
📌 사용 환경
Python 3.10.2
conda 24.9.0
JupyterLab 4.2.5
이번에는 CDA에 대한 심화과정이다.
한국보건사회연구원에서 발간한 조사 자료인 한국복지패널의 데이터를 가져다가 실습을 진행한다.
1. 데이터 전처리
링크:
https://www.koweps.re.kr:442/data/data/list.do - 회원가입 후 다운(2019년도 데이터)
파일:
.sav: 통계자료(통계 분석 소프트웨어 spss 전용 파일): pyreadstat 라이브러리 설치 필요
.xlsx: 내용 설명 파일
주의사항:
계속해서 내용들을 바꾸기 때문에 중간중간 저장을 자주해야함
1.1. 라이브러리 설치 및 설정
pip install pyreadstat먼저 통계분석에 필요한 라이브러리인 pyreadstat을 설치한다.(SPSS, SAS)
이로 spss, sav, sas 같은 파일을 읽어올 수 있다.
그리고 사용할 라이브러리들을 import한다.
import numpy as np
import pandas as pd
# 시각화
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rc("font", family="Malgun Gothic")
plt.rcParams["axes.unicode_minus"]=False
# 검증
import scipy.stats as stats1.2. 전처리
전체적인 전처리를 먼저 해주고 -> 분석하고 싶은대로 성별과 월급에 대한 전처리를 하고, 나이에 대한 전처리, 연령대에 대한 전처리, ... 이런식으로 진행해야 한다.
데이터를 불러오고 파악해야한다.
data=pd.read_spss("./data/pandas/project/Koweps_hpwc14_2019_beta2.sav")
data.shape(14418, 830)data.head()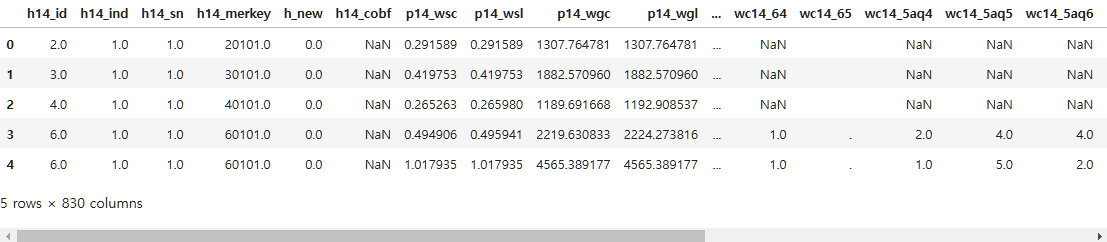
이렇게 데이터를 봤는데, 봐도 무슨 뜻인지를 모르겠다.
이 모든 컬럼을 사용할 수도 없으니 원하는 컬럼만 추출해야하고, 컬럼명도 변경해서 사용해야 한다.
따라서 이때 codebook을 봐야한다.
⭐ 이 codebook은 계속해서 보면서 참고해야한다.
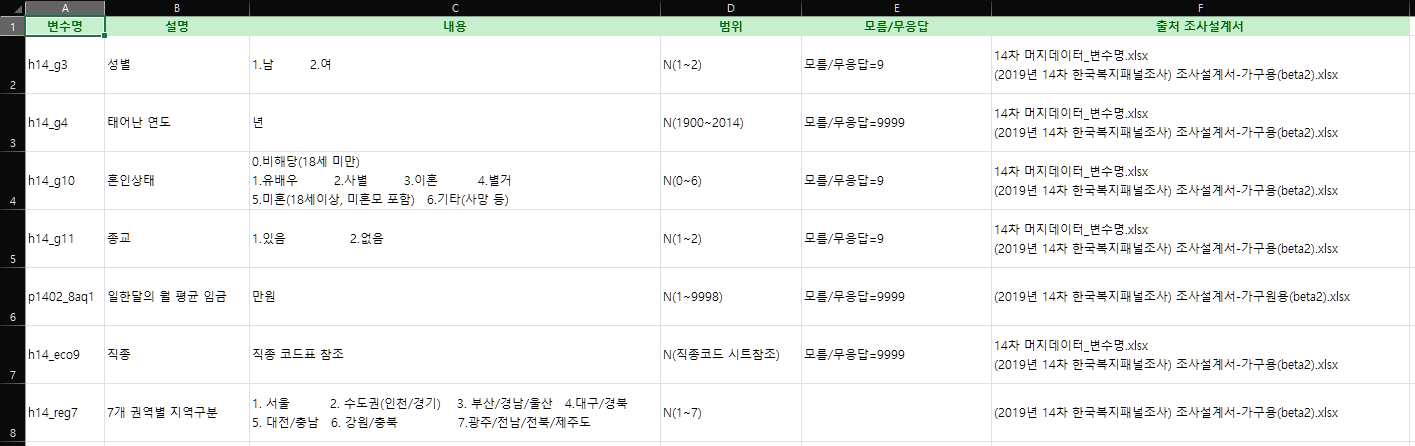
여기서 보이는 이 8개만 뽑아서 진행해보자.
person=data[["h14_g3", "h14_g4", "h14_g10", "h14_g11", "p1402_8aq1", "h14_eco9", "h14_reg7"]]
person.head()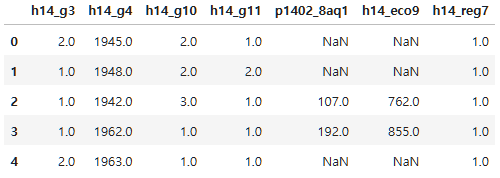
그런데 이제 이들을 전처리를 다 하고 분석으로 들어갔을때, 성별에 따른 월급 차이를 보고싶다고하면, 데이터가 굉장히 많은데 그 중에서 h14_g10의 혼인상태부분을 보니 나이가 18세 미만인 부분도 있다.
