Deep Learning: 신경망의 기초 - 기계학습 III
1.4 간단한 기계 학습의 예
-
기계학습 요소
-
카드 승인 예제 및 요소

-
-
카드 승인 교사학습 예제
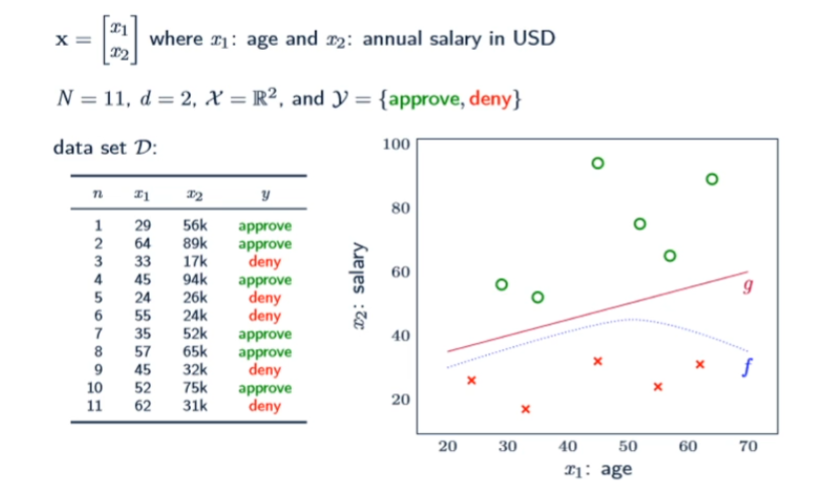
-
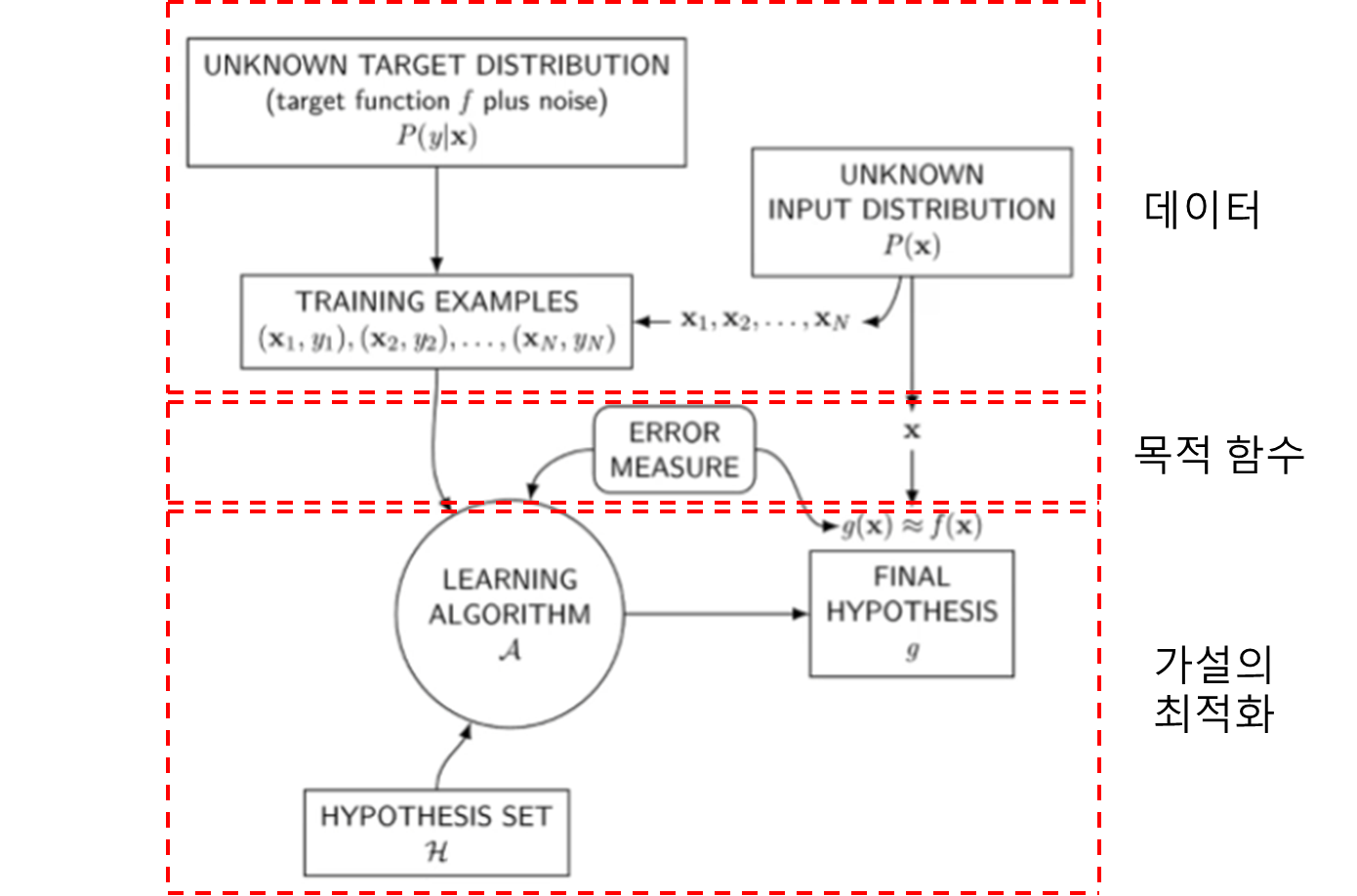
기계학습 설정
- 교사학습의 경우,
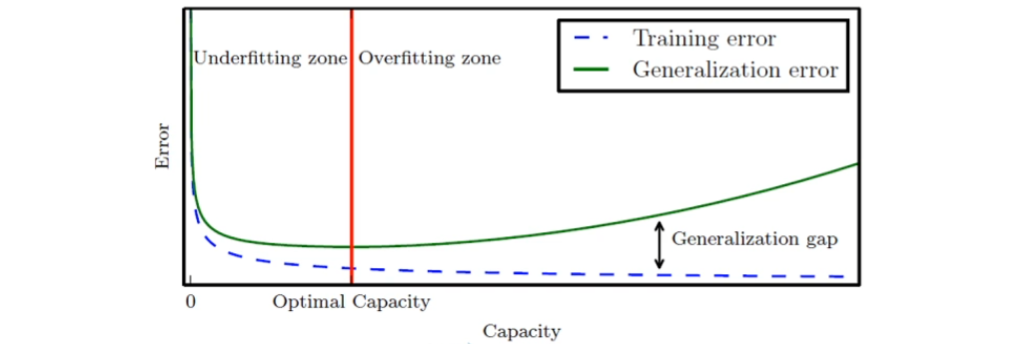
1.5.1 과소적합과 과잉적합
-
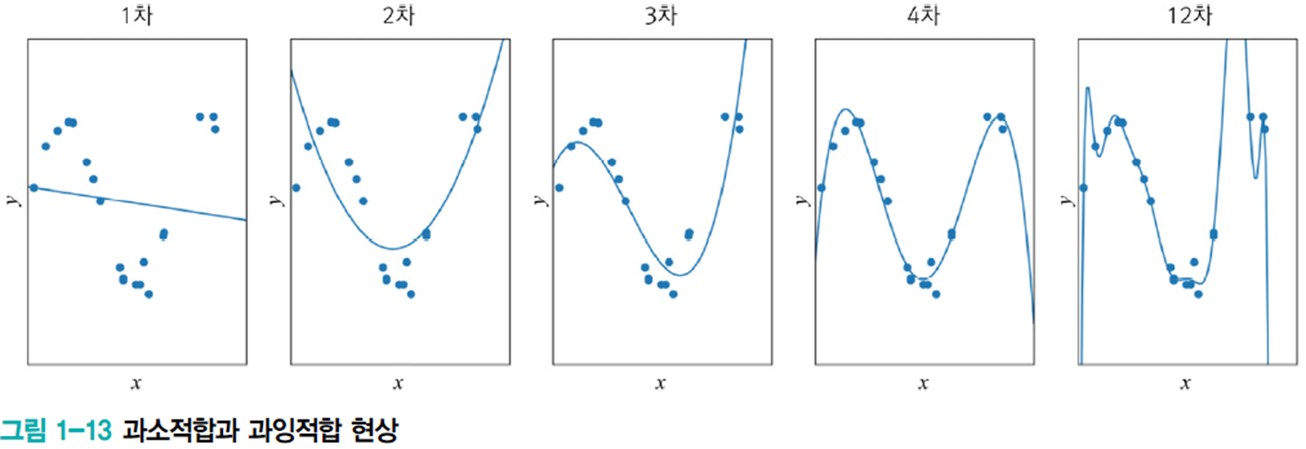
[그림 1.13]의 1차 모델은 과소적합underfitting
- 모델의 '용량이 작아' 오차가 클 수밖에 없는 현상
-
대안 : 비선형 모델을 사용
- [그림 1-13]의 2차, 3차, 4차, 12차는 다항식 곡선을 선택한 예
- 1차(선형)에 비해 오차가 크게 감소함
-
과잉적합overfitting
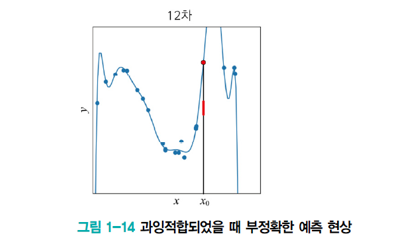
