
📌 사용 환경
Python 3.10.2
conda 24.9.0
JupyterLab 4.2.5
저번 글에 이어 자료형(data type)인 기본 자료형에 이어, 컬렉션 자료형이라는 분류가 또 있다.
하지만 컬렉션 자료형에 분류되긴 하지만 대부분 기본 자료형으로 보는 문자열(str)에 대해 조금 더 자세히 알아보고자 한다.
1. 문자열 자료형
문자열은 문자, 단어 등으로 구성된 문자들의 집합이다.
숫자의 경우 a=10은 숫자 하나가 변수에 저장되지만, b=“apple”은 a,p,p,l,e 각각 하나씩 메모리 공간에 순서대로 저장된다.
이는 인덱싱 부분으로 연결되어 하나하나 뽑아서 쓸 수 있다.
1.1. 문자열 선언
- 문자열 선언 : ' ' / "" / """ """ / ''' '''
문자열을 만드는 방법은 “apple”, ‘apple’, “””apple”””, ‘’’apple’’’ 이렇게
홀따옴표를 쓰는 경우와 쌍따옴표 쓰는 경우, 홀따옴표 3개를 쓰는 경우 그리고 쌍따옴표 3개를 쓰는 경우까지가 있다.
a='Hello, World'
b="안녕하세요"
c='''Hello, World'''
d="""안녕하세요"""
print(type(a), type(b), type(c), type(d))
print(a, "\t", b, "\t", c, "\t", d)
# ✅ 출력 결과
# <class 'str'> <class 'str'> <class 'str'> <class 'str'>
# Hello, World 안녕하세요 Hello, World 안녕하세요그렇다면 홀따옴표를 쓰는 경우, 쌍따옴표 쓰는 경우 그 차이와 이유는 무엇일까?
1.1.1. 홀따옴표와 쌍따옴표는 줄바꿈이 안된다.
여러 줄인 문자열을 변수에 대입하고 싶을때 사용한다.
x='Hello \n World'
print(x)
y='''어서와
파이썬은
처음이지?'''
print(y)
# ✅ 출력 결과
# Hello
# World
# 어서와
# 파이썬은
# 처음이지?개행 문자인 \n을 사용하여 줄을 바꿀 수 있지만
여러 줄을 써야할 경우에는 무조건 홀따옴표 3개 또는 쌍따옴표 3개를 사용해야 한다.
만약 ' ' / " " 를 사용할 경우 에러가 발생한다.
1.1.2. 문자열 안에 따옴표를 포함할 경우
문자열 안에 따옴표 포함하는 경우 두가지 방법을 기억하면 된다.
- 문자열 안에 사용하는 따옴표와 다른 따옴표를 사용한다.
- 문자열 안에 사용하는 따옴표 앞에, 이스케이프 문자(
\)를 적는다.
name="He's name is Honggildong."
print(name)
age='"He's name is 20." his friend said.'
print(age)
name2="\"He's name is Honggildong.\" his friend said."
print(name2)
# ✅ 출력 결과
# He's name is Honggildong.
# "He's name is 20." his friend said.
# "He's name is Honggildong. his friend said. 1.2. 문자열 연산
1.2.1. 문자열 결합
s1="Hello "
s2="World"
print(s1 + s2)
# ✅ 출력 결과
# Hello World문자열 결합은 덧셈 연산자를 이용하여 결합할 수 있다.
1.2.2. 문자열 반복
s1="Hello"
print(s1 * 3)
# ✅ 출력 결과
# HelloHelloHello문자열 반복은 * 연산자를 이용하며 주어진 횟수만큼 문자열을 반복한다.
1.2.3. 멤버십 연산
s2="World"
print('o' in s2)
print('o' not in s2)
# ✅ 출력 결과
# True
# False1.2.4. 문자열 비교
a="apple"
b="banna"
print(a == b)
print(a != b)
print(a < b)
print(a > b)
print(a <= b)
print(a >= b)
# ✅ 출력 결과
# False
# True
# True
# False
# True
# False이전 글의 연산자와 더불어 문자열도 연산이 가능하다.
문자열 비교는 ==, !=, <, >, <=, >= 등의 연산자를 사용할 수 있다.