즉 18세 미만은 사람들도 있는데, 18세 미만은 월급이 없을 수 있고, 퇴직한 노년층또한 없을 수 없고 이렇기 때문에 함부로 null값을 지워버리면 안된다.
따라서 전체적인 전처리를 먼저하고 세부로 들어가서 또 다시 전처리를 해야하는 것이다.
이제 먼저 컬럼명을 저렇게 쓸 수 없으니까 보기쉽게 바꿔보자.
person=person.rename(columns={"h14_g3": "성별",
"h14_g4": "태어난연도",
"h14_g10": "혼인상태",
"h14_g11": "종교",
"p1402_8aq1": "월급",
"h14_eco9": "직업코드",
"h14_reg7": "지역코드"})
person.head()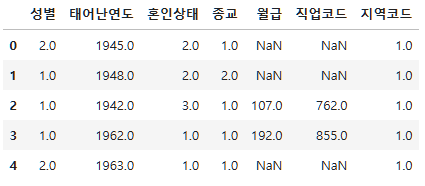
이제 이렇게 변경한 내용을 나중에 사용하기위해 csv파일로 저장해놓자.
person.to_csv("./data/pandas/project/person.csv", index=False)이제 자료형의 구성을 확인하자.
person.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 14418 entries, 0 to 14417
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 성별 14418 non-null float64
1 태어난연도 14418 non-null float64
2 혼인상태 14418 non-null float64
3 종교 14418 non-null float64
4 월급 4534 non-null float64
5 직업코드 6878 non-null float64
6 지역코드 14418 non-null float64
dtypes: float64(7)
memory usage: 788.6 KB보면 null값이 꽤 많다.
person.isna().sum()성별 0
태어난연도 0
혼인상태 0
종교 0
월급 9884
직업코드 7540
지역코드 0
dtype: int64그리고 자료형은 모두 float형이다.
성별이 0또는 1과 같이 표현이 되어있고, 혼인상태도 0~5까지 나뉘어져있으니 이런 부분은 나중에 형 변환을 해줘야한다.
person.describe().T.astype(int)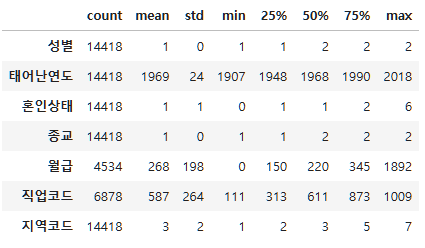
이를보면, codebook에서 / max값들에 9같은 값이 없는걸보니 모름으로 응답한 사람은 없는 거 같다.
전체에 대한 전처리는 마쳤다.
2. 분석
이제 어떤 것들을 분석할지를 정하자.
- 성별에 따른 월급 차이 - 성별에 따라 월급차이가 있는지
- 나이에 따른 월급 관계 - 몇 살때 월급을 가장 많이 받을지
- 연령대에 따른 월급 차이 - 어떤 연령대의 월급이 가장 많을지
- 연령대 및 성별 월급 차이 - 성별 월급 차이가 연령대별로 다를지
📌 이제 각 주제에 대해 다음과 같은 절차를 거쳐서 진행한다.
1단계) DDA, 변수 검토 및 전처리
- 분석에 활용할 변수 전처리
- 변수의 특징 파악, 이상치와 결측치 정제 (i.g., 월급없는사람 날리기)
- 변수의 값을 다루기 편하게 바꾸기 (i.g., 성별 float형 -> 문자형)
2단계) EDA, 변수 간 관계 분석
- 변수 간 관계 분석
- 데이터 요약 표(groupby, pivot_table), 그래프 만들기
3단계) CDA, 통계적 가설 검정
- 가설 설정
- 가설 검증 절차
2.1. 성별에 따른 월급 차이
⭐ 성별에 따라 월급차이가 있는지
DDA: 분석에 활용할 변수(성별, 월급) 전처리
- 이상치, 결측치 정제
- 변수값 다루기 편하게 수정 -> 남(1), 여(2), 무응답(9)
EDA: 변수 간 관게 분석
- 데이터 요약표: 성별월급 평균표 만들기
- 그래프 만들기: x(성별(범주(문자))), y(월급(연속(숫자))) -> barplot
CDA: 검증
- x(성별(범주(문자))), y(월급(연속(숫자))): 정규성 검증 -> 등분산 검증 -> 2집단/3집단이상
이제 성별에 대한 전처리, 월급에 대한 전처리를 먼저 진행하고,
성별에 따른 월급차이가 있는지를 진행한다.
2.1.1. 성별 변수 검토 및 전처리
이상치, 결측치 확인
성별 값 수정: 1(남), 2(여)
subject_one=person.copy()
subject_one["성별"].info()<class 'pandas.core.series.Series'>
RangeIndex: 14418 entries, 0 to 14417
Series name: 성별
Non-Null Count Dtype
-------------- -----
14418 non-null float64
dtypes: float64(1)
memory usage: 112.8 KBsubject_one["성별"].describe()count 14418.000000
mean 1.548828
std 0.497627
min 1.000000
25% 1.000000
50% 2.000000
75% 2.000000
max 2.000000
Name: 성별, dtype: float64min과 max를 보니 이상치가 없다는 것을 알 수 있다.
