자료구조
배열 (Array)
- 인덱스 번호가 부여, 생성시 셀의 수가 고정된다.
- 추가,삭제시 시간 복잡도 O(n)
- 인덱스를 알고 있다면 O(1)로 원소에 접근 가능
장점
- 인덱스로 인한 탐색이 용이.
단점
- 메모리 크기가 고정되어 있다.
- 데이터 추가/ 삭제시 비효율적이다.
연결 리스트 (Linked list)
- 데이터의 물리적 배치를 사용하지 않는다.
- Index나 위치보다 참조 시스템을 사용.
- 각 요소는 노드에 저장되며, 다음 노드 연결에 대한 포인터 또는 주소가 포함된 또 다른 노드에 저장된다.
- 데이터 추가 삭제 시 재구성이 필요없어 효율적이다.
- 추가 , 삭제시 O(1)
장점
- 새로운 요소들의 추가 및 삭제가 용이하고 효율적이다.
- 메모리에 연속적으로 위치하지 않는다. 재구성이 필요없다.
- 동적인 메모리 크기
- 메모리 크기가 정해지지 않을 때, 연속적으로 삽입 제거를 할 경우, 갤러리, 음악 플레이어 등등
단점
- 연결을 위한 별도 데이터 공간이 필요하므로, 저장 공간 효율이 높지는 않다.
- 탐색시 비효율적으로 검색/가져온다.
데이터 삽입,삭제가 쉽기고 데이터 재구성이 용이해서 대용량 데이터처리에 좋다???
스택 (Stack)
- 순서가 보존되는 선형 데이터 구조
- LIFO (Last In First Out)
- 추가 , 삭제시 O(1)
장점
- 동적인 메모리 크기
- 받는 순서대로 정렬
- 브라우저 뒤로가기, 재귀, 실행 취소 등에서 사용됨
단점
- 한번에 하나의 데이터만 처리 가능하다.
큐 (Queue)
- FIFO(First In First Out)
- 추가 , 삭제시 O(1)
장점
- 동적인 메모리 크기
- 받는 순서대로 정렬
- 캐시, 비동기적 처리, 프린트 대기열에서 사용
단점
- 한번에 하나의 데이터만 처리 가능하다.
해시 테이블 (Hash table / Hash map)
- Key를 통해 효율적으로 검색할 수 있다.
- Key / value의 쌍을 저장한다.
- Key를 저장할 때 메모리 공간을 효율적으로 사용하기 위해 Key를 해시 함수를 통해 hash라는 특정한 숫자값으로 변환한다. 해시 테이블은 필요할 때만 메모리 크기를 늘리고, 가능한 작은 크기를 유지한다.
Hash code를 배열의 Index로 사용한다. 해당 Index에 data를 넣는다.

장점
- 동적인 메모리 크기
- 검색 속도가 빠르다. (저장/읽기 속도)
- 새로운 요소 추가/삭제가 용이
- 중복 확인이 쉽다. 제거 굿
- 데이터 캐싱에 많이 사용됨.
- 검색이 많은 경우, 저장-삭제-읽기가 많은 경우,캐시 구현시
단점
- 충돌이 일어날 수 있다. (입력된 키의 해시값이 저장된 경우)
- 공간 복잡도가 커진다.
- 순서가 있는 배열에는 어울리지 않는다.
- 해시 함수 의존도가 높다.
=> Hash 중복이 일어날 경우 (=> 해시 함수로 변환후 값이 같아질 경우 충돌(Collision)이라고 한다.
해결 방안
1) Separating Chaining
- LinkedList (or Tree)
- 인덱스가 충돌이 날 때, 인덱스가 가리키고 있는 linked list에 노드를 추가하여 값을 삽입
- 추가할 수 있는 데이터 수의 제약이 있다.
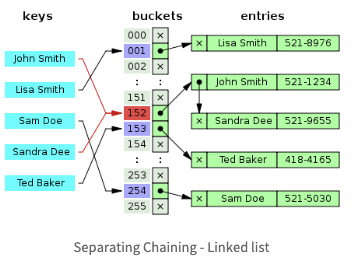
2) Open addressing - hash tabke array의 빈공간 사용.
- Separating 보다 메모리를 덜 사용한다.
- 빈 버켓을 찾아서 뒤에 index에 넣는다. 단, 삭제가 어려움.
