강의 들으면서 중요한 것 & 알게된 것 & 느낀점 정리!
[W1] Introduction to Deep Learning
- 정형 (Structured) 데이터 & 비정형 (Unstructured) 데이터
정형 데이터: databased of data. 각각의 feature가 매우 잘 정의 됨
비정형 데이터: raw audio, image, text 등의 데이터
[W2] Logistic Regression
1. Binary Classification
: 라벨이 1 or 0으로만 구성. 예를들어 고양이 인지(1) 아닌지(0) 구분하는 문제
2. Logistic Regression
: Binary Classification을 하기 위해 활용됨.
- Output:
- 출력을 0에서 1사이 값으로 mapping하기위해 sigmoid 사용
- 는 x가 주어졌을 때 y=1일 확률: - Parameters: and
3. 와 를 학습하기 위해서 Cost function 정의
여기서는 single training example에 대한 loss function을 다음과 같이 정의한다:
이를 전체 training set에 대해, parameters ( and )가 얼마나 잘하고 있는지 확인하기위해 cost function 정의:
4. Gradient Descent: Cost function을 최소화하는 와 를 찾기위한 Algorithm
최적의 W와 b를 찾기위해서, W와 b에 대한 cost function의 편미분을 계산해서 W와 b를 update. (이 부분은 그림으로 보는게 이해가 더 쉽다)
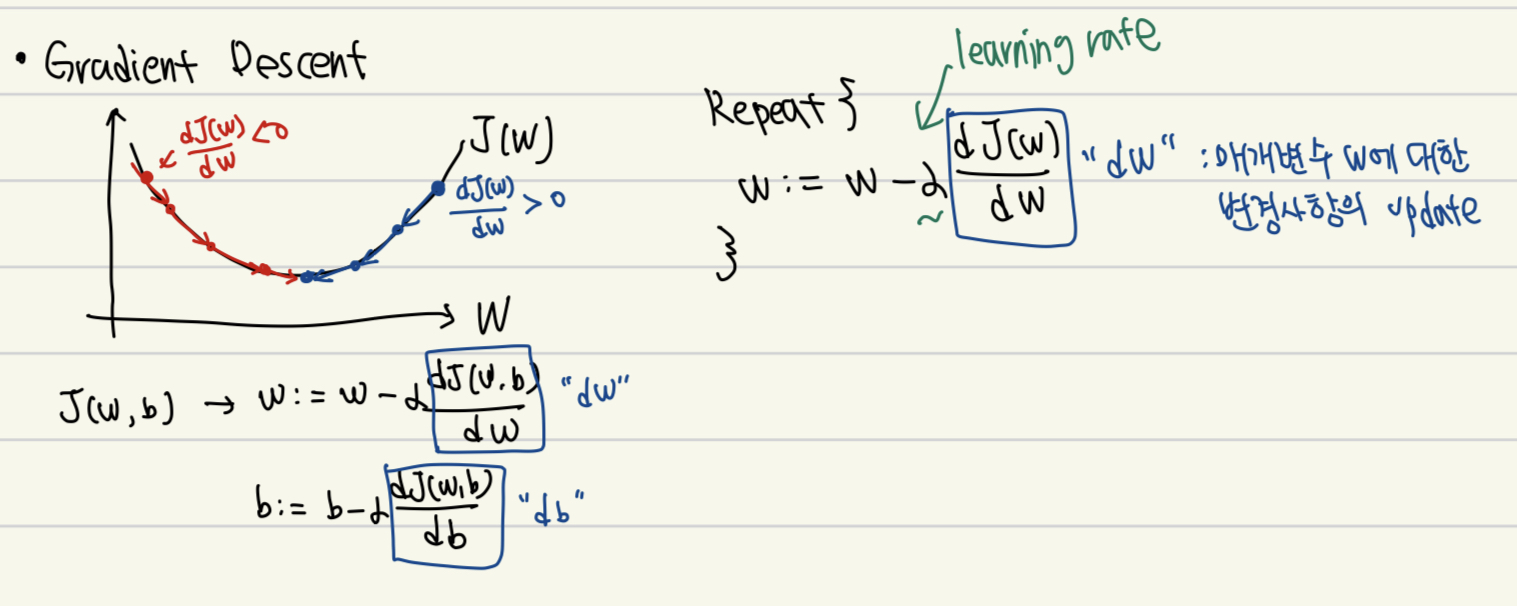
기울기가 0보다 크다면, w가 작아지는 방향으로 update 될 것이고 0보다 작다면, w가 커지는 방향으로 update 된다.