- 12차 다항식 곡선을 채택한다면 훈련집합에 대해 거의 완벽하게 근사화함
- 하지만 '새로운' 데이터를 예측한다면 큰 문제 발생
- x0에서 빨간 막대 근방을 예측해야 하지만 빨간 점을 예측
- 이유는 '모델의 용량capacity이 크기' 때문에 학습 과저에서 잡음까지 수용 -> 과잉적합 현상
- 훈련집합에 과몰입해서 단순 암기했기 때문
- 적절한 용량의 모델을 선택하는 모델 선택 작업이 필요함
-
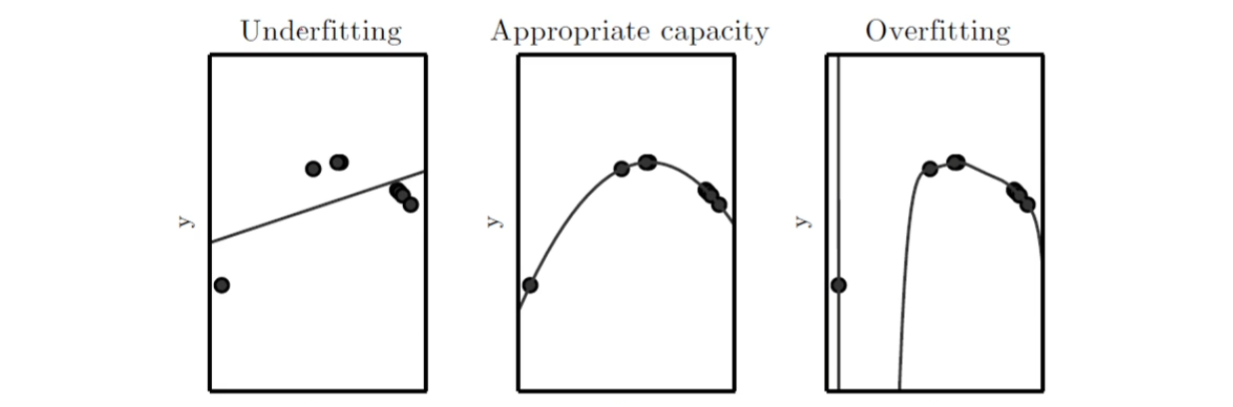
1차~12차 다항식 모델의 비교 관찰
- 1~2차는 훈련집합과 테스트집합 모두 낮은 성능
- 12차는 훈련집합에 높은 성능을 보이나 테스트집합에서는 낮은 성능 -> 낮은 일반화 능력
- 3~4차는 훈련집합에 대해 12차보다 낮겠지만 테스트집합에는 높은 성능 -> 높은 일반화 능력
-
모델의 일반화 능력과 용량 관계
-
훈련집합에 대한 세가지 모델 적합도 예
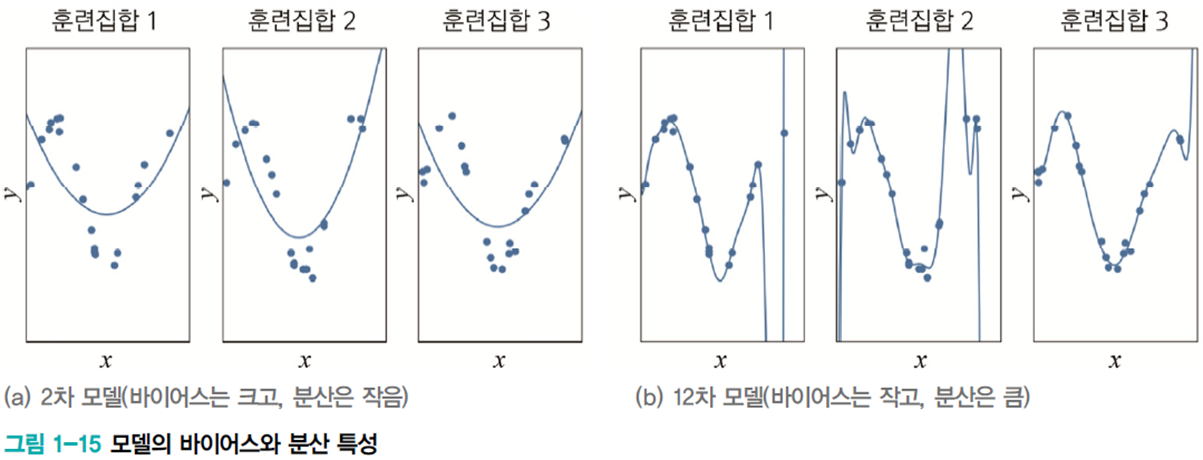
1.5.2 편향bias과 분산(변동)variance
-
