
이번에는 이미지와 label을 다 가지고 있는 데이터셋을 가져다가 쓰는 방법을 알아보자.
1. Roboflow Dataset
Roboflow의 Public Datasets 중, Aquarium Dataset을 사용해보자.
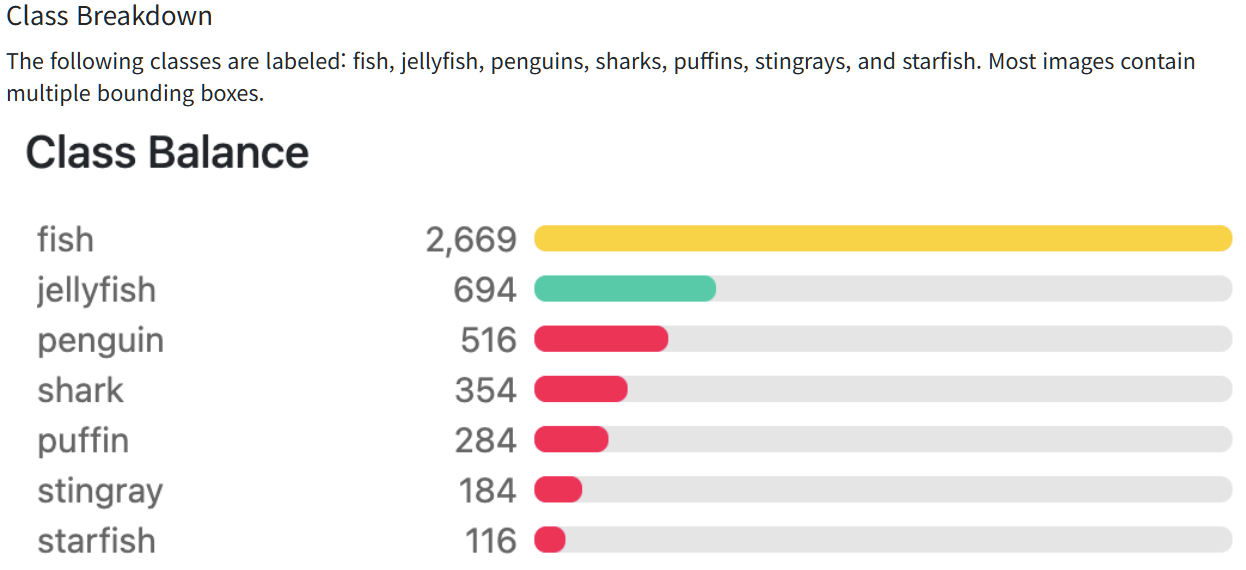
클래스 -> yaml 파일 names에 넣어주기여기서 