1. Overfitting
학습데이터를 과다하게 최적화 하여 새로운 데이터의 예측률을 떨어뜨린다.
너무 많은 파라미터를 만들면 데이터가 너무 정확하게 최적화되기 때문에 overfitting 현상이 발생한다.
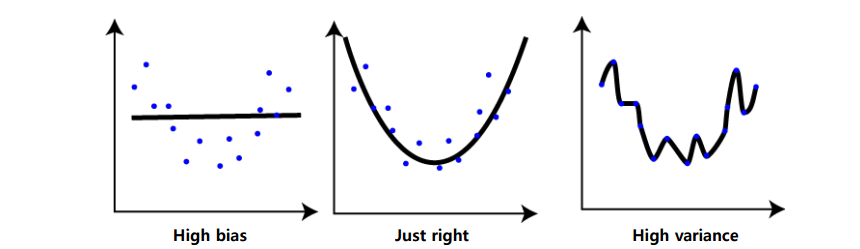 High bias : 잘못된 데이터로 계속 학습을 해서 원래 모델에 많이 떨어진 상태(=under fitting)
High bias : 잘못된 데이터로 계속 학습을 해서 원래 모델에 많이 떨어진 상태(=under fitting)
High variance : 모든 데이터에 민감하게 학습되어서 원래 데이터와의 차이가 크다.
2. Overcoming Overfitting
데이터의 개수를 늘린다.
Feature의 개수를 줄인다.
적절히 parameter를 정한다.
Regularization
3. L2 Regularization
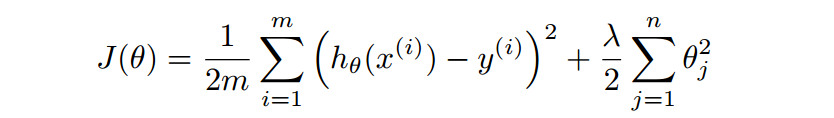 penalty term을 추가
penalty term을 추가
norm : 벡터의 길이 or 크기 측정
α: running rate
λ : 1~0의 값
m : 데이터의 개수

Data Engineer