코딩테스트를 준비하는 과정을 따로 Velog에 글로 다루지 않고 백준에서 문제만 풀고 있었는데, 이 과정들을 글로 정리해보면서 되짚어보는 것도 좋을 거 같다.
공부할 때 참고한 영상은 거의 바이블처럼 여겨지는
⭐ 나동빈님의 이코테 2021 강의 ⭐
였으며, 이번에는 다시 해당 영상 시리즈의 처음부터 끝까지 깃허브에 올려보기도 해보며 내가 많이 사용하는 알고리즘 코드를 라이브러리화 하는 일명 "팀 노트" 를 관리해보고자 한다.
1. 코딩 테스트 유형 분석
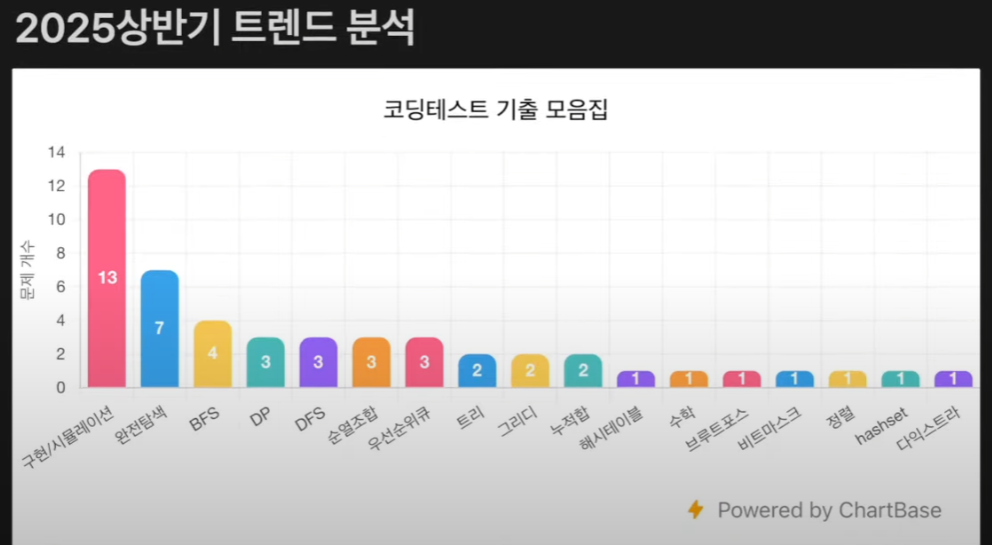
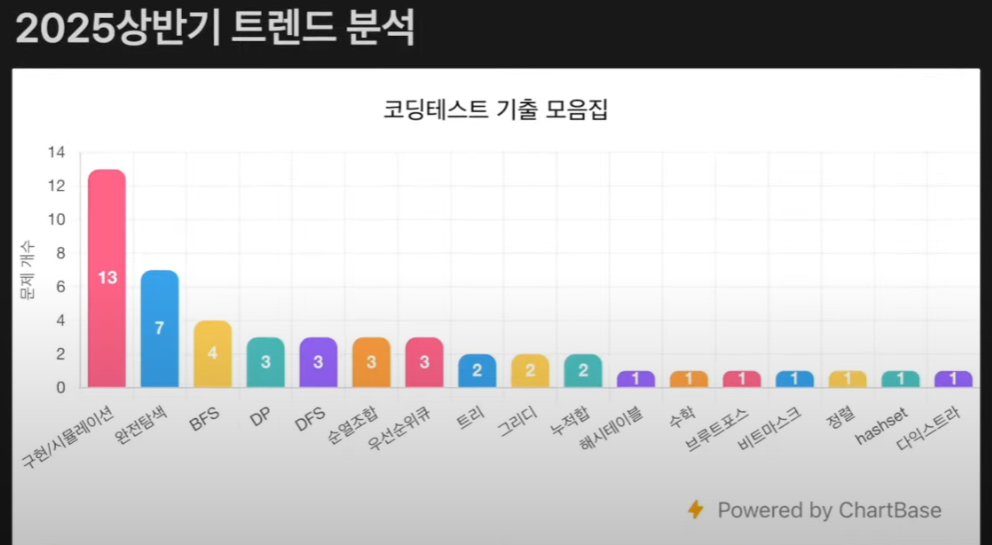
(출처: https://youtu.be/SwqsX8bb-gw?si=C0btl5n5Vg8eikUW)
이는 위 출처의 영상인, 유튜브 개발남노씨 님의 2025년 코테 기출 32문제 분석 영상 중, 2025년 상반기 코딩테스트 트렌드를 분석한 그래프다.
