얻을만한 아이디어
- Task간 상호작용하는 아이디어를 차용할만 함.
- 오디오 정보를 잘 활용을 못했는데 오디오 정보를 UMT 방식처럼 처리하는 모듈을 구현해서 고도화시킬 수 있을 것 같음
- Text와 Video joint feature를 뽑을 때, modal gap을 줄이기 위해 추가 loss를 도입해 MLP로 video/text feature가 더 좋게 나오도록 한 점도 괜찮았던 것 같음 (BCE Loss와 대조학습 사용)
- CG-DETR도 인코더를 많이 고도화시켰는데 둘이 좀 섞을 수도 있지않을까 생각이 듬. (joint feature를 잘 뽑는 방식과 video refinement 방식을 어떻게 잘 활용할 수 없을까?)
- 여기서는 MR2HD에서 GRU로 뽑은 것을 salinecy token처럼 사용함.
Contribution
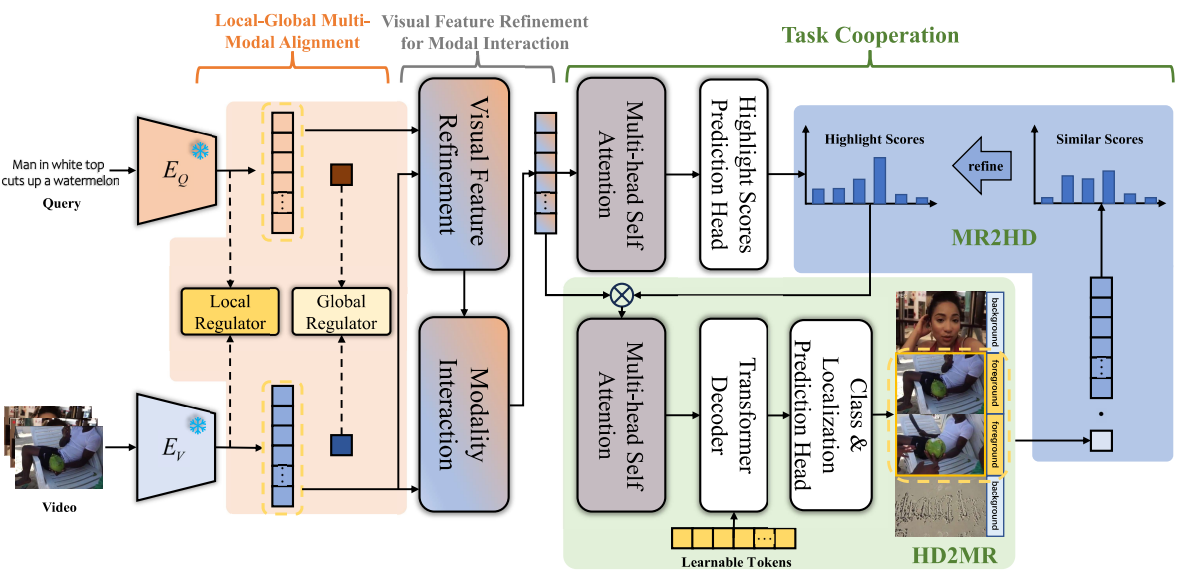
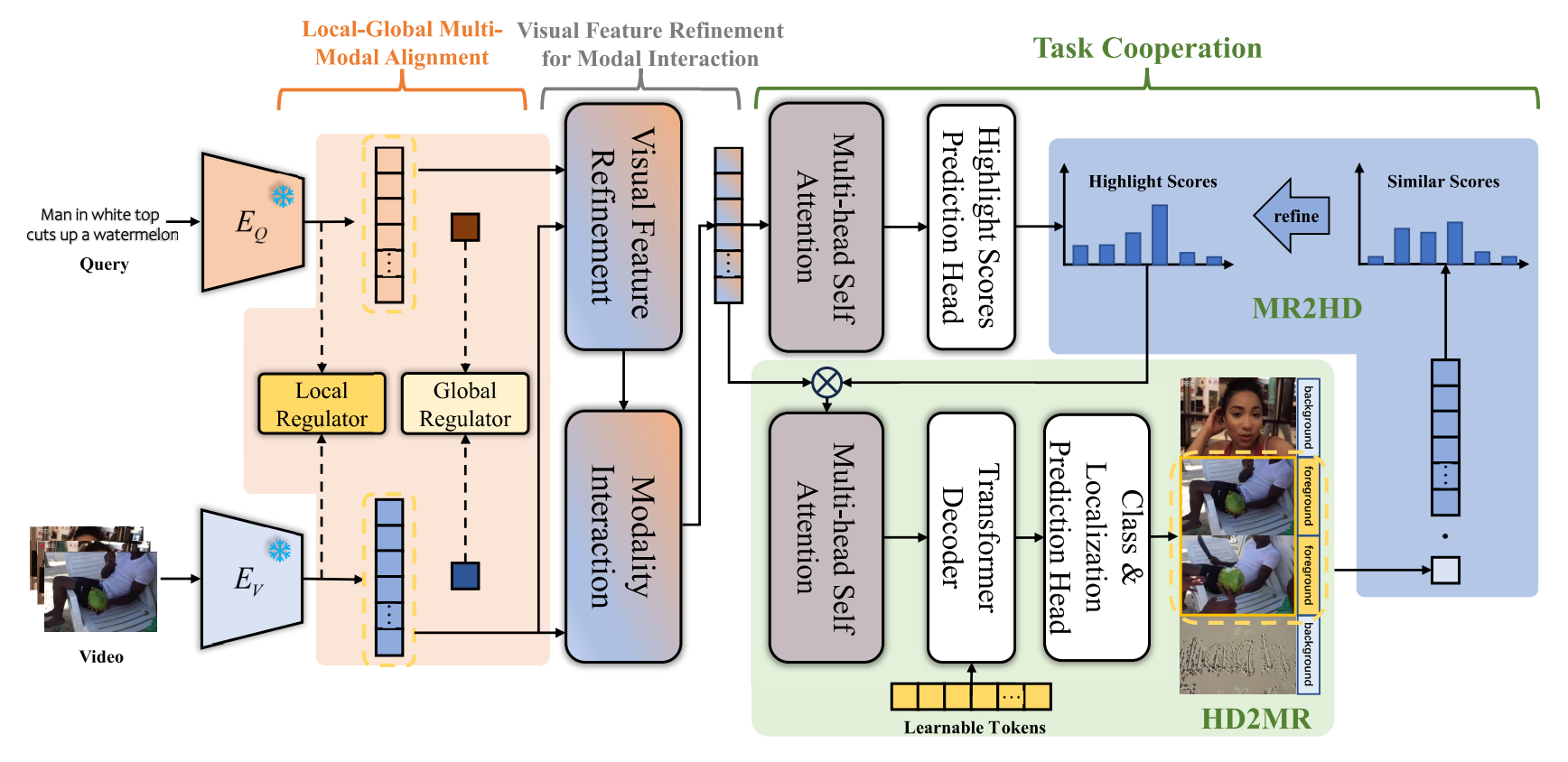
