얻을만한 아이디어
- plug-in 방식으로 만들어진 것이라 차용해서 써볼만도 한 것 같다.
- EaTR처럼 각잡고 디코더를 개발한 것이 아니라 Loss만 추가해서 학습하는 것인데 어떤 것이 더 좋을지 생각해봐야할듯함
- LLM Encoder를 넣었을 때, 성능이 진짜 제대로 향상되는지도 테스트를 한번 해봐야될 것 같음
Contribution
- Plug-in 방식으로 기존 모델(CG-DETR 등)에 결합 가능
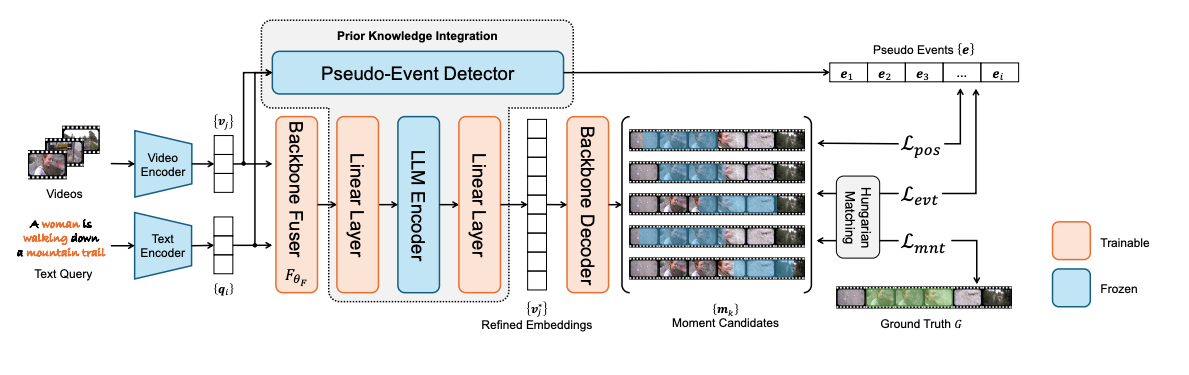
- LLM 인코더로 video feature를 정제함
- Event Detector(UBoCo)로 pseudo Event를 뽑고 그것으로 loss 구성
- 위 2개의 방식은 모두 plug-in 방식으로 사용
특이점
- LLM 인코더의 일부층만을 사용하여 정제
- 기존의 Moment-DETR 구조의 인코더 부분에서 Interaction 완료된 Video Feature가 나오면 그 후에, LLM을 한 번 더 거치는 식의 구조
- UBoCo로 Pseudo Event 만들고, 예측한 moment와 loss 계산 및 positional embedding loss 계산
전체 아키텍쳐
Ablation

- baseline은 QD-DETR이고 각 구성요소에 따른 성능증가
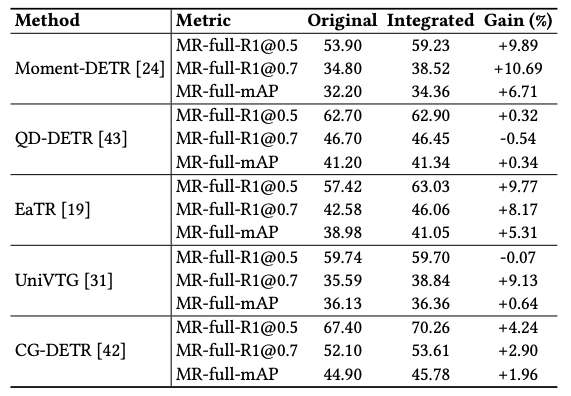
- 모든 모델들에 결합했을 때의 성능 비교 (다만, LLM으로 인한 성능증가인지, Event로 인한 성능증가인지는 모르겠음)

논문 읽은거 자꾸 까먹어서 기록