Tensorflow 기본이 되는 cifar10 데이터를 이용해 기본기 다지기 🤔
(Alexnet 직접 구현해보기)
import tensorflow as tf
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, BatchNormalization, Dense, Dropout
from tensorflow.keras.models import Sequential
from tensorflow.keras import layers
from sklearn.metrics import classification_report, confusion_matrix, ConfusionMatrixDisplay
# CounfusionMatrixDisplay(매트릭스 시각화를 위해 불러오기)
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
x_train, x_test = x_train / 255., x_test / 255.
## Alexnet을 직접 구현
model = Sequential()
model.add(layers.experimental.preprocessing.Resizing(244, 244, interpolation="bilinear", input_shape=x_train.shape[1:]))
model.add(Conv2D(96, kernel_size=(11, 11), strides=4, activation='relu', padding='same'))
model.add(MaxPooling2D((5, 5), strides=2))
model.add(BatchNormalization())
model.add(Conv2D(256, kernel_size=(5, 5), strides=1, activation='relu', padding='same'))
model.add(MaxPooling2D((3, 3), strides=2))
model.add(BatchNormalization())
model.add(Conv2D(384, kernel_size=(3, 3), strides=1, activation='relu', padding='same'))
model.add(Conv2D(384, kernel_size=(3, 3), strides=1, activation='relu', padding='same'))
model.add(Conv2D(256, kernel_size=(3, 3), strides=1, activation='relu', padding='same'))
model.add(MaxPooling2D((3, 3), strides=2))
model.add(BatchNormalization())
model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
# 10가지 labelmodel.summary()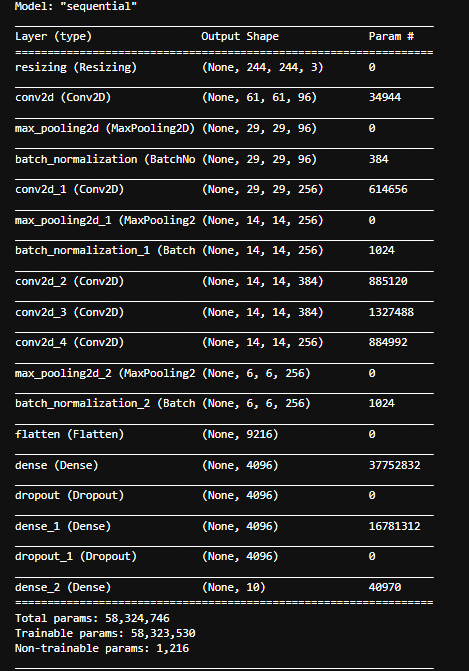
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy', metrics =['accuracy'])
history = model.fit(x_train, y_train, epochs=10, batch_size=200, validation_data=(x_test, y_test), validation_batch_size=200)
# epochs를 적게해서 결과가 썩 좋지는 않지만
# confusion matrix를 만들어 얼만큼 맞췄는지 확인하기 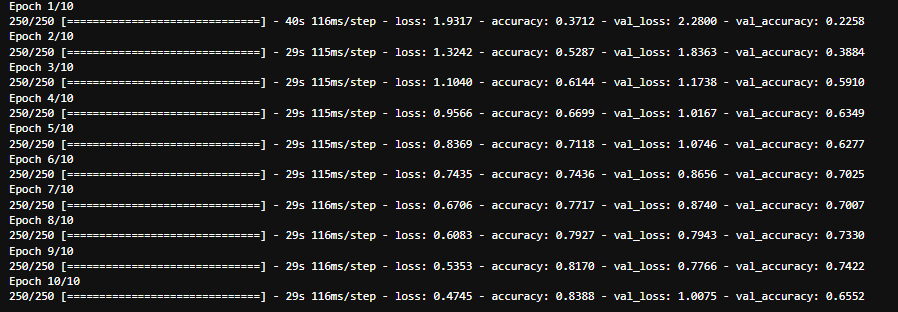
import matplotlib.pyplot as plt
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epochs')
plt.ylabel('loss')
plt.legend(['train', 'test'], loc = 'upper left')
plt.show()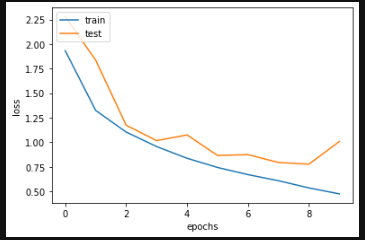
import numpy as np
x = model.predict(x_test)
y_pred = np.argmax(x, axis=1)
x = model.predict(x_test)
y_pred = np.argmax(x, axis=1)
# np.argmax는 가장 확률이 높은 부분만 출력하기 위함
y_test = y_test.reshape(10000,)
#y_test.shape = (10000, 1)이여서 flatten하게 만들어
#classification_report, confusion_matrix 적용
print(classification_report(y_test, y_pred))
labels = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
display = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)
fig, ax = plt.subplots(figsize=(10, 10))
display.plot(xticks_rotation='vertical', ax=ax)
plt.show()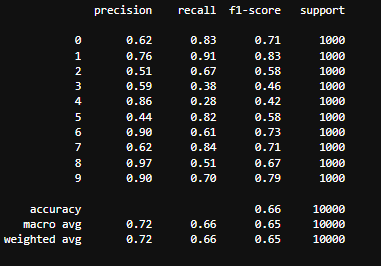
#조금 더 명확하게 확인하기 위해서 confusion-matrix를 활용
epochs 수가 적어서 고양이와 강아지를 구분을 잘 못하는 걸로 확인 ..
epochs 수를 늘려보거나 모델 로직을 다르게 해봐야겠습니다.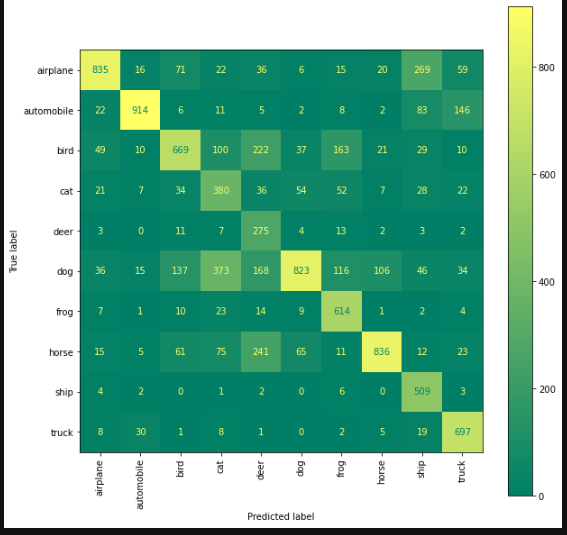

호기심천국