Sort
버블 정렬 (Bubble)
- 시간 복잡도 O(n²)
- 매번 연속된 두개 인덱스를 비교하여 값을 뒤로 넘겨 정렬한다.
선택 정렬 (Selection)
- 시간 복잡도 O(n²)
- 맨 앞부터 순회를 하면서 가장 작은 값을 찾아서 배열의 검사한 앞 위치와 교환한다.
삽입 정렬 (Insertion)
- 1부터 n까지 Index를 설정하여 두 번쨰 인덱스 부터 시작하여 현재 위치의 값과 비교 인덱스를 비교하여 알맞은 위치에 넣어줌.
- 자기보다 왼쪽의 수가 작을때까지 이동
- 정렬된 경우 O(n), 정렬되지 않았다면 O(n²)
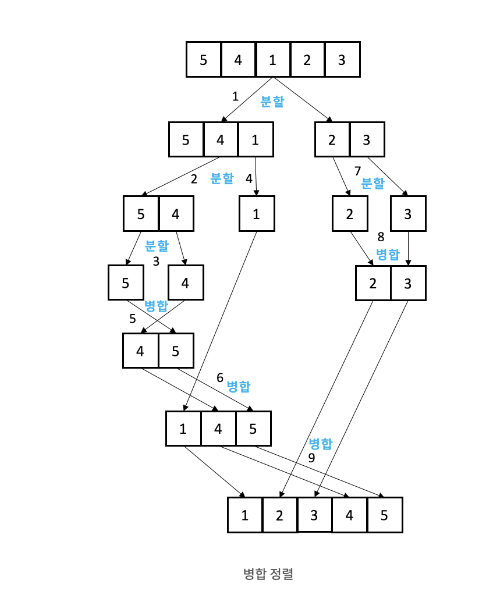
병합 정렬 (Merge)
- 정렬할 리스트를 반으로 쪼개나가며 좌측과 우측 리스트를 계속하여 분할한 뒤 리스트 내에서 정렬 후 병합하는 과정으로 정렬
- 시간 복잡도는 최소 O(nlogn)
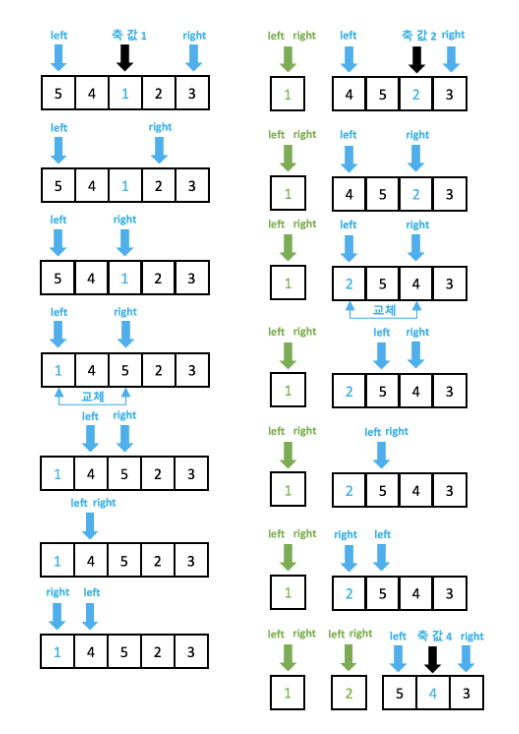
퀵 정렬 (Quick)
- real-world에서 가장 빠르다고 알려져서 가장 많이 쓰인다.
- pivot을 선정하여 pivot을 기준으로 좌측과 우측으로 pivot보다 작은값은 왼쪽, pivot보다 큰 값은 오른쪽으로 재배치하고 계속하여 분할하여 정렬한다.
- pivot은 맨 앞, 혹은 맨 뒤, 전체 배열 중간값 혹은 랜덤 값으로 정한다.
