
1. 객체 인식
기본적인 이미지 비전 관련 문법들은 이제 어느 정도 익혔고, 비전의 마지막 단계인 객체 인식(Object Detection)을 배워보려고 한다.
사실 순서상으로는 CNN -> 객체 인식 -> GAN이 자연스럽지만, GAN을 먼저 배우고 객체 인식을 마지막에 배우게 됐다.
지금까지는 이미지를 보고 그게 개인지 고양이인지 분류하거나, 아니면 GAN으로 새로운 이미지를 생성하는 작업을 했었다.
그런데 객체 인식은 조금 다르다.
예를 들어 CNN에서는 고양이 한 마리 사진을 보고 "고양이" 라고 분류했다면,
객체 인식은 한 장의 이미지 안에 고양이, 강아지, 오리가 동시에 있다면
그 각각을 하나의 객체로 인식해서, 박스를 그리고 분류하는 것이다.
즉, 이미지 안에 있는 여러 물체들을 구분해서
"무엇이 있는지" + "어디에 있는지" 까지 찾아내는 게 객체 인식이다.
이때 이미지에서 물체가 있을 법한 영역에 박스를 그리는 걸
Region Proposal, 또는 Bounding Box라고 부른다.
예전에는 CNN 커널처럼 윈도우(e.g., 3x3)를 이미지 위에서 조금씩 움직이며
물체가 있는지 확인하는 sliding window 방식을 사용했다.

출처: https://developer-lionhong.tistory.com/35
하지만 이 방식은 물체가 윈도우 안에 전부 안 들어오면 인식이 어렵고,
윈도우 크기를 바꿔가며 계속 검사해야 해서 계산량이 엄청나다는 문제가 있었다.
그래서 나온 방법이 Selective Search인데,
색, 텍스처, 크기 등을 기준으로 이미지에서 객체일 가능성이 높은 영역만 뽑는 방식이다.
조각조각 잘라서 비슷한 것들을 합치며 후보 영역을 만든다.

출처: https://stydy-sturdy.tistory.com/28?category=1104578
이 방식도 지금은 잘 안 쓰지만, 여기서부터 R-CNN이 시작된다.
1.1. 객체 인식 모델들의 발전
-
R-CNN
후보영역(Region)을 먼저 뽑고 그 영역을 잘라서 CNN에 하나씩 넣고,
회귀(위치 계산) + 분류(SVM)로 결과를 내는 구조다. -
Fast R-CNN
아예 이미지를 통째로 CNN에 넣고 feature map을 먼저 만든 다음
후보영역을 그 feature map 위에서 잘라서 쓰는 구조로 속도가 훨씬 빨라졌다. -
Faster R-CNN
아예 Region Proposal도 CNN 안에서 자동으로 뽑아서 완전한 end-to-end 구조로 성능도 좋고, 속도도 개선되었다.
1.2. YOLO
그런데 위 방식들은 대부분 두 단계를 거친다.
이를 Two-Stage라고 하는데, 회귀와 분류를 둘 다 진행해야하는데, 동시에 진행이 안됐다.
그래서 실시간으로 쓰기엔 느릴 수 있었다.
그래서 나온 게 One-Stage이며, 그 중 가장 BEST의 성능을 뽑아내는게 현재 YOLO(You Only Look Once).
YOLO는 Two-Stage처럼 먼저 영역을 뽑고 다시 분류하는 과정을 생략한다.
이미지를 한 번에 처리하면서 각 그리드 셀마다 객체의 유무, 위치, 클래스까지 동시에 예측한다.
이 구조 덕분에 속도는 훨씬 빠르면서도 정확도도 높게 나올 수 있게 되었다.
즉 YOLO는 말 그대로 이미지를 딱 한 번 보고 박스도 찾고, 클래스도 분류하는 방식이다.
속도가 빠르고, 성능도 정말 좋아서 가장 많이 쓰이는 객체 인식 모델 중 하나다.

출처: https://velog.io/@y6hyuk/Object-Detection-객체-탐지-이란
이와 같이 박스를 그리는데, 이를 bounding box 라 하며 물체의 종류를 분류하는 classification과 위치를 추정하는 localization이 필요하다.