2. 알고리즘 성능 평가
2.1. 복잡도
알고리즘의 성능을 나타내기 위해서는 복잡도라는 개념이 사용된다.
- 시간 복잡도: 특정한 크기의 입력에 대한 알고리즘의 수행 시간을 분석하기 위해 사용됨
- 공간 복잡도: 특정한 크기의 입력에 대한 알고리즘의 메모리 사용량을 분석하기 위해 사용됨
즉 복잡도가 낮을 수록 더 좋은 알고리즘인 것이다.
2.2. 빅-O 표기법
이 복잡도의 표기법에는 여러 가지가 있는데, 빅오(Big-O) 표기법이 효과적이다.
이는 가장 빠르게 증가하는 항만을 고려하며, 함수의 상한만을 나타낸다.
연산 횟수가 인 알고리즘에 있다고 가정하면, 빅-O 표기법에서는 차수가 가장 큰 항만 남기므로 으로 표현되며, 계수는 무시한다.
⭐ 여기서 만약
이 정말 커서 "1억" 정도가 된다고 가정한다면, 을 제외한 나머지 항들 이에 비해 작은 수가 된다.
그렇기 때문에 이 굉장히 큰 값이 될 수 있다고 가정했을 때, 이 함수의 상한 만을 고려한다고 하더라도 충분히 그 함수의 성능이 어느정도 나올지 가늠 할 수 있는 것이다.
📌 참고
- 항만
- 알고리즘의 시간 복잡도를 나타내는 함수에서 가장 영향력이 큰 항을 의미함
- 시간 복잡도 함수가 과 같을 때, n이 커짐에 따라 의 값에 가장 큰 영향을 미치는 항은 이므로, 이 항을 항만 이라고 함
- 빅-O에서는 이러한 가장 빠르게 증가하는 항만을 고려하여 함수의 상한을 표현함
- 상한
- 알고리즘의 시간 복잡도 함수에서 최악의 경우, 즉 가장 오래 걸리는 실행 시간을 나타냄
- 빅-O는 함수의 상한을 표현하는 표기법으로, 어떤 알고리즘의 시간 복잡도가 이라는 것은 최악의 경우에도 입력 크기 n에 비례하는 시간 안에 실행됨을 의미하며, 다시 말해, 입력 크기가 커짐에 따라 실행 시간이 에 비례하여 증가할 수 있다는 뜻
2.3. ⭐ 다양한 알고리즘 표기법
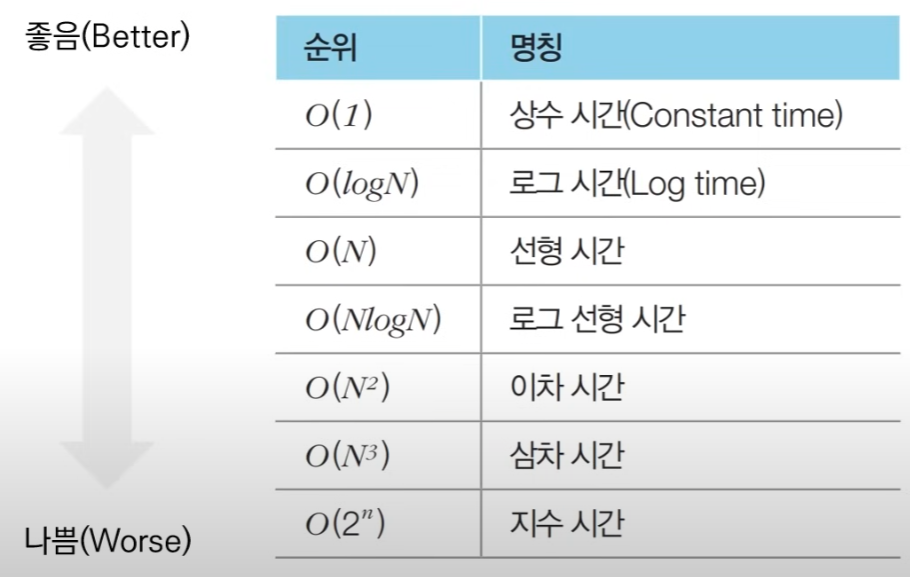
알고리즘은 이와 같이 상수 시간, 로그 시간, 선형 시간 등의 표기법을 붙여서 해당 알고리즘의 성능을 나타낼 수 있으며, 좋음(Better) 쪽으로 갈수록 복잡도가 낮은 것이다.
