
📌 사용 환경
Python 3.10.2
conda 24.9.0
JupyterLab 4.2.5
1. 컬렉션 자료형(Collection data types)
자료형(data type)인 기본 자료형에 이어, 이번에는 컬렉션 자료형이다. 컬렉션 자료형은 여러 요소를 하나로 묶어 다룰 수 있게 하는 데이터 타입으로, 다양한 컬렉션 자료형이 있다.
컬렉션의 종류로는 크게 순서형(시퀀스)과 비순서형이 있다.
순서형이란 순서가 있는 목록을 저장하는 자료구조로 순서대로 나열된 데이터를 저장한다.
- 순서형: str(문자열), list(리스트), tuple(튜플, 읽기전용리스트)
- 비순서: set(수학집합), dictonary(사전형태)
문자열, 리스트, 튜플, 딕셔너리, 세트 등이 있으며, 주로 사용되는 컬렉션 자료형은 리스트(List)와 딕셔너리(dictionary)다.
리스트는 순서가 중요하고 데이터의 변경이 필요한 경우에 유용하며, 딕셔너리는 Key와 Value로 묶여 데이터를 빠르고 효율적으로 찾고자 할 때 사용된다. 특히 딕셔너리는 이후 데이터의 구조화와 처리에 있어 중요한 역할을 한다.
그 중 이번에는 리스트에 대해 자세히 알아보자.
2. 리스트(List)
- 데이터 목록을 다루는 자료형
- 인덱싱(indexing)
- 리스트 안에 리스트
- 슬라이싱(slicing)
- 인덱싱과 슬라이싱을 이용한 값 치환
- 리스트 연산
- 리스트 함수
리스트 자료형은 여러 개의 값(정수, 실수, 문자열 등)들을 [ ]로 묶어서 사용한다.
이때 저장되는 데이터 타입은 모두 달라도 되며 데이터를 핸들링하기 위한 다양한 메서드들을 제공한다.
리스트에 관한 자세한 내용은 파이썬 문서 - 리스트를 참고하자.
2.1. 데이터 목록을 다루는 자료형
a=[]
b=[1,2,3,4,5] #정수형
c=["apple", "banana", "orange"] #문자열
d=[1, "apple", "A", 12.3] #섞인 형태
print(a, type(a))
print(b, type(b))
print(c, type(c))
print(d, type(d))
# ✅ 출력 결과
# [] <class 'list'>
# [1, 2, 3, 4, 5] <class 'list'>
# ['apple', 'banana', 'orange'] <class 'list'>
# [1, 'apple', 'A', 12.3] <class 'list'>2.2. 인덱싱(indexing)
인덱싱은 문자열(str)과 같은 방식으로 사용하면 된다.
data=[1, "AB", "Apple", 12.3]
print(data[0])
print(data[-1])
# ✅ 출력 결과
# 1
# 12.32.3. 리스트 안에 리스트
2차원 배열과는 다른 개념이다.
그림으로 보면 다음과 같다.