만약 이상치가 있다면?
결측치로 처리한 후,
subject_one["성별"]=np.where(subject_one["성별"]==9, np.nan, subject_one["성별"])
결측치 처리가 됐는지 확인해야한다.
subject_one["성별"].isna().sum()
그 이후 결측치를 대체 또는 삭제하면 된다.
그리고 각 몇명인지 확인해보면,
subject_one["성별"].value_counts()성별
2.0 7913
1.0 6505
Name: count, dtype: int64
즉 남성이 6505명, 여성이 7913명이다.
그러면 이제 성별 값을 다루기 편하도록 남과 여로 수정해보자.
subject_one["성별"]=np.where(subject_one["성별"]==1.0, "남", "여")
subject_one["성별"].value_counts()성별
여 7913
남 6505
Name: count, dtype: int64이제 시각화를 해보는데, 단일 변수 시각화의 범주형(문자)이기 때문에 countplot또는 pie chart를 사용한다.
sns.countplot(data=subject_one, x="성별")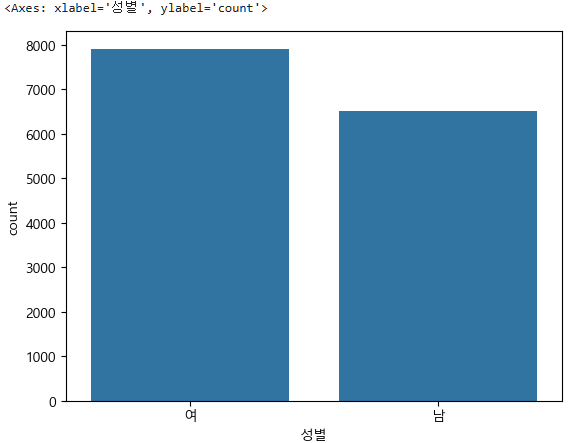
이번에는 비율을 보기 위해 pie chart를 사용해보자.
plt.pie(x=subject_one["성별"].value_counts(),
labels=subject_one["성별"].value_counts().index,
autopct="%.1f%%",
explode=[0, 0.1])
plt.show()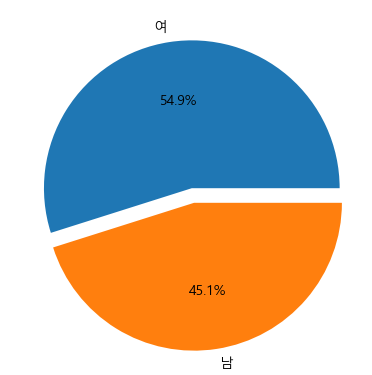
2.1.2. 월급 변수 검토 및 전처리
이상치, 결측치 확인
subject_one["월급"].info()<class 'pandas.core.series.Series'>
RangeIndex: 14418 entries, 0 to 14417
Series name: 월급
Non-Null Count Dtype
-------------- -----
4534 non-null float64
dtypes: float64(1)
memory usage: 112.8 KB총 14418개의 데이터 중, 4534개의 데이터만 있다.
즉 나머지는 결측치 인 것이다.
print("결측치:", subject_one["월급"].isna().sum())결측치: 9884subject_one["월급"].describe().astype(int)count 4534
mean 268
std 198
min 0
25% 150
50% 220
75% 345
max 1892
Name: 월급, dtype: int32여기보면 0이 있는데, 이를 날릴지 대체할지를 결정해야한다.
또, 코드북을 보면 9999가 모름/무응답 으로 대답한 사람인데 어디에 있는지 모른다.

subject_one_salary_zero=subject_one[subject_one["월급"]==0]
print(subject_one_salary_zero.shape)
subject_one_salary_zero.head()(7, 7)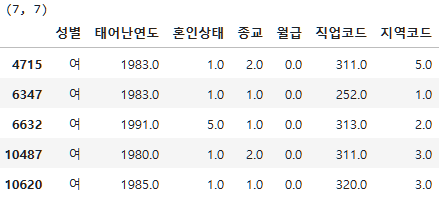
subject_one_salary_9999=subject_one[subject_one["월급"]==9999]
print(subject_one_salary_9999.shape)
subject_one_salary_9999.head()
이렇게보니 0으로 응답한 사람은 7명, 무응답인 사람은 0명이다.
만약 이 이상치들을 결측치로 바꾸고 싶다면 다음과 같이하면된다.
subject_one["월급"]=np.where(subject_one["월급"]==9999, np.nan, subject_one["월급"])
subject_one["월급"]=np.where(subject_one["월급"]==0, np.nan, subject_one["월급"])
subject_one["월급"].isna().sum()
그러면 일단 결측치를 떨궈주자.
subject_one.dropna(inplace=True)
subject_one["월급"].isna().sum()0subject_one.shape(4534, 7)이렇게 결측치를 삭제하고나니 4534개만 남은 것을 알 수 있다.
이제 이들을 시각화하면 다음과 같다.
