알고리즘
1.분할 정복 (Divde and Conquer)

알고리즘을 어떻게 공부해야할지 몰라서 구글링을 하던중 알고리즘 공부한답시고 처음 접했던게 병합정렬이었다. 그래서 그런지 제일 친숙한 정렬방법이기도 하다. 사실 병합정렬은 알고리즘보다는 정렬이라는 분류가 더 어울릴지 모르겠다. 하지만 병합정렬에는 분할정복이라는 중요한 알
2.Java로 순열(Permutation) 구현하기
보통 알고리즘은 c++로 많이 푼다. 그러나 못지않게 자바로도 많이 푸는데 각자의 장단점이 있다. 그중 c++에는 있고 자바에는 없는것이 바로 next_permutation이다. c++이 라이브러리로 순열을 제공 해준다고해도 순열의 원리가 필요한 특정문제에서는 제한적일
3.Java로 upper_bound와 lower_bound 구현하기
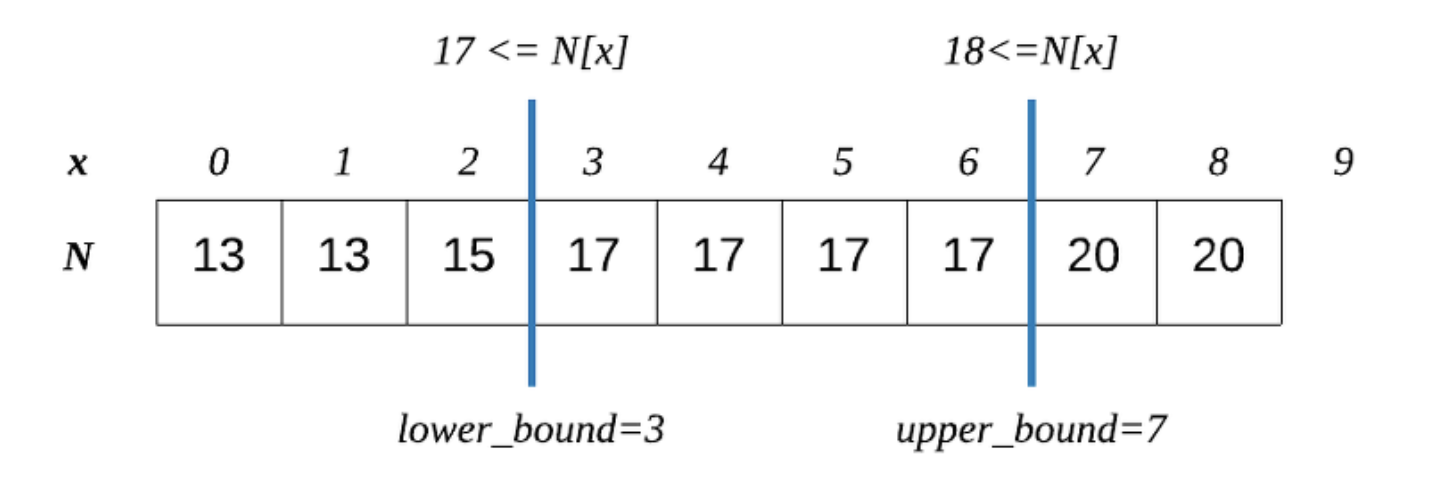
어떤 리스트에서 이분탐색을 이용해서 특정 값을 찾을때, 리스트가 중복된 값을 포함하고 있을 수 있다. 그 중복값을 전부 찾거나 또한 그 중복값들을 활용해서 문제를 해결하는 문제를 위해서 upper_bound나 lower_bound가 존재한다.
4.허프만 코딩(Huffman coding)
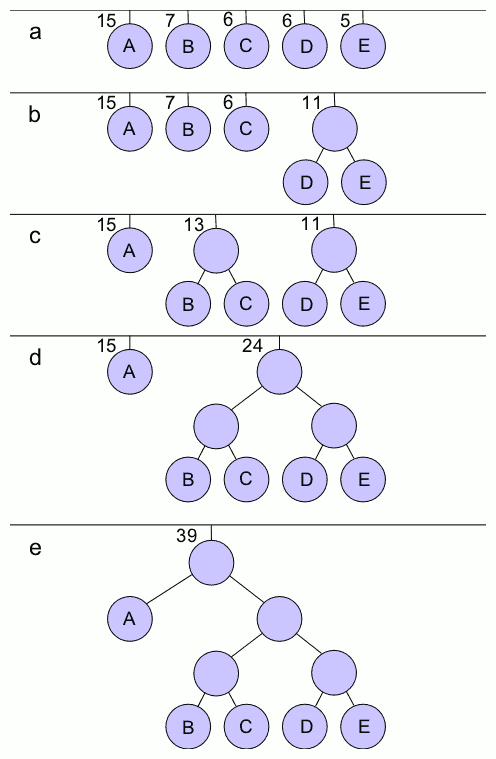
허프만 부호화 또는 허프만 코딩(Huffman coding)은 입력 파일의 문자 빈도 수를 가지고 최소힙을 이용하여 파일을 압축하는 과정이다. 허프만 코드(이진코드)는 Unix에서 파일압축에 사용되고, JPEG 이미지 파일 또는 MP3 음악 파일을 압축하기 위한 서브