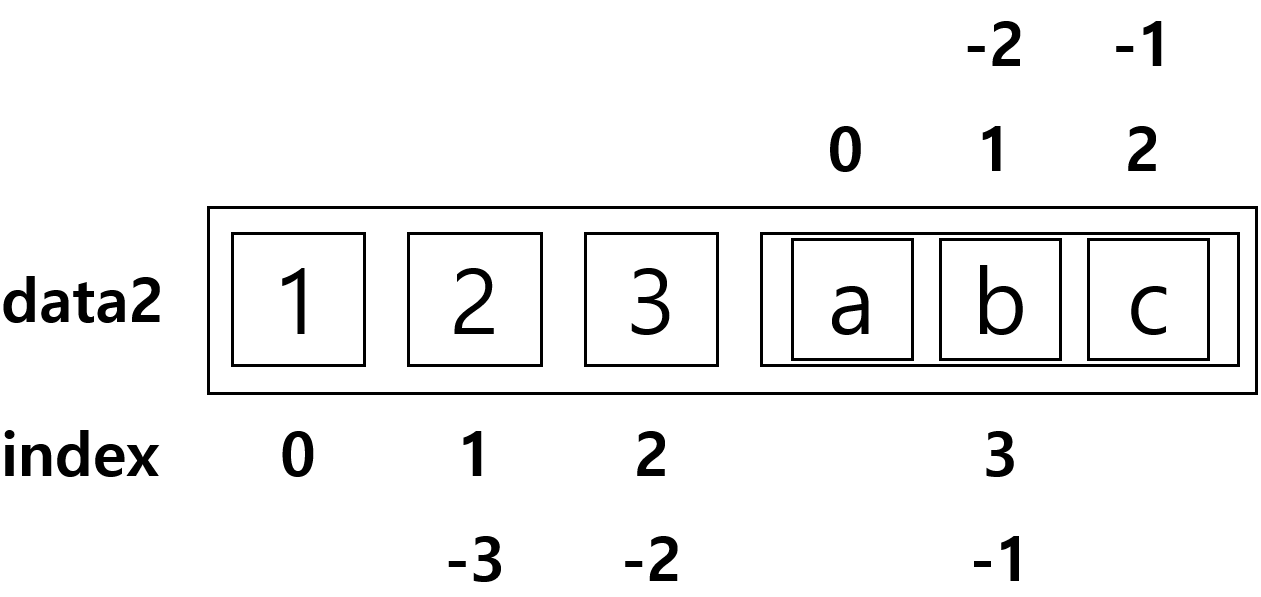
data2=[1,2,3,['a','b','c']]
print(data2[0])
print(data2[-1])
print(data2[3])
print(data2[-1][0]) # a
print(data2[-1][-3]) # a
print(data2[3][0]) # a
print(data2[3][-1]) # a
# ✅ 출력 결과
# 1
# ['a', 'b', 'c']
# ['a', 'b', 'c']
# a
# a
# a
# c2.4. 슬라이싱(slicing)
num=[10,20,30,40,50,60,70,80,90,100]
print(num[0:5:1])
print(num[0:5])
print(num[:5])
print(num[:3])
print(num[5:])
print(num[0:8:2])
# ✅ 출력 결과
# [10, 20, 30, 40, 50]
# [10, 20, 30, 40, 50]
# [10, 20, 30, 40, 50]
# [10, 20, 30]
# [60, 70, 80, 90, 100]
# [10, 30, 50, 70]2.5. 인덱싱과 슬라이싱을 이용한 값 치환
num[0]=77
print(num)
num[2:5]=['apple', 'banana', 'orange'] # 30, 40, 50을 치환
print(num)
# ✅ 출력 결과
# [77, 20, 30, 40, 50, 60, 70, 80, 90, 100]
# [77, 20, 'apple', 'banana', 'orange', 60, 70, 80, 90, 100]2.6. 리스트 연산
+연산자를 사용하여 문자열(str)과 같이 더하는 것이 아니라 합친다.
a=[1,2,3]
b=[4,5,6]
print(a+b)
print(b+a)
# ✅ 출력 결과
# [1, 2, 3, 4, 5, 6]
# [4, 5, 6, 1, 2, 3]단 print(a+b)와 print(b+a)와 같이a와 b의 순서에 따라 결과 값이 바뀌게 되니, 주의해야한다.
*연산자를 사용하여 주어진 숫자 만큼 반복한다.
print(a*3)
# ✅ 출력 결과
# [1, 2, 3, 1, 2, 3, 1, 2, 3]3. 리스트 함수
- 추가
- 정렬
- 검색
- 삭제
3.1. 추가
append(): 리스트 끝에 데이터를 추가한다.