먼저 classification은 이렇게 박스를 그려서 라벨을 car라고 할때, 다른 클래스들로 보행자, 오토바이, 배경이 있다고 가정하자.
1. 보행자
2. 자동차
3. 오토바이
4. 배경
이렇게 나눈 뒤 0과 1로 원핫 인코딩과 같이 표현한다.
localization은 박스를 기준으로 박스의 중심점을 하나 찍고, bx, by, bh, bw를 구한다.
bx와 by는 이미지 전체를 기준으로 x와 y좌표를 뜻하며,
bh와 bw는 박스를 기준으로 height와 width를 뜻한다.
1.2.1. YOLO 구조
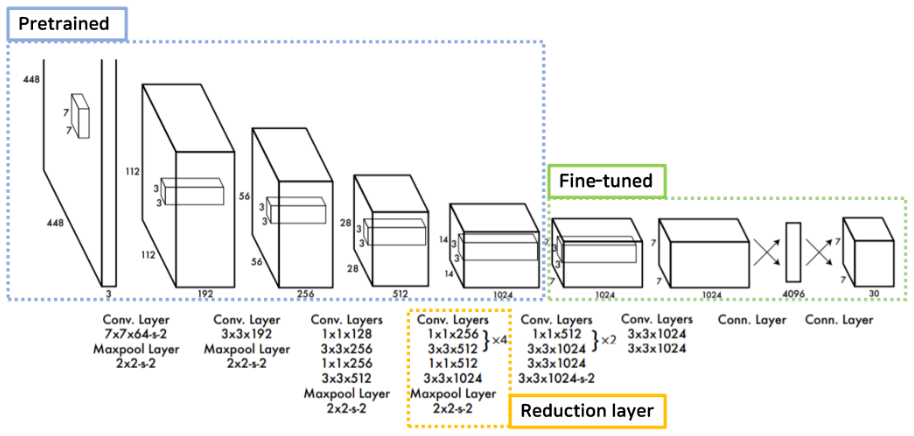
출처: https://dotiromoook.tistory.com/24
24개의 conv 층과 2개의 완전연결층으로 구성되어 있다.
Darknet network라고 부르며 ImageNet dataset으로 pre-trained된 network를 사용한다.
그럼 이제 이미지 데이터가 있다면, 정답 데이터가 있어야 한다.
즉 목표인 target, y 레이블을 정의 해야하는데,
앞선 classification과 localization이 여기서 사용된다.

출처: https://wooono.tistory.com/m/236
이 pc는 객체인지, 배경인지를 나타내며, 0일 경우 다른 내용들은 채워지지 않는다.
그리고 객체인 경우는 각 값들이 들어가게 된다.
그래서 실제로 어떤 식으로 이들이 들어가냐?
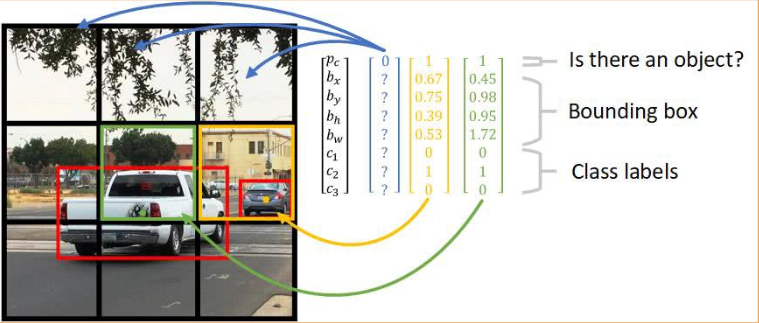
출처: https://dot-learning.tistory.com/36
이와 같이 격자(grid)로 나눠서 객체가 있는지를 찾아서 없는 배경이라면 pc를 0으로 채워서 나머지를 버리고,
객체가 있다면 앞서 말한 것과 같이 bounding box로 중앙을 찾은 다음 위치를 구한다음, 클래스 라벨을 적어준다.
그렇다면 이미지가 겹치는 경우는 어떻게 처리할까?