즉 여기서 상수 시간은 몇번의 연산만 거치면 수행이 완료되는 경우, 로그 시간은 에 비례하는 만큼 수행 되는 것을 말하는 것이다.
예시 프로그램을 보면 다음과 같다.
array=[3,5,1,2,4] # N=5
total=0
for x in array: total += x
print(total)이의 수행 시간은 데이터의 개수(N) 에 비례하기 때문에 시간 복잡도는 이 된다.
이런 점을 고려해야한다.
2.4. 알고리즘 설계 팁
일반적으로 CPU 기반의 개인 PC나 채점용 PC에서 연산 횟수가 5억을 넘어가는 경우에는 python을 기준으로 통상 5~15초 가량이 소요된다.
그리고 채점 서버가 PyPy를 제공한다면 경우에 따라 C언어(통상 1~3초)보다 빠르게 동작하기도 하기에 Python으로 제출했을때 시간초과가 나왔을때 PyPy로 제출하는 방법도 있다.
그런데 아예 반대로 PyPy보다 Python이 빠른 경우도 있으니 그 반대의 방안도 생각해 두는 것이 좋다.
그리고 코딩 테스트 문제에서 시간제한은 통상 1~5초 가량이라는 점을 유의해야 한다.
명시되지 않았다면 대략 5초 정도라고 생각하는 것이 좋다.
따라서 문제에서 가장 먼저 시간제한(수행시간 요구사항)을 확인해야 한다.
시간제한이 1초라면, 일반적으로 다음과 같을 때 풀 수 있다.
- N의 범위가 500인 경우: 시간 복잡도가 인 알고리즘 설계시
- N의 범위가 2,000인 경우: 시간 복잡도가 인 알고리즘 설계시
- N의 범위가 100,000인 경우: 시간 복잡도가 인 알고리즘 설계시
- N의 범위가 10,000,000인 경우: 시간 복잡도가 인 알고리즘 설계시
2.5. 수행 시간 측정 소스코드 예제
import time
start_time=time.time()
# ( 프로그램 소스코드 )
end_time=time.time()
print("time:", end_time-start_time)3. 자료형
3.1. 수 자료형
3.1.1. 실수형
- 소수부가 0이거나, 정수부가 0인 소수는 0을 생략할 수 있음
a=5.
print(a) # 5.0
a=-.7
print(a) #-0.7-
지수 표현
- e나 E를 이용한 방법으로, 다음에 오는 수는 10의 지수부를 의미
- ⭐ 최단 경로 알고리즘에서는 도달할 수 없는 노드에 대해 최단 거리를
무한(INF)로 설정함 - 이때 가능한 최댓값이 10억 미만일 때, 무한(INF)의 값으로 를 이용할 수 있음
a=1e9 print(a) # 1000000000.0 a=123e-3 print(a) # 0.123
- e나 E를 이용한 방법으로, 다음에 오는 수는 10의 지수부를 의미
-
IEEE754 표준
- 실수형을 저장하기 위해 4byte, 8byte의 고정된 크기의 메모리를 할당함
- 그래서 컴퓨터에서는 이를 표현하는 정확도가 떨어지는 경우가 있음
- 10진수에서 0.1+0.2=0.3 이지만 2진수에서는 정확하게 표현할 수 없어서 최대한 비슷하지만, 미세한 오차가 발생함
a=0.1 a+=0.2 print(a) # 0.30000000000000004- 따라서 이럴 때는
round()함수를 이용해서 처리
a=0.1 a+=0.2 print(round(a,2)) # 0.3 -
연산
- ⭐ 사칙연산과 나머지 연산자가 많이 사용됨
- 나누기(
/): 실수형 반환 - 나머지(
%): 홀수/짝수 체크용 - 몫(
//) - 거듭제곱/제곱근(
**):a=3; print(a**0.5) # 1.7320508075688772
⭐ 3.2. 리스트 자료형
- C/Java에서의 배열(Array)의 기능 및 Linked List와 유사한 기능 지원
- C++의 STL vector와 기능적으로 유사
- 리스트 대신 배열 혹은 테이블이라고도 부름
[]와,사용- 크기 N, 모든 값 0 1차원 리스트 초기화
n=5
a=[0]*n # [0, 0, 0, 0, 0]3.2.1. 인덱싱 & 슬라이싱
- 인덱스 번호: 0 부터 시작하며 가장 끝은 -1(음의 정수: 원소 거꾸로 탐색)
- 슬라이싱: 끝 인덱스는 실제 인덱스보다 1을 더 크게 설정
: 두 번째 원소부터 네 번째 원소까지
⭐ 3.2.2. 컴프리헨션
- 리스트 초기화 방법 중 하나
- ⭐ 대괄호 안에 조건문과 반복문 적용
lst=[i for i in range(10) if i%2==1]
