대립가설: 성별에 따른 직무의 차이가 있다.
subject_six_crosstab=pd.crosstab(subject_six["직무내용"], subject_six["성별"])
subject_six_crosstab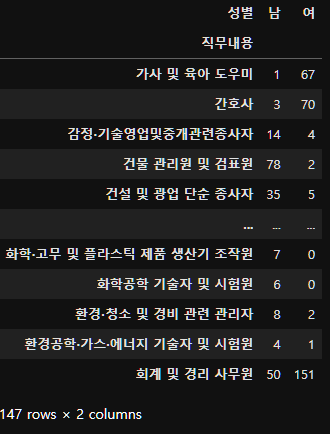
result=stats.chi2_contingency(subject_six_crosstab)
resultChi2ContingencyResult(statistic=1979.0205094555938, pvalue=0.0, dof=146, expected_freq=array([[ 34.32995148, 33.67004852],
[ 36.85421262, 36.14578738],
[ 9.0873401 , 8.9126599 ],
[ 40.38817821, 39.61182179],
[ 20.1940891 , 19.8059109 ],
[ 8.58248787, 8.41751213],
[ 12.11645346, 11.88354654],
[ 5.5533745 , 5.4466255 ],
...
...result.statistic, result.pvalue(1979.0205094555938, 0.0)pvalue 0.0 ... < 0.05 유의수준 으로 대립가설이 참이고, 연관성이 있다.
이렇게하여 분석결과는 Chi Square Test를 통해 성별에 따라 직업에 종사하는 사람의 수가 차이가 있다(통계량: 1970.0, pvalue < 0.05)가 나온다.
분석결과를 한장으로 요약하려면, 시각화한 사진, 직무내용을 그룹화하여 성별 요약표 사진, Chi Square Test 검정 결과 사진을 통해 성별에 따라 직업의 차이가 있다는 것을 보여주면 된다.
2.3. 종교 유무에 따른 이혼율
⭐ 종교가 있으면 이혼을 덜 할지
DDA: 분석에 활용할 변수(종교, 혼인상태) 전처리
- 이상치, 결측치 정제
- 변수값 다루기 편하게 수정 -> 종교유무 숫자->문자 / 혼인상태 숫자->문자 변환 후 컬럼(파생변수) 만들기
EDA: 변수 간 관게 분석
- 데이터 요약표: 종교 유무별 이혼율 요약표 만들기
- 그래프 만들기: 단일변수, 혼인타입(범주(문자)) + hue(종교유무) -> countplot
CDA: 검증
- x(종교유무(범주(문자))), y(혼인타입(범주(문자))): Chi Square Test
2.3.1. 변수 검토 및 전처리
성별 직업 빈도수까지 진행하면서 직업으로 묶인 사람만 뽑아서 사용했기 때문에 null값이 다 날라갔다. 따라서 다시 person을 불러와야한다.
person=pd.read_csv("./data/pandas/project/person.csv")
job_list=pd.read_excel("./data/pandas/project/joblist.xlsx")
print(person.shape, job_list.shape)(14418, 7) (156, 2)이 둘을 직업코드를 기준으로 merge한다.
이때 직업이 없다고해서 삭제시키면 안되기 때문에 left조인으로 한다.
person_job_merge=person.merge(job_list, on="직업코드", how="left")
person_job_merge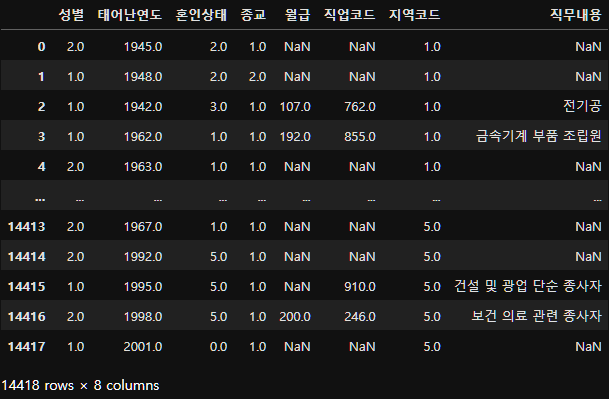
이제 merge를 그대로 쓰면 에러가 발생하니까 copy해주자.