단, 크기 비교 연산자는 사전의 순서를 이용하여 문자열의 크기를 비교한다. 사전적으로 앞선 문자열을 더 작은 문자열로 판단한다.
1.3. 형 변환
num=55.5
print(num, type(num))
value=int(num)
print(value, type(value))
# ✅ 출력 결과
# 5.5 <class 'float'>
# 55 <class 'int'>형 변환은 위와 같이 원하는 형(데이터 타입)을 선언해주면 된다.
그런데 여기서 놓치면 안되는 부분은 input() 함수를 사용하는 경우이다.
input() 함수란 사용자에게 입력을 받는 함수인데, 이를 사용할 때 주의할 점은 외부에서 들어오는 데이터는 전부 다 문자열(str)이라는 것이다.
이를 반드시 주의해서 사용해야 한다.
num=input("숫자를 입력해주세요: ")
# ✅ 출력 결과
# 숫자를 입력해주세요: 10print(num, type(num))
# ✅ 출력 결과
# 10 <class 'str'>이와 같이 데이터 타입이 str인 것을 확인할 수 있다.
따라서 숫자를 입력했다고 하더라도, 숫자와 연산하면 결과가 다르게 나올 수 있으니 주의하자.
에러가 나오는 코드를 확인해보자.
testnum1=10
testnum2=input("숫자 입력: ")
print(testnum1+testnum2)
# ✅ 출력 결과
# 숫자 입력: 20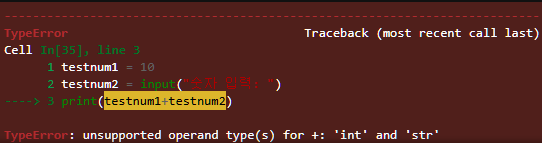
따라서, 이렇게 형 변환이 필요하다.
num=int(num)
print(num, type(num))
# ✅ 출력 결과
# 10 <class 'int'>1.4. ⭐ 인덱싱(Indexing)
문자열은 메모리 공간에 각 문자들이 일렬로 저장된다. 그렇다면 각 문자들은 자신의 위치에 순서가 있을 것이다. 인덱싱은 각 그 순서를 사용하여 원하는 곳에 데이터를 뽑아쓰는 것이다.
각 문자열의 위치는 0 부터 시작하며 뒤부터 찾을때 가장 뒤는 -1이다.
리스트나, 튜플에서 인덱스를 쓰는 경우가 많다.
a="Hello World"
print(a) # Hello World
print(a[0]) # H
print(a[8]) # r
print(a[-1]) # d1.5. ⭐ 슬라이싱(Slicing)
슬라이싱은 문자열의 범위를 지정하여 부분 문자열을 추출하는 것이다.
인덱싱과 비교하자면 슬라이싱은 범위로 가져온다고 생각하면 된다.
문자열[begin:end:step]의 형태를 가지며 각 부분은 생략 가능하다.
하지만, end 부분을 잘 알고 지정해야 하는데, end는 범위 끝 인덱스를 지정하지만, end 앞의 문자까지 추출하는 것이다.
즉 a[2:5]의 경우 2이상부터 5미만(2<=a<5)까지만 추출하는 것이다.
a="Hello World"
print(a[0:4:1])
print(a[0:4])
print(a[:4])
print(a[4:8:1])
print(a[4:8])
print(a[4:])
print(a[::2])
print(a[2::])
print(a[:4:2])
print(a[::])
# ✅ 출력 결과
# Hell
# Hell
# Hell
# o Wo
# o Wo
# o World
# HloWrd
# llo World
# Hl
# Hello World1.6. 문자열 포매팅(Formatting)
일반적으로 출력하는 방식은 다음과 같다.