print(lst) # [1, 3, 5, 7, 9]
lst=[i*i for i in range(1,10)]
print(lst) # [1, 4, 9, 16, 25, 36, 49, 64, 81]-
⭐ 2차원 리스트를 초기화할 때 좋음
-
크기의 2차원 리스트 한 번에 초기화 할 때,
즉 N번 반복할 때마다, 길이가 m인 리스트를 초기화하는 방식은
lst=[[0]*m for _ in range(n)] -
⭐ 그런데 주의할 점이 있음
만약 2차원 리스트를 위가 아닌 다음과 같이 초기화하면 문제가 발생함
lst=[[0]*m]*n
보기에는 문제가 없어 보이지만, 파이썬은 기본적으로 리스트 자료형으로 변수값을 할당하면, 내부적으로 그 리스트는 객체형태로 처리되고, 별도로 주소 값을 가지게 됨
따라서 이와 같이 리스트를 n번 곱하게 되면, 길이가 m인 리스트를 n번 만큼 참조 값을 복사하는 것과 같아짐
즉 내부적으로 포함되어 있는[[0]*m]이 리스트가, 모두 동일한, 같은 객체로 인식하게 되어버림
그렇게되면 내부 리스트에서 특정 위치의 하나의 값만 바꾸더라도, 모든 리스트에 동일하게 변경사항이 적용되어 버림n, m=3, 3 lst=[[0]*m]*n print(lst) # [[0, 0, 0], # [0, 0, 0], # [0, 0, 0]] lst[1][1]=1 print(lst) # [[0, 1, 0], # [0, 1, 0], # [0, 1, 0]]
⭐ 3.2.3. _ 사용
-
파이썬에서 반복을 수행할 때 반복을 위한 변수의 값을 무시하고자 할 때, 또는 변수를 사용하지 않을때
_를 사용total=0 for i in range(1,10): total += i print(total) # 45 for _ in range(3): print("Hello", end=" ") # Hello Hello Hello
또 다른 자주 사용되는 메서드
lst.append(): 가장 뒤에 원소 하나 삽입 # 시간복잡도:lst.sort(): 오름차순 정렬 # 시간복잡도:lst.sort(reverse=True): 내림차순 정렬 # 시간복잡도:lst.reverse(): 원소 순서 뒤집기 # 시간복잡도:lst.insert(삽입할 위치 인덱스, 삽입할 값): 특정 인덱스 위치에 원소 삽입 후 한 칸씩 뒤로 미룸 # 시간복잡도:lst.count(특정 값): 특정한 값을 가지는 원소 개수 count # 시간복잡도:lst.remove(특정 값): 특정한 값을 갖는 원소를 제거하는데, 값을 가진 원소가 여러 개면 하나만 제거 # 시간복잡도:
- ⭐ 특정 값 모두 제거할 때는
lst=[1,2,2,3,4,5] set_for_remove={2,3} # 집합 자료형 (특정한 원소의 존재 유무만 체크할 때 효과적으로 사용됨) # set_for_remove에 포함 안되는 값만 골라서 result에 저장 lst_after_remove=[i for i in lst if i not in set_for_remove] print(lst_after_remove) # [1, 4, 5]
3.3. 문자열 자료형
+를 이용해서 문자열을 연결할 수 있음
a="hello"
b=' world'
print(a+b) # hello world- ⭐ 인덱싱과 슬라이싱은 가능하지만, 특정 인덱스 값을 변경할 수는 없음(Immutable)
⭐ 3.4. 튜플 자료형
- 리스트와 유사하지만 한번 선언된 값을 변경할 수 없음
()이용- 리스트에 비해 기능이 제한적이여서 공간 효율적
- ⭐ 사용하면 좋은 경우
- 리스트와 다르게 일반적으로 서로 다른 성질의 데이터를 묶어서 관리해야 할 때 사용함
- 최단 경로 알고리즘에서는 (비용, 노드 번호)에서 비용을 실수 값으로 저장할 수 있고, 노드 번호는 정수형으로 처리한다고 하면, 이 튜플은 이들을 하나로 묶어서 사용할 수 있음
- (학번, 성적) 과 같이도 처리 가능
- 딕셔너리나 set같은 자료형에서는 해싱(Hashing)의 키 값으로 데이터의 묶음, 나열을 사용해야 하는 경우가 있는데, 튜플은 변경이 불가능해서 리스트와 다르게 키 값으로 사용될 수 있음
3.5. 사전(딕셔너리) 자료형
- key, value 쌍
- 리스트, 튜플과 다르게 비 순서형
- 변경 불가능(immutable) 자료형을 키 값으로 사용할 수 있음
- key 값으로 접근
