
📌 사용 환경
Python 3.10.2
conda 24.9.0
JupyterLab 4.2.5
사실 지금까지 배운 것들 중에서 사용되는것은 자기상관과 구간 평균법 정도만 사용된다.
계절적 요인이나 트렌드가 있는 것은 비정상 시계열이라고 하는데,
사실은 수학적인 것을 이용해서 이런 요인들을 사용해서 비정상 시계열을 예측했었지만 사실을 잘 못한다.
따라서 이런 추세나 계절적 요인을 가진 비정상 시계열을 정상성을 갖도록 전처리 과정이 필요하다.
이게 앞서 언급했던 차분 이라는 것이다.
이렇지 않으면 예측을 못한다.
당연히 전처리 과정이 굉장히 복잡하다.
1. 정상과 비정상 시계열
그래서 정상과 비정상 시계열의 모습은 다음과 같다.
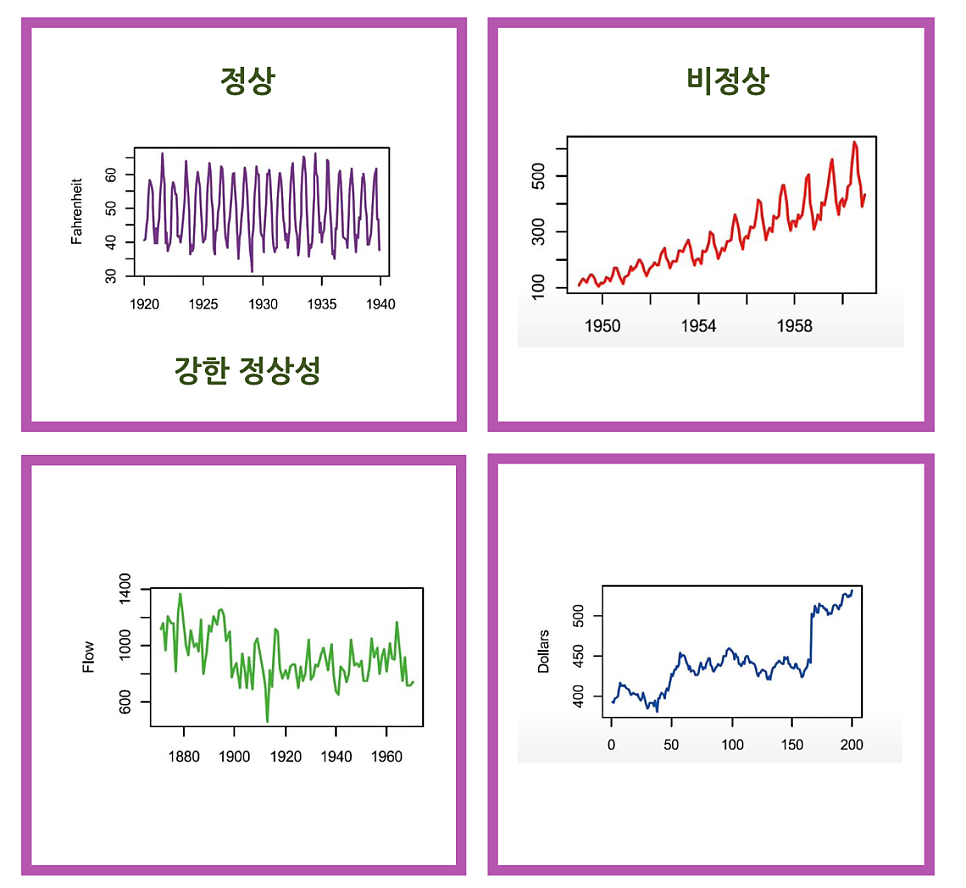
출처: https://m.blog.naver.com/kongda_s2/222567736804?view=img_6
첫번째 그래프만 정상이고 나머지는 비정상 시계열이다.
이렇게 평균과 분산이 일정해야 한다.
2. 자기상관과 부분 자기상관
여기서 자기상관함수와 부분자기상관함수에 대해 알아야하는데,
자기상관은 이미 배웠고, 부분자기상관함수란 특정 시차인 Lag에서 독립적인 자기상관만 측정하는 함수다.
중간에 끼어 있는 다른 시차들의 영향을 제거하고 직접적인 관게만 보는 것으로 ARIMA 모델의 파라미터 결정 및 모델의 적합도 평가에 이용된다.
예를들어 아이스크림의 가격이 다음과 같다고 하자.
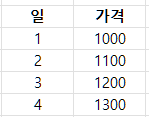
1일 전(Lag=1)의 가격이 현재 가격에 영향을 주는데,
2일 전(Lag=2)의 가격도 영향을 줄까?
ACF(자기상관 함수)의 경우
1일 전: 0.95
2일 전: 0.90
3일 전: 0.85 가 된다.
여기서 문제점은 Lag=2의 상관관계가 높은 이유는 Lag=1을 거쳐서 영향을 받은 거일 수도 있기 때문이다.
그렇다면 PACF(부분 자기상관 함수)의 경우는
1일 전: 0.95
2일 전: 0.05
3일 전: 0.02 가 되는데,
이 결과 PACF에서는 Lag=2 이후의 영향이 거의 없음을 알 수 있다.
즉 바로 전 데이터만 영향을 주고, 2일, 3일 전은 직접적인 영향이 없다는 것을 알 수 있다.
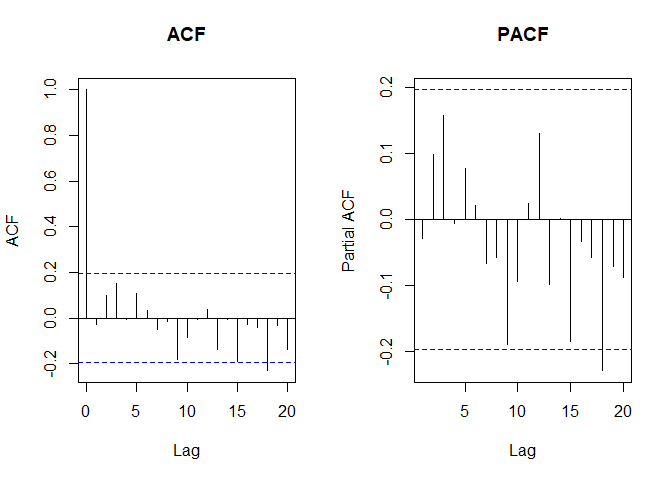
이제 다시 정상과 비정상으로 돌아와서 이 자기상관(ACF)과 부분자기상관(PACF)을 나타내는 도표를 봐도 차이가 있다.
정상일때는 이렇게 일정하지 않고 랜덤하며,
비정상일때는 ACF는 천천히 떨어져
자기 상관이 강함을 알 수 있다.
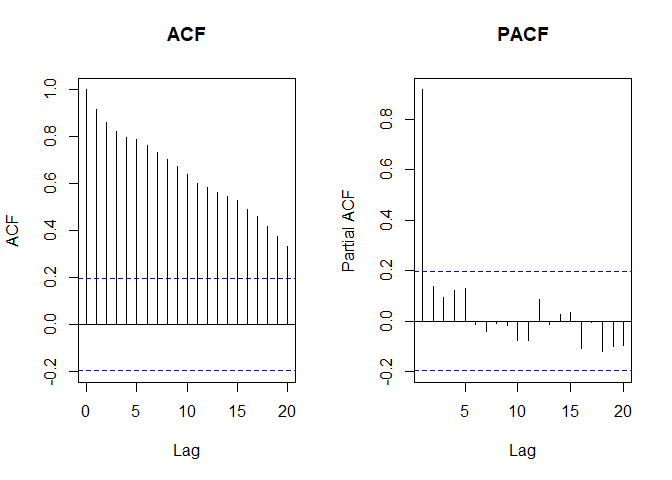
당연하게도 자기 상관은 지수형태를 보인다고 했었는데, 특정 시차(lag)가 늘어날 수록 기준 T에서도 멀어지며 비교하는데, 점차 멀어질 수록 상관관계가 떨어지기 때문에 저런 감소의 형태를 보이는 것이다.
3. ARIMA
ARIMA는 AR과 I(차분), MA에 대해 알아야한다.
AR(Autoregressive)은 선형회귀와 비슷하다.
앞서 말했듯이 회귀모델은 할 수 있지만 독립적이지 않기 떄문에 사용할 수 없었지만 AR을 사용하면 된다.
이 AR의 식은 다음과 같다.
주어진 내용을 수식으로 바꾸면 다음과 같습니다:
- 는 시점 에서의 값
- 는 상수 항
- 는 시점 에 대한 계수들
- 는 과거의 시점 값들
- 는 White Noise, 백색 잡음(오차 항)
는 절편으로 시계열의 평균 수준을 조정하는 역할을 하는데,
평균이 0인 시계열이이면 이 된다.
평균이 있는 경우는, 로 계산한다.
만약 이전 값이 이고 오차항이 라면,
즉 모델이 예측한 값(7)에 오차(2)를 더해 최종 값이 9가 된다.
만약 이면, 예측값 그대로 7이 된다.
MR(Moving Average)는 다음과 같다.
- 는 시점 에서의 값
- 는 상수 항 (절편)
- 는 White Noise, 백색 잡음 (오차 항)
- 는 시점 에 대한 계수들
- 는 과거의 오차 항들
그리고 이들의 합인 ARMA(Autoregressive and Moving Average)는 다음과 같다.
- 는 시점 에서의 값
- 는 상수 항
- 는 AR 부분의 계수들 (자기 회귀 계수)
- 는 과거 값들 (자기 회귀 항),
- 는 백색 잡음 (오차 항)
- 는 MA 부분의 계수들 (이동 평균 계수)
- 는 과거 오차 항들 (이동 평균 항)
자기 회귀(AR): 현재 값이 과거 값들의 선형 조합으로 설명되며,
이동 평균(MA): 현재 값이 과거의 오차 항들의 선형 조합으로 설명된다.
ARMA(p, q) 모델은 시계열 데이터가 자기 회귀와 이동 평균의 특성을 동시에 가질 때 적합하다.
정리하자면, AR, MA, ARMA는 정상성만 가능하며 그래서 차분이란게 필요하고,
(p, d, q)라는 파라미터가 존재하는데, 이는 각각 AR, I, MA를 나타낸다.
그렇다면 차분이란 무엇일까?
차분이란 현재 값에서 이전 값을 빼는 과정을 말한다.
이를 통해 변화량을 보는 것이기 때문에 추세(Trend)를 제거하는 효과가 있다.
즉 차분하면 변화량만 남고 추세는 사라지게 되는 것이다.
앞서 아이스크림의 가격을 다시 보면,
여기서 차분하게 되면 각 행은 100만 남게 된다.
