얻을만한 아이디어
- 디코더는 단순히 UniVTG를 썼음에도 CLIP에서 최대한 정보를 끌어올려서 Video와 Text 정보가 잘 결합된 feature를 뽑아서 SOTA 성능을 낸 것이 인상깊음.
- CLIP에서 최대한 정보를 끌어낸 것이 좋긴한데, InternVideo2와 같이 비디오를 학습시킨 인코더가 나와서 그것이 더 좋지 않을까 싶긴함.
- 이렇게 feature를 최대한 잘 뽑아내게 설계하는 여러 방식(현 논문, TR-DETR)들을 사용하고 CG-DETR 등의 인코더와 적절히 합치고 디코더도 좋게 합치면 좋지 않을까 생각함
Contribution
- SlowFast 없이 CLIP 단일 인코더만 사용해서 효율성과 성능 모두 챙김
- CLIP 끝 feature만 사용하는 것이 아니라, 더 낮은 레벨도 활용
특이점
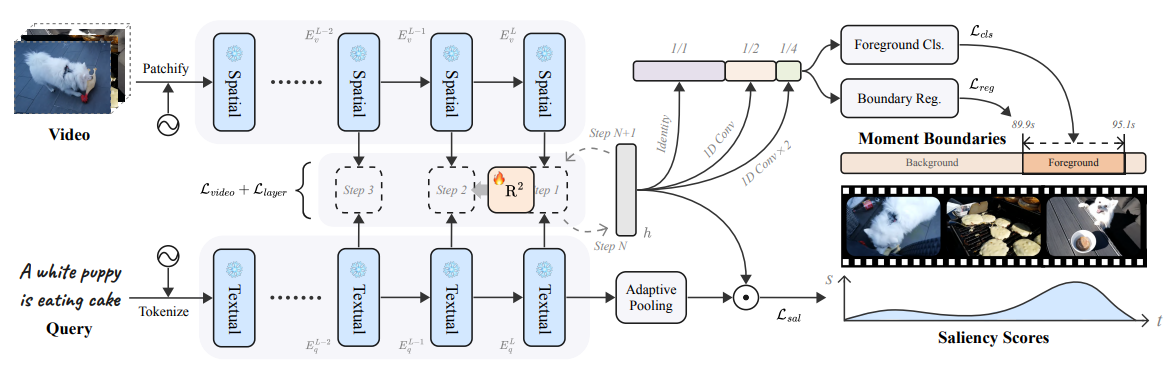
- 디코더는 UniVTG와 거의 동일 (Dense Prediction)
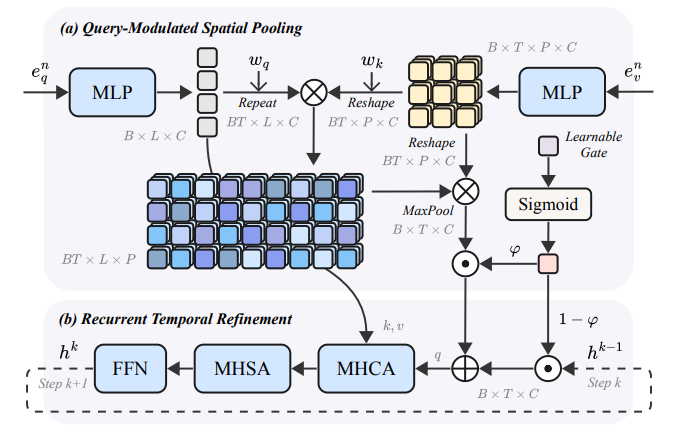
- (a) 모듈: Text 피처를 Query, Video 피처를 key/Value로 사용해서 Cross-attention하는데 patch단위로 가중합이 되고, 텍스트 토큰에 대해서 Max Pooling해주는 형식으로 의 비디오 피처를 얻음.
- Recurrent하게 MHCA, MHSA, FFN 반복하며 비디오 피처 업데이트
- saliency token으로 그냥 text 피처에 adaptive pooling한것을 사용함.
- Granularity Calibration: adaptive pooling한 text 피처와 moment에 해당하는 clip들의 AVGPooling 피처를 사용해서 대조학습함. (이때, layer별로, batch별로 각각 수행함)
전체 아키텍쳐
성능
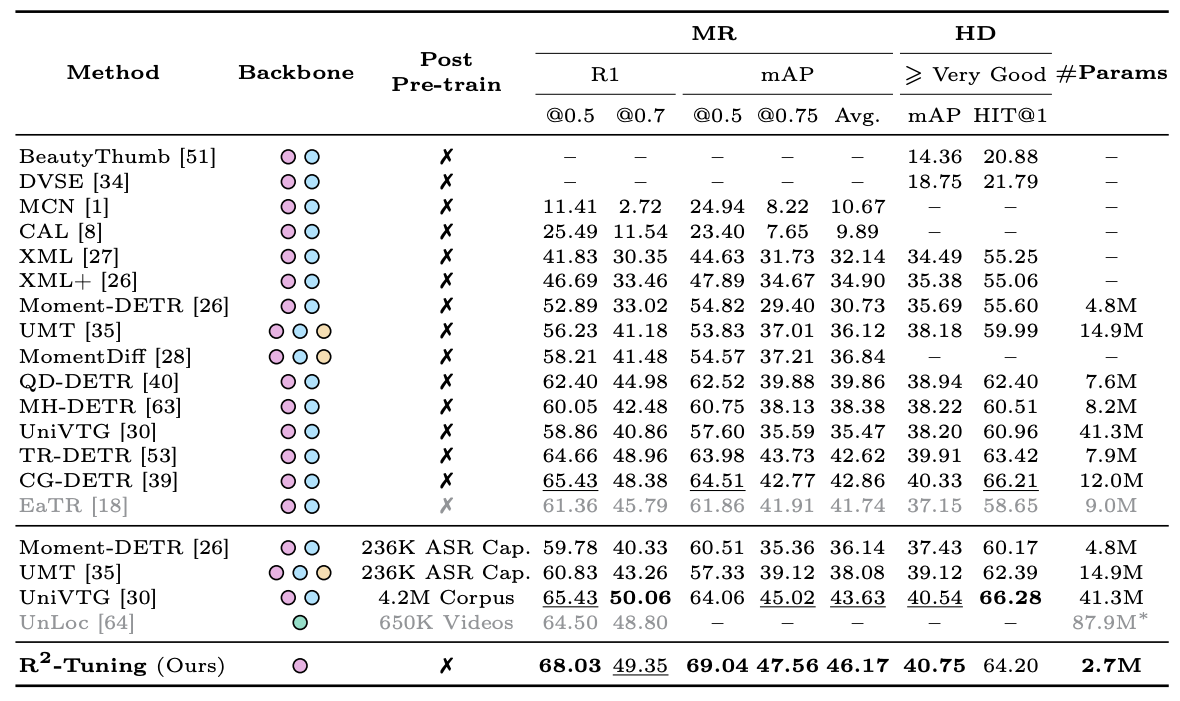
단순히, UniVTG 디코더를 활용했음에도 CG-DETR을 넘는 성능을 보임

논문 읽은거 자꾸 까먹어서 기록