
SLAM관련 개발자가 되고싶은 내가 공부를 시작하며 좋은 논문이 뭘까? 하던중에 google docs에서 바로 나오는 논문을 선택해서 읽기로 했다!
개인적인 관심사로 Lidar와 camera(vision sensor)를 이용한 SLAM알고리즘이 어떤게 있을까 궁금해서 lidar vision fusion 을 검색해서 나온 논문을 선택했다
처음 리뷰하는 논문인만큼 리뷰의 질(?) 이 좋진 않을 수도 있지만..!
열심히 리뷰해보도록 할 예정이다!
introduction
자율주행 연구가 최근 매우 활성화 되고있는데, 그 중 중요한 2가지 개념으로 localization과 perception을 제시한다.
Localizaition
로봇 스스로의 자신의 위치를 인지한다는 개념으로, 높은 정확도를 갖는 localization을 갖도록 하는데에 연구가 진행된다.
Perception
주변의 물체들을 인식한다는 뜻으로 센서 값을 받아들이는 것을 의미함. 논문에서는 lidar와 vision센서를 이용한 perception을 주로 다룬다.
최근에는 주로 GNSS(흔히들 말하는 GPS센서라고 생각하면 됨)를 이용하는데 이는 환경에 따른 한계가 존재한다(터널, 건물안 등등..) 모바일 로봇은 여러 환경을 이동하고 잠재적 장애물들도 만나는 경우가 많다보니, 해당 GNSS센서는 모바일 로봇에서 이용하기가 어렵다. 따라서 3D맵을 만드는 것이 가장 좋은 방법이 될 수 있다고 한다.
3D맵은 단순한 지형지물과, 복잡한 지형들을 포함한다. 해당 맵을 통해서 로봇은 자유로운 공간(움직일 수 있는 공간)과 장애물 등을 감지하고, 알지 못하는 부분을 탐사하고, 상호작용 할 수 있게 된다.
GNSS만을 이용할 경우 해당 센서가 작동되지 않는 곳은 탐사할 수 없지만 해당 3D맵을 통해서는 탐사할 수 있다는 의미로 받아들이면 될 것 같다.
이러한 navigation적 접근을 SLAM 이라고 논문에선 정의한다. 이름인 Simultaneous Localization and Mapping 처럼 Mapping을 함과 동시에 Localization을 하는 process를 SLAM이라 한다.
mapping: 환경에 관한 map을 만드는 것
Localization: 로봇 자신의 위치를 추정하는 것
map은 환경을 visualize하고, 로봇의 경로 계획을 생성하는데 사용된다. 자율 주행에서 로봇은 그 스스로의 경로를 직접 생성하고 옳바른 결정을 사람의 개입 없이 해내야 한다. 여기서 옳바른 결정은 로봇 스스로 안정적인 움직임을 계획하고 유지해야 한다는 것을 의미한다.
최근 SLAM의 주요 분야는 자율주행 자동차(논문 에서는 vehcle) 영역에서 진행되는데, 산업에서 부르는 자율주행 자동차는 실제로 autonomous가 아닌 semi-autonomous라고 한다.
위에서 설명했듯, 실제 자율주행이라 함은 스스로 개입 없이 이루어져야 하는데, 산업에서 사용되는 자율주행이라는 뜻은 특정 상황(고속도로 혹은 주차와 날씨 등등.. 같은 일정한 상황)에서만 가능하기 때문
로봇이나 분야에 계신 분들의 이야기를 들어보면 상당히 예민하게 받아들이는 분들도 많더라...
'이미 자율주행 잘 되는거 아님?' 이라는 말은 주의하자
대부분의 자율주행 자동차들은 GNSS,IMU,SBAS등을 주로 이용한다. 아주 성능이 좋은 GNSS는 오차를 센티미터 단위로 줄여 localization에 활용할 수 있지만, 해당 센서를 못쓰는 경우에는 다른 방법으로 licalization을 수행하여야 한다(고한다). 따라서 주로 Lidar,Radar,camera를 통해서 localization문제를 해결하려 한다. Lidar와 camera센서를 주로 이용하여 다른 센서들이 가진 불확실성을 덜어준다.