이를 다시 표로 보면 아래와 같다.
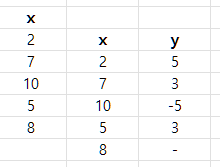
이와 같을때, 1차 차분은 ,
2차 차분은 와 같다.
이 차분은 거의 1차분과 2차분만 사용하며 이 1, 2차분에도 별 차이가 없다.
이제 코드로 보자.
이번에는 캐글에서 제공하는 월별 항공 승객 수에 대한 데이터를 가지고 진행한다.
AirPassengers
https://www.kaggle.com/datasets/rakannimer/air-passengers
월별 항공 승객 수: 1946년 ~ 1960년 매달 비행기 탑승객수에 대한 시게열 데이터
import statsmodels.tsa.api as tsa
from scipy import stats
from statsmodels.tsa.arima_model import ARIMA
from statsmodels.tsa.statespace.sarimax import SARIMAX
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from statsmodels.tsa.stattools import adfuller
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
import itertools4.1. 데이터 구조 파악
air_df=pd.read_csv("data/airPassengers.csv")
air_df| Month | #Passengers | |
|---|---|---|
| 0 | 1949-01 | 112 |
| 1 | 1949-02 | 118 |
| 2 | 1949-03 | 132 |
| 3 | 1949-04 | 129 |
| 4 | 1949-05 | 121 |
| ... | ... | ... |
| 139 | 1960-08 | 606 |
| 140 | 1960-09 | 508 |
| 141 | 1960-10 | 461 |
| 142 | 1960-11 | 390 |
| 143 | 1960-12 | 432 |
144 rows × 2 columns
air_df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 144 entries, 0 to 143
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Month 144 non-null object
1 #Passengers 144 non-null int64
dtypes: int64(1), object(1)
memory usage: 2.4+ KBMonth가 object형이고 컬럼명에 #이 들어가 있으니 변경해주자.
air=air_df.copy()air=air.rename(columns={"Month":"month", "#Passengers":"passengers"})
air| month | passengers | |
|---|---|---|
| 0 | 1949-01 | 112 |
| 1 | 1949-02 | 118 |
| 2 | 1949-03 | 132 |
| 3 | 1949-04 | 129 |
| 4 | 1949-05 | 121 |
| ... | ... | ... |
| 139 | 1960-08 | 606 |
| 140 | 1960-09 | 508 |
| 141 | 1960-10 | 461 |
| 142 | 1960-11 | 390 |
| 143 | 1960-12 | 432 |
144 rows × 2 columns
sns.scatterplot(data=air, x="month", y="passengers")
시계열에서 가장 먼저 해야하는 것은 자료형을 봐야한다.
그러나 month가 object형이었기 때문에 날짜형으로 바꿔줘야한다.
air["month"]=pd.to_datetime(air["month"])
air.info()
air.head()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 144 entries, 0 to 143
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 month 144 non-null datetime64[ns]
1 passengers 144 non-null int64
dtypes: datetime64[ns](1), int64(1)
memory usage: 2.4 KB| month | passengers | |
|---|---|---|
| 0 | 1949-01-01 | 112 |
| 1 | 1949-02-01 | 118 |
| 2 | 1949-03-01 | 132 |
| 3 | 1949-04-01 | 129 |
| 4 | 1949-05-01 | 121 |
그리고 이제 날짜형 자료를 index 값으로 바꿔줘야한다.
지금은 index가 0,1인데 이 month를 index로 바꿔주자.
air=air.set_index("month")
air.head()| passengers | |
|---|---|
| month | |
| 1949-01-01 | 112 |
| 1949-02-01 | 118 |
| 1949-03-01 | 132 |
| 1949-04-01 | 129 |
| 1949-05-01 | 121 |
이제 원래 결측치를 확인해야하는데,
air.isna().sum()passengers 0
dtype: int64지금은 없는데, 이 시계열의 결측치를 대체하는 방법이 여러가지가 있다.
보통 air.ffill()이라는 것을 사용하여 이전(forward) 자료로 채운다.
그리고 air.bfill()을 쓰면 다음(backward) 자료로 채운다.
4.2. 정상성 확인
그 다음에 할 작업이 바로 정상성을 확인하는 것이다.
추세(trend) 확인, 자기상관(ACF, PACF 도표 보기), 검증을 진행하고
비정상성이라면 차분을 진행한다.
4.2.1. 추세확인
먼저 추세를 확인하는데 seaborn의 lineplot을 사용해도 되는데,
판다스에서도 plot이라는 시각화 함수를 제공한다.
그리고 지금은 index와 passenger밖에 없기 때문에 plot을 사용하는 것이 편하다.
#sns.lineplot(data=air, x=air.index, y="passenger")
air.plot()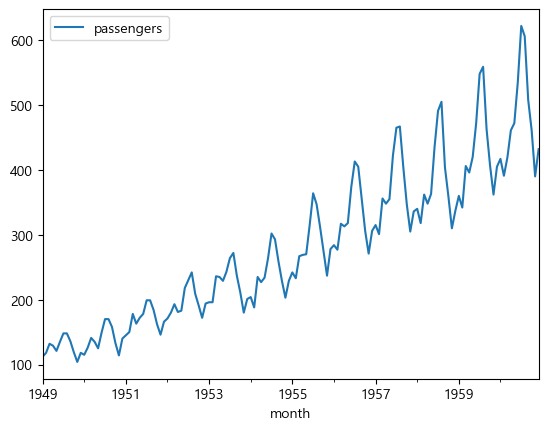
4.2.2. 시계열 분해
시계열에 영향을 주는 일반적인 요인을 시계열에서 분리해서 분석하는 방법
추세(Trend), 순환(Cycle), 계절(Seasonal)
그리고 시계열을 분해해서 볼 수 있는데 이를 제공하는 함수가 tsa.seasonal_decompose 다.
API문서: https://www.statsmodels.org/stable/index.html
이를 이용하면 additive라면 +, multiplicative라면 * 를 사용해서,
시계열=트랜드+계절성+잔차
시계열=트랜드x계절성x잔차
와 같이 사용할 수 있다.
d=tsa.seasonal_decompose(air["passengers"], model="additive")이렇게 시계열 분해해서 d에 담겼다.
이제 시각화해주면,
fig=d.plot()
fig.set_size_inches(8,8)
plt.show()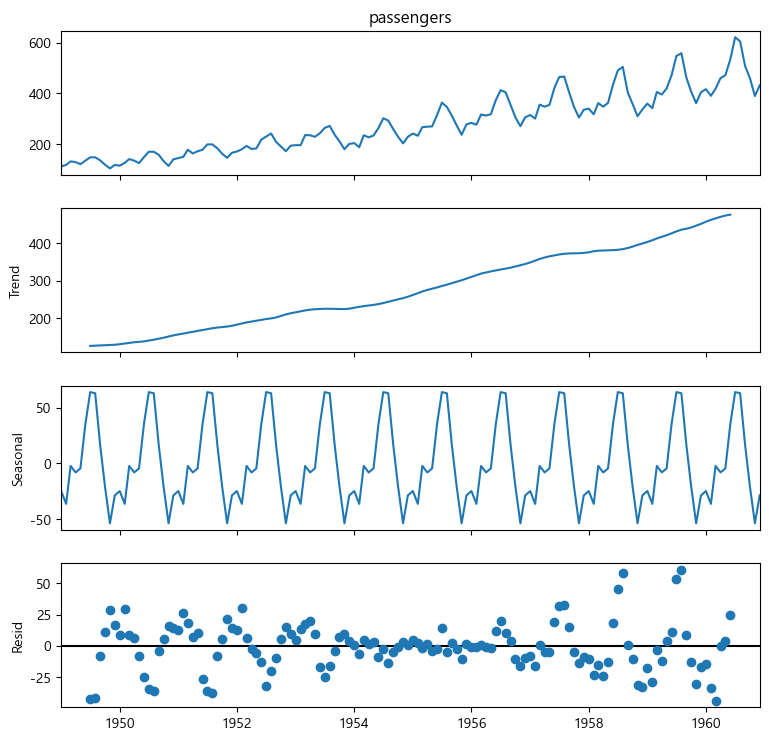
순서대로 원본, Trend, Seaonsal, 잔차다.
Trend: 시간에 따른 데이터의 전반적인 변화 경향
Seasonal: 주기적인 변화
Resid: 트랜드와 계절성 성분을 제외한 나머지 변화
이를 보니 선형회귀로 되지 않겠다는 것을 알 수 있다.
그리고 앞서 additive와 multiplicative의 두 경우에 따라 그래프의 모양이 바뀌는데,
덧셈 모델의 경우는 트렌드에 계절성이 일정하게 더해져서 계절성의 크기는 시간에 관계없이 일정하고, 트랜드가 증가하거나 감소해도 계절성의 크기는 일정한 선형의 모습을 보이고,
곱셈 모델의 경우는 트렌드에 따라 계절성의 크기가 비례적으로 변하며, 트렌드가 증가하면 계절성의 변동폭도 커지고, 트렌드가 감소하면 계절성의 변동폭도 작아지는 곡선의 모습을 보인다.
4.2.3. 훈련 및 테스트 데이터
그러면 이제 Y가 다음인 1961년 1월에 승객이 몇명 타는지인데,
이는 열이 하나기 때문에 값들 안에서 훈련과 테스트 데이터로 나눠서 진행해야한다.
air_train, air_test = train_test_split(air, test_size=0.2, shuffle=False)
air_train.shape, air_test.shape((115, 1), (29, 1))당연히 이는 하나의 열로 진행되기 때문에 X와 Y로 나누지 않았고,
시계열이기 때문에 Random으로 뽑지 않는, 즉 섞지 않는 Shuffle=False가 되는 것이다.
4.2.4. 시각화 - ACF, PCAF 도표 확인
fig, ax=plt.subplots(1,2,figsize=(10,5))
plot_acf(air_train["passengers"], lags=30, ax=ax[0])
plot_pacf(air_train["passengers"], lags=30, ax=ax[1])
plt.show()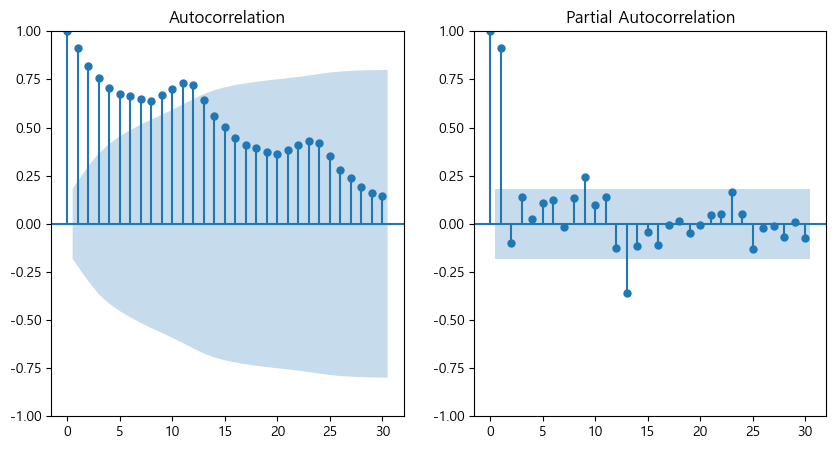
자기 상관이 굉장히 강하기 때문에 비정상이다.