arr=[1,2,3]
arr.append(4) # 리스트 끝에 새 요소를 추가
print(arr)
# ✅ 출력 결과
# [1, 2, 3, 4]insert(위치, 데이터): 원하는 위치에 데이터를 삽입한다.
arr.insert(0, 77)
print(arr)
# ✅ 출력 결과
# [77, 1, 2, 3, 4]이처럼 두 함수 모두 데이터를 추가하지만 insert()함수의 경우 원하는 위치에 데이터를 삽입한 후 한 칸씩 미루게 되는 점에서 차이가 있다.
3.2. 정렬
# sort(): 리스트의 요소들을 순서대로 정렬한다.
arr.sort()
print(arr)
# reverse(): 리스트의 요소들의 순서를 뒤집는다.
arr.reverse()
print(arr)
# ✅ 출력 결과
# [1, 2, 3, 4, 77]
# [77, 4, 3, 2, 1]3.3. 검색
# []의 인덱스를 활용한다면 해당 리스트의 위치를 찾아가 값을 반환한다.
fruits=["apple", "banana", "orange"]
print(fruits[0])
# .index() 를 활용한다면 리스트안에서 ()에 지정한 특정한 요소를 찾아 그 위치를 반환한다.
print(fruits.index("apple"))
# ✅ 출력 결과
# apple
# 03.4. 삭제
앞선 검색에서 사용한 fruits=["apple", "banana", "orange"] 를 사용한 삭제 연산은 다음과 같다.
# remove("요소값"): 리스트에서 요소값과 동일한 값을 찾아 삭제한다.
fruits.remove("apple")
print(fruits)
# del 리스트[인덱스]: 리스트의 인덱스 위치에 찾아가 요소를 삭제한다.
del fruits[1]
print(fruits)
# ✅ 출력 결과
# ['banana', 'orange']
# ['banana']3.5. 리스트에서 리스트를 더하는 함수
extend(): 각 요소 값을 추가하는 append()가 아닌, 리스트에 리스트를 연장시키는 방식이다.
num=[10,20,30]
value=[40,50,60]
num.extend(value)
num.extend(["apple", "banana", "orange"])
print(num)
# ✅ 출력 결과
# [10, 20, 30, 40, 50, 60, 'apple', 'banana', 'orange']3.6. 그 외 함수들 및 python 내장 함수
# count(): 리스트에 포함된 요소의 개수를 반환한다.
num=[1,2,3,4,5,1,2,3,4,1]
print(num.count(1))
# pop(): 리스트의 가장 마지막 요소를 출력 후 삭제한다.
print(num.pop())
print(num.pop())
print(num)
# ✅ 출력 결과
# 3
# 1
# 4
# [1, 2, 3, 4, 5, 1, 2, 3]여기서 pop() 함수가 중요하다.
pop()은 stack 자료구조 LIFO(Last In Frist Out) 형식에서 사용되는데, 사실 파이썬에는 stack 클래스가 존재하지 않는다.
따라서 실제로는 절대 stack 구조가 아니지만 리스트에 pop() 함수를 사용 가능하게 하여 LIFO 구조를 가지게 된다.
⭐
pop()심화이
pop()함수를 이용한 알고리즘 관련 문제들이 매우 중요하기 때문에
다음에 이 리스트를 이용하여 스택(stack) 자료구조를 구현해보면 다음과 같다.# 스택 초기화 stack=[] # 요소 삽입(push) stack.append(10) stack.append(20) stack.append(30) print(stack) # ✅ 출력 결과 # [10, 20, 30]# 요소 제거(pop) print(stack.pop()) print(stack.pop()) print(stack) # ✅ 출력 결과 # 30 # 20 # [10]
append(): 스택에 요소 추가 (맨 끝에 추가)
pop(): 스택의 마지막 요소 반환 후 삭제이처럼 리스트를 이용해 스택의 핵심 동작을 쉽게 구현할 수 있고, 알고리즘 문제에서 매우 자주 활용되니 꼭 익혀두는 게 좋다.
4. ⭐ 내장함수
- 메서드: 문자열 메서드, 리스트 메서드
a.functionName() - 내장함수:
print().type()
함수? 메서드?
글을 정리하면서 이 함수와 메서드라는 용어를 번갈아 사용하여 헷갈릴 수 있다고 생각한다. 그래서 이에 대해 간략히 집어본다.
문자열과 리스트로 먼저 살펴보면 다음과 같다.
str="abc"
str.함수()
lst=[1,2,3,4]
lst.함수()이때, str, list 에서 .(점) 연산자로 호출한 함수들을 method(메서드)라고 한다.
그렇다면 앞서 3.6 에서 사용한 num=[1, 2, 3, 4, 5, 1, 2, 3, 4, 1] 이 리스트를 사용한다고 할 때,
num.pop()과 print(num) 와 같은 명령을 내릴 수 있었다.