훈련집합을 여러 번 수집하여 1차~12차에 적용하는 실험
- 2차는 매번 큰 오차 -> 바이어스가 큼. 하지만 비슷한 모델을 얻음 -> 낮은 분산
- 12차는 매번 작은 오차 -> 바이어스가 작음. 하지만 크게 다른 모델을 얻음 -> 높은 분산
- 일반적으로 용량이 작은 모델은 바이어스는 크고 분산은 작음.
복잡한 모델은 바이어스는 작고 분산은 큼 - 바이어스와 분산은 상충trade-off 관계
-
기계 학습의 목표
- 낮은 편향과 낮은 분산을 가진 예측 모델을 만드는 것이 목표 (왼쪽 아래)
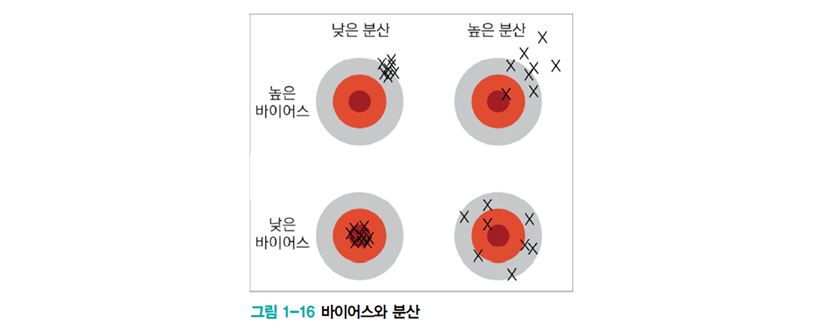
- 하지만 모델의 편향과 분산은 상충 관계
- 따라서 편향을 최소로 유지하며 분산도 최대로 낮추는 전략 필요
- 낮은 편향과 낮은 분산을 가진 예측 모델을 만드는 것이 목표 (왼쪽 아래)
-
편향과 분산의 관계
- 용량 증가 -> 편향 감소, 분산 증가 경향
- 일반화 오차 성능 (=편향+분산)은 U형의 곡선을 가짐
1.5.3 검증집합과 교차검증을 이용한 모델 선택 알고리즘
-
검증집합을 이용한 모델 선택