단일변수의 연속형을 시각화하는 것이기 때문에 histplot이나 boxplot을 사용하면 된다.
sns.histplot(data=subject_one, x="월급", kde=True)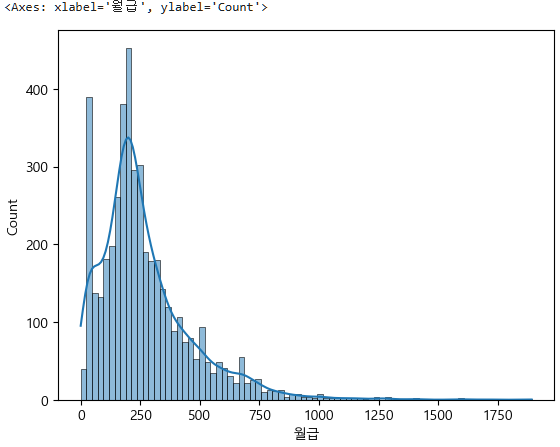
boxplot도 보자.
sns.boxplot(data=subject_one, x="월급")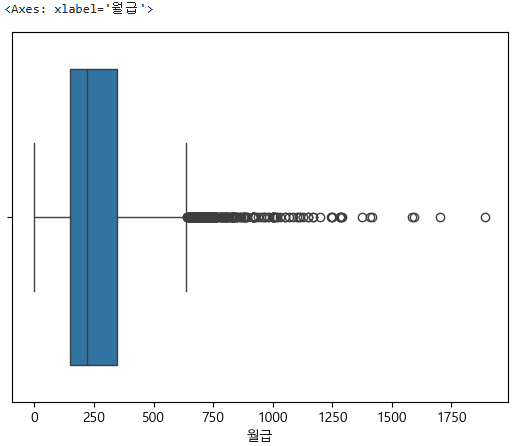
이제 DDA가 끝났고 EDA 시각화를 중간중간 했는데 조금 더 자세히 변수간 관계를 분석하고 성별 월급 평균표를 만들고 그래프를 그려보자.
2.1.3. 성별, 월급 간 관계 분석
성별에 따른 월급 차이: 성별에 따라 월급이 다를지
시각화, 데이터 요약
다변수이며 x(성별(문자형)) y(월급(숫자형)) 이므로, barplot
sns.barplot(data=subject_one, x="성별", y="월급", errorbar=None)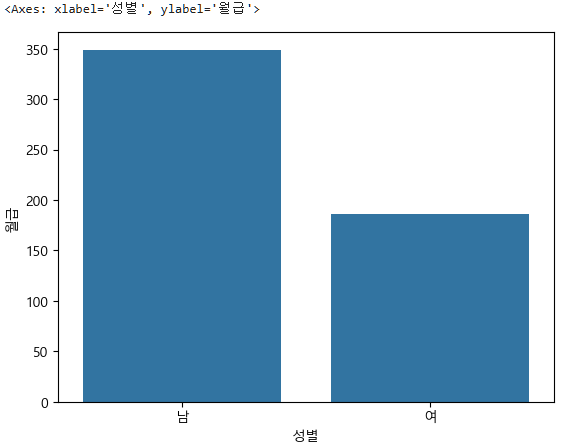
요약표도 하나 만들어주자.
subject_one.groupby("성별")["월급"].mean()성별
남 349.037571
여 186.293096
Name: 월급, dtype: float64subject_one.groupby("성별")["월급"].mean().reset_index(name="월급평균")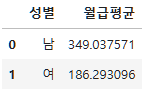
pivot_table로 만들려면 다음과 같다.
subject_one_table=subject_one.pivot_table(index="성별", values="월급", aggfunc="mean")
subject_one_table.rename(columns={"월급":"월급평균"}, inplace=True)
subject_one_table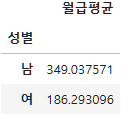
2.1.4. 통계적 가설 검정
성별에 따른 월급 차이: 성별에 따라 월급이 다를지
다변수, x(성별(범주(문자))), y(월급(연속(숫자))): y, 월급의 정규성 확인 -> 정규면 등분산/이분산, 비정규면 -> 2집단, 3집단 이상
가설:
- 귀무가설: 남녀간 월급의 차이가 없다.
- 대립가설: 남녀간 월급의 차이가 있다.
이제 이렇게 분석을 완료했으니 이제 CDA, 통계적 가설 검정을 해야한다.
y, 월급의 정규성 검정 먼저 진행해야 한다.
stats.normaltest(subject_one["월급"])NormaltestResult(statistic=1657.4427188351524, pvalue=0.0)pvalue 0.0 < 0.05 이므로 대립가설이 참, 비정규분포임을 확인했다.
이제 비정규임을 확인했으니까 x항목의 수를 봐야한다.
그런데 여기서는 남/녀 둘이니까 2집단인 Wilcoxon Test를 진행한다.
subject_one_m=subject_one[subject_one["성별"]=="남"]
subject_one_f=subject_one[subject_one["성별"]=="여"]
subject_one_m.shape, subject_one_f.shape((2289, 7), (2245, 7))이제 Wilcoxon Test를 위해 ranksums()함수를 사용한다.
stats.ranksums(subject_one_m["월급"], subject_one_f["월급"])RanksumsResult(statistic=30.80580065407471, pvalue=2.1912606852089194e-208)pvalue 0.00...219 < 0.05 유의수준 이므로 대립가설이 참이고, 남여 월급의 차이가 있다.
이렇게하여 분석결과는 Wilcoxon Test를 통해 통계적으로 남여 월급의 차이가 있다(pvalue < 0.05)가 나온다.
이렇게하여 분석결과를 한장으로 요약하려면, 시각화한 사진, 성별 월급 평균 비교표 사진, 윌콕슨 검정 결과 사진을 통해 남여 월급의 차이가 있다는 것을 보여주면 된다.