5. Logistic Regression Gradient Descent
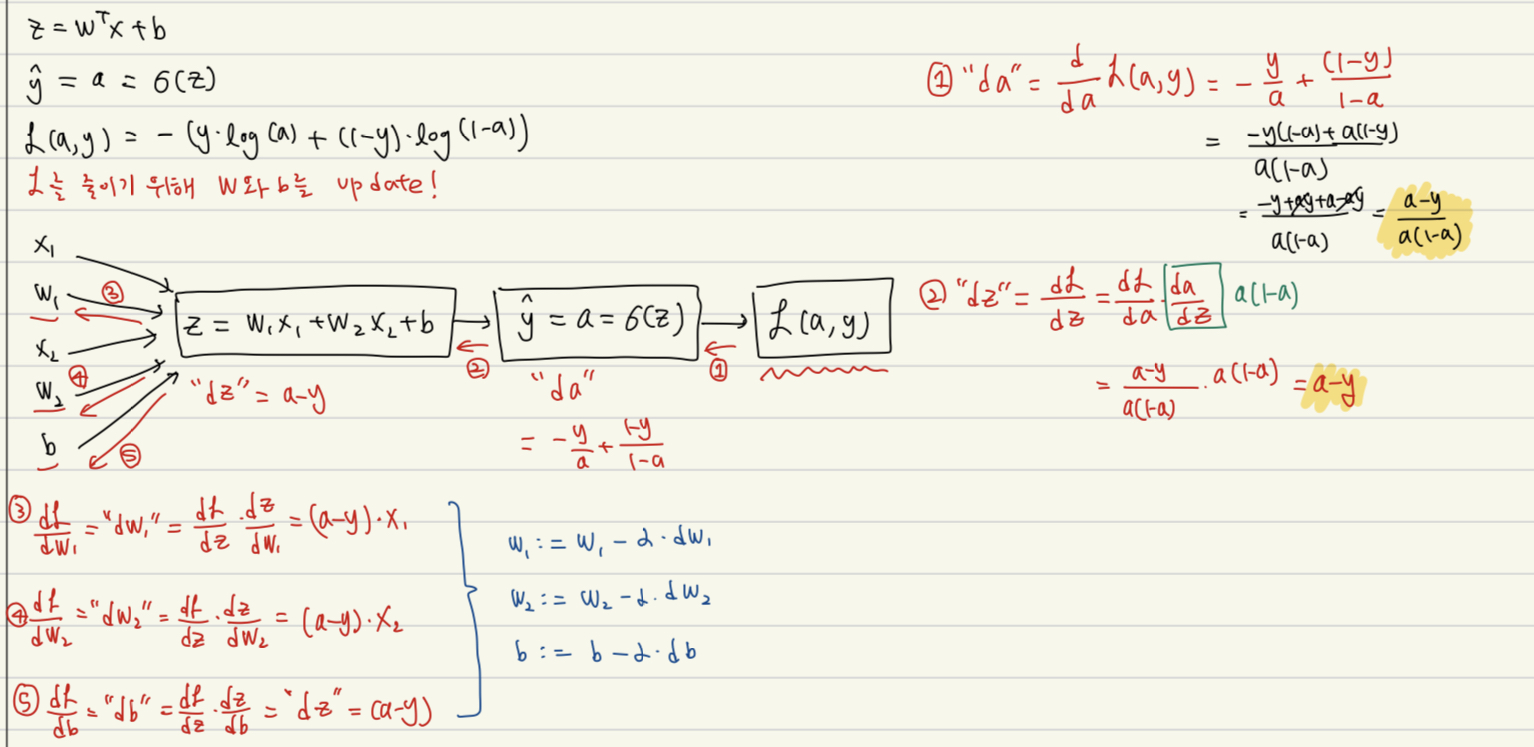
(1) Single training example에 대해서 먼저 계산해보자 (Derivatives 계산)
(Gradient Descent: update the parameters)
(: learning rate, step)
(2) m training examples에 대해 계산
: 우리의 training set에는 m개의 example이 존재한다. 전체 training set에 대해서 NN를 학습하려면 두 가지 방법이 존재한다.