IMU: 로봇의 속도, 방향 등의 위치를 알려주는 센서
Radar: 거리를 알려주는 센서(전자기파를 이용하여 감지)
LiDAR: 거리를 알려주는 센서로 카메라와 유사한 map을 만들 수 있음 (빛을 이용하여)
이 논문에서는 현존하는 SLAM기술에 대한 접근을 LiDAR-camera센서를 이용한 방법에 대해 overview를 제시한다.
SLAM
Principle
SLAM은 방문한 위치를 움직임을 추정함과 동시에 지리적 구조를 재구성하는 기술을 의미한다. 여기서 다루는 알고리즘들은 플랫폼과 환경, 파라미터에 대해 의존적인 알고리즘들이다.
논문에서 말하는 근본적인 SLAM의 idea는 landmark의 상관관계를 이용하여 solution(결과)를 발전시킨다는 것이다. SLAM solution은 데이터의 연관성을 이용하여 loop closure를 이용하여 불확실성을 줄일 수 있음.
loop closure 는 map을 만들 때 map이 틀어진 것을 보정해주는 역할을 함
(프로젝트를 하면서 사용해봤는데 기능이 없는 mapping알고리즘만 사용하다보니 매우 좋더라.. 했던기억이)
SLAM은 추정 문제다. 로봇의 trajectory나 pose를 나타내는 변수 와 환경의 landmark를 나타내는 변수 M사이의 관계를 추정하는 것이 목표이다 이라는 측정치와 측정모델 를 와 를 이용하여 나타낸다
는 관측 노이즈를 의미하고, SLAM은 Maximum A Posteriori(MAP) 의 문제를 해결하는 것을 목표로 한다
는 관측 결과를 의미하고 는 현재 위치, 은 맵을 의미한다고 보면 이해가 빠를듯하다.
해당 과정을 설명하는데 논문에서는 매우 간단하게 식으로 넘어갔다. 밑 내용에서 자세하게 다룰 예정이니 간단하게 식만 읽고 넘어가자..!
SLAM에서 목표로 하는 과정을 식으로 나타내면 위와 같다.
베이즈 정리를 이용하여 위의 식 () 을 정리하면 밑과 같은 식을 유추할 수 있다.
위 식에서 를 독립이라 가정하면 식을 밑과 같이 풀 수 있음
여기서 는 시점을 의미한다.
각 시점에서 이전 시점의 측정치가 다음 시점의 측정치에 영향을 미치지 않는다고 가정한다.
매우 일리있는 가정이라고 생각하는데, 이전 측정이 다음 측정에 별도의 영향을 미치지는 않을것 같다.
이러한 SLAM의 문제(MAP)는 EKF에서 해결했다고 한다. 해당 EKF에 관한 내용은 이번 포스트에서는 간단하게 다루고 추후 자세하게 다뤄보도록 하겠다.
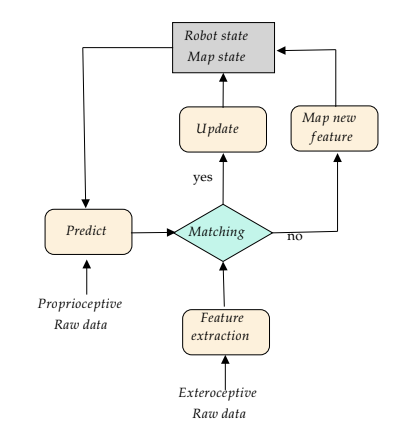
위 다이어그램은 EKF의 간단한 도식을 나타낸다. 입력받은 landmark와 map에 존재하는 해당 landmark를 비교하여 존재 여부에 따라 맵에 새로운 landmark를 추가하거나 현재 상태를 update한다.
이 과정을 재귀적으로 진행하여 mapping 과 localization을 수행하는 것을 볼 수있다...!
현재상태 update (localization)
새로운 landmark추가 (mapping)
Probablistic Solution of the SLAM Framework
이 챕터부터는 위에서 설명한 내용들을 자세하게 다룬다. 확률적인 내용이 SLAM에서 매우 중요하게 다뤄지는 부분이고, 미적분이 많이 나올 예정이니 마음의 준비들 하도록 하자...!
위에서 확인 할 수 있듯 SLAM은 재귀적인 추정 과정이라고 한다 (위치를 추정하고 현재 맵을 업데이트 하는 과정을 의미). 위의 추정 과정을 확률적인 관점으로 접근해 보도록 하자.