2.2. 나이에 따른 월급 관계
⭐ 몇 살때 월급을 가장 많이 받을지
DDA: 분석에 활용할 변수(나이, 월급) 전처리
- 이상치, 결측치 정제
- 변수값 다루기 편하게 수정 -> 태어난연도로 나이 컬럼(파생변수) 만들기
EDA: 변수 간 관게 분석
- 데이터 요약표: 나이별 월급 평균표 만들기
- 그래프 만들기: x(나이(순서(시간))), y(월급(연속(숫자))) -> lineplot
- (그런데 나이를 순서형으로 보니까 순서형으로 하고 lineplot으로 시각화)
CDA: 검증
- x(나이(연속(숫자))), y(월급(연속(숫자))): 상관분석(corr)
- 정규성 분석: 정규(personr), 비정규(spearmanr)
이번에는 나이에 대한 전처리, 월급에 대한 전처리는 생략하고,
나이에 따른 월급차이가 있는지를 진행한다.
2.2.1. 나이 변수 검토 및 전처리
이번에는 나이와 월급의 관계를 분석하는데,
1번째 주제에서 진행했던 월급을 그대로 사용할 수 있어서 suject_one을 복사해서 사용하면 된다.
subject_two=subject_one.copy()subject_two.head()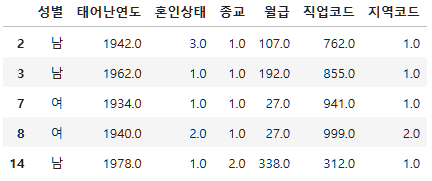
그리고 info()를 확인해보면,
subject_two["태어난연도"].info()<class 'pandas.core.series.Series'>
Index: 4534 entries, 2 to 14416
Series name: 태어난연도
Non-Null Count Dtype
-------------- -----
4534 non-null float64
dtypes: float64(1)
memory usage: 70.8 KB이처럼 이미 subject_one에서 결측치를 제거했기 때문에 제거된 4534개만 나온다.
물론 아래와 같이 확인해도 된다.
print(subject_two["태어난연도"].dtypes)
print(subject_two["태어난연도"].size)
print(subject_two["태어난연도"].isna().sum())float64
4534
0이상치를 확인해보자.
subject_two["태어난연도"].describe().astype(int)count 4534
mean 1971
std 15
min 1928
25% 1961
50% 1972
75% 1982
max 2001
Name: 태어난연도, dtype: int32확인해보니 중간값이 1971, max가 2001, min은 1928년생
그리고 코드북에가서 보면, 태어난 연도의 무응답이 9999다.

그런데 max값에 9999가 아니기 때문에, 무응답, 즉 이상치는 없다.
만약 이상치가 있다면? 계속말했듯이 결측치 처리이후 대체 또는 삭제 하면 된다.
subject_two["태어난연도"]=np.where(subject_two["태어난연도"]==9999, np.nan, subject_two["태어난연도"])
subject_two["태어난연도"]=np.where(subject_two["태어난연도"]==0, np.nan, subject_two["태어난연도"])
subject_two["태어난연도"].isna().sum()
이번에는 나이에 대한 파생변수를 만들자.
대신 2019년도 자료이기 때문에 2019년도라고 가정하고 진행하자.
# current_year=pd.Timestamp.today().year # 2025년도로 하려면
current_year=2019
subject_two["나이"]=current_year-person["태어난연도"]+1
subject_two.head()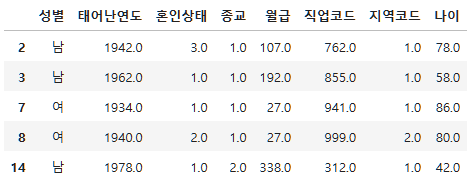
이제 이에 대한 그래프를 찍어보는데 단일변수에 연속형(숫자) 변수이기 떄문에 histplot과 boxplot을 사용한다.
sns.histplot(data=subject_two, x="나이", kde=True)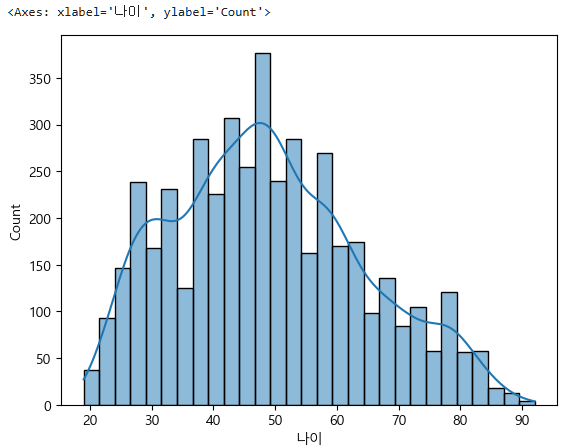
2.2.2. 월급 변수 검토 및 전처리
사실 이는 이미 앞서 주제1의 2.1.2. 월급 변수 검토 및 전처리에서 진행했다.
그래도 순서대로 보기위해 우선 진행한다.
subject_two["월급"].info()<class 'pandas.core.series.Series'>
Index: 4534 entries, 2 to 14416
Series name: 월급
Non-Null Count Dtype
-------------- -----
4534 non-null float64
dtypes: float64(1)
memory usage: 70.8 KB2.2.3. 나이와 월급 관계 분석
나이에 따른 월급 차이: 몇 살때 월급을 가장 많이 받을지
시각화, 데이터 요약
먼저 나이별 월급의 평균을 구하기 위해 나이별 그룹화를 하고, 월급의 평균을 구한다.
age_salary_mean=subject_two.groupby("나이")["월급"].mean().reset_index(name="나이월급평균")
age_salary_mean.head()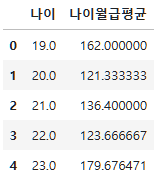
그러면 월급을 가장 많이 받는 나이가 몇살인지 알아보자.
max_age_salary_mean=age_salary_mean[age_salary_mean["나이월급평균"] == age_salary_mean["나이월급평균"].max()]
max_age_salary_mean
이제 시각화를 하는데,
다변수이고, x는 나이로 연속형이기도 하지만, 동시에 순서형이다.