먼저 통계적 검증으로 정상인지 확인해보자.
4.2.5. 통계적 검증
ADF 검정 수행
자기상관 검증은 앞선 리웅박스가 있고,
정상성 검증이 있는데, 정상성 검증은 ADF 검증이다.
귀무: 정상성 없음(비정상적)
대립: 정상성 있음(정상적)
r=adfuller(air_train["passengers"])
r(np.float64(-0.35688921964045317),
np.float64(0.9170517285875924),
13,
101,
{'1%': np.float64(-3.4968181663902103),
'5%': np.float64(-2.8906107514600103),
'10%': np.float64(-2.5822770483285953)},
np.float64(743.4234021319355))
print(f"palue: {r[1]}")palue: 0.91705172858759244.2.6. 차분(Differencing)
비정상성 확인
1차 차분: 직선
2차 차분: 곡선
시계열에서 정상은 평균이 0이고 분산이 일정한 것을 말하고, 트랜드가 없어야 학습을 할 수 있다.
이제 비정상성을 확인했기 때문에 차분을 진행하자.
diff_air_train=air_train.copy()
diff_air_train=air_train["passengers"].diff()
diff_air_train[:5]month
1949-01-01 NaN
1949-02-01 6.0
1949-03-01 14.0
1949-04-01 -3.0
1949-05-01 -8.0
Name: passengers, dtype: float64가장 위인 1949-01-01은 앞선 데이터가 없기 떄문에 Null값으로 나온다.
이 null값을 지워주자.
diff_air_train.dropna(inplace=True)
diff_air_train[:5]month
1949-02-01 6.0
1949-03-01 14.0
1949-04-01 -3.0
1949-05-01 -8.0
1949-06-01 14.0
Name: passengers, dtype: float64이제 차분을 진행한 것과 기존 데이터와 비교해보자.
fig, ax=plt.subplots(2, 1, figsize=(12,8))
ax[0].plot(air_train)
ax[0].legend(["Original - Nonstationary"])
ax[1].plot(diff_air_train, "orange")
ax[1].legend(["Differenced - Stationary"])
plt.show()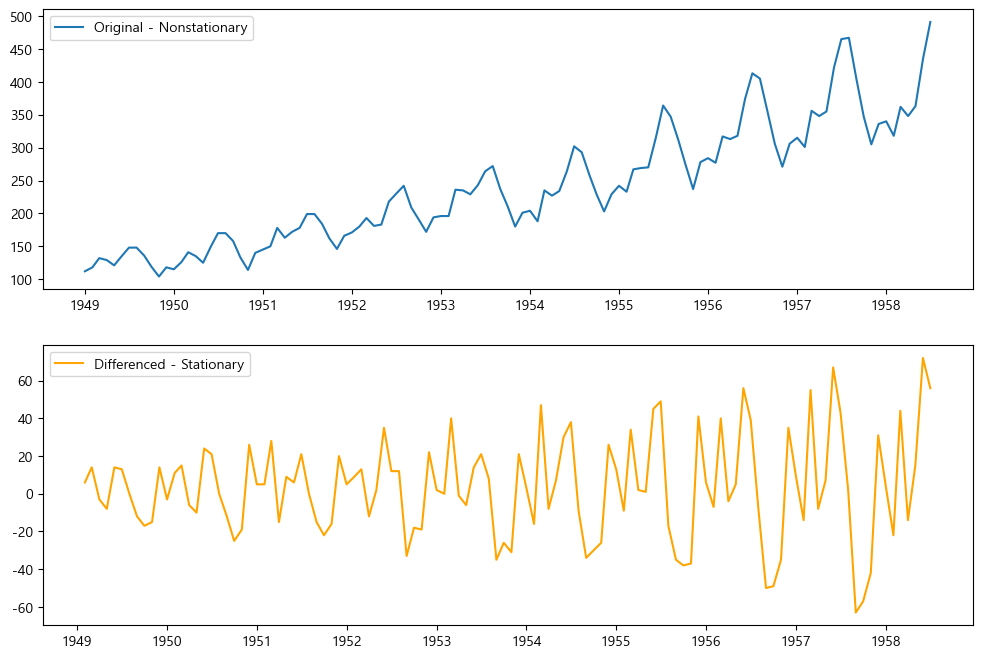
이렇게 계절성은 있지만 0을 기준으로 차분으로 정리가 된 것을 알 수 있다.
자기상관도 없어졌는지 확인하자.
fig, ax=plt.subplots(1,2,figsize=(10,5))
plot_acf(diff_air_train.values, lags=30, ax=ax[0])
plot_pacf(diff_air_train.values, lags=30, ax=ax[1])
plt.show()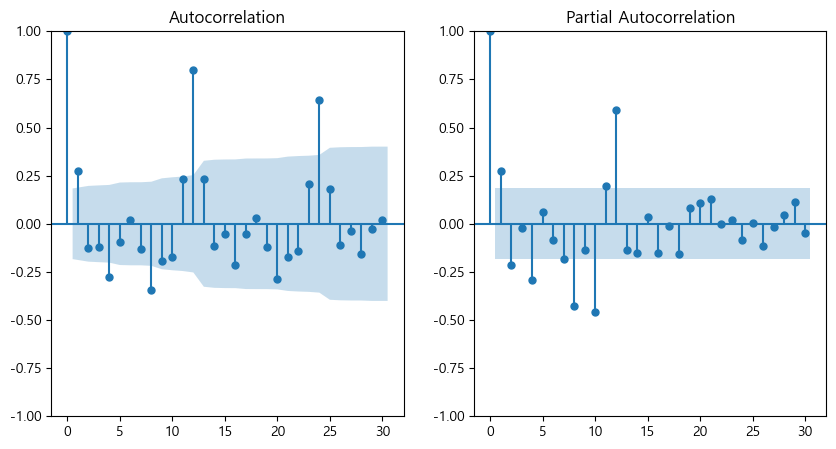
랜덤하게 구간내에 잘 들어가서 자기상관과 파셜자기상관도 해결이 됐다.
4.3. 모델 학습
시범적 모델 선정 -> 파라미터 추정 -> 모델 확인
파라미터 추정: 자기상관과 부분자기상관을 봐야한다.
p(AR), d(I, 차분), q(MA)
차분을 한 다음에 이제 모델을 선택하는 것이다.
AR, MA, ARMA 중 하나를 선택하는데 이과정에 Box-Jenkins ARIMA Procedure라는 과정이 있다. 자세한 과정은 다음과 같다.
1. 데이터 전처리
2. 시범적 모델 선정 -> 변경 가능
3. 파라미터 추정 (p, d, q)
4. 모델 Check
5. 모델로 예측
이때 2~4번 과정을 반복한다.
이 2번 시범적 모델을 선정할때 봐야하는 표가 있다.
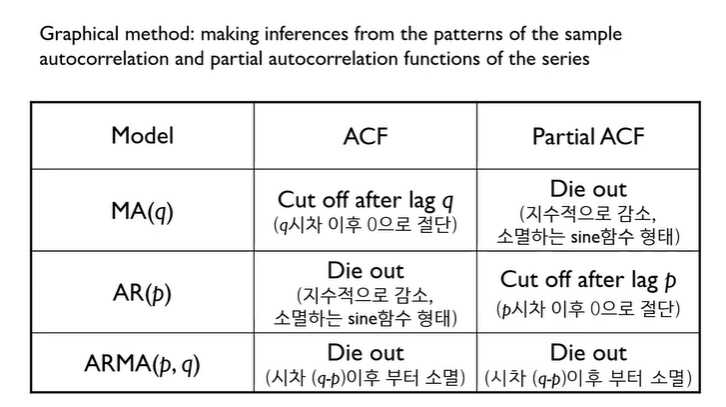
출처: https://velog.io/@sjina0722/%EC%8B%9C%EA%B3%84%EC%97%B4%EB%B6%84%EC%84%9D-ARIMA-%EB%AA%A8%EB%8D%B8
이 과정에서 표를 함께 참고해서 봐야하는데,
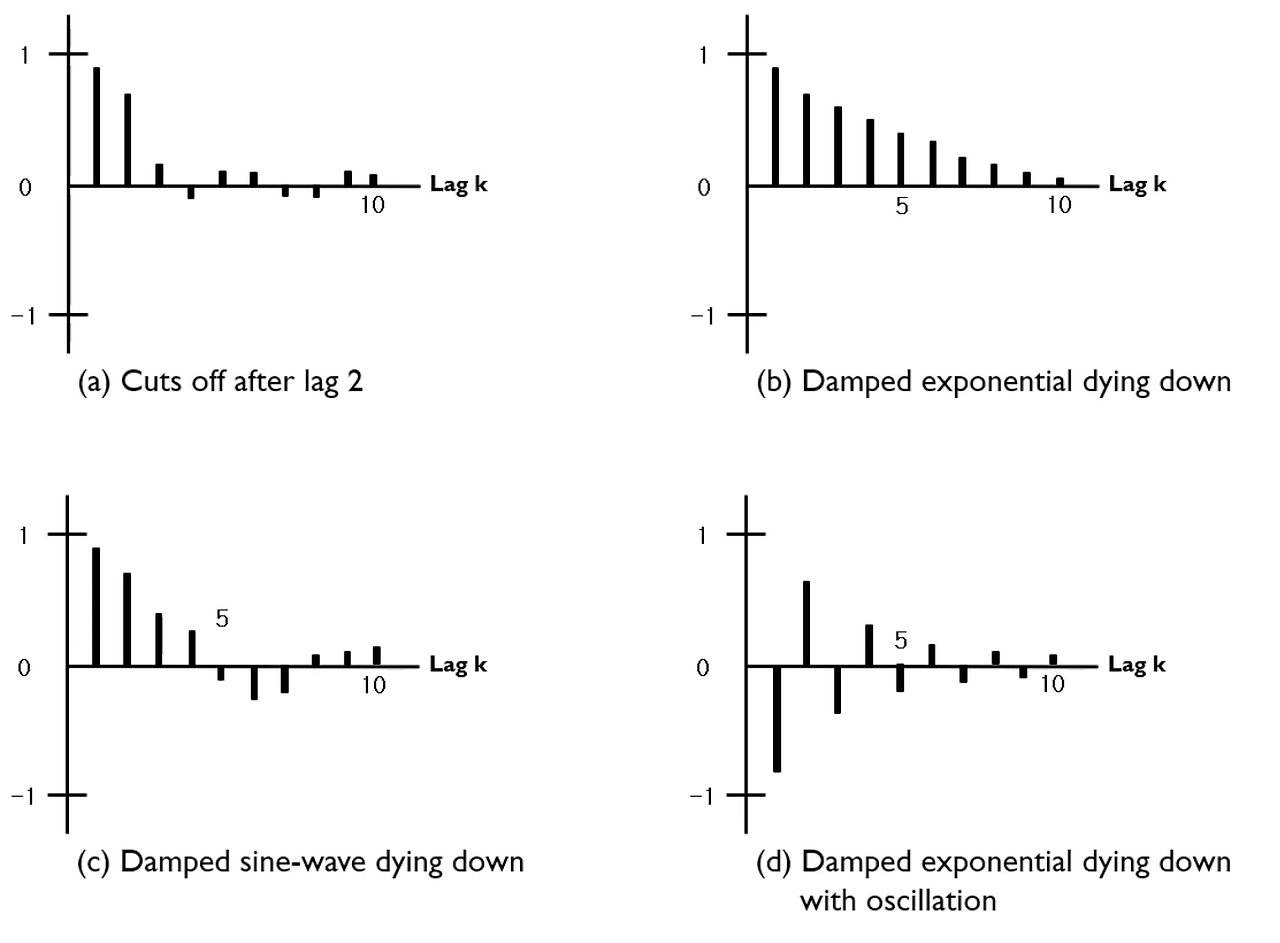
출처: https://velog.io/@sjina0722/%EC%8B%9C%EA%B3%84%EC%97%B4%EB%B6%84%EC%84%9D-ARIMA-%EB%AA%A8%EB%8D%B8
이렇게 a와 같이 뚝 떨어지는 모습이 Cut off이며, b와 같은 지수형태나 c와 같이 sine함수 형태나, 0을 기준으로 +,-가 반복되며 줄어드는 형태가 Die out이다.