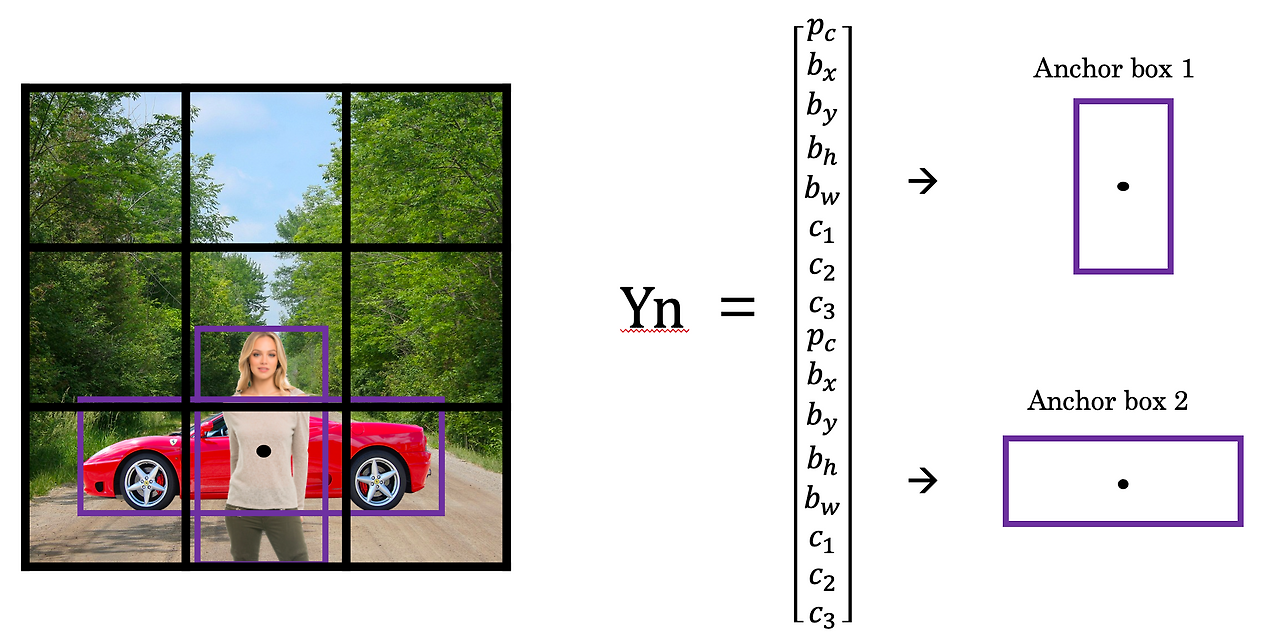
출처: https://wikidocs.net/142645
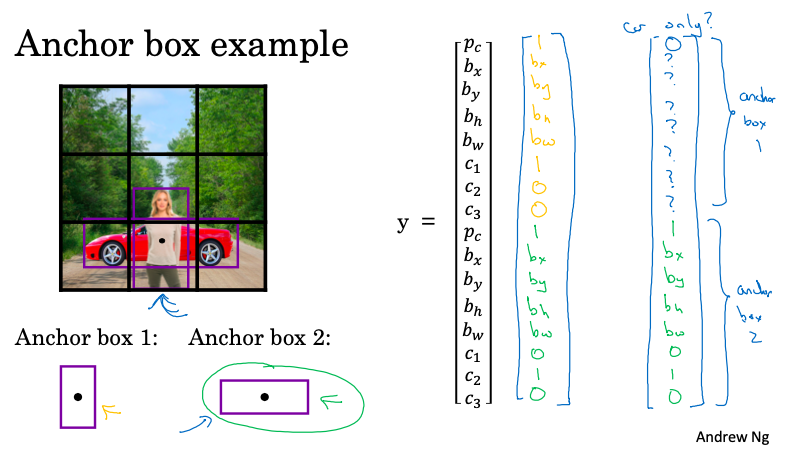
이는 엥커 박스(Anchor Box)라는 개념이 들어가는데, 보행자의 중심점과 차량의 중심점이 거의 같은 위치에 있고, 둘 다 동일한 그리드 셀에 속해 있다.
그럴때, 엥커 박스는 탐지하려는 모양을 미리 정의하고, 객체가 탐지되었을 때 어떤 엥커 박스와 유사한지 비교해 vector 값을 할당하는 방식이다.
