1. Gradient descent
hyper parameter(사용자가 직접 세팅해주는 값)를 설정해주기 위해 gradient descent 알고리즘을 이해해야 한다.
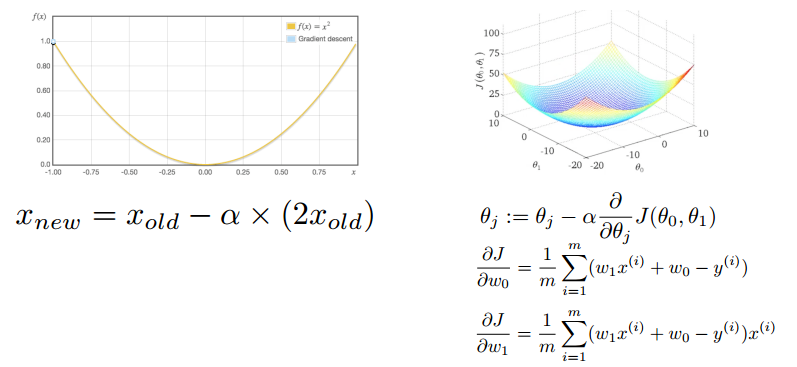 ↑ 왼쪽 : Gradient descent 오른쪽 : Full-batch Gradient descent
↑ 왼쪽 : Gradient descent 오른쪽 : Full-batch Gradient descent
- Full-batch gradient descent
일반적으로 GD(Gradient Descent) = (full) batch GD라고 가정한다.
모든 데이터 셋으로 학습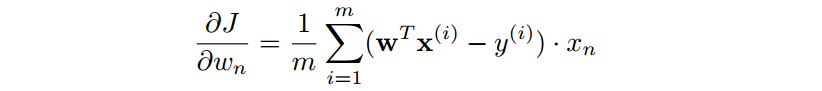
업데이트 감소로 계산상 효율성 높아진다.
안정적인 Cost 함수로 수렴한다.
큰 데이터를 한번에 test하므로 메모리 문제가 발생할 수 있다.
대규모 dataset으로 모델/파라미터 업데이트가 느려진다.
👉 그래서 stochastic gradient descent를 사용한다.
2. Stochastic gradient descent
dataset에서 random하게 training sample을 뽑은 후 학습할 때 사용한다.
 데이터를 넣기 전에 Shuffle
데이터를 넣기 전에 Shuffle
일부 문제에 대해선 빠르게 수렴하지만 너무 빈번하게 업데이트를 하면서 속도가 오래걸린다.
그래서 mini-batch SGD를 사용한다.
3. Mini-batch SGD
한번의 일정량의 데이터를 랜덤하게 뽑아서 학습한다.
SGD와 Batch GD를 혼합한 기법으로 가장 일반적으로 많이 사용된다.
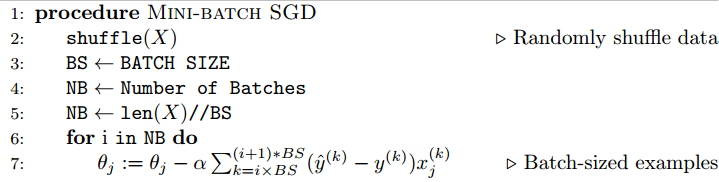 Epoch : 전체 데이터가 Training에 들어가는 횟수 (1epoch = full-batch가 한 번 돈것)
Epoch : 전체 데이터가 Training에 들어가는 횟수 (1epoch = full-batch가 한 번 돈것)
batch-size : 한 번에 학습되는 데이터의 개수
Q. 총 5,120개의 Training data에 512 batch-size면 몇 번 학습을 해야 1 epoch이 되는가?
A. 10번
4. SGD 구현할 때 발생하는 이슈
-
Mini-Batch SGD

if is_SGD = SGD일 때 True로 shuffle (SGD는 처음에 값을 셔플링 시켜준다.)
BATCH_SIZE가 full-batch이면 배치 사이즈는 number of data로 데이터의 개수만큼 X_batch 생성한다. -
Covergence process
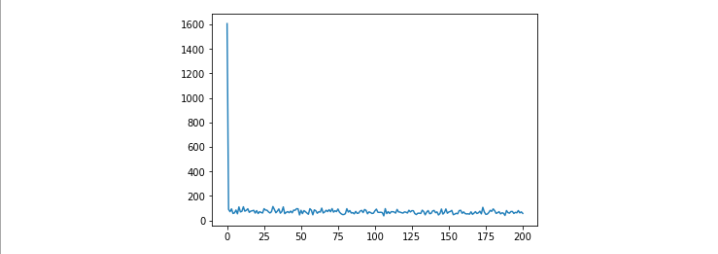 SGD의 경우 랜덤하게 값을 돌리기 때문에 데이터가 튀는 모습을 볼 수있다.
SGD의 경우 랜덤하게 값을 돌리기 때문에 데이터가 튀는 모습을 볼 수있다. -
Learning-rate decay
한 번 이동할 때(특정 epoch마다) 조금씩 learning-rate를 줄여주면 정확히 학습할 수 있다.
즉 Learning-rate decay : 일정한 주기로 Learning rate를 감소
✔ 종료조건 설정
SGD에서 특정 값이하로 cost function이 줄어들지 않을 경우 GD를 멈춘다.
성능이 좋아질 필요 없는 연산을 방지한다.
tol> loss-previous_loss (tol은 hyperparameter로 사람이 설정)