subject_seven=person_job_merge.copy()
subject_seven.head() 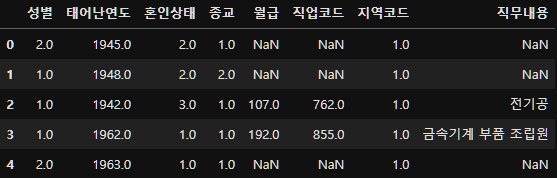
subject_seven.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 14418 entries, 0 to 14417
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 성별 14418 non-null float64
1 태어난연도 14418 non-null float64
2 혼인상태 14418 non-null float64
3 종교 14418 non-null float64
4 월급 4534 non-null float64
5 직업코드 6878 non-null float64
6 지역코드 14418 non-null float64
7 직무내용 6878 non-null object
dtypes: float64(7), object(1)
memory usage: 901.2+ KB2.3.2. 종교 변수 검토 및 전처리
1 있음 -> 유 / 2 없음 -> 무 / 9 모름 -> 무응답

subject_seven["종교"].value_counts()종교
2.0 7815
1.0 6603
Name: count, dtype: int64살펴보니 무응답은 없다.
이제 1과 2로 표시된 종교의 여부를 보기 쉽게 유와 무로 변경하자.
subject_seven["종교유무"]=np.where(subject_seven["종교"]==1, "유", "무")
subject_seven["종교유무"].value_counts()종교유무
무 7815
유 6603
Name: count, dtype: int64종교유무를 시각화해보면,
sns.countplot(data=subject_seven, x="종교유무")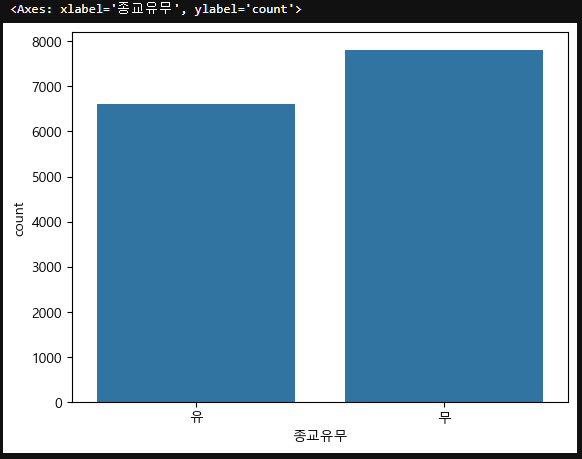
2.3.3. 혼인 상태 변수 검토 및 전처리
파생변수 만들기: 1 -> 유배우 / 3 -> 이혼 / 2~6 -> 기타

subject_seven["혼인타입"]=np.where(subject_seven["혼인상태"]==1, "유배우",
np.where(subject_seven["혼인상태"]==3, "이혼", "기타"))
subject_seven["혼인타입"].value_counts()혼인타입
유배우 7190
기타 6539
이혼 689
Name: count, dtype: int64subject_seven.columnsIndex(['성별', '태어난연도', '혼인상태', '종교', '월급', '직업코드', '지역코드', '직무내용', '혼인타입'], dtype='object')이제 분석하려는 목표는 종교 유무에 따른 이혼율이기 때문에 기타는 필요가 없다.
따라서 기타가 아닌 것들을 따로 빼주자.
new_df_except_etc=subject_seven[subject_seven["혼인타입"] != "기타"]
new_df_except_etc["혼인타입"].value_counts()혼인타입
유배우 7190
이혼 689
Name: count, dtype: int64new_df_except_etc
2.3.4. 종교 유무와 이혼율 관계 분석
종교가 있으면 이혼을 덜 할지
시각화, 데이터 요약표 - 종교 유무별 혼인타입
혼인타입(범주형(문자)의 빈도수를 보기 위해서 countplot을 사용하며, 서브카테고리로 종교유무를 지정한다.
sns.countplot(data=new_df_except_etc, x="혼인타입", hue="종교유무")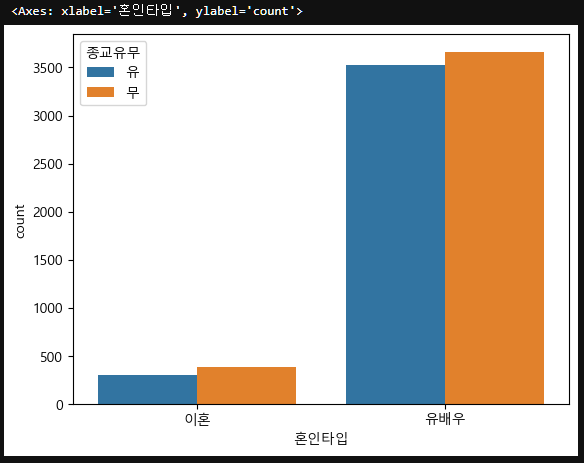
이제 데이터 요약표를 만들어보자.