name="홍길동"
age=23
print("이름:",name, "\t 나이:", age)
# ✅ 출력 결과
# 이름: 홍길동 나이: 23문자열 포매팅은 문자열 안의 특정 값이 변할 경우, 문자열과 다른 유형의 타입을 조합해서 사용하는 방법이다.
특히 머신러닝에서 뭔가를 예측하거나 데이터 분석하고 그래프의 형태로 시각화 해줄때, x축과 y축이 각각 키인지, 몸무게인지 그리고 그래프의 타이틀이 무엇인지, 이런 부분에서 많이 사용한다.
1.6.1. % 연산자 / s: 문자, d: 정수
name="홍길동"
age=23
print("이름:%s 나이:%d" % (name, age))
# ✅ 출력 결과
# 이름:홍길동 나이:231.6.2. str의 format 함수 사용한 포맷
name="홍길동"
age=23
print("이름:{} 나이:{}".format(name,age))
# ✅ 출력 결과
# 이름:홍길동 나이:231.6.3. str의 순서를 지정한 format 함수 포맷
name="홍길동"
age=23
print("나이:{1} 이름:{0}".format(name, age))
# ✅ 출력 결과
# 나이:23 이름:홍길동1.6.4. ⭐ python 3.6 부터 나온 새로운 포맷 (f-string (f 포매팅))
name="홍길동"
age=23
print(f"나의 이름은 {name} 입니다. 나이는 {age} 입니다.")
# ✅ 출력 결과
# 나의 이름은 홍길동 입니다. 나이는 23 입니다.1.6.5. 출력 서식 지정
print("%10s" % "hi") # 전체 10칸 중 오른쪽 정렬
print("%-10s" % "hi") # 전체 10칸 중 왼쪽 정렬
print("%10.4f" % 3.141592) # 전체 10칸 중 오른쪽 정렬 + 소수점 아래 4자리 까지만
print("%.4f" % 3.141592) # 소수점 아래 4자리 까지만 출력
print("%0.4f" % 3.141592)
print("%08.4f" % 3.141592) # 앞에 0으로 채우고 8칸을 맞추며 소수점 아래 4자리 까지만 출력
# ✅ 출력 결과
# hi
# hi
# 3.1415
# 3.1415
# 3.1415
# 003.1415print()함수에 %를 이용하여 출력 서식을 지정할 수 있는데, %와 함께 오는 s, d, f 등에 따라서 문자열, 정수, 실수 등을 출력할 수 있다.
1.7. 문자열 함수
문자열 관련 함수는 정말 다양하게 있다. 이 모든 함수들을 다 외우지는 못하기 때문에 몇 가지만 집고 넘어가며 자세한 내용들은 파이썬 문서를 참고하면 된다.
s="Hello World"
print("문자열 개수 세는 함수:", s.count('o')) # o의 개수
print("문자열 앞부터 위치 찾기:", s.find('H')) # 있으면 인덱스 번호, 없으면 -1
print("문자열 뒤부터 위치 찾기:", s.rfind('r')) # 있으면 인덱스 번호, 없으면 -1
print("문자열 앞부터 위치 찾기:", s.index('H')) # 있으면 인덱스 번호, 없으면 ERROR -> 자주 사용함
print("문자열 대문자로 변환:", s.upper())
print("문자열 소문자로 변환:", s.lower())
print("문자열 첫글자만 대문자 변환:",s.title())
print("문자열 치환:", s.replace("World", "Apple"))
# ✅ 출력 결과
# 문자열 개수 세는 함수: 2
# 문자열 앞부터 위치 찾기: 0
# 문자열 뒤부터 위치 찾기: 8
# 문자열 앞부터 위치 찾기: 0
# 문자열 대문자로 변환: HELLO WORLD
# 문자열 소문자로 변환: hello world
# 문자열 첫글자만 대문자 변환: Hello World
# 문자열치환: Hello Apple1.7.1. strip()
strip() 이라는 함수를 이용하여 문자열 안에 앞, 뒤, 양쪽의 공백을 지울 수 있는데 코드는 다음과 같다.