따라서 num.pop()은 num라는 리스트가 가지고 있는 pop()이라는 함수를 메서드 라고 하며
print(num)와 같이 .(점) 연산자가 없는 함수를 내장함수라고 한다.
이 내장함수의 종류도 정말 많기 때문에 더 많은 종류와 상세한 설명은 파이썬 문서 - 내장함수를 참고하자.
4.1. 문자열, 리스트, 튜플, 딕셔너리에서도 사용 가능
num=[1,2,3,4,5,1,2,3,4,1]
print(len(num)) # 길이 출력
print(max(num))
print(min(num))
print(sorted(num)) # 오름차순 Ascending
print(sorted(num, reverse=True)) # 내림차순 descending
# ✅ 출력 결과
# 10
# 5
# 1
# [1, 1, 1, 2, 2, 3, 3, 4, 4, 5]
# [5, 4, 4, 3, 3, 2, 2, 1, 1, 1]4.2. ⭐ 내장함수와 메서드의 차이점
이 부분이 상당히 중요하다.
내장함수와 메서드의 차이점은 원본 데이터에 영향을 주는지에 따라 다르다.
- 내장함수
lst=[1, 2, 3, 4, 5, 1, 2, 3, 4, 1]
result=sorted(lst)
print(result)
print(lst)
# ✅ 출력 결과
# [1, 1, 1, 2, 2, 3, 3, 4, 4, 5]
# [1, 2, 3, 4, 5, 1, 2, 3, 4, 1]이와 같이 sorted()는 원본 리스트를 변경하지 않고 정렬된 새로운 리스트를 반환하는 내장 함수다.
- 메서드
lst2=[1, 2, 3, 4, 5, 1, 2, 3, 4, 1]
lst2.sort()
print(lst2)
# ✅ 출력 결과
# [1, 1, 1, 2, 2, 3, 3, 4, 4, 5]이처럼 sort()는 원본 리스트 자체를 정렬하며 원본 데이터를 변경한다.
즉 문자열, 리스트, 튜플 등의 메서드는 .을 통해 호출한 각자의 데이터에 영향을 미치지만 내장 함수는 데이터에 영향을 미치지 않고 새로운 값을 반환한다.
.sort(): 원본 데이터에 영향sorted(): 원본 데이터에 영향 X
💪 객관식 퀴즈
Q1. sort() 메서드와 sorted() 내장 함수의 차이점은?
1) sort()는 원본 데이터를 수정하며, sorted()는 새로운 정렬된 리스트를 반환한다.
2) sort()는 새로운 리스트를 반환하고, sorted()는 원본 데이터를 수정한다.
3) sort()는 문자열만 사용 가능하고, sorted()는 리스트만 사용 가능하다.
4) sort()와 sorted()는 동일한 동작을 한다.
A1. 1
Q2. pop() 메서드를 잘 설명한 것은?
1) 리스트의 첫 번째 요소를 반환하고 삭제한다.
2) 리스트의 마지막 요소를 반환하고 삭제한다.
3) 리스트에서 특정 인덱스의 요소를 반환하고 삭제한다.
4) 리스트에서 특정 값을 삭제한다.
A2. 2
Q3. insert() 메서드를 잘 설명한 것은?
1) 리스트의 마지막에 요소를 추가한다.
2) 리스트의 첫 번째 요소를 제거한다.
3) 리스트의 특정 위치에 요소를 삽입한다.
4) 리스트의 모든 요소를 삭제한다.
A3. 3
Q4. remove() 메서드를 잘 설명한 것은?
1) 값이 아닌 인덱스를 기준으로 삭제한다.
2) 리스트의 가장 첫 번째 값을 삭제한다.
3) 리스트에서 주어진 값을 찾아 삭제한다.
4) 리스트에서 주어진 인덱스를 찾아 삭제한다.
A4. 3
Q5. 리스트에서 sort() 메서드의 기본 정렬 방식은?
1) 내림차순
2) 오름차순
3) 사전순(알파벳 순)
4) 숫자 순
A5. 2