종교별 그룹화 후 혼인타입으로 비율을 구하자.
그리고 백분율로 표시하는 열을 하나 더 만들어보자.
result=new_df_except_etc.groupby(["종교유무", "혼인타입"])["혼인타입"].count().reset_index(name="인원수")
result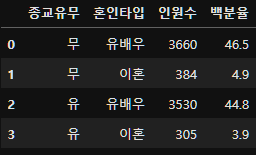
그렇다면 이혼한 인원들의 종교유무 비율을 보자.
result[result["혼인타입"] == "이혼"]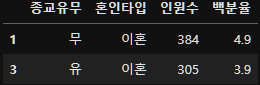
2.3.5. 통계적 가설 검증
종교 유무에 따른 혼인 타입의 차이가 있는지
다변수, x(종교유무(범주(문자))), y(혼인타입(범주(문자))): Chi Square Test
(숫자-숫자: 상관 / 문자-문자: 연관)
가설:
- 귀무가설: 종교 유무에 따른 이혼율의 연관성이 없다.
- 대립가설: 종교 유무에 따른 이혼율의 연관성이 있다.
먼저 Chi Square Test에 사용할 crosstab을 만들고,
subject_seven_tab=pd.crosstab(new_df_except_etc["혼인타입"], new_df_except_etc["종교유무"])
subject_seven_tabstats.chi2_contingency(subject_seven_tab)Chi2ContingencyResult(statistic=5.6769927793878825, pvalue=0.01718880447200066, dof=1, expected_freq=array([[3690.36172103, 3499.63827897],
[ 353.63827897, 335.36172103]]))pvalue 0.01718880447200066 < 0.05 유의수준 이므로, 대립가설 참, 종교와 이혼율의 연관성이 있다.
이렇게하여 분석결과는 Chi Square Test를 통해 종교와 이혼율이 연관이 있다(통계량: 5.67, pvalue < 0.05)가 나온다.
분석결과를 한장으로 요약하려면, 시각화한 사진, 종교별 그룹화 후 혼인타입으로 비율을 구한 요약표 사진, Chi Square Test 검정 결과 사진을 통해 종교에 따라 혼인타입의 차이가 있다는 것을 보여주면 된다.
2.4. 지역별 연령대 비율
⭐ 어느 지역에 노년층이 많을지
DDA: 분석에 활용할 변수(태어난연도, 지역코드) 전처리
- 변수값 다루기 편하게 수정: 태어난연도->나이 파생변수->연령대(문자) / 지역코드+지역 데이터프레임 생성 및 병합
EDA: 변수 간 관게 분석
- 데이터 요약표: 지역별 연령대 비율 요약표 만들기
- 그래프 만들기: 가로막대 그래프, barh
CDA: 검증
- x(지역(범주(문자))), y(연령대(범주(문자))): Chi Square Test
2.4.1. 연령대 변수 검토 및 전처리
subject_eight=subject_seven.copy()
subject_eight.head()
태어난연도를 이용하여 나이라는 파생변수를 만들고 각 연령대를 나누자.
subject_eight["나이"]=2019-subject_eight["태어난연도"]+1
subject_eight["연령대"]=np.where(subject_eight["나이"] < 30, "초년층",
np.where(subject_eight["나이"] <= 59, "중년층", "노년층"))
subject_eight["연령대"].value_counts().sort_index()연령대
노년층 5955
중년층 4963
초년층 3500
Name: count, dtype: int64subject_eight.head()
2.4.2. 지역코드 변수 검토 및 전처리
2.4.2.1 지역코드 목록 만들기
지역별 연령대의 비율을 구하기 위함이니 먼저 지역코드와 지역이 어떻게 이루어져 있는지 코드북을 확인한다.