- ⭐ 파이썬의 딕셔너리 자료형은 내부적으로 해시 테이블을 이용하므로 데이터 조회 및 수정에 있어서 의 시간에 처리할 수 있음
dict()함수를 이용해서 초기화 가능
data=dict()
data["사과"]="Apple"
data["바나나"]=Banana"
print(data) # {'사과': 'Apple', '바나나': 'Banana'}
if "사과" in data:
print("'사과'를 키로 가지는 데이터가 존재한다.") # '사과'를 키로 가지는 데이터가 존재한다.keys()와values()라는 함수로 키만, 값만 뽑을 수 있는데,
data={
"사과": "Apple",
"바나나": "Banana"
}
print(data) # {'사과': 'Apple', '바나나': 'Banana'}
key_lst=data.keys()
print(key_lst) # dict_keys(['사과', '바나나'])이때, keys()나, values()는 dict_keys나, dict_values라는 하나의 객체로 반환되기 때문에, 리스트와 같이 반환하고 싶다면 형변환을 해주면 됨
data={
"사과": "Apple",
"바나나": "Banana"
}
print(data) # {'사과': 'Apple', '바나나': 'Banana'}
key_lst=data.keys()
print(key_lst) # dict_keys(['사과', '바나나'])
value_lst=data.values()
print(value_lst) # dict_values(['Apple', 'Banana'])
print(list(value_lst)) # ['Apple', 'Banana']3.6. 집합(set) 자료형
- 중복을 허용하지 않음
- 비 순서형
- 데이터가 존재하는지 존재하지 않는지 여부 체크용으로 많이 사용
- 리스트나 문자열을 이용해서 초기화 할 수 있음
- 초기화:
set()함수 이용 또는{}안에 각 원소를,를 기준으로 구분하여 삽입data=set([1,2,2,3,3,4,5]) # {1, 2, 3, 4, 5}data={1,1,2,3,4,5,5} # {1, 2, 3, 4, 5}
- 딕셔너리와 동일하게 조회, 수정에 있어서 의 시간에 처리할 수 있음
3.6.1. 집합 자료형 연산
s1=set([1,2,3,4,5])
s2={3,4,5,6,7}
# 합집합(|)
print(s1|s2) # {1, 2, 3, 4, 5, 6, 7}
# 교집합(&)
print(s1&s2) # {3, 4, 5}
# 차집합(-)
print(s1-s2) {1, 2}3.6.2. 관련 함수
data=set([1,2,3])
data.add(4)
print(data) # {1, 2, 3, 4}
data.update([5,6])
print(data) # {1, 2, 3, 4, 5, 6}
data.remove(3)
print(data) # {1, 2, 4, 5, 6}⭐ 자료형 정리
리스트나 튜플은 순서가 있기 떄문에 인덱싱을 통해 자료형 값을 얻을 수 있지만,
딕셔너리나 집합은 순서가 없기 때문에 인덱싱으로 값을 얻을 수 없음
사전의 키나 집합의 원소를 이용해 의 시간 복잡도로 조회함
4. 입출력
프로그램 동작의 첫 번째 단계는 데이터를 입력 받거나 생성하는 것이다.
일반적으로 코딩테스트 문제들은 특정한 양식으로 입력이 주어진다고 문제에 정해지고, 실제로 문제에서 정해놓은 규칙에 따라서 프로그램의 입력이 주어진다.
예를 들자면, 학생의 성적 데이터가 주어지고 이를 내림차순으로 정렬한 결과를 출력하는 프로그램을 작성하라는 식으로 나온다.
- 입력 예시
5
60 70 30 90 85- 출력 예시
90 85 70 60 30알고리즘 문제 및 코딩테스트에서 가장 많이 표준 입력 방법은 다음과 같다.
input(): 한 줄의 문자열 입력 받음- ⭐
map(): 리스트의 모든 원소에 각각 특정한 함수를 적용할 때 사용 - 공백을 기준으로 구분된 데이터를 입력 받을 때,
list(map(int, input().split())) - 공백을 기준으로 구분된 데이터의 수가 많지 않다면, 단순하게,
`a, b, c = map(int, input().split())
n=int(input())
data=input()
print(f"입력받은 n: {n}")
print(f"입력받은 data: {data}")글이 길어져서 나머지는 다음 글에서 적겠다!