그렇다면 이제 표와 그래프를 같이 본다면,
만약 ACF가 a, PCAF가 b라면, 이는 AR이 되는데,
여기서 파라미터 설정이 들어간다.
이 파라미터를 앞서 (p, d, q)라고 했는데 이는 순서대로 AR,I,MA 이다.
즉 AR=p, I=d, MA=q 가 된다.
그리고 AR로 선택했다면, MA는 0으로 고정이 되며,
I(차분)는 앞서 말했듯이 거의 1과 2만 사용하며,
마지막 p값만 정해주면 된다.
이 p값은 지금 보면 lag 0부터 시작하여 lag 2에서 뚝 떨어졌으므로 이 값을 선정할 수 있다.
그러면 다음과 같다.
| AR | I | MA |
|---|---|---|
| p | d | q |
| 2 | 1 | 0 |
이런식으로 진행되며 이 파라미터 값을 바꿔가며 최적의 값을 찾는 것이다.
이제 다시 코드로 보면,
먼저 다시 학습과 테스트로 나누고
air_train, air_test = train_test_split(air, test_size=0.2, shuffle=False)
air_train.shape, air_test.shape((115, 1), (29, 1))지금은 차분 후의 ACF, PACF 도표가 둘 다 lag 1에서만 뚜렷하게 스파이크가 있는데, 앞선 차분 전에는 ACF는 지수적으로 감소했고, PACF는 cut off됐기 때문에 우선은 시범적으로 AR로 두고 진행한다.
즉 MA는 0으로 고정하고 진행한다.
from statsmodels.tsa.arima.model import ARIMA
air_model=ARIMA(air_train.values, order=(1,1,0))
air_model_fit=air_model.fit()
air_model_fit.summary()| Dep. Variable: | y | No. Observations: | 115 |
|---|---|---|---|
| Model: | ARIMA(1, 1, 0) | Log Likelihood | -532.268 |
| Date: | Mon, 07 Apr 2025 | AIC | 1068.536 |
| Time: | 15:41:06 | BIC | 1074.008 |
| Sample: | 0 | HQIC | 1070.757 |
| - 115 | |||
| Covariance Type: | opg |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| ar.L1 | 0.2904 | 0.089 | 3.278 | 0.001 | 0.117 | 0.464 |
| sigma2 | 664.7320 | 89.253 | 7.448 | 0.000 | 489.800 | 839.664 |
| Ljung-Box (L1) (Q): | 0.32 | Jarque-Bera (JB): | 3.25 |
|---|---|---|---|
| Prob(Q): | 0.57 | Prob(JB): | 0.20 |
| Heteroskedasticity (H): | 6.18 | Skew: | 0.40 |
| Prob(H) (two-sided): | 0.00 | Kurtosis: | 2.79 |
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
여기서 AIC값이 낮을 수록 좋은 것이다.
4.4. 최적화
이제 내가 정한 AR 1번째가 아닌 최적화를 돌려서 가장 좋은 것을 골라보자.
p=range(0,3)
d=range(1,2) # 차분은 1아니면 2
q=range(0,3)
pdq=list(itertools.product(p,d,q)) # 경우의 수를 만들어주는 함수
pdq[(0, 1, 0),
(0, 1, 1),
(0, 1, 2),
(1, 1, 0),
(1, 1, 1),
(1, 1, 2),
(2, 1, 0),
(2, 1, 1),
(2, 1, 2)]이 튜플형태의 경우의 수들을 가지고 돌리는 것이다.
aic=[]
for i in pdq:
model=ARIMA(air_train.values, order=i)
model_fit=model.fit()
print(i, ">>>> AIC :", round(model_fit.aic, 2))(0, 1, 0) >>>> AIC : 1076.27
(0, 1, 1) >>>> AIC : 1063.65
(0, 1, 2) >>>> AIC : 1060.69
(1, 1, 0) >>>> AIC : 1068.54
(1, 1, 1) >>>> AIC : 1058.25
(1, 1, 2) >>>> AIC : 1057.33
(2, 1, 0) >>>> AIC : 1065.64
(2, 1, 1) >>>> AIC : 1058.65
(2, 1, 2) >>>> AIC : 1057.52이렇게 보니 (1, 1, 2) >>>> AIC : 1057.33 이 값이 가장 최저의 값이다.
즉 ARIMA 모델을 다 선택한 것이다.
그렇다면 이제 최적화 했으니 이 파라미터를 가지고 예측을 진행하자.
air_opt=ARIMA(air_train.values, order=(1,1,2)) # ARIMA
air_opt_fit=air_opt.fit()
air_opt_fit.summary()| Dep. Variable: | y | No. Observations: | 115 |
|---|---|---|---|
| Model: | ARIMA(1, 1, 2) | Log Likelihood | -524.664 |
| Date: | Mon, 07 Apr 2025 | AIC | 1057.328 |
| Time: | 16:10:29 | BIC | 1068.272 |
| Sample: | 0 | HQIC | 1061.769 |
| - 115 | |||
| Covariance Type: | opg |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| ar.L1 | 0.5387 | 0.128 | 4.219 | 0.000 | 0.288 | 0.789 |
| ma.L1 | -0.2053 | 0.122 | -1.688 | 0.091 | -0.444 | 0.033 |
| ma.L2 | -0.5606 | 0.084 | -6.647 | 0.000 | -0.726 | -0.395 |
| sigma2 | 578.5728 | 105.827 | 5.467 | 0.000 | 371.155 | 785.991 |
| Ljung-Box (L1) (Q): | 0.52 | Jarque-Bera (JB): | 4.81 |
|---|---|---|---|
| Prob(Q): | 0.47 | Prob(JB): | 0.09 |
| Heteroskedasticity (H): | 5.54 | Skew: | 0.18 |
| Prob(H) (two-sided): | 0.00 | Kurtosis: | 2.06 |
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
4.4. 예측
air_forecast=air_opt_fit.forecast(len(air_test))
air_forecastarray([482.49384085, 450.83165341, 433.77578041, 424.58807647,
419.6388192 , 416.97273987, 415.53656902, 414.76292861,
414.3461819 , 414.12168765, 414.00075648, 413.93561295,
413.90052125, 413.88161796, 413.87143509, 413.86594975,
413.86299489, 413.86140316, 413.86054573, 413.86008384,
413.85983503, 413.859701 , 413.8596288 , 413.85958991,
413.85956895, 413.85955767, 413.85955159, 413.85954831,
413.85954655])r2_score(air_test.values, air_forecast)-0.11863065243213766그런데 이렇게 -0.1이 나오면 안좋은 것이다.
예측을 잘 못한 것이다.