그리고 y 월급은 숫자형 이므로 lineplot을 사용한다.
sns.lineplot(data=subject_two, x="나이", y="월급", errorbar=None)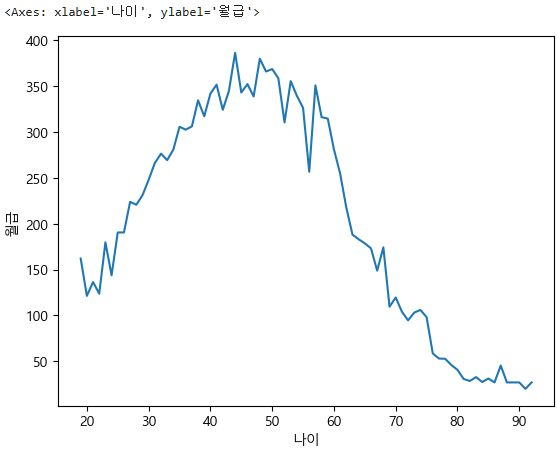
2.2.4. 통계적 가설 검정
나이에 따른 월급 차이: 나이에 따라 월급이 다를지
다변수, x(나이(연속(숫자))), y(월급(연속(숫자)))
- 상관분석(corr): 정규 / 비정규
- 귀무가설: 나이와 월급은 상관이 없다.
- 대립가설: 나이와 월급은 상관이 있다.
이제 이렇게 분석을 완료했으니 이제 CDA, 통계적 가설 검정을 해야한다.
둘 다 숫자형이기 때문에 이때는 상관분석을 진행한다.
subject_two_num=subject_two.select_dtypes(include="number")
round(subject_two_num.corr(), 2)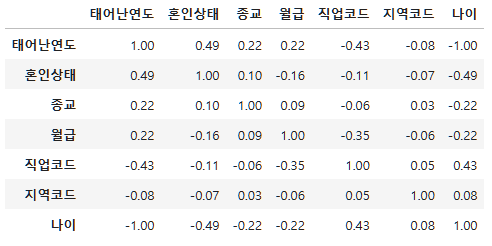
이를 보면 -값들이 있는데, 이들이 상관이 없는게 아니라, 음의 상관관계가 있는 것이다.
월급과 나이를 보면 -0.2로 음의 약한 상관관계다.
그리고 지금 월급을 기준으로 보면, 0.5를 넘어서는 게 없다.
그러면 이걸 예측으로 이어가면 예측율이 떨어지게 될 것이다.
그래서 그나마 고른다면 연도와 직업코드만 조금 연관이 있다.
즉 나이와 월급의 -0.22는 약한 상관관계이며,
40대에서 최고점을 찍고 점점 떨어지니까 정년퇴직등을 생각하면 나이가 60대 부터는 월급이 감소하는 경향이 있는 것이다.
이를 히트맵으로 보면
plt.figure(figsize=(10,5))
sns.heatmap(subject_two_num.corr(), annot=True)
plt.show()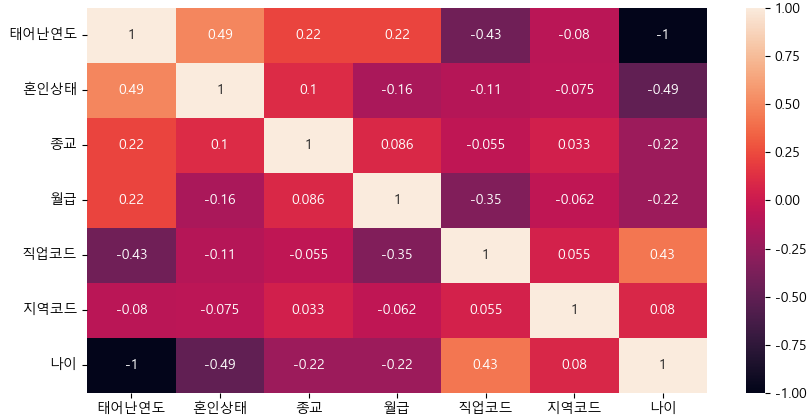
어찌됐든 우선 정규성을 검정해보자.
stats.normaltest(subject_two["월급"])NormaltestResult(statistic=1657.4427188351524, pvalue=0.0)pvalue 0.0 < 0.05 유의수준 이므로 비정규다.
따라서 spearmanr() 함수를 을 사용한다.
stats.spearmanr(subject_two["나이"], subject_two["월급"])SignificanceResult(statistic=-0.2995003794137383, pvalue=1.2825223923244415e-94)pvalue 0.000..128 < 0.05 유의수준 이므로 대립가설이 참이고, 나이와 월급의 상관성이 있다는 것이다.
이렇게하여 분석결과는 spearman를 통해 나이와 월급은 상관이 있다(통계량: 0.29, pvalue < 0.05)가 나온다.
분석결과를 한장으로 요약하려면, 시각화한 사진, 나이 월급 평균 비교표 사진으로 44살이 가장 많이 받았다는 점, spearman 검정 결과 사진을 통해 나이에 따른 월급의 차이가 있다는 것을 보여주면 된다.