- 훈련집합과 테스트집합과 다른 별도의 검증집합validation set을 가진 상황(데이터의 양이 많을 경우)

-
교차검증cross validation
- 비용 문제로 별도의 검증집합이 없는 상황에 유용한 모델 선택 기법(데이터 양이 적을 경우)
- 훈련집합을 등분하여, 학습과 평가 과정을 여러 번 반복한 후 평균 사용
-
10겹 교차검증10-fold cross validation의 예
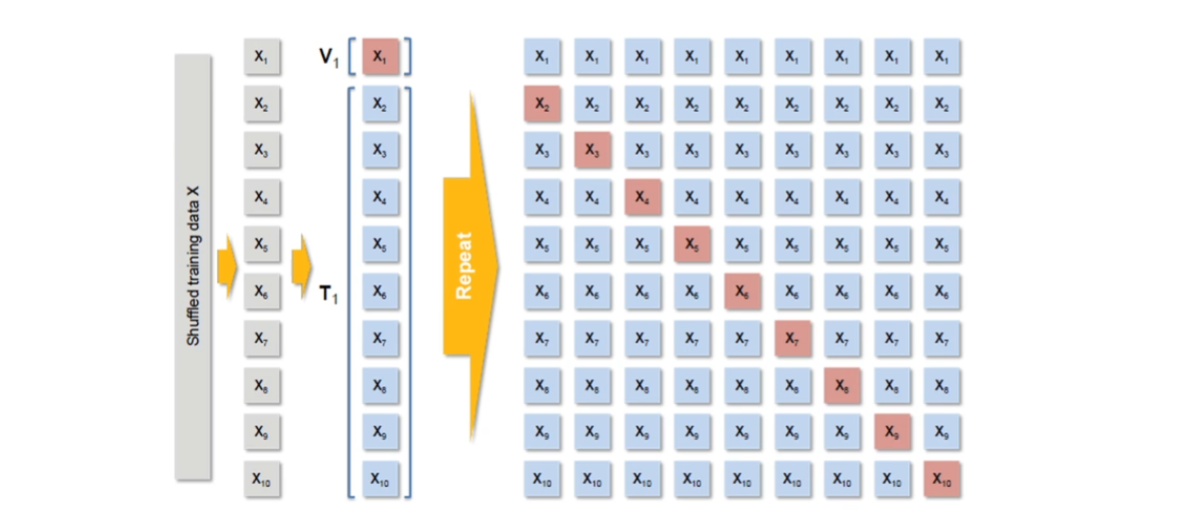
-
부트스트랩boot strap
- 임의의 복원 추출 샘플링sampling with replacement 반복
- 데이터 분포가 불균형일 때 적용
- 임의의 복원 추출 샘플링sampling with replacement 반복
1.5.4 모델 선택의 한계의 현실적인 해결책
- 현대 기계 학습의 전략
- 용량이 충분히 큰 모델을 선택 한 후,
선택한 모델이 정상을 벗어나지 않도록 여러 가지 규제regularization 기법을 적용함
- 용량이 충분히 큰 모델을 선택 한 후,