그러면 우선 훈련과 테스트를 그려보면 다음과 같고,
plt.figure(figsize=(12,6))
plt.plot(air_train, label="train")
plt.plot(air_test, label="test", linestyle="dashed")
plt.legend()
plt.show()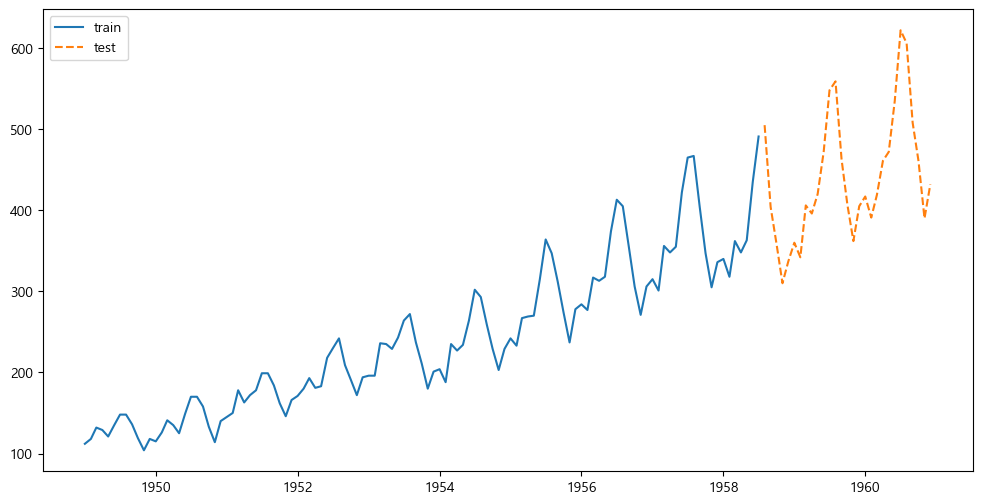
여기에 예측을 그려봐야하는데,
plt.figure(figsize=(12,6))
plt.plot(air_train, label="train")
plt.plot(air_test, label="test", linestyle="dashed")
plt.plot(air_test.index, air_forecast, linestyle="dashed")
plt.legend()
plt.show()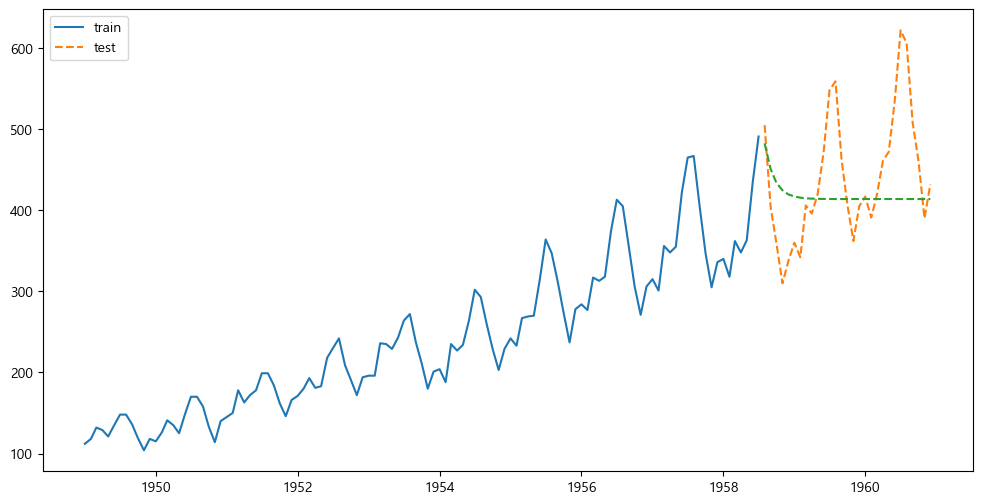
완전히 떨어진 값을 볼 수있다.
이는 사실 계절성이 빠졌기 때문이다.
이를 위해서는 Seasonal이 들어가는 SARIMA를 사용해야한다.
4.5. SARIMA (Seasonal ARIMA)
ARIMA 모델에 계절 변동을 반영한 모델이다.
ARIMA에 계절적요인인 P,D,Q가 들어가는 것이다.
s값은 만약 월별 계절성을 나타내면 s=12, 분기면 s=4와 같이 바뀐다.
비계절적 요인인 p,d,q를 찾아준 것과 똑같이
계절적 요인도 range로 잡아서 튜플 조합을 만들어서 for문으로 돌려준다.
먼저 비계절적 요인 먼저 경우의 수를 생성해주자.
이때 SARIMA는 SARIMAX 클래스를 사용해야한다.
from statsmodels.tsa.statespace.sarimax import SARIMAX
p=range(0,3)
d=range(1,2)
q=range(0,3)
pdq=list(itertools.product(p,d,q))
pdq[(0, 1, 0),
(0, 1, 1),
(0, 1, 2),
(1, 1, 0),
(1, 1, 1),
(1, 1, 2),
(2, 1, 0),
(2, 1, 1),
(2, 1, 2)]
for x in list(itertools.product(p,d,q)):
print(x)(0, 1, 0)
(0, 1, 1)
(0, 1, 2)
(1, 1, 0)
(1, 1, 1)
(1, 1, 2)
(2, 1, 0)
(2, 1, 1)
(2, 1, 2)이제 계절적 요인도 처리해야하는데,
지금 근데 출력하면 튜플형태다.
이를 x[0], x[1]과 같이 뽑아온 후에 뒤에 12를 붙여줘야한다.
for x in list(itertools.product(p,d,q)):
print(x[0], x[1], x[2], 12)0 1 0 12
0 1 1 12
0 1 2 12
1 1 0 12
1 1 1 12
1 1 2 12
2 1 0 12
2 1 1 12
2 1 2 12그러면 이제 이를 계절적 요인으로 처리하기 위해서 list에 담아줘야한다.
s_pdq=[]
for x in list(itertools.product(p,d,q)):
s_pdq.append((x[0], x[1], x[2], 12))
s_pdq[(0, 1, 0, 12),
(0, 1, 1, 12),
(0, 1, 2, 12),
(1, 1, 0, 12),
(1, 1, 1, 12),
(1, 1, 2, 12),
(2, 1, 0, 12),
(2, 1, 1, 12),
(2, 1, 2, 12)]
숫자 조합시 조합이 안되는 경우 에러가 발생하는데,
이를 그냥 무시하고 continue 시키기 위해 try, except를 사용한다.
그리고 조합이 많기 때문에 한눈에 최적값을 찾기 어렵다.
따라서 리스트로 담아서 후에 처리한다.
aic=[]
params=[]
for i in pdq:
for j in s_pdq:
try:
model=SARIMAX(air_train.values, order=i, seasonal_order=j)
model_fit=model.fit()
print(f"SARIMAX:{i}{j} >>>> AIC: {round(model_fit.aic, 2)}")
# 최적의 값 찾기 위해 리스트로 담아두기
aic.append(round(model_fit.aic, 2))
params.append((i,j))
except:
continueSARIMAX:(0, 1, 0)(0, 1, 0, 12) >>>> AIC: 757.83
SARIMAX:(0, 1, 0)(0, 1, 1, 12) >>>> AIC: 756.99
SARIMAX:(0, 1, 0)(0, 1, 2, 12) >>>> AIC: 758.83
SARIMAX:(0, 1, 0)(1, 1, 0, 12) >>>> AIC: 756.96
SARIMAX:(0, 1, 0)(1, 1, 1, 12) >>>> AIC: 758.92
SARIMAX:(0, 1, 0)(1, 1, 2, 12) >>>> AIC: 754.43
SARIMAX:(0, 1, 0)(2, 1, 0, 12) >>>> AIC: 758.87
SARIMAX:(0, 1, 0)(2, 1, 1, 12) >>>> AIC: 760.73
d:\anaconda\envs\thirdENV\lib\site-packages\statsmodels\base\model.py:607: ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals
warnings.warn("Maximum Likelihood optimization failed to "
SARIMAX:(0, 1, 0)(2, 1, 2, 12) >>>> AIC: 754.91
SARIMAX:(0, 1, 1)(0, 1, 0, 12) >>>> AIC: 756.01
SARIMAX:(0, 1, 1)(0, 1, 1, 12) >>>> AIC: 756.38
SARIMAX:(0, 1, 1)(0, 1, 2, 12) >>>> AIC: 757.65
SARIMAX:(0, 1, 1)(1, 1, 0, 12) >>>> AIC: 756.17
SARIMAX:(0, 1, 1)(1, 1, 1, 12) >>>> AIC: 758.11
SARIMAX:(0, 1, 1)(1, 1, 2, 12) >>>> AIC: 751.73
SARIMAX:(0, 1, 1)(2, 1, 0, 12) >>>> AIC: 757.99
SARIMAX:(0, 1, 1)(2, 1, 1, 12) >>>> AIC: 753.78
SARIMAX:(0, 1, 1)(2, 1, 2, 12) >>>> AIC: 762.1
SARIMAX:(0, 1, 2)(0, 1, 0, 12) >>>> AIC: 757.78
SARIMAX:(0, 1, 2)(0, 1, 1, 12) >>>> AIC: 758.04
SARIMAX:(0, 1, 2)(0, 1, 2, 12) >>>> AIC: 759.28
SARIMAX:(0, 1, 2)(1, 1, 0, 12) >>>> AIC: 757.81
SARIMAX:(0, 1, 2)(1, 1, 1, 12) >>>> AIC: 759.75
SARIMAX:(0, 1, 2)(1, 1, 2, 12) >>>> AIC: 753.5
SARIMAX:(0, 1, 2)(2, 1, 0, 12) >>>> AIC: 759.64
d:\anaconda\envs\thirdENV\lib\site-packages\statsmodels\base\model.py:607: ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals
warnings.warn("Maximum Likelihood optimization failed to "
SARIMAX:(0, 1, 2)(2, 1, 1, 12) >>>> AIC: 755.48
SARIMAX:(0, 1, 2)(2, 1, 2, 12) >>>> AIC: 761.99
SARIMAX:(1, 1, 0)(0, 1, 0, 12) >>>> AIC: 755.5
SARIMAX:(1, 1, 0)(0, 1, 1, 12) >>>> AIC: 755.98
SARIMAX:(1, 1, 0)(0, 1, 2, 12) >>>> AIC: 757.1
SARIMAX:(1, 1, 0)(1, 1, 0, 12) >>>> AIC: 755.75
SARIMAX:(1, 1, 0)(1, 1, 1, 12) >>>> AIC: 757.65
SARIMAX:(1, 1, 0)(1, 1, 2, 12) >>>> AIC: 751.15
SARIMAX:(1, 1, 0)(2, 1, 0, 12) >>>> AIC: 757.45
SARIMAX:(1, 1, 0)(2, 1, 1, 12) >>>> AIC: 752.99
d:\anaconda\envs\thirdENV\lib\site-packages\statsmodels\base\model.py:607: ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals
warnings.warn("Maximum Likelihood optimization failed to "
SARIMAX:(1, 1, 0)(2, 1, 2, 12) >>>> AIC: 760.52
SARIMAX:(1, 1, 1)(0, 1, 0, 12) >>>> AIC: 756.02
SARIMAX:(1, 1, 1)(0, 1, 1, 12) >>>> AIC: 756.63
SARIMAX:(1, 1, 1)(0, 1, 2, 12) >>>> AIC: 757.75
SARIMAX:(1, 1, 1)(1, 1, 0, 12) >>>> AIC: 756.41
SARIMAX:(1, 1, 1)(1, 1, 1, 12) >>>> AIC: 758.26
SARIMAX:(1, 1, 1)(1, 1, 2, 12) >>>> AIC: 752.53
SARIMAX:(1, 1, 1)(2, 1, 0, 12) >>>> AIC: 758.03
d:\anaconda\envs\thirdENV\lib\site-packages\statsmodels\base\model.py:607: ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals
warnings.warn("Maximum Likelihood optimization failed to "
SARIMAX:(1, 1, 1)(2, 1, 1, 12) >>>> AIC: 754.16
SARIMAX:(1, 1, 2)(0, 1, 0, 12) >>>> AIC: 757.92
SARIMAX:(1, 1, 2)(0, 1, 1, 12) >>>> AIC: 758.44
SARIMAX:(1, 1, 2)(0, 1, 2, 12) >>>> AIC: 759.63
SARIMAX:(1, 1, 2)(1, 1, 0, 12) >>>> AIC: 758.22
SARIMAX:(1, 1, 2)(1, 1, 1, 12) >>>> AIC: 760.1
SARIMAX:(1, 1, 2)(1, 1, 2, 12) >>>> AIC: 754.53
SARIMAX:(1, 1, 2)(2, 1, 0, 12) >>>> AIC: 759.92
d:\anaconda\envs\thirdENV\lib\site-packages\statsmodels\base\model.py:607: ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals
warnings.warn("Maximum Likelihood optimization failed to "
SARIMAX:(1, 1, 2)(2, 1, 1, 12) >>>> AIC: 756.16
d:\anaconda\envs\thirdENV\lib\site-packages\statsmodels\base\model.py:607: ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals
warnings.warn("Maximum Likelihood optimization failed to "
SARIMAX:(1, 1, 2)(2, 1, 2, 12) >>>> AIC: 763.42
SARIMAX:(2, 1, 0)(0, 1, 0, 12) >>>> AIC: 756.77
SARIMAX:(2, 1, 0)(0, 1, 1, 12) >>>> AIC: 757.23
SARIMAX:(2, 1, 0)(0, 1, 2, 12) >>>> AIC: 758.31
SARIMAX:(2, 1, 0)(1, 1, 0, 12) >>>> AIC: 756.98
SARIMAX:(2, 1, 0)(1, 1, 1, 12) >>>> AIC: 758.86
SARIMAX:(2, 1, 0)(1, 1, 2, 12) >>>> AIC: 752.77
SARIMAX:(2, 1, 0)(2, 1, 0, 12) >>>> AIC: 758.65
SARIMAX:(2, 1, 0)(2, 1, 1, 12) >>>> AIC: 754.51
d:\anaconda\envs\thirdENV\lib\site-packages\statsmodels\tsa\statespace\sarimax.py:966: UserWarning: Non-stationary starting autoregressive parameters found. Using zeros as starting parameters.