이제 데이터셋을 다운 받아야하는데, 638 images를 클릭하면 회원가입을 우선 해야한다.
회원가입을 완료한 후
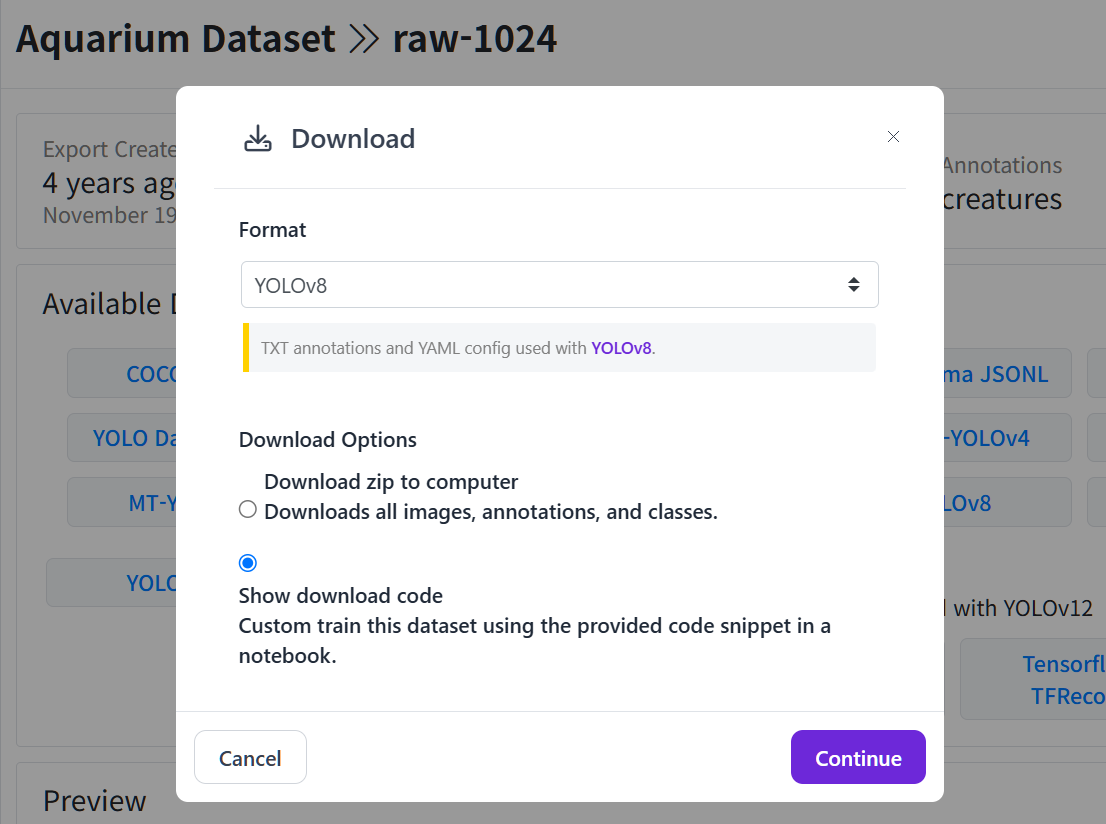
YOLOv8 -> continue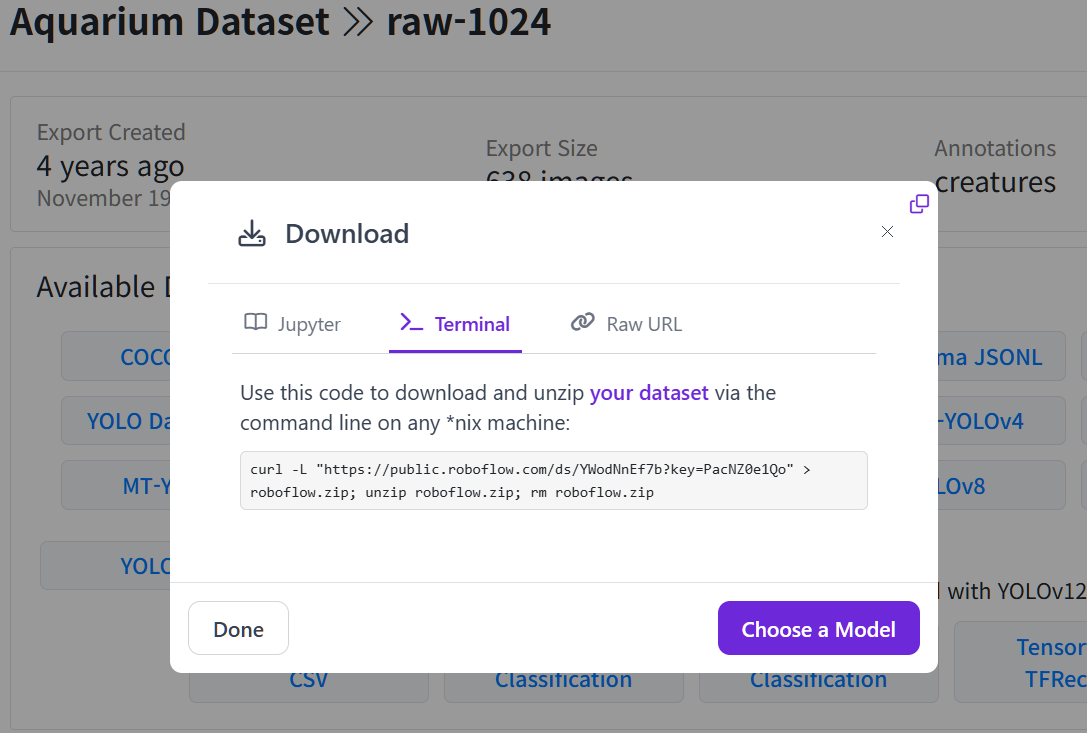
Terminal -> 코드 복사이제 이를 사용하면 된다.