1.6 규제
1.6.1 데이터 확대
-
데이터를 더 많이 수집하면 일반화 능력이 향상됨
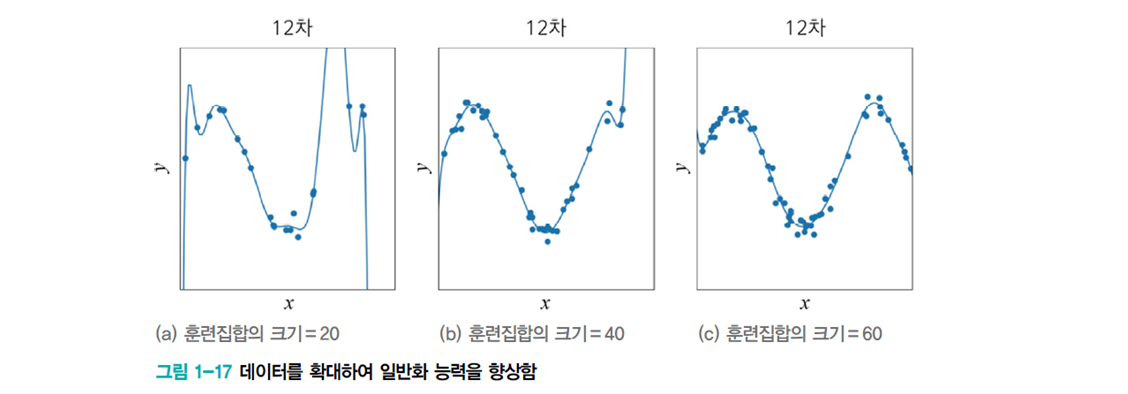
-
데이터 수집은 많은 비용이 듦
- 실측자료ground thruth를 사람이 일일이 표식labeling을 해야 함
-
인위적으로 데이터 확대data augmentation
- 훈련집합에 있는 샘플을 변형transform함
- ex) 약간 회전rotation 또는 왜곡warping (원 데이터의 부류 소속 등의 고유 특성이 변하지 않게 주의할 것)
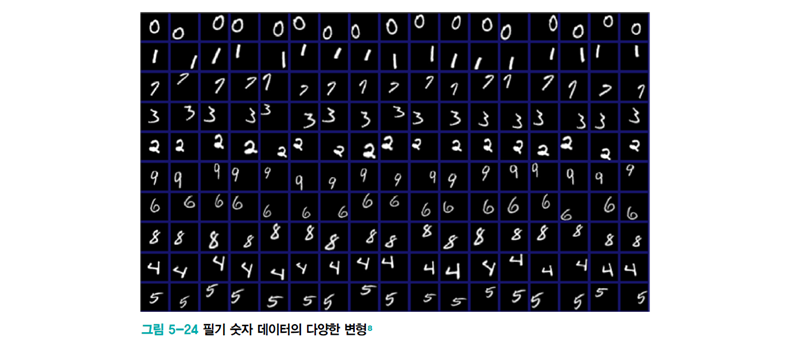
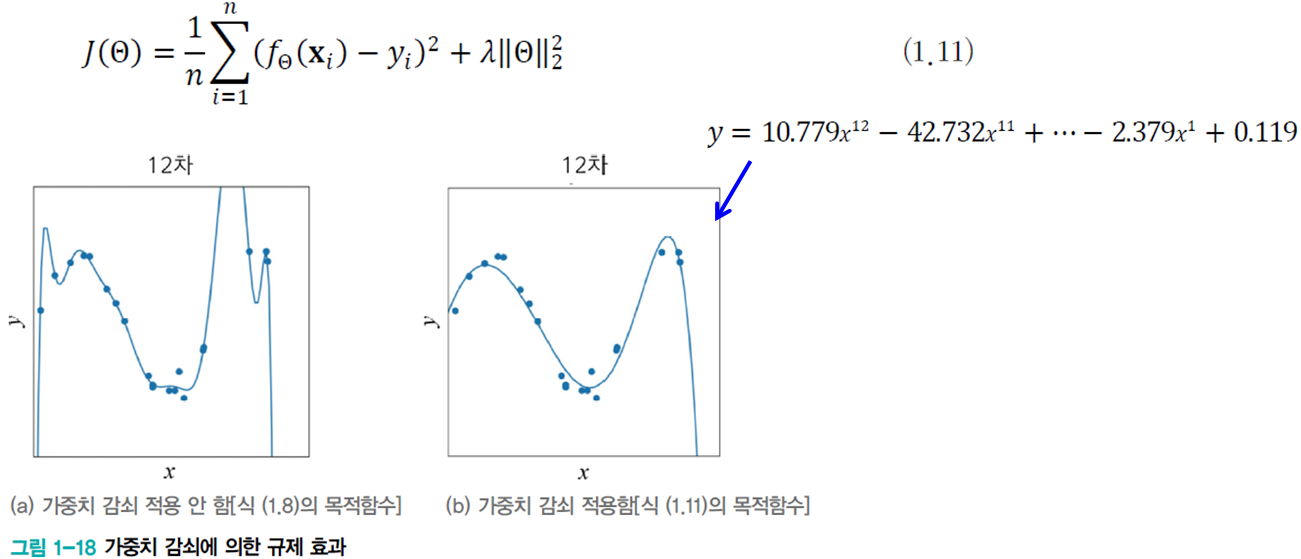
1.6.2 가중치 감쇠
-
가중치를 작게 조절하는 기법
-
[그림 1-18(a)]의 12차 곡선은 가중치가 매우 큼
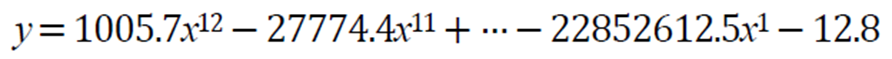
-
가중치 감쇠는 개선된 목적함수를 이용하여 가중치를 작게 조절하는 규제 기법