이에 맞춰서 DataFrame을 새롭게 생성한다.
list_region=pd.DataFrame({"지역코드":[1, 2, 3, 4, 5, 6, 7],
"지역":["서울",
"수도권(인천/경기)",
"부산/경남/울산",
"대구/경북",
"대전/충남",
"강원/충북",
"광주/전남/전북/제주"]})
list_region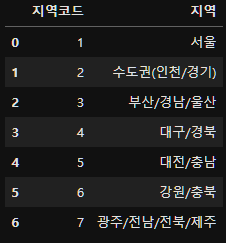
2.4.2.2. 병합
이제 이렇게 테이블을 만들었으니 subject_eight의 지역코드와 list_region 테이블을 join 해보자.
subject_eight_merge=subject_eight.merge(list_region, on="지역코드", how="left")
subject_eight_merge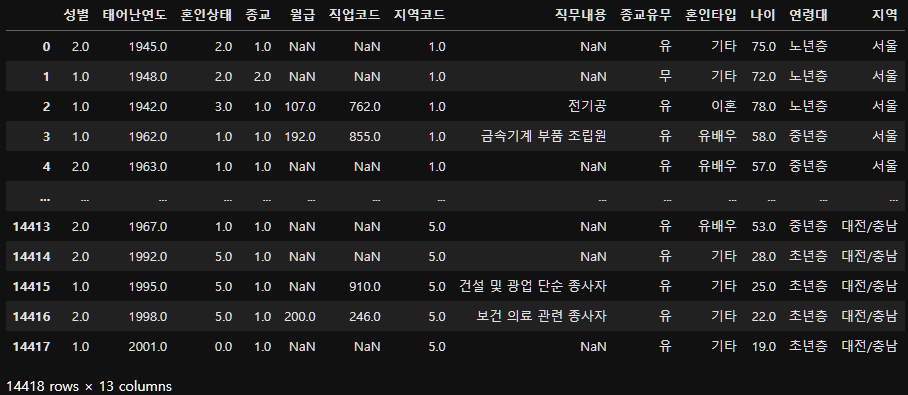
2.4.3. 지역별 연령대 분포 관계 분석
시각화, 데이터 요약표(지역별 연령대 비율)
어떤 지역에 몇명이 사는지를 보기 때문에 countplot을 사용하며, 서브카테고리로 연령대를 준다.
여기서도 지역명이 x축에 적히면 겹치기 때문에 y축으로 지정한다.
sns.countplot(data=subject_eight_merge, y="지역", hue="연령대")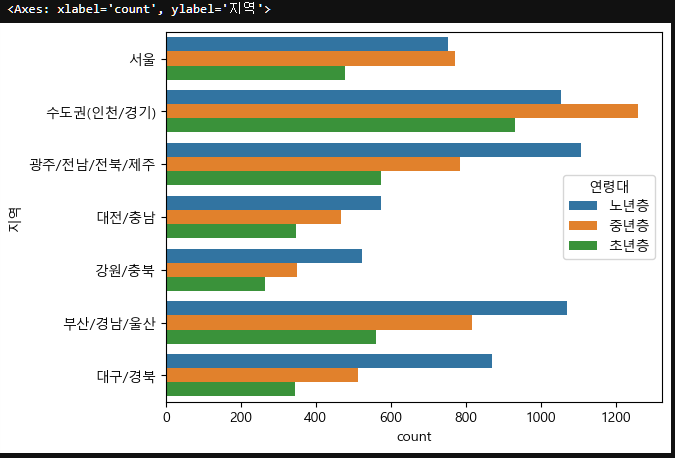
이제 지역별 연령대 비율의 요약표를 만들자.
result=subject_eight_merge.groupby("지역")["연령대"].value_counts().reset_index(name="인원수")
result.head()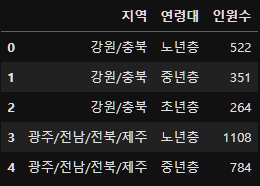
앞서 진행했던 부분중에 아래와 같이 백분율을 구했었는데,
result["백분율"]=round(result["인원수"] / result["인원수"].sum() * 100, 1)
value_counts(normalize=True)를 사용하면 비율로 계산이 가능하다.