해당 접근에 앞서 몇가지 가정과 정의를 하고 넘어간다
- : 시점에서 로봇의 상태(state)를 나타내는 벡터
- : 시점의 이전 state벡터들의 영향을 고려한 벡터
- : 시점에서 의 상태가 되기 위한 제어를 나타내는 벡터
- : 의 landmark를 나타내는 벡터
- : 시점에서 관측된 랜드마크
- : 0부터 시점까지의 로봇(vehicle 등등) 의 위치집합
- : 0 부터 시점까지의 제어 입력집합
- : 0부터 시점까지의 관측집합
- : map과 landmark의 집합
- : 까지의 정보를 바탕으로 추정된 시점의 map
변수가 매우 많은데.. 실제로 다 사용해야하는 변수이니 각 변수의 알파벳이 어떤걸 의미하는지는 꼭 알고 가자..!
확률적 접근을 통해 나타내고자 하는 식은 위 식과 같다. 위에서 언급하듯 재귀적인 연산을 통해서 solution을 구한다. 해당 solution을 위해서 우리는 motion model을 정의해야 하는데 라는 제어입력에 대해 나타내면
처럼 나타낼 수 있다.
이전 제어 입력에 대해 현재상태에 대한 예측을 나타내는 부분, 재귀적인걸 이용하여 solution을 취하는 것이 목표이므로 k-1이라는 노테이션이 나오면 아!.. 이전값들의 영향 고려! 로 알고갔다.
imu가 생각난다
같은 방법으로 인지(관측)에 대한 모델을 수식으로 나타낼 수 있다. 에 대해 시점 번째 관측에 대해 추정된 state를 나타내면
현재까지의 관측으로 알 수 있는 map상태를 나타냄 - map이 landmark와 유사하게 이용되고 있습니다...(?)
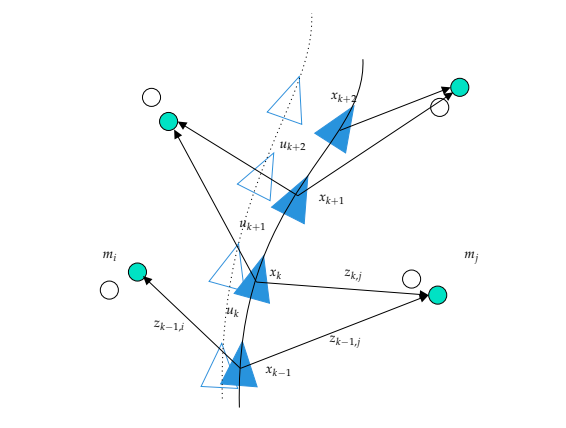
위 그림을 이용하면 위의 notation들에 대해 직관적 이해를 할 수 있다. 로 나타난 부분에서 관측을 입력받고, 제어, 현재 state등등을 이용하여 위치를 update하는 것을 볼 수 있다. 위의 두 식을 합쳐둔 모습으로, 파란색 삼각형은 추정된 위치를 나타내고, 흰색 삼각형은 실제 위치를 나타낸다.
관측 모델과 motion모델을 고려하여 현재state와 map을 유추할 수 있다는 Equation
위의 방정식은 SLAM에서 필요한 재귀적인 베이즈 정리를 이용하는데, SLAM을 해결하기 위해서는 motion model과 observation모델의 적절한 계산이 재귀적 모델을 풀기에 필요하다고 한다. 현재(2020 - 논문 출판 시점) 좋은 기술들은 IMU를 물체(로봇,vehicle ... ) 예측이나 추정 단계에 사용한다. Visual SLAM의 observation모델 관점에서, 위의 식은 inverse-depth에 관련된 식이고, LiDAR, RGB-D, RADAR관점에서는 더욱 간단한 직관적인 실제 word의 3D모형과 같다.
위의 식에서, 로, 센서의 6D pose에 대한 변환을 나타내고, 는 센서의 내장 함수, 는 perspective projection함수이다. 위 함수는 기초적인 관측 모델인()의 역이지만 직관적으로 구할 수 없기에 추가적인 2D관측이 이루어진 후에 일어난다.
P2D는 센서 함수나 기타 조건으로 인해 방정식을 구하기가 어려우니 다른 관측을 이용한다.