1.1. 데이터 로드
!curl -L "https://public.roboflow.com/ds/YWodNnEf7b?key=PacNZ0e1Qo" > roboflow.zip; unzip roboflow.zip; rm roboflow.zip % Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 903 100 903 0 0 2424 0 --:--:-- --:--:-- --:--:-- 2427
100 66.9M 100 66.9M 0 0 35.7M 0 0:00:01 0:00:01 --:--:-- 68.6M
Archive: roboflow.zip
extracting: README.dataset.txt
extracting: README.roboflow.txt
extracting: data.yaml
creating: test/
creating: test/images/
extracting: test/images/IMG_2289_jpeg_jpg.rf.fe2a7a149e7b11f2313f5a7b30386e85.jpg
...
...
extracting: valid/labels/IMG_8595_MOV-1_jpg.rf.7ec06740adf2a710a14c479f9bd8db5b.txt
extracting: valid/labels/IMG_8599_MOV-1_jpg.rf.8b8f5d9d4eacd671546a3025e6f52a0e.txt
1.2. Custom yaml 파일 생성
import yaml
# 참고로 이 딕셔너리니까 key값 다르게 쓰면 안됨
data_cf={
'train': '/content/train',
'val': '/content/valid',
'test': '/content/test',
'names': ['fish', 'jellyfish', 'penguin', 'puffin', 'shark', 'starfish', 'stingray'],
'nc': 7
}
with open('/content/Aquarium_data.yaml', 'w') as f:
yaml.dump(data_cf, f)
with open('/content/Aquarium_data.yaml') as f:
aquarium_yaml = yaml.safe_load(f)
display(aquarium_yaml){'names': ['fish',
'jellyfish',
'penguin',
'puffin',
'shark',
'starfish',
'stingray'],
'nc': 7,
'test': '/content/test',
'train': '/content/train',
'val': '/content/valid'}
1.3. YOLOv8 Setup
!pip install ultralyticsfrom ultralytics import YOLO
import cv2
from google.colab.patches import cv2_imshow
model=YOLO('yolov8n.pt')이제 이 YOLOv8 모델을 가져왔다.
이 YOLO의 아키텍처를 가지고 생성한 Aquarium_data yaml파일로 파인튜닝하자.
1.4. 모델 아키텍처를 이용해 Custom Dataset으로 학습
저번 글에서는 이미지를 20개 정도만 진행했으나 이번에는 640개 정도의 이미지기 때문에 시간이 아주 많이 늘어난다.
PC가 좋지 않다면 반드시 Colab을 사용하자.. 7분에 1번 정도 돌아간다..😭
# epochs 100번 -> 성능 잘나옴 (30min 정도 소요)
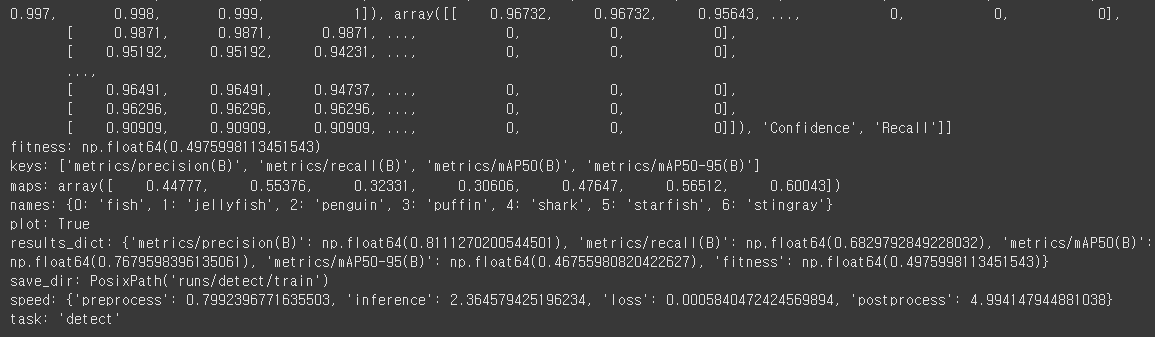
model.train(data='/content/Aquarium_data.yaml', epochs=30, batch=16, imgsz=640) 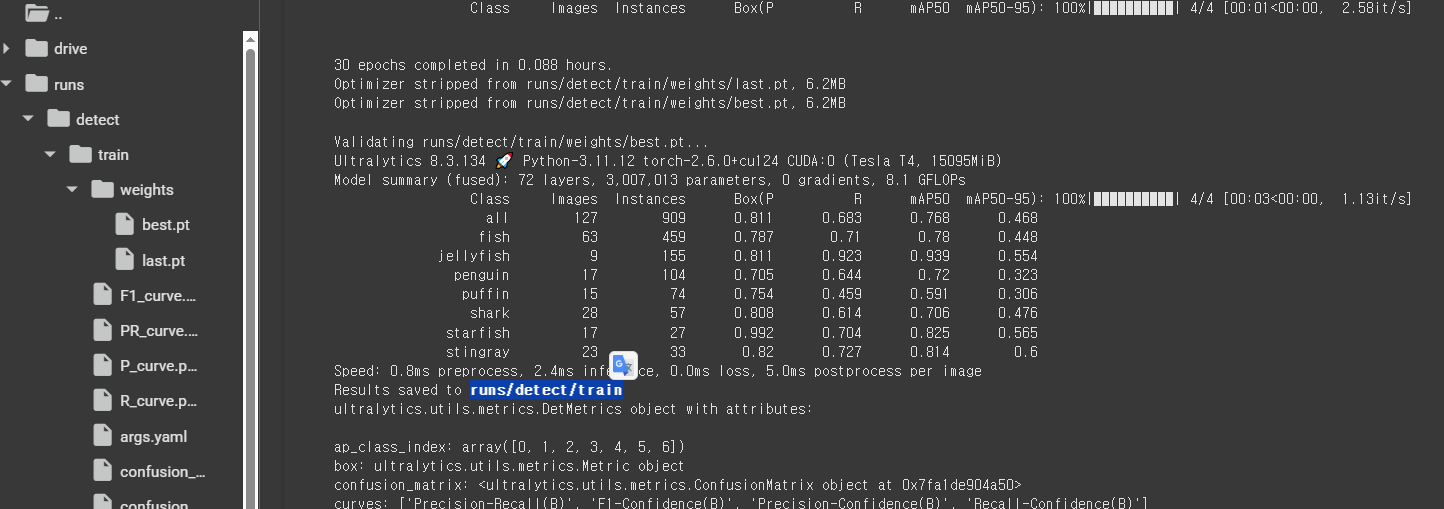
1.5. 학습 결과 확인
그래프 파일을 확인해보자.
result_img=cv2.imread('/content/runs/detect/train/results.png')
result_img_resize=cv2.resize(result_img, None, fx=0.5, fy=0.5, interpolation=cv2.INTER_AREA)
cv2_imshow(result_img_resize)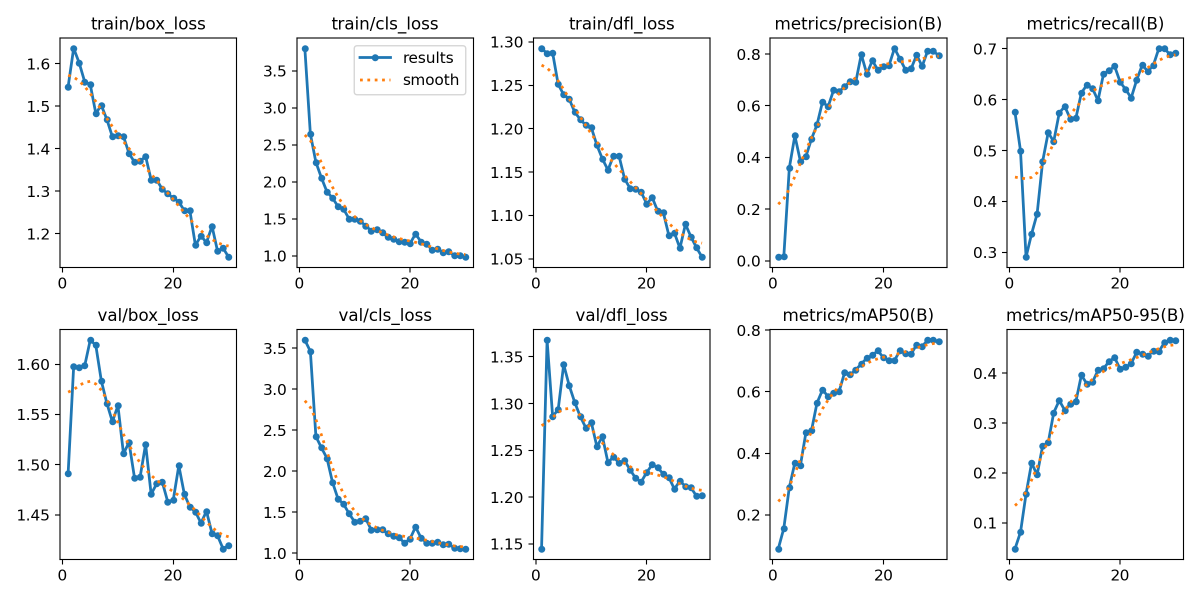
30번 정도 돌렸는데 꽤 잘 맞췄다.