result=subject_eight_merge.groupby("지역")["연령대"].value_counts(normalize=True).reset_index(name="인원수")
result["인원수백분율"]=round(result["인원수"] * 100, 1)
result.head()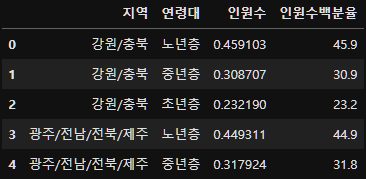
너무 복잡한 느낌이 있으니 pivot_table로 정리해보자.
pivot_tb=result.pivot_table(index="지역", columns="연령대", values="인원수백분율")
pivot_tb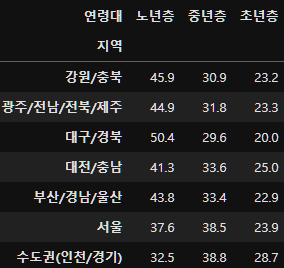
이제 시각화를 진행하는데, 이번에는 DataFrame에 적용가능한 matplotlib에서 지공하는 plot.barh 라는 가로막대를 그려보자.
pivot_tb.plot.barh(stacked=True)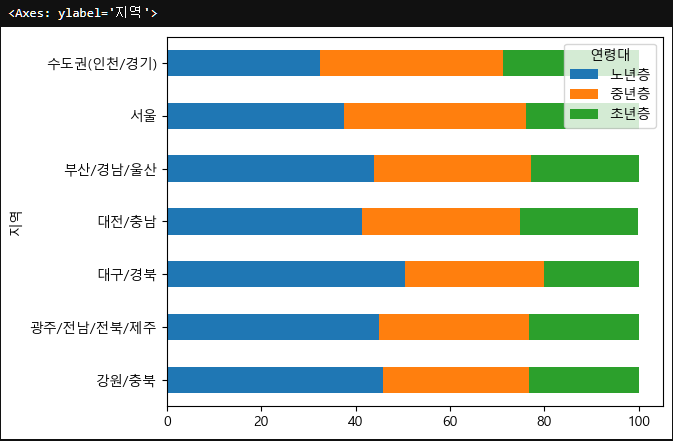
물론 pivot_df라는 데이터프레임이기 때문에 seaborn으로 표현도 가능하지만 더 편리하기 때문에 사용한 것이다.
자세한 내용은 Pandas DataFrame plot API문서를 참고하자.
2.4.4. 통계적 가설 검증
연령대에 따라 거주지역이 다른지
다변수, x(지역(범주(문자))), y(연령대(범주(문자))): Chi Square Test
(숫자-숫자: 상관 / 문자-문자: 연관)
가설:
- 귀무가설: 연령대별 거주 지역의 연관성이 없다.(독립적이다.)
- 대립가설: 연령대별 거주 지역의 연관성이 없다.(독립적이지 않다.)
그리고 앞서 비율과 백분율을 계산할때,
result=subject_eight_merge.groupby("지역")["연령대"].value_counts(normalize=True).reset_index(name="인원수")
result["인원수백분율"]=round(result["인원수"] * 100, 1)
result.head()이와 같이 사용하였는데, crosstab을 사용할때 좀더 쉽게 표현이 가능하다.
먼저 crosstab을 생성하면,
subject_eight_crosstab=pd.crosstab(subject_eight_merge["지역"], subject_eight_merge["연령대"])
subject_eight_crosstab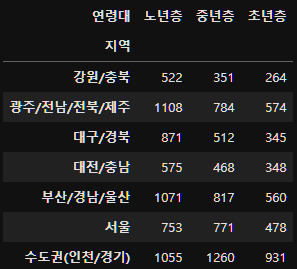
type(subject_eight_crosstab)pandas.core.frame.DataFrame이렇게 DataFrame의 형태처럼 나온다.