6D는 []를 말함
Graph Based Solution of the SLAM Framework
LiDAR를 이용한 경우, 관측 모델은 직관적이다. 확률론적인 접근에도 SLAM관점에서는 graph-based method에서 상대적인 관점의 변환이 최적화 될 경우 해결된다.
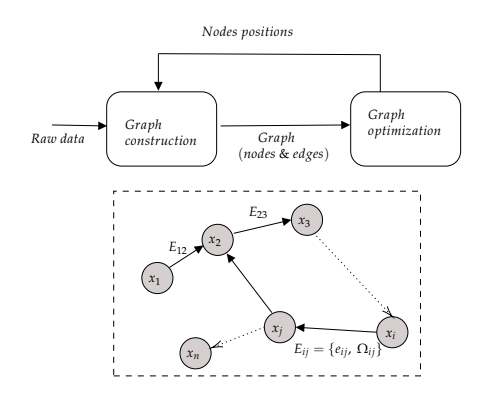
입력받는 raw데이터는 graph에서 edge로 나타내면서 쉽게 해결한다. 사실 이러한 edge는 확률분포를 따라 각 연관있는(근처) 위치에 label된다고 한다. 위의 그림에서 볼 수 있듯 graph based slam은 graph construction과 graph optimization으로 이루어 지는데, 각 부분을 SLAM에서 frontend(construction) 와 backend(optimization)라 한다.
해당 부분 또한 추후에 구체적으로 다뤄보도록 하자
Visual SLAM
해당 챕터에서는 Visual SLAM에 대한 전반적인 내용을 다룬다. Visual SLAM은 비용이 적게들고, 수많은 정보를 수집할 수 있기에 매우 용이하다고 한다. Visual SLAM은 이미지 픽셀의 움직임을 이용하여 카메라의 동작을 추정하는것을 목표로 한다. 카메라의 동작을 추정함으로서 주변 환경을 인식하고, 자신의 위치를 파악한다.
Feature Based SLAM
Feature based SLAM은 filter based 와 Bundle Adjusted based(BA method)인 2가지로 다시 나뉜다. 두 방법의 비교는 참고 논문으로 대체되어있다.
MonoSLAM
EKF를 이용하여 카메라의 motion과 feature를 파악하는 방식이다. 이러한 filter based 기술들은 많은 feature들을 필요로 한다. 이러한 문제를 해결하기 위해 제시된 방법이 PTAM방식이다.
PTAM
해당 알고리즘은 pose와 map을 나누어 여러스레드를 이용하는 BA방법이다. 해당 방법에 대해 많은 보완된 방식들이 제시 되었다고 한다. 이러한 BA방식을 향상시키는 방법으로 loop closing이 추가되었다.
ORB SLAM
해당 알고리즘은 SLAM기능 향상과 monocular, stereo, RGB-D camera를 제어할 수 있도록 여러가지의 트릭을 쓴다고 한다. 그러나 ORB SLAM은 여러가지의 파라미터를 필요로 한다는 단점이 있다.
ORB SLAM은 대표적인 SLAM방식중에 하나이므로 추후에 자세하게 다뤄보도록 할 예정이다.
Direct SLAM
feature based방식들과 달리 direct method는 feature를 이용하지 않고 직접적으로 이미지를 이용한다. direct SLAM은 주로 2개의 연속적인 이미지를 이용한다(측광을 이용하여 카메라의 pose나 동작을 추정함). 해당 방식으로는 LSD-SLAM, SVO, DSO가 있다. 요즘에는 딥러닝을 이용한 방식이 있으나 GPU의 사용이 필요하다는 점에서 단점이 존재한다.
RGB-D SLAM
카메라 센서의 RGB-D빛을 이용한 방식이다. 카메라들은 3D정보를 제공할 수 있지만, 대부분 실내 주행 환경에서만 사용된다고 한다. 해당 방식은 햇빛에 매우 민감하다.
Event Camera SLAM
event camera라는 센서를 이용한 방식으로, 빛의 변화에 따른 event를 이용하는 방식이다. 해당 센서는 V-SLAM애서 주로 사용된다. SLAM기능에 있어서 아직 완벽한 성능을 보이지 못한다고 한다.
'아직' 이나 '현재' 같은 말들은 논문이 써진 시점을 기준으로 하는 것임에 주의하자..!