- 명시적으로 for loop 활용 --> 너무 많은 시간 낭비
- Vectorization --> 두 행렬의 곱으로 수행 가능
Vectorization: column 방향으로 training example을 stack하여 하나의 큰 행렬 ()로 만든 다음 행렬 곱을 수행한다.
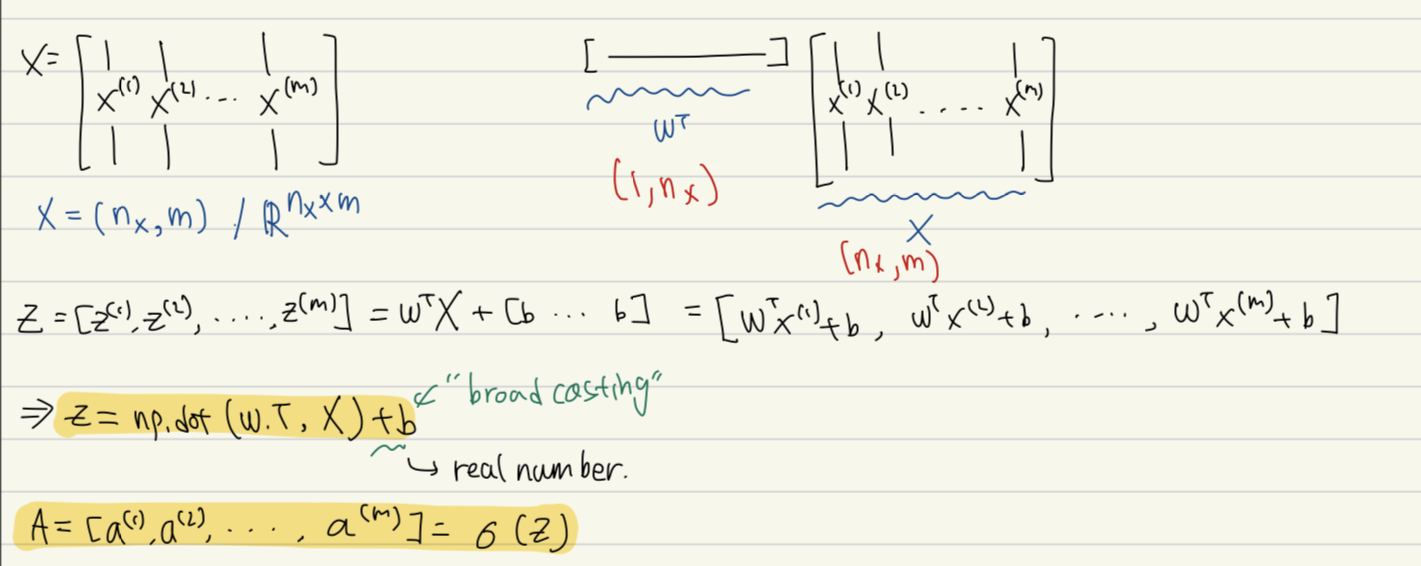
- np.sum(, axis=1, keepdims=1)