그런데 위처럼 groupby한 후, 비율을 계산해주는 방법이 아닌 아래와 같이 사용하면 한번에 비율까지 표현이 가능해서 편하다.
subject_eight_crosstab=pd.crosstab(subject_eight_merge["지역"], subject_eight_merge["연령대"], normalize="all")
subject_eight_crosstab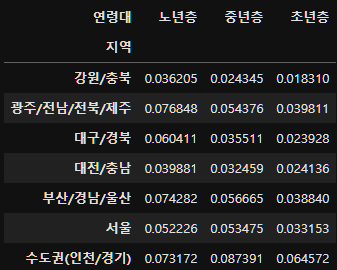
만약 백분율로 표시하고싶다면 끝에 * 100을 붙여주면 된다.
subject_eight_crosstab=pd.crosstab(subject_eight_merge["지역"], subject_eight_merge["연령대"], normalize="all") * 100
subject_eight_crosstab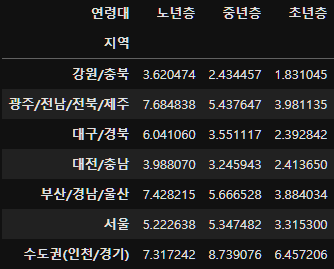
그래서 결과값을 그릴떄는 df.plot.~로 표현하면 편하다.
ax=subject_eight_crosstab.plot.line()
fig=ax.get_figure()
fig.set_size_inches(10,6)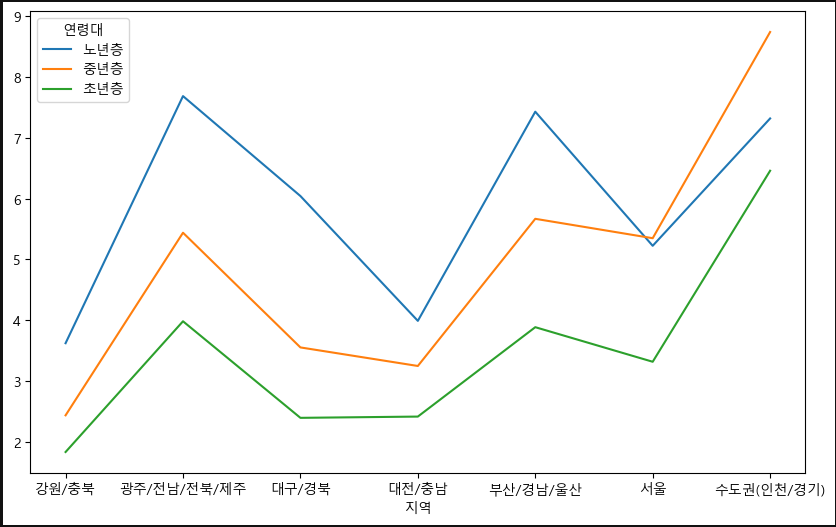
이제 만든 crosstab을 Chi Square Test에 사용하자.
stats.chi2_contingency(subject_eight_crosstab)Chi2ContingencyResult(statistic=1.471450362300088, pvalue=0.999882251090635, dof=12, expected_freq=array([[3.25710822, 2.71453032, 1.91433732],
[7.06422943, 5.88745099, 4.15194005],
[4.95011697, 4.1255131 , 2.90938865],
[3.98472958, 3.32094255, 2.34199052],
[7.01266571, 5.8444769 , 4.12163392],
[5.73503135, 4.77967433, 3.37071532],
[9.29865723, 7.74966177, 5.46520576]]))pvalue 0.999882251090635 > 0.05 유의수준 으로 귀무가설이 참이고, 연령대별 지역 거주의 연관성이 없다.
이렇게하여 분석결과는 Chi Square Test를 통해 연령대에 따른 거주 지역의 차이는 없다(통계량: 1.47, pvalue > 0.05)가 나온다.
분석결과를 한장으로 요약하려면, 시각화한 가로막대 사진, 지역별 연령대 비율표 사진, Chi Square Test 검정 결과 사진을 통해 연령대에 따른 거주 지역의 차이가 없다는 것을 보여주면 된다.
⭐ 정리
이렇게 데이터셋에서 총 8가지의 주제를 정하여 DDA, EDA, CDA 전체를 진행해봤는데 CDA 부분에서 확실히 이해가 안되는 부분이 많았지만 여러번 반복하다보니 느낌을 잡을 수 있었다.
통계적 데이터 분석 절차인 DDA, EDA, CDA 이후 이제 PDA를 진행할 때인데, 머신러닝 부분이 정말 핵심이기 때문에 들어가기 전에 이에 대한 심화로 한번 더 진행해보고 확실히 익히고 가겠다.