- 이 논문에서도 디코더는 거의 건들이지 않고, 인코더 부분과 MR/HD 간 상호작용 부분에 신경을 썼음.
- MR, HD 작업간 상호작용을 통해 성능을 더 높임
- Feature Extraction할 때, modal gap을 줄이기위해 추가로 학습
- Query-Guided Visual Refinement으로 비디오 feature 정제(VSLNet에서 쓰인 방식) 후 cross-attention으로 비디오 피처를 구함
특이점
- Audio 정보를 활용할 때, 단순히 비디오 피처 옆에 concat하는데 좀 더 고도화가 필요해보임.
전체 아키텍쳐
Ablations
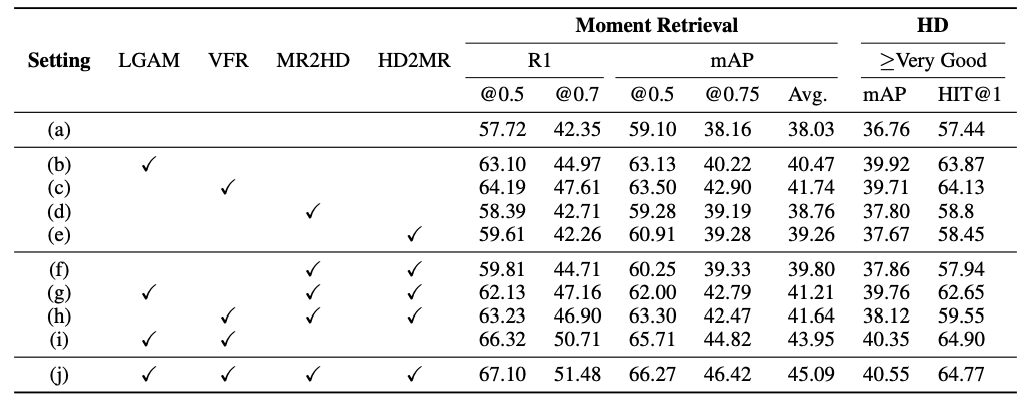
- baseline은 moment-DETR에 Dab-DETR 디코더 구조
- MR, HD간 상호작용도 도움이 되는데, 더 특이한 점은 Local-Global alignment Module과 Video feature refinement module들이 많이 도움이 되는 것을 볼 수 있음.

논문 읽은거 자꾸 까먹어서 기록