warn('Non-stationary starting autoregressive parameters'
d:\anaconda\envs\thirdENV\lib\site-packages\statsmodels\tsa\statespace\sarimax.py:978: UserWarning: Non-invertible starting MA parameters found. Using zeros as starting parameters.
warn('Non-invertible starting MA parameters found.'
SARIMAX:(2, 1, 1)(0, 1, 0, 12) >>>> AIC: 757.98
SARIMAX:(2, 1, 1)(0, 1, 1, 12) >>>> AIC: 758.54
SARIMAX:(2, 1, 1)(0, 1, 2, 12) >>>> AIC: 759.69
SARIMAX:(2, 1, 1)(1, 1, 0, 12) >>>> AIC: 758.31
SARIMAX:(2, 1, 1)(1, 1, 1, 12) >>>> AIC: 760.18
d:\anaconda\envs\thirdENV\lib\site-packages\statsmodels\base\model.py:607: ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals
warnings.warn("Maximum Likelihood optimization failed to "
SARIMAX:(2, 1, 1)(1, 1, 2, 12) >>>> AIC: 754.53
SARIMAX:(2, 1, 1)(2, 1, 0, 12) >>>> AIC: 759.98
d:\anaconda\envs\thirdENV\lib\site-packages\statsmodels\base\model.py:607: ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals
warnings.warn("Maximum Likelihood optimization failed to "
SARIMAX:(2, 1, 1)(2, 1, 1, 12) >>>> AIC: 756.16
SARIMAX:(2, 1, 2)(0, 1, 0, 12) >>>> AIC: 755.2
SARIMAX:(2, 1, 2)(0, 1, 1, 12) >>>> AIC: 755.99
SARIMAX:(2, 1, 2)(0, 1, 2, 12) >>>> AIC: 759.77
SARIMAX:(2, 1, 2)(1, 1, 0, 12) >>>> AIC: 755.82
SARIMAX:(2, 1, 2)(1, 1, 1, 12) >>>> AIC: 757.71
SARIMAX:(2, 1, 2)(1, 1, 2, 12) >>>> AIC: 752.34
SARIMAX:(2, 1, 2)(2, 1, 0, 12) >>>> AIC: 757.56
d:\anaconda\envs\thirdENV\lib\site-packages\statsmodels\base\model.py:607: ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals
warnings.warn("Maximum Likelihood optimization failed to "
SARIMAX:(2, 1, 2)(2, 1, 1, 12) >>>> AIC: 753.96
SARIMAX:(2, 1, 2)(2, 1, 2, 12) >>>> AIC: 761.39
d:\anaconda\envs\thirdENV\lib\site-packages\statsmodels\base\model.py:607: ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals
warnings.warn("Maximum Likelihood optimization failed to "
중간중간 에러, 경고가 나오는 이유는 중간중간 연산이 안되는 파라미터가 있기 때문이다.
이제 앞서 잡은 리스트 aic와 params를 이용해서 최적의 값을 뽑아보자.
min(aic), aic.index(min(aic))(np.float64(751.15), 32)params[32]((1, 1, 0), (1, 1, 2, 12))sorted_list=sorted(zip(aic, params))
sorted_list[(np.float64(751.15), ((1, 1, 0), (1, 1, 2, 12))),
(np.float64(751.73), ((0, 1, 1), (1, 1, 2, 12))),
(np.float64(752.34), ((2, 1, 2), (1, 1, 2, 12))),
(np.float64(752.53), ((1, 1, 1), (1, 1, 2, 12))),
(np.float64(752.77), ((2, 1, 0), (1, 1, 2, 12))),
(np.float64(752.99), ((1, 1, 0), (2, 1, 1, 12))),
(np.float64(753.5), ((0, 1, 2), (1, 1, 2, 12))),
(np.float64(753.78), ((0, 1, 1), (2, 1, 1, 12))),
(np.float64(753.96), ((2, 1, 2), (2, 1, 1, 12))),
(np.float64(754.16), ((1, 1, 1), (2, 1, 1, 12))),
(np.float64(754.43), ((0, 1, 0), (1, 1, 2, 12))),
(np.float64(754.51), ((2, 1, 0), (2, 1, 1, 12))),
(np.float64(754.53), ((1, 1, 2), (1, 1, 2, 12))),
(np.float64(754.53), ((2, 1, 1), (1, 1, 2, 12))),
(np.float64(754.91), ((0, 1, 0), (2, 1, 2, 12))),
(np.float64(755.2), ((2, 1, 2), (0, 1, 0, 12))),
(np.float64(755.48), ((0, 1, 2), (2, 1, 1, 12))),
(np.float64(755.5), ((1, 1, 0), (0, 1, 0, 12))),
(np.float64(755.75), ((1, 1, 0), (1, 1, 0, 12))),
(np.float64(755.82), ((2, 1, 2), (1, 1, 0, 12))),
(np.float64(755.98), ((1, 1, 0), (0, 1, 1, 12))),
(np.float64(755.99), ((2, 1, 2), (0, 1, 1, 12))),
(np.float64(756.01), ((0, 1, 1), (0, 1, 0, 12))),
(np.float64(756.02), ((1, 1, 1), (0, 1, 0, 12))),
(np.float64(756.16), ((1, 1, 2), (2, 1, 1, 12))),
(np.float64(756.16), ((2, 1, 1), (2, 1, 1, 12))),
(np.float64(756.17), ((0, 1, 1), (1, 1, 0, 12))),
(np.float64(756.38), ((0, 1, 1), (0, 1, 1, 12))),
(np.float64(756.41), ((1, 1, 1), (1, 1, 0, 12))),
(np.float64(756.63), ((1, 1, 1), (0, 1, 1, 12))),
(np.float64(756.77), ((2, 1, 0), (0, 1, 0, 12))),
(np.float64(756.96), ((0, 1, 0), (1, 1, 0, 12))),
(np.float64(756.98), ((2, 1, 0), (1, 1, 0, 12))),
(np.float64(756.99), ((0, 1, 0), (0, 1, 1, 12))),
(np.float64(757.1), ((1, 1, 0), (0, 1, 2, 12))),
(np.float64(757.23), ((2, 1, 0), (0, 1, 1, 12))),
(np.float64(757.45), ((1, 1, 0), (2, 1, 0, 12))),
(np.float64(757.56), ((2, 1, 2), (2, 1, 0, 12))),
(np.float64(757.65), ((0, 1, 1), (0, 1, 2, 12))),
(np.float64(757.65), ((1, 1, 0), (1, 1, 1, 12))),
(np.float64(757.71), ((2, 1, 2), (1, 1, 1, 12))),
(np.float64(757.75), ((1, 1, 1), (0, 1, 2, 12))),
(np.float64(757.78), ((0, 1, 2), (0, 1, 0, 12))),
(np.float64(757.81), ((0, 1, 2), (1, 1, 0, 12))),
(np.float64(757.83), ((0, 1, 0), (0, 1, 0, 12))),
(np.float64(757.92), ((1, 1, 2), (0, 1, 0, 12))),
(np.float64(757.98), ((2, 1, 1), (0, 1, 0, 12))),
(np.float64(757.99), ((0, 1, 1), (2, 1, 0, 12))),
(np.float64(758.03), ((1, 1, 1), (2, 1, 0, 12))),
(np.float64(758.04), ((0, 1, 2), (0, 1, 1, 12))),
(np.float64(758.11), ((0, 1, 1), (1, 1, 1, 12))),
(np.float64(758.22), ((1, 1, 2), (1, 1, 0, 12))),
(np.float64(758.26), ((1, 1, 1), (1, 1, 1, 12))),
(np.float64(758.31), ((2, 1, 0), (0, 1, 2, 12))),
(np.float64(758.31), ((2, 1, 1), (1, 1, 0, 12))),
(np.float64(758.44), ((1, 1, 2), (0, 1, 1, 12))),
(np.float64(758.54), ((2, 1, 1), (0, 1, 1, 12))),
(np.float64(758.65), ((2, 1, 0), (2, 1, 0, 12))),
(np.float64(758.83), ((0, 1, 0), (0, 1, 2, 12))),
(np.float64(758.86), ((2, 1, 0), (1, 1, 1, 12))),
(np.float64(758.87), ((0, 1, 0), (2, 1, 0, 12))),
(np.float64(758.92), ((0, 1, 0), (1, 1, 1, 12))),
(np.float64(759.28), ((0, 1, 2), (0, 1, 2, 12))),
(np.float64(759.63), ((1, 1, 2), (0, 1, 2, 12))),
(np.float64(759.64), ((0, 1, 2), (2, 1, 0, 12))),
(np.float64(759.69), ((2, 1, 1), (0, 1, 2, 12))),
(np.float64(759.75), ((0, 1, 2), (1, 1, 1, 12))),
(np.float64(759.77), ((2, 1, 2), (0, 1, 2, 12))),
(np.float64(759.92), ((1, 1, 2), (2, 1, 0, 12))),
(np.float64(759.98), ((2, 1, 1), (2, 1, 0, 12))),
(np.float64(760.1), ((1, 1, 2), (1, 1, 1, 12))),
(np.float64(760.18), ((2, 1, 1), (1, 1, 1, 12))),
(np.float64(760.52), ((1, 1, 0), (2, 1, 2, 12))),
(np.float64(760.73), ((0, 1, 0), (2, 1, 1, 12))),
(np.float64(761.39), ((2, 1, 2), (2, 1, 2, 12))),
(np.float64(761.99), ((0, 1, 2), (2, 1, 2, 12))),
(np.float64(762.1), ((0, 1, 1), (2, 1, 2, 12))),
(np.float64(763.42), ((1, 1, 2), (2, 1, 2, 12)))]
for aic_val, param_val in sorted_list[:10] :
print(aic_val, ">>>>", param_val)751.15 >>>> ((1, 1, 0), (1, 1, 2, 12))
751.73 >>>> ((0, 1, 1), (1, 1, 2, 12))
752.34 >>>> ((2, 1, 2), (1, 1, 2, 12))
752.53 >>>> ((1, 1, 1), (1, 1, 2, 12))
752.77 >>>> ((2, 1, 0), (1, 1, 2, 12))
752.99 >>>> ((1, 1, 0), (2, 1, 1, 12))
753.5 >>>> ((0, 1, 2), (1, 1, 2, 12))
753.78 >>>> ((0, 1, 1), (2, 1, 1, 12))
753.96 >>>> ((2, 1, 2), (2, 1, 1, 12))
754.16 >>>> ((1, 1, 1), (2, 1, 1, 12)) 이제 최적으로 나온 값으로 돌려보면,
model=SARIMAX(air_train.values, order=(1,1,0), seasonal_order=(1,1,2,12))
model_fit=model.fit()
print(model_fit.summary())SARIMAX Results
===============================================================================================
Dep. Variable: y No. Observations: 115
Model: SARIMAX(1, 1, 0)x(1, 1, [1, 2], 12) Log Likelihood -370.574
Date: Tue, 08 Apr 2025 AIC 751.147
Time: 10:29:09 BIC 764.272
Sample: 0 HQIC 756.462
- 115
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ar.L1 -0.2359 0.093 -2.548 0.011 -0.417 -0.054
ar.S.L12 0.9989 0.189 5.289 0.000 0.629 1.369
ma.S.L12 -1.3751 2.839 -0.484 0.628 -6.939 4.188
ma.S.L24 0.3965 1.034 0.383 0.702 -1.631 2.424
sigma2 69.6263 185.439 0.375 0.707 -293.828 433.080
===================================================================================
Ljung-Box (L1) (Q): 0.02 Jarque-Bera (JB): 2.76
Prob(Q): 0.88 Prob(JB): 0.25
Heteroskedasticity (H): 1.10 Skew: 0.38
Prob(H) (two-sided): 0.79 Kurtosis: 2.72
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).sa_forecast=model_fit.forecast(len(air_test))
sa_r2=r2_score(air_test, sa_forecast)
sa_r20.890266581684617앞서 계절적 요인이 빠져서 -0.1 정도가 나온 값보다 훨씬 올라간 정확도를 볼 수 있다.