5.DFS와 BFS
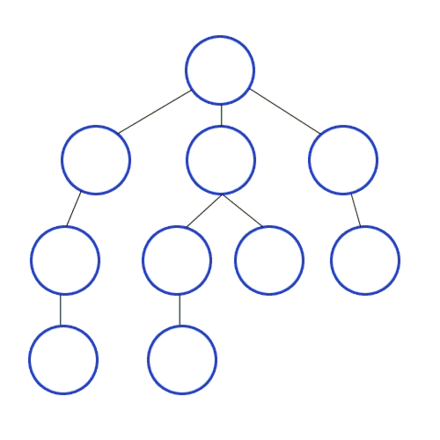
그래프 이론을 통해서 그래프에서 사용되어지는 용어들을 알아봤다. 이제 모든 자료구조의 기초가 되는 탐색 연산을 알아볼 차례인데, DFS와 BFS로 두가지 연산이 존재한다.깊이 우선 탐색(Depth-First-Search)는 너비 우선 탐색과 달리 탐색 방향이 아래로 진
6.KMP 알고리즘

특정 문자열에서 부분 문자열을 찾을 때 사용한다. KMP 알고리즘은 부분문자열을 찾는 알고리즘 중 유일하게 선형 시간복잡도를 가지기때문에 유명하다. 가령 문자열의 길이가 10^5 이고 패턴의 길이가 10^3일 때, 완전탐색 또는 다른 알고리즘의 최악의 경우 1억번 검사
7.다익스트라(Dijkstra) 알고리즘
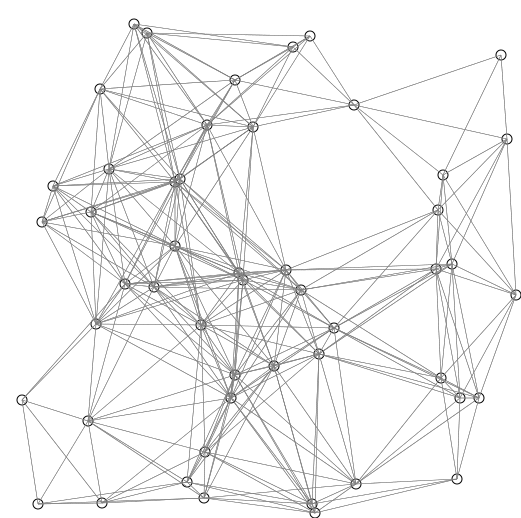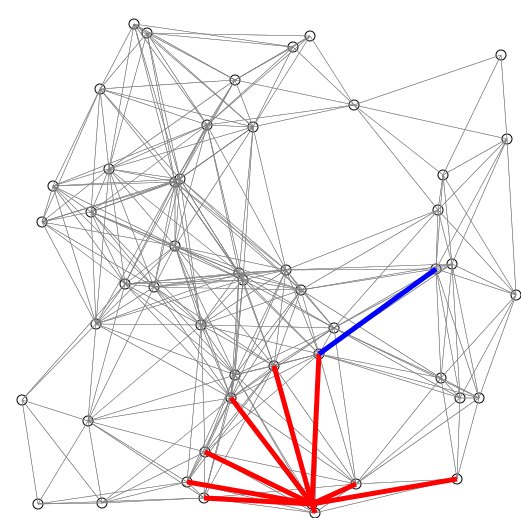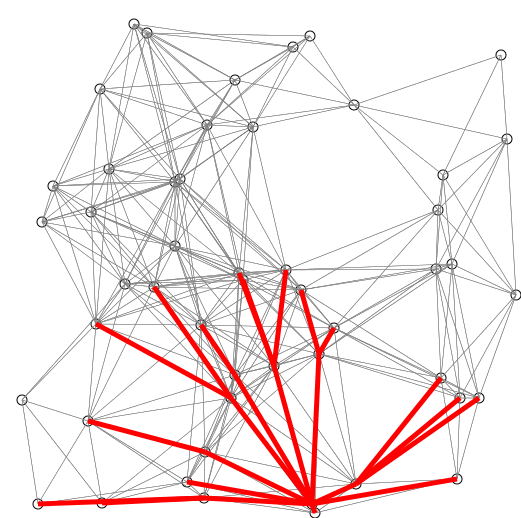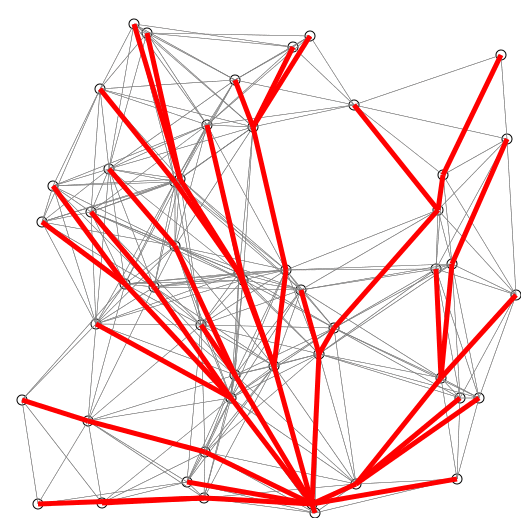
다익스트라 알고리즘밸만포드 알고리즘플로이드-와샬 알고리즘최단경로를 찾는 알고리즘 중 다익스트라는 오직 양의 가중치를 가진 그래프만을 취급한다. 또한 특정 출발위치에서 도착위치의 최단경로를 찾는 알고리즘으로, 모든 경로의 최단경로를 구하지 않는다.그리디하게 정점을 선택하