from typing import Dict, Text
import tensorflow as tf
import tensorflow_datasets as td
import tensorflow_recommenders as tr
import numpy as np
from pprint import pprint
import matplotlib.pyplot as plt
# tensorflow_datasets -> train, test로 나눠져있음
ratings = td.load('movielens/100k-ratings', split = 'train')
movies = td.load('movielens/100k-movies', split ='train')
# tensorflow_datasets 사용 (데이터가 많음) 
# as_numpy_iterator -> 데이터세트 전체를 numpy로 변환하는 반복문
for x in ratings.take(1).as_numpy_iterator():
pprint(x) # ratings
# as_numpy_iterator -> 데이터세트 전체를 numpy로 변환하는 반복문
for y in movies.take(1).as_numpy_iterator():
pprint(y) # movies


ratings = ratings.map(lambda x: {
'movie_title': x['movie_title'],
'user_id': x['user_id']
})
movies = movies.map(lambda x: x['movie_title'])
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
# train, test split -> 8 : 2
movie_titles = movies.batch(1_000)
# batch 는 개수를 맞춰주는 방법
user_ids = ratings.batch(1_000_000).map(lambda x: x['user_id'])
unique_movie_titles = np.unique(np.concatenate(list(movie_titles)))
# movie_title는 shape 형태로만 나와서 list로 담고
#tensor 형태를 np.concatenate 배열을 합쳐 unique값만 출력
unique_user_id = np.unique(np.concatenate(list(user_ids)))
# movie_title는 shape 형태로만 나와서 list로 담고
#tensor 형태를 np.concatenate 배열을 합쳐 unique값만 출력
embedding_dimension = 32
# 값이 높을 수록 정확하지만 속도가 느리고 과적합 되기 쉽다.
user_model = tf.keras.Sequential([
tf.keras.layers.StringLookup(vocabulary=unique_user_id, mask_token=None),
# stringlookup -> word embedding 과 같이 data-value들이 index로 표현되게 하는 함수
#mask_token=None -> 마스킹 용어가 추가 되지않게 하는 방법 (1 ~ oov+1)에서 (0~ oov) 으로 인덱싱
tf.keras.layers.Embedding(len(unique_user_id)+1, embedding_dimension)
#tf.keras.layers.Embedding(input_dim, output_dim)
# input_dim -> 최대크기의 정수 , output_dim -> 결과값이 몇개 나올지
])
movie_model = tf.keras.Sequential([
tf.keras.layers.StringLookup(vocabulary=unique_movie_titles, mask_token=None),
tf.keras.layers.Embedding(len(unique_movie_titles) + 1, embedding_dimension)
])
metrics = tr.metrics.FactorizedTopK(candidates=movies.batch(128).map(movie_model))
# 매트릭 평가를 위해 후보 데이터 세트
task = tr.tasks.Retrieval(metrics=metrics)
#계산된 손실을 반환하는 계층class tr_model(tr.Model):
def __init__(self, user_model, movie_model):
super().__init__()
self.movie_model : tf.keras.Model = movie_model
self.user_model : tf.keras.Model = user_model
self.task: tf.keras.layers.Layer = task
def compute_loss(self, features: Dict[Text, tf.Tensor], training=False) -> tf.Tensor:
user_embeddings = self.user_model(features['user_id'])
movie_embeddings = self.movie_model(features['movie_title'])
return self.task(user_embeddings, movie_embeddings)
model = tr_model(user_model, movie_model)
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.1))
cached_train = train.shuffle(100_000).batch(8192).cache()
# 값을 캐싱을 하지않으면 적용이 안됨
# 아직 이유를 몰라서 공부를 더 해야알것같음
cached_test = test.batch(4096).cache()
history = model.fit(cached_train, epochs=5)
def show_train_history(hisData,first,second):
plt.plot(hisData.history[first])
plt.plot(hisData.history[second])
plt.title('Training History')
plt.ylabel(first)
plt.xlabel('Epoch')
plt.legend([first, second], loc='upper left')
plt.show()
# 시각화 진행
show_train_history(history, 'factorized_top_k/top_50_categorical_accuracy', 'factorized_top_k/top_100_categorical_accuracy')
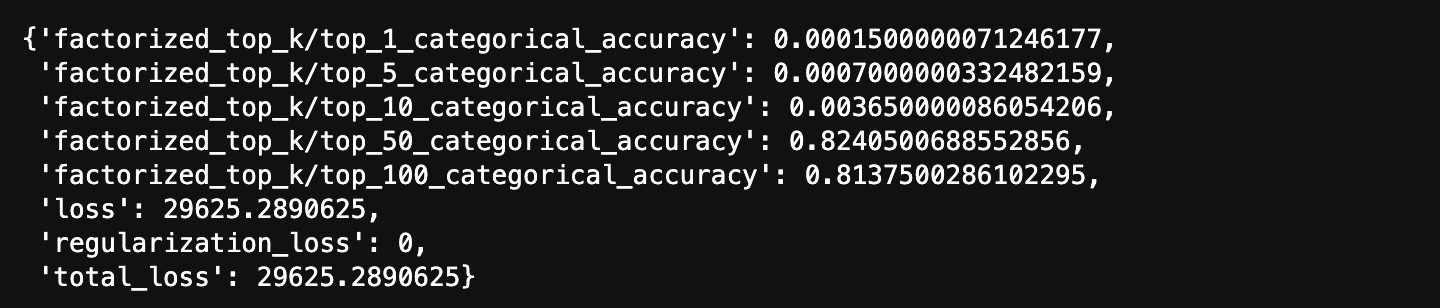
test_history = model.evaluate(cached_test, return_dict = True)
# Test evaluate를 진행해 봤는데 epochs 수가 적어서 그런지
# 아쉽게도 top10 밑으로는 예측점수가 그렇게 높지않았다.
# 다음에는 epochs 수도 늘리고 어떤 데이터를 추천을 해주는지를 시연해봐야겠다.

호기심천국