plt.figure(figsize=(12,6))
plt.plot(air_train, label="train")
plt.plot(air_test, label="test", linestyle="dashed")
plt.plot(air_test.index, sa_forecast, label="forecast", linestyle="dashed")
plt.legend()
plt.show()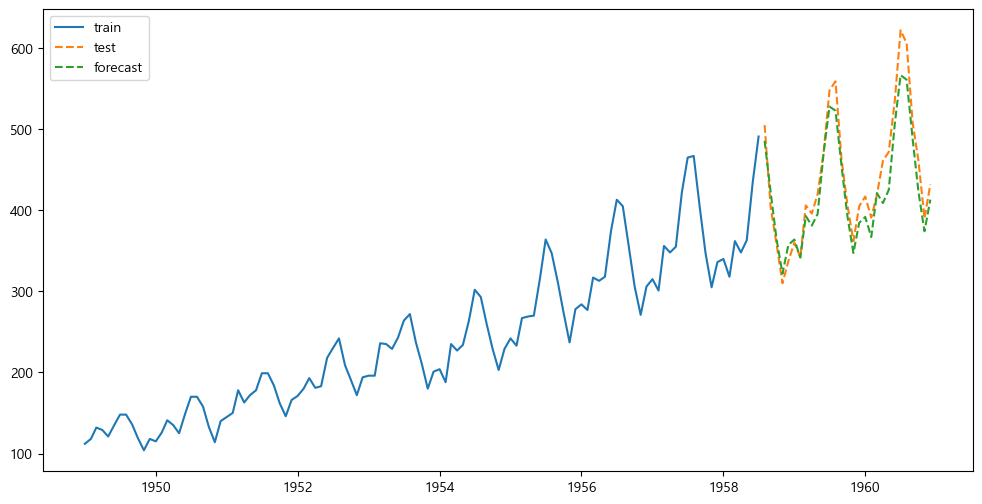
이렇게 시각화해보니 잘 따라간 모습을 볼 수 있다.
4.6. AUTO ARIMA
그런데 지금 보면 p,d,q 등을 지정해주고, SARIMAX 클래스에 있는 order라는 거에 넘겨주는 등의 작업을 했었는데,
이걸 전체 다 하는 AUTO ARIMA라는 것이 있다.
이는 모델은 아니고 라이브러리다.
이 과정을 이해하기 위해 지금까지 한거고.. 당연히 특별한 경우가 아니라면 이 AUTO ARIMA를 사용하면 된다.
pip install pmdarima
from pmdarima import auto_arima이 import 과정에서 에러가 발생할 수 있는데,
이런 경우에는 라이브러리들을 upgrade하고, pip도 업그레이드해보고,
c++ 빌드 툴을 새로 설치를 해야할 수도 있다.
또는 혹시 conda 환경이라면 conda install도 실행해보자.
air_train, air_test = train_test_split(air, test_size=0.2, shuffle=False)
air_train.shape, air_test.shape((115, 1), (29, 1))auto_model=auto_arima(air_train,
start_p=0, start_q=0, max_p=3, max_q=3, # 차분은 자동으로 수행
seasonal=True, start_P=0, start_Q=0, max_P=3, max_Q=3, m=12, # 계절성 PDA / m=12월별. 4분기별, 7일주기
trace=True, # 학습과정 출력
error_action="ignore", # 조합이 안되는 계산 에러 무시
suppress_warnings=True, # 경고 무시
stepwise=False) # 모든 조합을 테스트해서 매개변수 범위 찾기ARIMA(0,1,0)(0,1,0)[12] : AIC=757.826, Time=0.03 sec
ARIMA(0,1,0)(0,1,1)[12] : AIC=756.988, Time=0.09 sec
ARIMA(0,1,0)(0,1,2)[12] : AIC=758.826, Time=0.36 sec
ARIMA(0,1,0)(0,1,3)[12] : AIC=758.186, Time=0.51 sec
ARIMA(0,1,0)(1,1,0)[12] : AIC=756.959, Time=0.07 sec
ARIMA(0,1,0)(1,1,1)[12] : AIC=758.922, Time=0.17 sec
ARIMA(0,1,0)(1,1,2)[12] : AIC=inf, Time=1.02 sec
ARIMA(0,1,0)(1,1,3)[12] : AIC=754.685, Time=1.57 sec
ARIMA(0,1,0)(2,1,0)[12] : AIC=758.869, Time=0.16 sec
ARIMA(0,1,0)(2,1,1)[12] : AIC=760.726, Time=0.60 sec
ARIMA(0,1,0)(2,1,2)[12] : AIC=inf, Time=1.94 sec
ARIMA(0,1,0)(2,1,3)[12] : AIC=756.686, Time=1.86 sec
ARIMA(0,1,0)(3,1,0)[12] : AIC=759.643, Time=0.38 sec
ARIMA(0,1,0)(3,1,1)[12] : AIC=inf, Time=2.26 sec
ARIMA(0,1,0)(3,1,2)[12] : AIC=756.688, Time=2.53 sec
ARIMA(0,1,1)(0,1,0)[12] : AIC=756.011, Time=0.04 sec
ARIMA(0,1,1)(0,1,1)[12] : AIC=756.380, Time=0.13 sec
ARIMA(0,1,1)(0,1,2)[12] : AIC=757.653, Time=0.53 sec
ARIMA(0,1,1)(0,1,3)[12] : AIC=756.866, Time=0.69 sec
ARIMA(0,1,1)(1,1,0)[12] : AIC=756.166, Time=0.11 sec
ARIMA(0,1,1)(1,1,1)[12] : AIC=758.107, Time=0.27 sec
ARIMA(0,1,1)(1,1,2)[12] : AIC=inf, Time=1.63 sec
ARIMA(0,1,1)(1,1,3)[12] : AIC=752.982, Time=1.27 sec
ARIMA(0,1,1)(2,1,0)[12] : AIC=757.994, Time=0.22 sec
ARIMA(0,1,1)(2,1,1)[12] : AIC=inf, Time=1.59 sec
ARIMA(0,1,1)(2,1,2)[12] : AIC=inf, Time=2.78 sec
ARIMA(0,1,1)(3,1,0)[12] : AIC=758.104, Time=0.47 sec
ARIMA(0,1,1)(3,1,1)[12] : AIC=inf, Time=2.17 sec
ARIMA(0,1,2)(0,1,0)[12] : AIC=757.778, Time=0.06 sec
ARIMA(0,1,2)(0,1,1)[12] : AIC=758.043, Time=0.18 sec
ARIMA(0,1,2)(0,1,2)[12] : AIC=759.284, Time=0.59 sec
ARIMA(0,1,2)(0,1,3)[12] : AIC=758.652, Time=0.76 sec
ARIMA(0,1,2)(1,1,0)[12] : AIC=757.811, Time=0.15 sec
ARIMA(0,1,2)(1,1,1)[12] : AIC=759.751, Time=0.22 sec
ARIMA(0,1,2)(1,1,2)[12] : AIC=inf, Time=1.99 sec
ARIMA(0,1,2)(2,1,0)[12] : AIC=759.641, Time=0.28 sec
ARIMA(0,1,2)(2,1,1)[12] : AIC=inf, Time=1.61 sec
ARIMA(0,1,2)(3,1,0)[12] : AIC=759.804, Time=0.67 sec
ARIMA(0,1,3)(0,1,0)[12] : AIC=752.936, Time=0.11 sec
ARIMA(0,1,3)(0,1,1)[12] : AIC=753.809, Time=0.20 sec
ARIMA(0,1,3)(0,1,2)[12] : AIC=755.269, Time=1.06 sec
ARIMA(0,1,3)(1,1,0)[12] : AIC=753.663, Time=0.18 sec
ARIMA(0,1,3)(1,1,1)[12] : AIC=755.497, Time=0.65 sec
ARIMA(0,1,3)(2,1,0)[12] : AIC=755.384, Time=0.37 sec
ARIMA(1,1,0)(0,1,0)[12] : AIC=755.499, Time=0.03 sec
ARIMA(1,1,0)(0,1,1)[12] : AIC=755.982, Time=0.13 sec
ARIMA(1,1,0)(0,1,2)[12] : AIC=757.103, Time=0.49 sec
ARIMA(1,1,0)(0,1,3)[12] : AIC=756.433, Time=0.52 sec
ARIMA(1,1,0)(1,1,0)[12] : AIC=755.750, Time=0.10 sec
ARIMA(1,1,0)(1,1,1)[12] : AIC=757.649, Time=0.27 sec
ARIMA(1,1,0)(1,1,2)[12] : AIC=inf, Time=1.57 sec
ARIMA(1,1,0)(1,1,3)[12] : AIC=752.557, Time=1.50 sec
ARIMA(1,1,0)(2,1,0)[12] : AIC=757.453, Time=0.19 sec
ARIMA(1,1,0)(2,1,1)[12] : AIC=inf, Time=1.52 sec
ARIMA(1,1,0)(2,1,2)[12] : AIC=inf, Time=nan sec
ARIMA(1,1,0)(3,1,0)[12] : AIC=757.510, Time=0.43 sec
ARIMA(1,1,0)(3,1,1)[12] : AIC=inf, Time=3.09 sec
ARIMA(1,1,1)(0,1,0)[12] : AIC=756.022, Time=0.08 sec
ARIMA(1,1,1)(0,1,1)[12] : AIC=756.629, Time=0.21 sec