- 식 (1.11)의 두 번째 항은 규제 항으로서 가중치 크기를 작게 유지해줌
-
1.7.1 지도 방식에 따른 유형
- 지도 학습supervised learning
- 특징 벡터 𝕏와 목푯값 𝕐가 모두 주어진 상황
- 회귀regression와 분류classification 문제로 구분
- 비지도 학습unsupervied learning
- 특징 벡터 𝕏는 주어지는데 목푯값 𝕐 가 주어지지 않는 상황(정답 없음)
- 군집화clustering 과업 (고객 성향에 따른 맞춤 홍보 응용 등)
- 밀도 추정density estimation, 특징 공간 변환 과업(PCA)
-
강화 학습reinforcement learning
- (상대적) 목표치가 주어지는데, 지도 학습과 다른 형태임(==보상reward)
- ex) 바둑
- 수를 두는 행위가 샘플인데, 게임이 끝나면 목푯값 하나가 부여됨
-이기면 1, 패하면 -1을 부여 - 게임을 구성한 샘플들 각각에 목푯값을 나누어 주어야 함
- 수를 두는 행위가 샘플인데, 게임이 끝나면 목푯값 하나가 부여됨
-
준지도 학습
-
일부는 𝕏와 𝕐를 모두 가지지만, 나머지는 𝕏만 가진 상황
-
최근, 대부분의 데이터가 𝕏의 수집은 쉽지만, 𝕐는 수작업이 필요하여 최근 중요성 부각
1.7.2 다양한 기준에 따른 유형
-
오프라인 학습offline learning과 온라인 학습online learning
- 보통은 오프라인 학습을 다룸
- 온라인 학습은 IoT 등에서 추가로 발생하는 샘플을 가지고 점증적 학습 수행
-
결정론적 학습deterministic learning과 확률적 학습stochastic learning
- 결정론적에서는 같은 데이터를 가지고 다시 학습하면 같은 예측기가 만들어짐
- 스토캐스틱 학습은 학습 과정에서 난수를 사용하므로 같은 데이터로 다시 학습하면 다른 예측기가 만들어짐. 보통 예측 과정도 난수 사용
-
분별 모델discriminative models과 생성 모델generative models
- 분별 모델은 부류 예측에만 관심. 즉 P(y|x)의 추정에 관심
- 생성 모델은 P(x) 또는 P(x|y)를 추정함
- 따라서 새로운 샘플을 ‘생성’할 수 있음