추가로 참고해서 더 볼 것!!

(https://hee96-story.tistory.com/48)
트리 (Tree)
- 최상위 노드(루트)를 만들고 child가 있는 계층적 자료구조
대용량 데이터 저장시 많이 쓰인다? B-트리
트리 구조와 관련하여 반드시 알아야 할 개념들:
- Node: 트리에서 데이터를 저장하는 기본 요소 (데이터와 다른 연결된 노드에 대한 Branch 정보 포함)
- Root Node: 트리 맨 위에 있는 노드
- Level: 최상위 노드를 Level 0으로 하였을 때, 하위 Branch로 연결된 노드의 깊이를 나타냄
- Parent Node: 어떤 노드의 다음 레벨에 연결된 노드
- Child Node: 어떤 노드의 상위 레벨에 연결된 노드
- Leaf Node (Terminal Node): Child Node가 하나도 없는 노드
- Sibling (Brother Node): 동일한 Parent Node를 가진 노드
- Depth: 트리에서 Node가 가질 수 있는 최대 Level
이진 탐색 트리의 장점과 주요 용도
주요 용도: 데이터 검색(탐색)
장점: 탐색 속도를 개선할 수 있음 O(logn)
단점: 최악의 경우 O(n) 한쪽으로 있는 경우
B-Tree
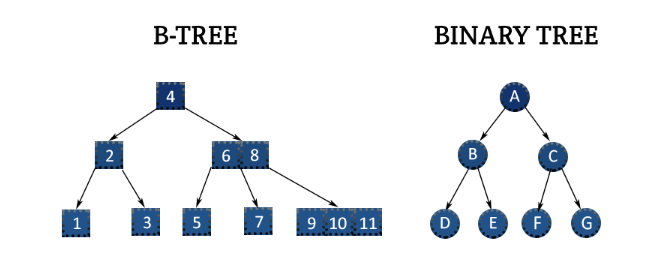
- 대용량 데이터를 위한 구조
- 자식노드 두개만 가지는 이진 트리를 확장하여 더 많은 자식 노드를 갖게 함.
- 노드수가 N이면, 자식수는 N+1
- 각 노드의 자료는 정렬된 상태이며 왼쪽 서브트리는 부모보다 작은 값, 오른쪽 서브트리는 부모보다 큰값.
- 삽입시 중간의 키를 기준으로 두가지 노드로 나눠진다. 가운데 키를 부모로 올린다.
- 대량의 데이터는 메모리보다 하드디스크 혹은 SSD에 저장되어야 하는데 외부 기억 장치들은 블럭 단위로 입출력 한다.(1 블럭 1024바이트을 꽉 채우는게 효율적). 따라서 B-tree는 데이터베이스 시스템의 인덱스 저장 방법으로 애용된다.
- 같은 노드 공간의 데이터들을 참조 포인트로 접근할 필요가 없이 실제 메모리 디스크에서 바로 다음 인덱스를 빠르게 접근 가능하다.
최악의 경우에도 O(logN) => DB Index에서 사용하는 이유
결론적으로 DB 인덱스로 B-Tree가 가장 적합한 이유들을 정리하면 아래와 같다.
- 항상 정렬된 상태로 특정 값보다 크고 작은 부등호 연산에 문제가 없다.
- 참조 포인터가 적어 방대한 데이터 양에도 빠른 메모리 접근이 가능하다.
- 데이터 탐색뿐 아니라, 저장, 수정, 삭제에도 항상 O(logN)의 시간 복잡도를 가진다.