ARIMA(1,1,1)(0,1,2)[12] : AIC=757.749, Time=0.94 sec
ARIMA(1,1,1)(0,1,3)[12] : AIC=757.733, Time=1.26 sec
ARIMA(1,1,1)(1,1,0)[12] : AIC=756.406, Time=0.17 sec
ARIMA(1,1,1)(1,1,1)[12] : AIC=758.260, Time=0.39 sec
ARIMA(1,1,1)(1,1,2)[12] : AIC=inf, Time=2.25 sec
ARIMA(1,1,1)(2,1,0)[12] : AIC=758.031, Time=0.49 sec
ARIMA(1,1,1)(2,1,1)[12] : AIC=inf, Time=1.72 sec
ARIMA(1,1,1)(3,1,0)[12] : AIC=758.462, Time=0.82 sec
ARIMA(1,1,2)(0,1,0)[12] : AIC=757.925, Time=0.08 sec
ARIMA(1,1,2)(0,1,1)[12] : AIC=758.441, Time=0.26 sec
ARIMA(1,1,2)(0,1,2)[12] : AIC=759.634, Time=0.85 sec
ARIMA(1,1,2)(1,1,0)[12] : AIC=758.220, Time=0.21 sec
ARIMA(1,1,2)(1,1,1)[12] : AIC=760.100, Time=0.43 sec
ARIMA(1,1,2)(2,1,0)[12] : AIC=759.915, Time=0.38 sec
ARIMA(1,1,3)(0,1,0)[12] : AIC=754.178, Time=0.15 sec
ARIMA(1,1,3)(0,1,1)[12] : AIC=753.995, Time=0.53 sec
ARIMA(1,1,3)(1,1,0)[12] : AIC=753.975, Time=0.52 sec
ARIMA(2,1,0)(0,1,0)[12] : AIC=756.771, Time=0.06 sec
ARIMA(2,1,0)(0,1,1)[12] : AIC=757.226, Time=0.16 sec
ARIMA(2,1,0)(0,1,2)[12] : AIC=758.313, Time=0.60 sec
ARIMA(2,1,0)(0,1,3)[12] : AIC=758.011, Time=0.67 sec
ARIMA(2,1,0)(1,1,0)[12] : AIC=756.982, Time=0.13 sec
ARIMA(2,1,0)(1,1,1)[12] : AIC=758.859, Time=0.28 sec
ARIMA(2,1,0)(1,1,2)[12] : AIC=inf, Time=1.53 sec
ARIMA(2,1,0)(2,1,0)[12] : AIC=758.650, Time=0.27 sec
ARIMA(2,1,0)(2,1,1)[12] : AIC=inf, Time=1.76 sec
ARIMA(2,1,0)(3,1,0)[12] : AIC=758.903, Time=0.55 sec
ARIMA(2,1,1)(0,1,0)[12] : AIC=757.976, Time=0.10 sec
ARIMA(2,1,1)(0,1,1)[12] : AIC=758.537, Time=0.35 sec
ARIMA(2,1,1)(0,1,2)[12] : AIC=759.694, Time=1.03 sec
ARIMA(2,1,1)(1,1,0)[12] : AIC=758.314, Time=0.22 sec
ARIMA(2,1,1)(1,1,1)[12] : AIC=760.183, Time=0.56 sec
ARIMA(2,1,1)(2,1,0)[12] : AIC=759.976, Time=0.53 sec
ARIMA(2,1,2)(0,1,0)[12] : AIC=755.201, Time=0.20 sec
ARIMA(2,1,2)(0,1,1)[12] : AIC=755.987, Time=0.45 sec
ARIMA(2,1,2)(1,1,0)[12] : AIC=755.821, Time=0.50 sec
ARIMA(2,1,3)(0,1,0)[12] : AIC=755.253, Time=0.45 sec
ARIMA(3,1,0)(0,1,0)[12] : AIC=755.605, Time=0.08 sec
ARIMA(3,1,0)(0,1,1)[12] : AIC=756.424, Time=0.18 sec
ARIMA(3,1,0)(0,1,2)[12] : AIC=757.829, Time=0.77 sec
ARIMA(3,1,0)(1,1,0)[12] : AIC=756.268, Time=0.13 sec
ARIMA(3,1,0)(1,1,1)[12] : AIC=758.159, Time=0.41 sec
ARIMA(3,1,0)(2,1,0)[12] : AIC=758.003, Time=0.29 sec
ARIMA(3,1,1)(0,1,0)[12] : AIC=754.435, Time=0.19 sec
ARIMA(3,1,1)(0,1,1)[12] : AIC=754.694, Time=0.45 sec
ARIMA(3,1,1)(1,1,0)[12] : AIC=754.571, Time=0.54 sec
ARIMA(3,1,2)(0,1,0)[12] : AIC=inf, Time=0.47 sec
Best model: ARIMA(1,1,0)(1,1,3)[12]
Total fit time: 70.835 seconds⭐ 참고로 scikit-learn 1.6 이상에서는 경고 메시지가 발생하므로 아래 코드를 넣어주면 된다.
import warnings warnings.filterwarnings("ignore", category=FutureWarning)
이렇게 Best model 까지 출력해준다.
이제 summary를 보면,
auto_model.summary()| Dep. Variable: | y | No. Observations: | 115 |
|---|---|---|---|
| Model: | SARIMAX(1, 1, 0)x(1, 1, [1, 2, 3], 12) | Log Likelihood | -370.278 |
| Date: | Tue, 08 Apr 2025 | AIC | 752.557 |
| Time: | 11:38:46 | BIC | 768.307 |
| Sample: | 01-01-1949 | HQIC | 758.934 |
| - 07-01-1958 | |||
| Covariance Type: | opg |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| ar.L1 | -0.2218 | 0.093 | -2.388 | 0.017 | -0.404 | -0.040 |
| ar.S.L12 | 0.9288 | 0.275 | 3.374 | 0.001 | 0.389 | 1.468 |
| ma.S.L12 | -1.2065 | 0.448 | -2.692 | 0.007 | -2.085 | -0.328 |
| ma.S.L24 | 0.2771 | 0.174 | 1.596 | 0.111 | -0.063 | 0.618 |
| ma.S.L36 | 0.1251 | 0.164 | 0.765 | 0.444 | -0.195 | 0.446 |
| sigma2 | 75.0386 | 19.073 | 3.934 | 0.000 | 37.657 | 112.421 |
| Ljung-Box (L1) (Q): | 0.01 | Jarque-Bera (JB): | 2.50 |
|---|---|---|---|
| Prob(Q): | 0.91 | Prob(JB): | 0.29 |
| Heteroskedasticity (H): | 1.05 | Skew: | 0.37 |
| Prob(H) (two-sided): | 0.90 | Kurtosis: | 2.81 |
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
auto_pred=auto_model.predict(len(air_test))
auto_r2=r2_score(air_test.values, auto_pred)
auto_r20.8836215198338278plt.figure(figsize=(12, 6))
plt.plot(air_train, label="Train")
plt.plot(air_test, label="Test", linestyle="dashed")
plt.plot(air_test.index, auto_pred, label="Forecast", linestyle="dashed")
plt.legend()
plt.show()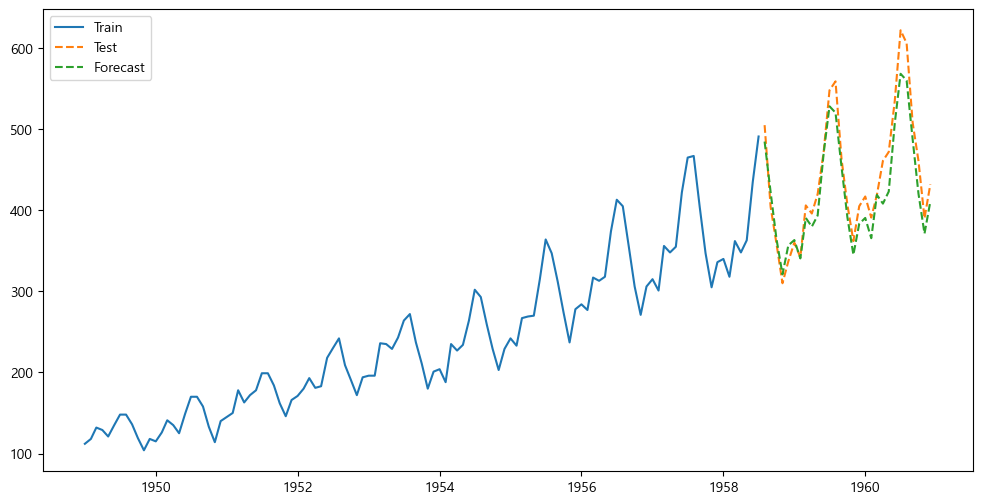
이렇게 간단하게 처리가 가능하기 때문에 당연히 이 AUTO ARIMA를 가장 많이 사용한다.