a=" Hello World"
b="Hello World "
c=" Hello World "
print(a)
print(b)
print(c)
print("문자열 왼쪽 공백제거:", a.lstrip())
print("문자열 오른쪽 공백제거:", b.rstrip())
print("문자열 양쪽 공백제거:", c.strip())
# ✅ 출력 결과
# Hello World
# Hello World
# Hello World하지만 결과값을 보면 알 수 있듯, 문자열의 앞과 뒤, 양쪽의 공백을 지울 수 는 있지만, 단어 사이의 공백은 지워지지 않는 것을 알 수 있다. 이 부분을 잘 기억하자.
1.7.2. isalpha(), isnumeric(), isalnum()
a="ABCDefg"
b='123'
c="1234ABC"
print(type(a), type(b), type(c))
# ✅ 출력 결과
# <class 'str'> <class 'str'> <class 'str'>a, b, c는 각각 따옴표로 묶여있기 때문에 이들을 출력하면 모두 타입이 str이다.
하지만 다음을 이용하여 각 변수가,
문자열로만 이루어져 있는지(isalpha()),
숫자로 이루어져 있는지(isnumeric()),
문자열과 숫자가 섞여 있는지(isalnum()) 등을 확인할 수 있다.
print("문자열로 이루어져 있는가?", a.isalpha())
print("숫자 이루어져 있는가?", b.isnumeric())
print("문자열과 숫자로 이루어져 있는가?", c.isalnum())
# ✅ 출력 결과
# 문자열로 이루어져 있는가? True
# 숫자 이루어져 있는가? True
# 문자열과 숫자로 이루어져 있는가? True1.8. 문자열 자료형을 리스트 자료형으로 변환
fruits="Apple Banana Orange"
print(fruits, fruits[3], fruits[0])
# ✅ 출력 결과
# Apple Banana Orange l Afruits_list=fruits.split(" ")
print(fruits_list)
print(fruits_list[0])
# ✅ 출력 결과
# ['Apple', 'Banana', 'Orange']
# Apple이렇게 split() 함수를 사용하면 (" ")안에 선언한 내용을 기준으로 각 문자열을 쪼갠다.
따라서 만약 split(",")를 사용하면 다음과 같다.
fruits2="Apple,Banana,Orange"
fruits2_list=fruits2.split(",")
print(fruits2_list)
# ✅ 출력 결과
# ['Apple', 'Banana', 'Orange']또 지금까지는 각 리스트 들로 변환하여 출력했지만 리스트를 문자열로 반환하기 위해서는 join()함수를 활용할 수 있다.
str_fruits="".join(fruits)
print(str_fruits, type(str_fruits))
✅ 출력 결과
# Apple Banana Orange <class 'str'>💪 단답형 퀴즈
Q1. 문자열 "Hello, World!"에서 "World"라는 단어가 시작하는 위치는?
A1. 7 / index("W")를 이용한다.
Q2. "apple".upper()의 결과값은?
A2. "APPLE"
Q3. "abc123".isnumeric()의 결과는?
A3. False
Q4. 문자열 "Python"에서 인덱스 -2에 해당하는 문자는?
A4. "o"
Q5. 문자열 "abcdefg"에서 첫 번째 'e'를 찾기 위한 함수는?
A5. find("e")
Q6. 문자열 " Hello "에서 앞뒤 공백을 제거한 결과는?
A6. Hello / strip() 함수를 이용한다.
Q7. "apple" == "Apple"의 결과는?
A7. False / 대소문자를 구분해야 한다.
Q8. "abc" + "def"의 결과는?
A8. abcdef
Q9. "Python"[::2]의 결과는?
A9. "Pto"
Q10. "Hello World".split()의 결과는?
A10. ['Hello', 'World']