그래서 Yn을 보면 위에서부터 pc~c3까지가 보행자, 다시 pc~c3가 차량으로 나누어 볼 수 있다.
이렇게 2가지 엥커 박스를 사용하면 각 그리드 셀은 2가지 객체에 대한 target label y 값을 가질 수 있으며 2개의 vector를 이어 붙인 형태가 된다.
그리고 test 과정에서 각 그리드 셀은 객체를 탐지하며, 탐지한 객체의 Bounding Box가 엥커 박스 1과 유사한지 엥커 박스2와 유사한지 IoU를 통해 계산한다.
이 IoU는 Intersection Over Union으로, 객체 검출의 정확도를 평가하는 지표다.
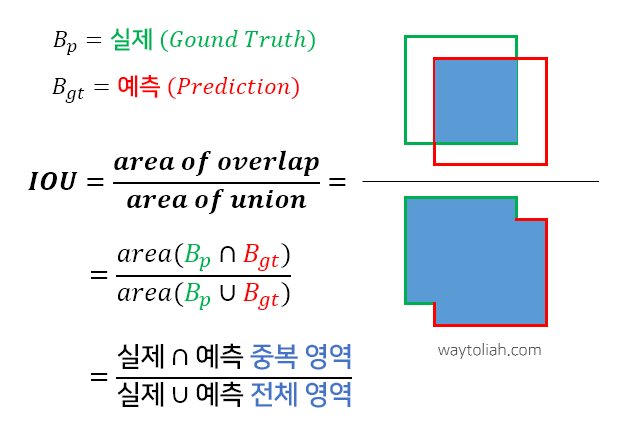
IOU (Intersection Over Union) = area of overlap / area of union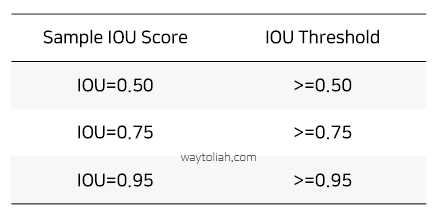
IOU 표기법 및 threshold 예시 (메트릭에 따라 일반적으로 50%, 75%, 95%로 설정)출처: https://www.waytoliah.com/1491
0~1 사이의 값을 가지며, 실제 객체 위치인 Ground Truth와 예측한 Prediction의 두 box가 중복되는 영역의 크기를 통해 평가하는 방식이다.
겹치는 영역이 넓을 수록 잘 예측한 것으로 평가한다.
어찌 됐든 이렇게 IoU를 계산 후, 높은 엥커박스 vector 자리에 값을 할당한다.
출처: https://gnoej671.tistory.com/39
따라서 각 그리드 셀이 무엇을 인식하느냐에 따라 Target Label y 값이 할당된다.
이 YOLO는 사전학습 + 전이학습 모델이다.
사전학습은 데이터셋을 학습한것으로 ImageNet, COCO 등이 있으며,
전이학습은 데이터셋 + 가중치까지 있는 것을 말한다.
그래서 YOLO는 결국에 가져다 쓰면 되는데, 제일 중요한 것은 내 Data에서 라벨링을 잘 해야한다.
YOLO는 단순히 물체를 찾는 detect 뿐만 아니라, 분할하는 Segment, 자세를 추정하는 pose 같은 다양한 기능을 지원하며
이번에는 YOLO의 다양한 버전 중 가장 경량화된 모델인 YOLOv8-nano를 사용해서
이 세 가지 기능을 직접 실습해볼 예정이다.
그리고 다음 글에서는 직접 내 데이터로 테스트 해볼 예정이다.
2. YOLO ver8
- YOLO: ultralytics에서 개발
- ultraytics github 참조 : https://github.com/ultralytics/ultralytics
- 버전 8 공식문서 : https://docs.ultralytics.com/ko/models/yolov8/#yolov8-usage-examples
객체를 Classify(분류), Detect(검출), Segmentation(분할), Tracking(추적), Pose(포즈) 를 수행할 수 있다.
이 중 detect, segment, pose 정도만 진행해보자.