2.3. 연령대에 따른 월급 차이
⭐ 어떤 연령대의 월급이 가장 많을지
DDA: 분석에 활용할 변수(나이, 월급) 전처리
- 이상치, 결측치 정제
- 변수값 다루기 편하게 수정 -> 나이로 연령대 컬럼(파생변수) 만들기
EDA: 변수 간 관게 분석
- 데이터 요약표: 연령대별 월급 평균표 만들기
- 그래프 만들기: x(연령대(범주(문자))), y(월급(연속(숫자))) -> barplot
CDA: 검증
- x(연령대(범주(문자))), y(월급(연속(숫자))): 정규성 검증 -> 등분산 검증 -> 2집단/3집단이상
2.3.1. 연령대 변수 검토 및 전처리
이번에는 나이는 만들었으니 나이를 가져와서(subject_two["나이"]) 파생변수를 만들면 된다.
월급도 만들어 놨으니 생략해도 된다.
subject_three=subject_two.copy()
subject_three.head()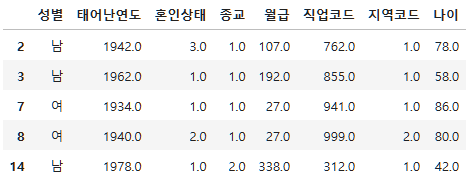
이제 연령대 파생변수를 만들어야 한다.
30세 미만을 초년층, 30~59세를 중년층, 60세 이상을 노년층으로 나눌 것이다.
# subject_three["연령대"]=np.where(subject_three["나이"] < 30, "초년", np.where(subject_three["나이"] <= 59, "중년", "노년"))
def categorize_age(age):
if age < 30:
return "초년"
elif age <= 59:
return "중년"
else:
return "노년"
subject_three["연령대"]=subject_three["나이"].apply(categorize_age)
subject_three["연령대"].value_counts().sort_index()연령대
노년 1093
중년 2927
초년 514
Name: count, dtype: int64시각화해보는데, 단일 변수 시각화의 범주형(문자)이기 때문에 countplot을 사용한다.
sns.countplot(data=subject_three, x="연령대")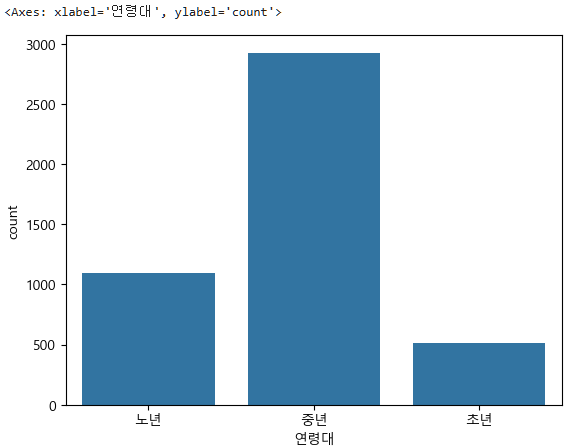
2.3.2. 월급 변수 검토 및 전처리
월급 전처리 부분은 2.1.2.를 참고하자.
2.3.3. 연령대와 월급의 관계 분석
연령대에 따른 월급 차이: 어떤 연령대의 월급이 가장 많을지
시각화, 데이터 요약
다변수 문자-숫자이므로 barplot을 사용한다.
sns.barplot(data=subject_three, x="연령대", y="월급")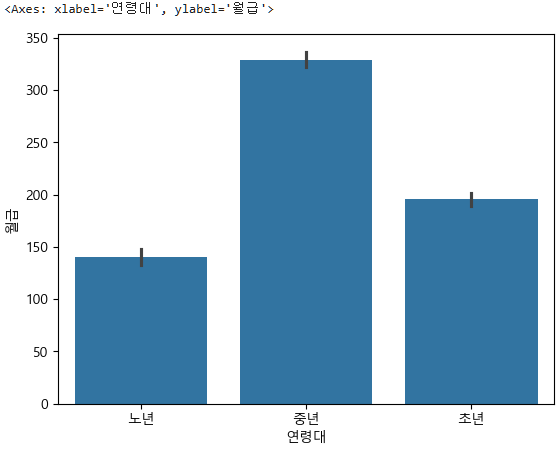
먼저 연령대별 월급의 평균을 구하기 위해 연령대별 그룹화를 하고, 월급의 평균을 구한다.
subject_three_salary_mean=subject_three.groupby("연령대")["월급"].mean().reset_index(name="연령대평균월급")
subject_three_salary_mean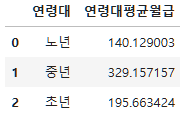
2.3.4. 통계적 가설 검정
나이에 따른 월급 차이: 나이에 따라 월급이 다를지
다변수, x(연령대(범주(문자))), y(월급(연속(숫자))): y, 월급의 정규성 확인 -> 정규면 등분산/이분산, 비정규면 -> 2집단, 3집단 이상
가설:
- 귀무가설: 연령대별 월급의 차이가 없다.
- 대립가설: 연령대별 월급의 차이가 있다.
이제 이렇게 분석을 완료했으니 이제 CDA, 통계적 가설 검정을 해야한다.
stats.normaltest(subject_three["월급"])NormaltestResult(statistic=1657.4427188351524, pvalue=0.0)pvalue 0.0 < 0.05 유의수준 이므로 비정규형이다.