Visual SLAM Conclusions
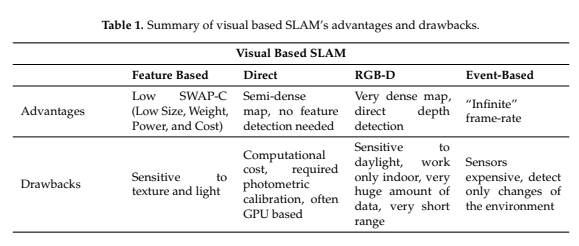
V-SLAM에 대한 내용을 주로 다룬 부분이다. V-SLAM이 좋은 성능을 보일 수 있다고 해도, 해당 방식 또한 햇빛의 영향을 많이 받으며 low-texture한 환경에서는 좋은 성능을 보일 수 없다고 한다. RGB-D방식은 IR light에 기반을 하고 있기 때문에, 낮에 햇빛의 영향을 많이 받는다고 한다. 결론적으로, Visual SLAM은 실내 환경에서 좋은 성능을 보인다고 한다. 다른 알고리즘들을 고려하여도 환경이 low texture하다면 좋은 성능을 보일 수 없다. 밑의 표에서 각 방식의 장단점을 확인하자.
LiDAR Based SLAM
위의 한계들을 극복할 수 있는 LiDAR센서를 이용한 SLAM에 대해 알아보자. LiDAR센서를 이용한 방식은 RADAR를 이용한 방식에 비해 3D mapping에 있어서 정확도와 난이도 측면에서 좋은 성능을 보여준다. RADAR센서를 이용한 방식은 visual센서와 fusion하는 과정에서는 어렵다고 한다.
LiDAR센서를 이용한 SLAM은 pointcloud를 이용하여 SLAM을 하는데에 좋은 성능을 보인다. 예전의 방식으론 stop-and-scan방식이 있었지만, 해당 방식은 navigation에 있어서 좋은 방식은 아니다. IMU 센서와의 fusion을 이용하여 motion의 왜곡(distortion)을 error model을 이용하여 보정하고 속도 입력을 구한다.
LiDAR의 영향이 매우 큼에도 불구하고, LiDAR scan registraion방식은 크게 변한 바가 없다고 한다. LiDAR기반 navigation의 주요 주제는 graph optimization을 위한 scan-matching 방식에 있다.
Scan-Matching and Graph Optimization
scan-matching은 LiDAR를 이용한 정확한 3D mapping에 있어서 기초적인 process이다. 일반적인 방식으로는 Iterative Closest Point(ICP)를 이용하여 3D point cloud를 구성하는 방식이다. ICP는 대응점을 찿는데에 많은 연산이 필요하다는 것과 알고리즘이 초기값의 영향을 많이 받는다는 단점이 있다. 이러한 단점을 줄이기 위해 kd-tree와 같은 방식을 이용하여 탐색 속도를 줄인다. ICP는 probablistic framework에서 더 좋은 성능을 보일 수 있다. ICP의 대안으로는 Polar Scan Matching(PSM) 이 있다.
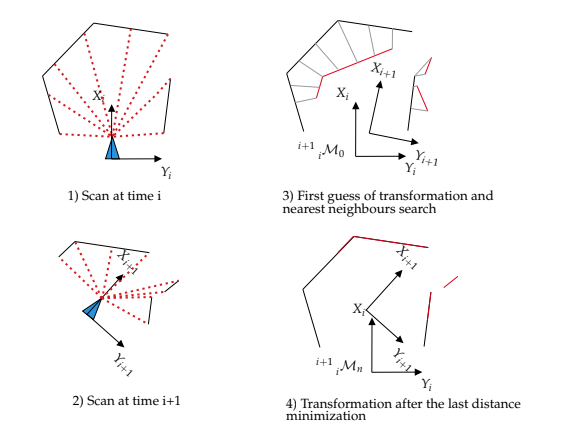
위 그림에서 ICP의 과정을 볼 수 있다.
local error를 줄이기 위해 graph based method를 이용할 수 있다. 로봇의 pose변화는 graph로 대체되는데, 노드들은 센서값, 엣지는 관측결과(ICP를 통한)를 의미한다.