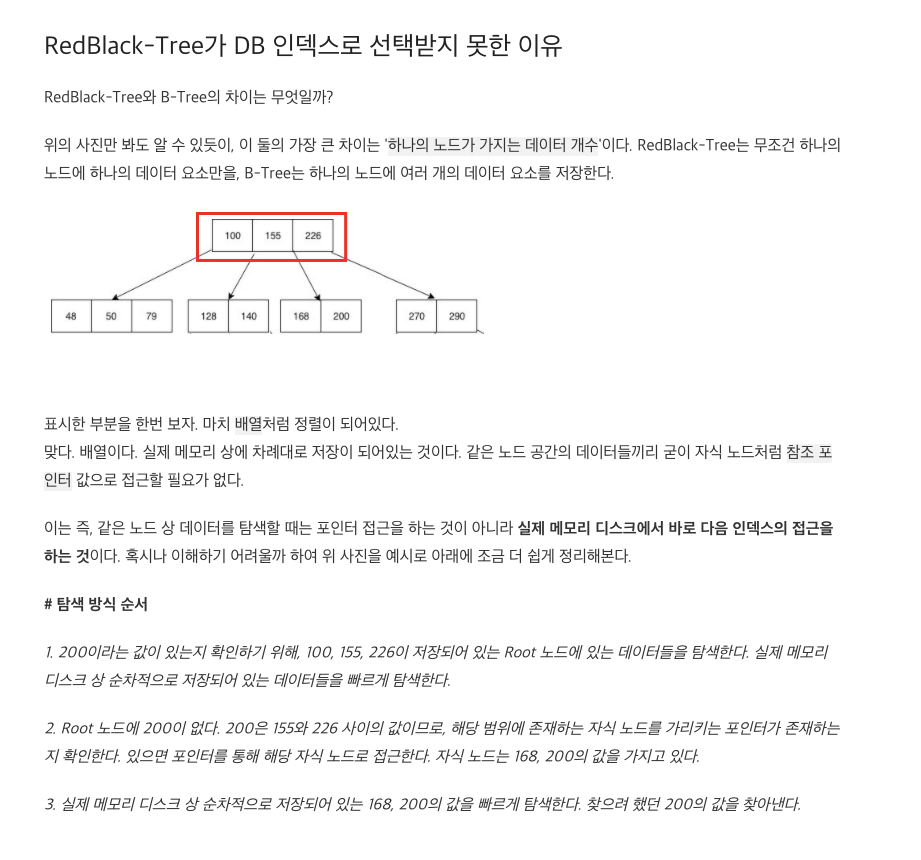
Red-black 트리
- RedBlack-Tree는 무조건 하나의 노드에 하나의 데이터 요소만 저장해야 한다. (B-tree는 하나의 노드에 여러개 요소 저장 가능)
- Redblack은 데이터를 접근할 때 무조건 참조 포인터로 접근해야 한다. 시간 복잡도는 O(logN)으로 동일하나 실제로는 차이가 난다.
힙 (Heap)
- 데이터에서 최대값과 최소값을 빠르게 찾기 위해 고안된 완전 이진 트리(Complete Binary Tree)
- 완전 이진 트리: 노드를 삽입할 때 최하단 왼쪽 노드부터 차례대로 삽입하는 트리
힙을 사용하는 이유
- 배열에 데이터를 넣고, 최대값과 최소값을 찾으려면 O(n) 이 걸림
- 이에 반해, 힙에 데이터를 넣고, 최대값과 최소값을 찾으면, 𝑂(logn)
- 우선순위 큐와 같이 최대값 또는 최소값을 빠르게 찾아야 하는 자료구조 및 알고리즘 구현 등에 활용됨
힙의 구조
- 힙은 최대값을 구하기 위한 구조 (최대 힙, Max Heap) 와, 최소값을 구하기 위한 구조 (최소 힙, Min Heap) 로 분류할 수 있음
- 각 노드의 값은 해당 노드의 자식 노드가 가진 값보다 크거나 같다. (최대 힙의 경우)
- 최소 힙의 경우는 각 노드의 값은 해당 노드의 자식 노드가 가진 값보다 크거나 작음
- 완전 이진 트리 형태를 가짐
힙과 이진 탐색 트리의 차이점
- 공통점: 힙과 이진 탐색 트리는 모두 이진 트리임
- 차이점:
- 힙은 각 노드의 값이 자식 노드보다 크거나 같음(Max Heap의 경우)
- 이진 탐색 트리는 왼쪽 자식 노드의 값이 가장 작고, 그 다음 부모 노드, 그 다음 오른쪽 자식 노드 값이 가장 큼
힙은 이진 탐색 트리의 조건인 자식 노드에서 작은 값은 왼쪽, 큰 값은 오른쪽이라는 조건은 없음
- 힙의 왼쪽 및 오른쪽 자식 노드의 값은 오른쪽이 클 수도 있고, 왼쪽이 클 수도 있음
=> 이진 탐색 트리는 탐색을 위한 구조, 힙은 최대/최소값 검색을 위한 구조
시간 복잡도
O(logN)

프론트엔드 개발자 남준영입니다.