- 최악의 경우 O(n²), 평균 O(nlogn)
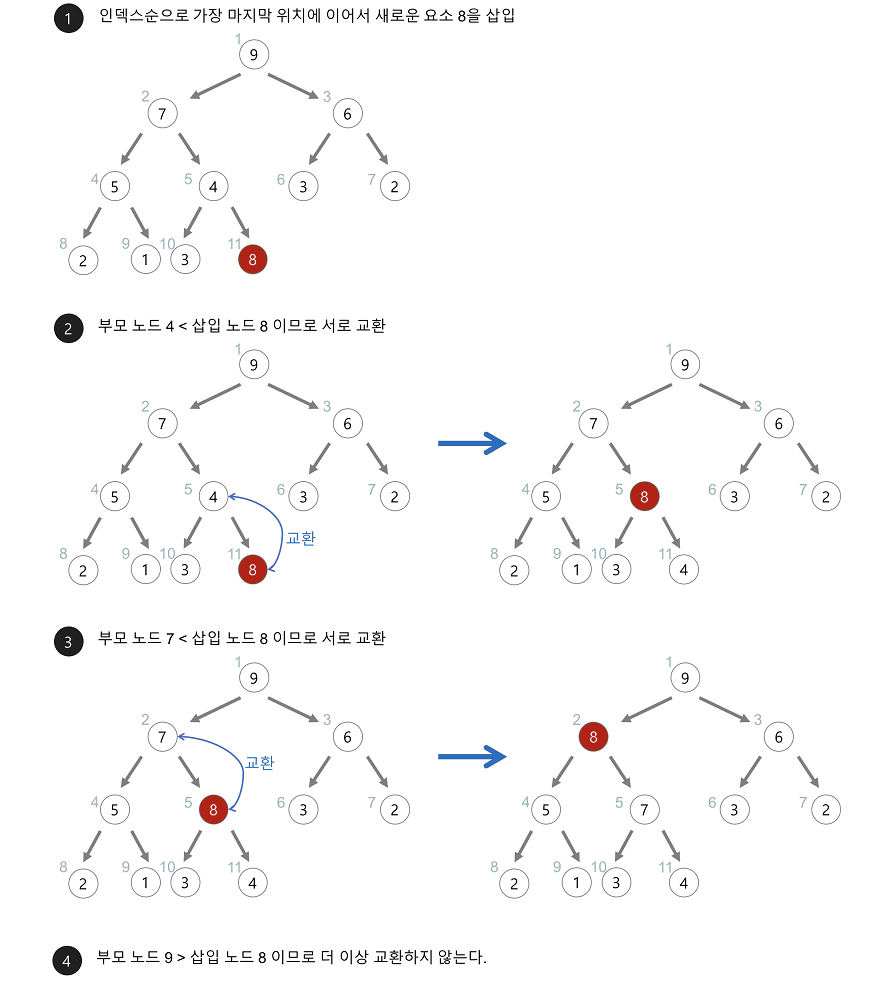
힙 정렬 (Heap)
- 힙 자료구조로 만들어 최대값 또는 최소값부터 하나씩 꺼내서 정렬
- 시간 복잡도는 O(nlogn)
추가
Quick Selection [ n개의 배열에서 k(k<=n) 번째로 큰수를 찾는 알고리즘 ]
이러한 문제를 해결하기 위해 일반적으로 퀵정렬을 사용합니다. 하지만 퀵정렬을 사용하면 정렬이 불필요한 부분들을 정렬하면서 효율적이지 못하게 됩니다. 퀵선택 알고리즘은 퀵정렬을 한번 한 후에 결정된 피봇의 인덱스와 K를 비교하여 아래와 같이 수행합니다.
- pivot의 인덱스가 k와 같은 경우 : 그대로 그 인덱스의 값을 리턴하면 된다.
- pivot의 인덱스가 k보다 작은 경우 : pivot의 인덱스+1부터 마지막 인덱스까지 다시 Partition함수에 넘겨준다.
- pivot의 인덱스가 k보다 큰 경우 : 첫번째 인덱스부터 pivot의 인덱스-1까지 다시 Partition함수에 넘겨준다.
퀵정렬 알고리즘과의 다른 점은 예를 들어 Pivot의 인덱스가 7이고 K가 5인 경우에, 피봇의 오른쪽 부분은 재귀 함수를 돌지 않아 한 쪽만으로 재귀를 진행하는 것입니다.
이러한 이유로 퀵선택 알고리즘의 시간복잡도는 𝑛+𝑛/2+4/𝑛+....1=𝑂(𝑛) 입니다.

출처: https://mangkyu.tistory.com/90 [MangKyu's Diary]

프론트엔드 개발자 남준영입니다.