2.1. Detect
# yolo ver 8, nano를 사용 -> 모델의 구조와 가중치를 다 불러옴 -> 경로에 yolo8n.pt 파일이 자동으로 생성됨
model=YOLO('yolov8n.pt')CNN에서 진행할때는 다 학습시키고 model.predict를 진행했었는데,
이 YOLO는 위 과정들이 다 진행되어 있고 predict만 진행하면 된다.
단 일단은 이때 이미지에 라벨링 작업이 필요한데, 지금 안해놨기 때문에 우선 ultralytics에서 제공하는 이미지로 테스트해보자.
# 모델 예측 -> 결과값 저장 -> runs라는 폴더 자동 생성되며 저장됨
results=model.predict(source="https://ultralytics.com/images/bus.jpg", save=True)Found https://ultralytics.com/images/bus.jpg locally at bus.jpg
image 1/1 d:\ProgramLangs\pythonLang\joohwan\workspace\DeepLearning\cnn\bus.jpg: 640x480 4 persons, 1 bus, 1 stop sign, 198.4ms
Speed: 4.0ms preprocess, 198.4ms inference, 1.8ms postprocess per image at shape (1, 3, 640, 480)
Results saved to runs\detect\predict이제 이를 찍어봐야하니까 이를 위해서 OpenCV를 배웠던 것이다.
img=cv2.imread('runs/detect/predict/bus.jpg')
print(f"원본 이미지 크기:{img.shape}") # height 1000, width 810
fix_width=400
height, width=img.shape[:2] # 1000, 810
ratio=fix_width/width # 0.49 너비 비율
demension=(fix_width, int(height*ratio)) # 최종길이 400 533 -> demension=(400, 533) 이렇게 지정해도 됨
img_resize=cv2.resize(img, demension, interpolation=cv2.INTER_AREA) # 사이즈 조절: 보간법 축소
img=cv2.cvtColor(img_resize, cv2.COLOR_BGR2RGB)
plt.imshow(img)
plt.axis('off')
plt.show()원본 이미지 크기:(1080, 810, 3)
2.2. Segmentation
# yolo ver 8, nano - segment 사용
model=YOLO('yolov8n-seg.pt')
# 모델 예측 -> 결과값 저장 -> runs라는 폴더 자동 생성되며 저장됨
results=model.predict(source="bus.jpg", save=True)Downloading https://github.com/ultralytics/assets/releases/download/v8.3.0/yolov8n-seg.pt to 'yolov8n-seg.pt'...
100%|██████████| 6.74M/6.74M [00:00<00:00, 20.8MB/s]
image 1/1 d:\ProgramLangs\pythonLang\joohwan\workspace\DeepLearning\cnn\bus.jpg: 640x480 4 persons, 1 bus, 1 skateboard, 210.8ms
Speed: 12.5ms preprocess, 210.8ms inference, 31.0ms postprocess per image at shape (1, 3, 640, 480)
Results saved to runs\segment\predictimg=cv2.imread('runs/segment/predict/bus.jpg')
img_resize=cv2.resize(img,(400,533), interpolation=cv2.INTER_AREA)
img=cv2.cvtColor(img_resize, cv2.COLOR_BGR2RGB)
plt.imshow(img)
plt.axis('off')
plt.show()
2.3. Pose
model=YOLO('yolov8n-pose.pt')
results=model.predict(source='bus.jpg', save=True)Downloading https://github.com/ultralytics/assets/releases/download/v8.3.0/yolov8n-pose.pt to 'yolov8n-pose.pt'...
100%|██████████| 6.52M/6.52M [00:00<00:00, 29.3MB/s]
image 1/1 d:\ProgramLangs\pythonLang\joohwan\workspace\DeepLearning\cnn\bus.jpg: 640x480 4 persons, 154.5ms
Speed: 6.0ms preprocess, 154.5ms inference, 2.5ms postprocess per image at shape (1, 3, 640, 480)
Results saved to runs\pose\predictimg=cv2.imread('runs/pose/predict/bus.jpg')
# 이렇게도 가능
img_resize=cv2.resize(img, None, fx=0.5, fy=0.5, interpolation=cv2.INTER_AREA)
img=cv2.cvtColor(img_resize, cv2.COLOR_BGR2RGB)
plt.imshow(img)
plt.axis('off')
plt.show()
2.4. My Image
model=YOLO('yolov8n.pt')
result=model.predict(source='data/fruit/fruit01.jpg', save=True)image 1/1 d:\ProgramLangs\pythonLang\joohwan\workspace\DeepLearning\cnn\data\fruit\fruit01.jpg: 480x640 2 apples, 4 oranges, 181.9ms
Speed: 6.9ms preprocess, 181.9ms inference, 1.9ms postprocess per image at shape (1, 3, 480, 640)
Results saved to runs\detect\predict2img=cv2.imread('runs/detect/predict2/fruit01.jpg')
img_resize=cv2.resize(img, None, fx=0.5, fy=0.5, interpolation=cv2.INTER_AREA)
img=cv2.cvtColor(img_resize, cv2.COLOR_BGR2RGB)
plt.imshow(img)
plt.axis('off')
plt.show()
내 데이터이기 때문에 잘 안나왔다.