1.6. 모델 검출
그렇다면 test 폴더의 이미지 하나를 골라서 predict해보면 어떻게 분류하는지 확인해보자.
# 전체를 보려면 /content/test/images/ 로
results=model.predict(source='/content/test/images/IMG_2289_jpeg_jpg.rf.fe2a7a149e7b11f2313f5a7b30386e85.jpg',
save=True)image 1/1 /content/test/images/IMG_2289_jpeg_jpg.rf.fe2a7a149e7b11f2313f5a7b30386e85.jpg: 640x480 1 puffin, 45.2ms
Speed: 2.7ms preprocess, 45.2ms inference, 10.1ms postprocess per image at shape (1, 3, 640, 480)
Results saved to runs/detect/train2이제 예측한 이미지를 확인해보면
img=cv2.imread('/content/runs/detect/train2/IMG_2289_jpeg_jpg.rf.fe2a7a149e7b11f2313f5a7b30386e85.jpg')
img_resize=cv2.resize(img, None, fx=0.5, fy=0.5, interpolation=cv2.INTER_AREA)
cv2_imshow(img_resize)
1.7. 학습된 모델 가중치
aquarium_model=YOLO('/content/runs/detect/train/weights/best.pt')
# 클래스 수
print(type(aquarium_model.names), len(aquarium_model.names))
# 클래스
print(aquarium_model.names)<class 'dict'> 7
{0: 'fish', 1: 'jellyfish', 2: 'penguin', 3: 'puffin', 4: 'shark', 5: 'starfish', 6: 'stingray'}1.8. ⭐ 동영상 예측
이제 학습된 모델 가중치(aquarium_model)를 이용해서 이번에는 동영상도 분류해내는지 확인해보는데, 상어 동영상을 하나를 가져와서 확인해보자.
results=aquarium_model.predict(source='/content/drive/MyDrive/Colab Notebooks/YOLOv8/image/shark.mp4',
save=True)...
...
video 1/1 (frame 147/148) /content/drive/MyDrive/Colab Notebooks/YOLOv8/image/shark.mp4: 384x640 1 fish, 1 shark, 7.0ms
video 1/1 (frame 148/148) /content/drive/MyDrive/Colab Notebooks/YOLOv8/image/shark.mp4: 384x640 1 fish, 1 shark, 6.8ms
Speed: 2.3ms preprocess, 13.7ms inference, 2.5ms postprocess per image at shape (1, 3, 384, 640)
Results saved to runs/detect/predict이제 출력을 해야하는데, 이게 코랩이 웹브라우저이기 때문에 출력하는 방법이 조금 다르다.
저장 된 파일을 보면 avi파일이다.
그냥 클릭하면 다운로드를 받기때문에 코랩에서 보려면 작업이 필요하다.
따라서 avi 파일을 mp4로 변환 후 영상을 보여줘야한다.
이때 리눅스 명령어가 들어가니까 경로만 잘 확인해서 따라 쳐서 확인하자.
import io
from IPython.display import HTML
from base64 import b64encode
import os
import locale
path_video=os.path.join('/content/runs/detect/predict', 'shark.avi') # 경로와 파일명 join
# 아래는 리눅스 명령어 (앞에 % 달아주기)
# 해당 폴더로 이동한 후
%cd /content/runs/detect/predict
# encoding
locale.getpreferredencoding=lambda : "UTF-8"
# .avi -> .mp4 변환
!ffmpeg -y -loglevel panic -i "shark.avi" "shark.mp4"
# 다시 빠져나가기 (/content/runs 로)
%cd ../../..//content/runs/detect/predict
/content이제 코랩에서 영상을 보여줄 준비를 해야한다.
def show_video(file_name, width=640):
mp4=open(file_name, 'rb').read() # read binary
data_url="data:video/mp4;base64," + b64encode(mp4).decode() # 데이터비디오/base64형식, 바이트 데이터를 base64형식
return HTML("""
<video width={0} controls>
<source src="{1}" type="video/mp4">
</video>
""".format(width, data_url))
path_output=os.path.join('/content/runs/detect/predict', 'shark.mp4')
show_video(path_output, width=640)
이렇게 비전쪽은 마무리 짓겠다.