Occupancy Map and Particle Filter
SLAM문제를 해결하기 위해 Gmapping 에서 사용된 Particle Filter(PF)를 사용할 수 있다. PF는 local error를 많이 줄여주고, 평면환경에서 좋은 결과를 보여준다. 각각의 particle은 로봇의 pose와 map의 가능성(possible)을 나타낸다. 그러나 정확한 mapping을 위해 많은 양의 particle들이 요구된다는 단점이 있다. likelihood model에서 PF는 높은 정확성을 가진다. 해당 결과로 나오는 occupancy grid map은 기존 방식보다 한차원 적은 particle 수 를 이용하여 좋은 성능을 보인다.
3D에서의 PF를 이용하는 방식은 occupancy grid의 크기 때문에 매우 어렵다고 한다.
Loop Closure Refinement Step
완전하게 SLAM을 하기 위해선 loop closing step이 추가되어야 한다. global map을 향상시키기 위해서 로봇이 이전에 방문한 곳을 재방문시 loop closing이 일어난다. feature based 방식과 같이 이용되는데, geomatric description을 이용한다. geomatric description으론 line, plane, sphere와 같은 것이 이용된다. scan matcher가 실제로 scan마다 진행되기는 어려우므로 환경을 대표할 수 있는 submap마다 이용된다. 완성된 submap들은 scan matching loop에 추가되고, 현재 로봇 위치에서 sliding window를 사용하여 loop detection이 이루어진다.

Graph based 방식과 Occupancy Map의 비교
LiDAR-Camera Fusion
SLAM은 위에서 볼 수 있듯 visual(camera etc...) 센서와 LiDAR를 이용하여 좋은 성능을 보인다. V-SLAM은 정확한 성능을 보여주지만 몇가지의 단점들이 존재하고, LiDAR를 이용한 SLAM의 경우에도, 해당 기술들 또한 scan matching과 graph-pose의 영향을 받는다. 이 챕터에서는 두 센서를 모두 활용하는 방법에 대해 제시한다.
The Mandatory Calibrtion Step
LiDAR와 Camera의 fusion을 통한 SLAM을 위해서 두 센서의 claibration이 전제되어야 한다. 해당 방법으로는 상호 관계가 존재하는 지점을 일치시키는 방법이 존재하지만 특정 상황에서만 존재한다는 단점이 있다. CNN을 통한 방법이 있는데 이는 이전 방법에 비해 optimal한 결과를 제공한다고 한다. 논문이 쓰여진 시점에서 solution처럼 여겨지는 방법은 아직까지 존재하지 않았다고 한다.
Visual-LiDAR SLAM
EKF Hybridized SLAM
EKF SLAM을 활용한 sensor fusion 방법이다. 해당 방법은 visual tracking이 잘 되지 않는다는 이슈가 있다고 한다. RGB-D 값에서 받아지는 pointcloud 를 lidar를 통하여 localize하여 3D map을 만드는 방식으로 진행된다. 실제 센서퓨전이라고 할 수는 없지만 두 modalities의 switch mechanism이라고 한다.
Improved Visual SLAM
sensor fusion을 이용하여 visual SLAM분야에서 큰 발전이 있다. LiDAR를 이용하여 depth를 측정하여 성능을 높이는 방식이 있는데, 카메라의 depth보다 해상도가 낮은 LiDAR의 depth정보를 이용하는 방식이다. 해당 방식의 해상도 차이는 interpolation을 통해서 해결한다고 한다. 두 센서의 transformation을 연산한 후 가우시안을 이용하여 부족한 값들을 interpolation 한다고 한다.
Improved LiDAR SLAM
많은 visual-LiDAR SLAM에서 LiDAR는 scan-matching 을 통한 motion 추정에 사용되었다. 그러나 LiDAR의 성능이 안좋은 경우 visual sensor를 이용하여 SLAM의 성능을 높일 수 있는데, ORB SLAM과 같은 경우에서 visual loop detection과 scan matching방식을 이용하여 성능을 높일 수 있다. bag-of-words를 이용하여 feature frame을 매칭하는 방식으로 이루어진다. 라이다의 경우 ICP를 사용하는데 장점이 있기에 좋은 성능을 보인다고 한다.