그리고 노년, 중년, 초년의 3집단이므로 Kruskal Wallis Test로 진행한다.
old=subject_three[subject_three["연령대"]=="노년"]
middle_aged=subject_three[subject_three["연령대"]=="중년"]
young=subject_three[subject_three["연령대"]=="초년"]
old.shape, middle_aged.shape, young.shape((1093, 9), (2927, 9), (514, 9))stats.kruskal(old["월급"], middle_aged["월급"], young["월급"])KruskalResult(statistic=1154.8545662293197, pvalue=1.6846793127448966e-251)pvalue 0.00...168 < 0.05 유의수준 으로 대립가설이 참이고, 연령대별 월급의 차이가 있다.
이렇게하여 분석결과는 Kruskal Wallis Test를 통해 연령대에 따른 월급의 차이가 있다(통계량: 1154.8, pvalue < 0.05)가 나온다.
분석결과를 한장으로 요약하려면, 시각화한 사진, 연령대별 월급 평균 비교표 사진으로 중년층이 가장 많이 받았다는 점, Kruskal Wallis 검정 결과 사진을 통해 연령대에 따른 월급의 차이가 있다는 것을 보여주면 된다.
2.4. 연령대 및 성별 월급 차이
⭐ 성별 월급 차이가 연령대별로 다를지
DDA: 분석에 활용할 변수(연령대, 성별, 월급) 전처리
- 생략
EDA: 변수 간 관게 분석
- 데이터 요약표: 연령대 및 성별 월급평균표 만들기
- 그래프 만들기: x(연령대, 성별(범주(문자))), y(월급(연속(숫자))) -> barplot
CDA: 검증
- x(연령대, 성별(범주(문자))), y(월급(연속(숫자))): y, 월급은 비정규 -> 3집단 이상 Kruskal Wallis Test
2.4.1. 변수 검토 및 전처리
연령대(2.3.1)와 성별(2.1.1), 월급(2.1.2)은 위에서 이미 진행했으니 전처리 부분을 참조하면 된다.
subject_four=pd.read_csv("./data/pandas/project/subject_three.csv")
subject_four.head()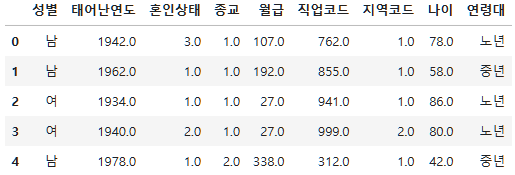
2.4.2. 연령대 및 성별과 월급 분석
연령대 및 성별에 따른 월급 차이: 성별 월급 차이가 연령대별로 다를지
시각화, 데이터 요약
전처리에 대한 부분은 이미 진행했으니 시각화를 해주면 되는데,
이는 x문자, y숫자이므로 barplot을 사용한다.
sns.barplot(data=subject_four, x="연령대", y="월급", hue="성별", order=["초년","중년","노년"])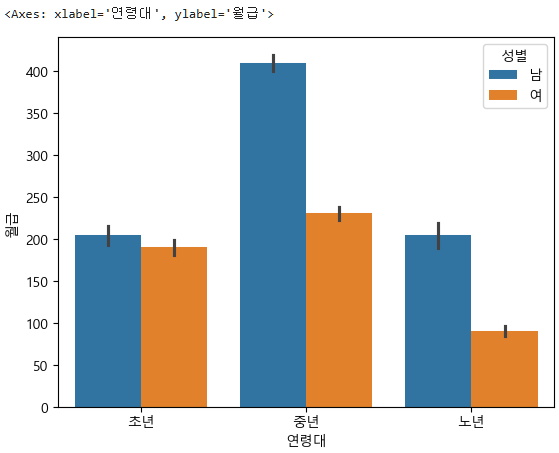
이제 데이터 요약표(비교표)를 만들자.
subject_four_salary_mean=subject_four.groupby(["연령대", "성별"])["월급"].mean().reset_index(name="월급평균")
subject_four_salary_mean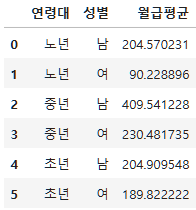
2.4.3. 통계적 가설 검정
성별 월급 차이가 연령대별로 다를지
다변수, x(성별, 연령대(범주(문자))), y(월급(연속(숫자))): y, 월급은 비정규 -> 3집단 이상 Kruskal Wallis Test
가설:
- 귀무가설: 성별 월급 차이는 연령대별로 다르지 않다.
- 대립가설: 성별 월급 차이가 연령대별로 다르다.
m=subject_four[subject_four["성별"]=="남"]
f=subject_four[subject_four["성별"]=="여"]
old=subject_four[subject_four["연령대"]=="노년"]
middle_aged=subject_four[subject_four["연령대"]=="중년"]
young=subject_four[subject_four["연령대"]=="초년"]
stats.kruskal(m["월급"], f["월급"], old["월급"], middle_aged["월급"], young["월급"])KruskalResult(statistic=2104.3728897890423, pvalue=0.0)pvalue 0.0 < 0.05 유의수준으로 대립가설이 참, 성별 월급차이는 연령대별로 차이가 있다.
이렇게하여 분석결과는 Kruskal Wallis Test를 통해 성별 월급차이는 연령대별로 차이가 있다(통계량: 2104.3, pvalue < 0.05)가 나온다.
분석결과를 한장으로 요약하려면, 시각화한 사진, 연령대별 성별 평균 비교표 사진, Kruskal Wallis 검정 결과 사진을 통해 연령대별 성별 월급의 차이가 있다는 것을 보여주면 된다.
⭐ 정리
이렇게 4개의 주제에 대해 다뤄봤는데, 추가로 4개의 주제로 새로운 글에서 다루겠다.