따라서 내 이미지로 진행하려면 이미지를 다 라벨링해서 학습시켜서 예측률을 높여야 한다.
라벨링하는 과정은 따로 글을 남길 에정이다.
또 본격적으로 YOLO를 사용하기 위해서 jupyter에서는 한계가 있기 때문에 이제 colab에서 진행한다.
Colab으로 넘어와서 이전 글에서 jupyter에서 수행했던 부분을 다시 적어보자.
3. Colab - YOLOv8
!pip install ultralyticsColab은 한번 세션이 종료되면 이렇게 반복해서 설치를 해줘야한다.
3.1. Detect
from ultralytics import YOLO
import cv2
# 구글이 OpenCV를 내장시켜놨음
from google.colab.patches import cv2_imshowCreating new Ultralytics Settings v0.0.6 file ✅
View Ultralytics Settings with 'yolo settings' or at '/root/.config/Ultralytics/settings.json'
Update Settings with 'yolo settings key=value', i.e. 'yolo settings runs_dir=path/to/dir'. For help see https://docs.ultralytics.com/quickstart/#ultralytics-settings.코랩에서 굉장히 편한 기능인데, OpenCV를 내장시켜놔서 나중에 활용할때 정말 편하다.
model=YOLO('yolov8n.pt') # 모델 아키텍처 + 가중치 다 불러옴Downloading https://github.com/ultralytics/assets/releases/download/v8.3.0/yolov8n.pt to 'yolov8n.pt'...
100%|██████████| 6.25M/6.25M [00:00<00:00, 161MB/s]result=model.predict('https://ultralytics.com/images/bus.jpg', save=True)Found https://ultralytics.com/images/bus.jpg locally at bus.jpg
image 1/1 /content/bus.jpg: 640x480 4 persons, 1 bus, 1 stop sign, 9.4ms
Speed: 2.8ms preprocess, 9.4ms inference, 1.8ms postprocess per image at shape (1, 3, 640, 480)
Results saved to runs/detect/predict⭐ 그동안 Jupyter에서는 Gray나 RGB 등으로 바꿔줬어야 했는데,
코랩에서는 OpenCV가 내장되어 있어서 그냥 imshow로 찍어주면 된다.
img=cv2.imread('/content/runs/detect/predict/bus.jpg')
img_resize=cv2.resize(img, None, fx=0.5, fy=0.5, interpolation=cv2.INTER_AREA)
cv2_imshow(img_resize)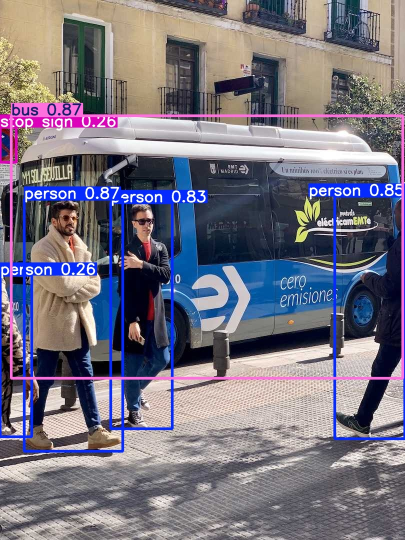
3.2. Segmentation
model=YOLO('yolov8n-seg.pt')
results=model.predict(source='/content/bus.jpg', save=True)Downloading https://github.com/ultralytics/assets/releases/download/v8.3.0/yolov8n-seg.pt to 'yolov8n-seg.pt'...