Concurrent LiDAR-Visual SLAM
visual-LiDAR sensor fusion을 통하여 Visual SLAM과 LiDAR SLAM을 합치려는 시도가 많이 일어나는 중이라고 한다. 동시에 두 방식을 시행하여 coupling하는 방식도 존재하고, 두 센서를 이용하여 odometry를 구성하는 VLOAM또한 존재한다고 한다.
Summery
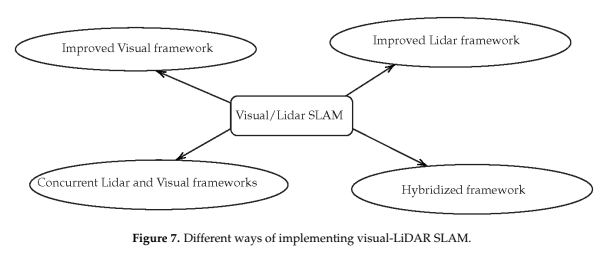
위에서 다룬 내용들을 바탕으로 설명하면, sensor fusion을 이용하여 LiDAR SLAM또는 Visual SLAM에 추가적인 정보를 제공하여 성능을 높이는 방식으로 fusion이 진행된다. Fig.7 에 나오는 Hybridized framework가 앞으로의 연구 방향이라고 제시한다. 이전 내용들에 비해 tight하게 연결된 LiDAR-Vision SLAM framework가 필요하다고 한다.
Discussion on fucture Research Directions
아직 sensor fusion을 통해 뛰어난 성능을 보이는 framework가 없다고 한다. V-SLAM은 빛이나 특징이 없는 환경에서 사용하기 어려운 단점이 있지만, LiDAR SLAM은 가능하다, LiDAR SLAM은 너무 넓은 범위에서는 사용할 수 없다는 단점이 존재하지만, V-SLAM은 해당 단점을 보완할 수 있다. multi-modal, hybrid multi-constraint MAP과 같은 문제들을 해결하면 더 좋은 성능의 SLAM을 할 수 있고, 해결 가능한 문제라고 한다.
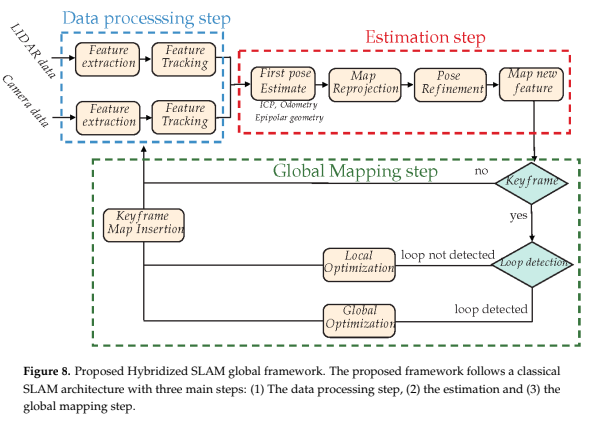
위와 같은 방식으로 sensor fusion을 활용한 framework를 제시한다. 이러한 framework가 이상적으로 작동하기 위해서, Data processing step이 중요하다. feature detection과 LiDAR vision calibration step에서의 좋은 성과를 통해 이후 Visual-LiDAR SLAM을 향상시킬 수 있다.
Conclusions
가장 좋은 성능을 발휘하는 SLAM을 찿기 위한 많은 연구가 진행되었다. 이론적으로, SLAM은 자율주행분야에서 가장 완벽한 solution이라 한다. 그러나 그 과정에서 알아본 바와 같이 많은 문제들이 발생한다. 실제 주행에 있어서, 많은 문제들이 발생할 수 있기에 AI를 활용한 방법에 대한 연구도 많이 필요하다.
해당 논문은 2020년에 쓰여진 논문으로 이 포스트에서 말하는 현재, 지금 기타등등의 시간에 관한 말들은 2020년을 의미합니다!
처음 포스트를 리뷰하면서 논문을 그저 한글로 번역했다는 생각이 듭니다...
앞으로 다룰 SLAM관련 논문들은 EKF, ORB가 될것같고, Visual SLAM에 관한 내용도 다룰 예정입니다.
현재 진행하는 프로젝트에서 실외넓은 환경에서 SLAM을 해야할 것 같은데 LiDAR의 range가 짧아서 어떻게 진행할지 고민중이니, 해당 문제상황에 관련된 논문들 위주로 읽게될 것도 같습니다.
