Data preprocessing issues
처리해야할 데이터 이슈 → 처리한 후 데이터 분석을 한다.
- 데이터가 빠진 경우 (결측치의 처리)
결측치 : 데이터가 없을때 어떻게 해야되는지 - 라벨링된 데이터(category) 데이터의 처리
- 데이터의 scale의 차이가 매우 크게 날 경우
1. Missing Values
NaN인 데이터(데이터 값이 존재하지 않을 때) drop
-
데이터가 없으면 sample을 drop
NaN값이 있을 때 가장 좋은 방법(데이터 값이 존재하지 않을 때)
1) df.isnull().sum() : data가 null일때의 값들을 sum()
⇒ 각 column마다 몇개의 null인 data가 있는지 알 수 있는 방법.
df.isnull().sum() / len(df) : 전체 데이터의 개수를 나눠준다.
⇒ 몇 퍼센트가 비어져 있는지 확인 가능. 퍼센트 비율로 나오게 된다.
2) df.dropna()
NaN인 데이터들을 삭제
df_cleaned = df.dropna(how='all')
df_cleaned
⇒ 행의 모든 데이터가 비어 있으면 drop -
데이터가 없는 최소 개수를 정해서 sample을 drop
df.dropna(axis=1, thresh=3) : 데이터가 최소 4개 이상 없을 때 drop
df.dropna(thresh=5) : 5개 이상의 데이터가 있지 않으면 drop -
데이터가 거의 없는 feature는 feature 자체를 drop
데이터 채우기
df.fillna(0) : 데이터가 없는 곳에 0으로 집어 넣는다. But 이렇게 사용하면 안된다.

- 최빈값, 평균값으로 비어있는 데이터를 채우기
1) 평균값 사용

2) groupby로 transform을 사용

2. Category data
- One-Hot Encoding
import pandas as pd
import numpu as np
edges = pd.DataFrame({'source' : [0,1,2],
'target' : [2,2,3],
'weight' : [3,4,5],
'color' : ['red,'blue,'blue']})
👉 ordinary data일 경우 딕트 타입을 만들어 map을 시켜준다

3. Feature scaling
두 변수 중 하나의 값의 크기가 독보적으로 차이 날 때 사용
👉 Feature 간 최대-최소값의 차이를 맞춘다.
-
Min-Max Normalization
일반적으로 변수의 범위를 0과 1사이의 값으로 변경

-
Standardization(Z-score Normalization)
기존 변수에 범위를 정규 분포로 변환
실제 Min-Max 값을 모를때 활용 가능

-
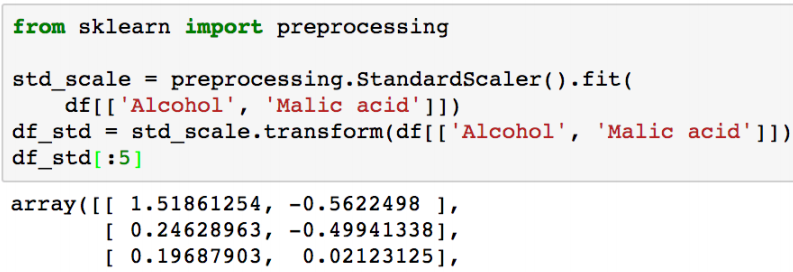
Feature scaling with sklearn
MinMaxScaler와 StandardScaler를 사용
1) StandardScaler
 2) MinMaxScaler
2) MinMaxScaler
Preprocessing은 모두 fit - transform의 과정을 거친다(label encoder와 동일)
단, scaler는 한번에 여러 column을 처리 가능