100%|██████████| 6.74M/6.74M [00:00<00:00, 193MB/s]
image 1/1 /content/bus.jpg: 640x480 4 persons, 1 bus, 1 skateboard, 18.6ms
Speed: 2.9ms preprocess, 18.6ms inference, 108.3ms postprocess per image at shape (1, 3, 640, 480)
Results saved to runs/segment/predictimg=cv2.imread('/content/runs/segment/predict/bus.jpg')
img_resize=cv2.resize(img, None, fx=0.5, fy=0.5, interpolation=cv2.INTER_AREA)
cv2_imshow(img_resize)
3.3. Pose
model=YOLO('yolov8n-pose.pt')
results=model.predict(source='/content/bus.jpg', save=True)Downloading https://github.com/ultralytics/assets/releases/download/v8.3.0/yolov8n-pose.pt to 'yolov8n-pose.pt'...
100%|██████████| 6.52M/6.52M [00:00<00:00, 203MB/s]
image 1/1 /content/bus.jpg: 640x480 4 persons, 19.3ms
Speed: 4.0ms preprocess, 19.3ms inference, 4.6ms postprocess per image at shape (1, 3, 640, 480)
Results saved to runs/pose/predictimg=cv2.imread('/content/runs/pose/predict/bus.jpg')
img_resize=cv2.resize(img, None, fx=0.5, fy=0.5, interpolation=cv2.INTER_AREA)
cv2_imshow(img_resize)
이렇게 실행을 다 했는데, 코랩의 문제는 로컬과 다르게 끄고 나서 다시 실행하면 전부 다 사라진다.
그래서 이를 방지하기 위해 내 드라이브에 저장시켜야한다.
import shutil
import os# 원본 폴더
src='/content/runs/'
# 대상 폴더
dst='/content/drive/MyDrive/Colab Notebooks/YOLOv8/01_Disp'
if os.path.exists(dst):
print('폴더가 존재합니다.')
else:
print('폴더가 존재하지 않습니다.')폴더가 존재합니다.# 폴더 전체 복사 후 붙여넣기
shutil.copytree(src, dst, dirs_exist_ok=True) # True: 덮어쓰기/content/drive/MyDrive/Colab Notebooks/YOLOv8/01_Disp하다보면 학습이 한번에 잘 되는게 아니다.
몇번 해보고, 이것저것 해보고 최종 last를 저장하는게 맞기때문에 다 돌려보고 마지막 최종만 저장하는게 좋은데,
결과가 다 사라지니까 아예 처음부터 내 드라이브에 저장할 수도 있다.
단, 구글 드라이브 용량도 생각하면서 필요할 때 골라서 쓰자.
fruit_model=YOLO('yolov8n.pt')
results=fruit_model.predict(source='/content/drive/MyDrive/Colab Notebooks/YOLOv8/image/fruit01.jpg',
save=True, # 여기까지면 똑같이 runs에 저장되는데,
project='/content/drive/MyDrive/Colab Notebooks/YOLOv8/', # 저장할 폴더 경로
name='02_Fruit_Disp') # 최종 폴더 명image 1/1 /content/drive/MyDrive/Colab Notebooks/YOLOv8/image/fruit01.jpg: 480x640 2 apples, 4 oranges, 45.5ms
Speed: 3.6ms preprocess, 45.5ms inference, 2.0ms postprocess per image at shape (1, 3, 480, 640)
Results saved to /content/drive/MyDrive/Colab Notebooks/YOLOv8/02_Fruit_Disp
이제 저장된거도 한번 확인해보면,
img=cv2.imread('/content/drive/MyDrive/Colab Notebooks/YOLOv8/02_Fruit_Disp/fruit01.jpg')
fix_width=400 # 고정하고자 하는 가로 길이
height,width=img.shape[:2] # 원본 이미지 height, width
ratio=fix_width/width # width 비율 계산
demension=(fix_width, int(height*ratio))
img_resize=cv2.resize(img, demension, interpolation=cv2.INTER_AREA)
#img_resize=cv2.resize(img, None, fx=0.5, fy=0.5, interpolation=cv2.INTER_AREA)
cv2_imshow(img_resize)
