
SHAP (SHapley Additive exPlanations)
모델의 예측 결과에 대한 변수 중요도 뿐만 아니라 변수들이 얼마 만큼의 영향이인지 확인해 보는 방법이다.
✔ 특정 데이터에 대해서 예측 값에 대한 기여도를 확인할 수 있다.
✔ 모델에서 변수 중요도를 확인할 수 있다.
✔ 특정 변수 값에 따라 예측 값의 변화를 살표 볼 수 있다.
Shapley value (기여도)
✔ 조합의 전체 feature로 예측한 값에서 특정 변수를 빼고 예측한 값을 기여도로 계산한다.
✔ 모든 가능한 조합에서, 하나의 feature에 대한 가중 평균 기여도를 계산한 값이다.
✔ shapley value를 이용하여 feature의 중요도를 설명할 수 있다.
전체 데이터 예측값 - 나의 데이터 예측값 의 차이를 알고 싶을때
각 feautre들은 이 차이에 어떤 기여를 했을까?
다음은 기여도 계산을 요약해 보았다.
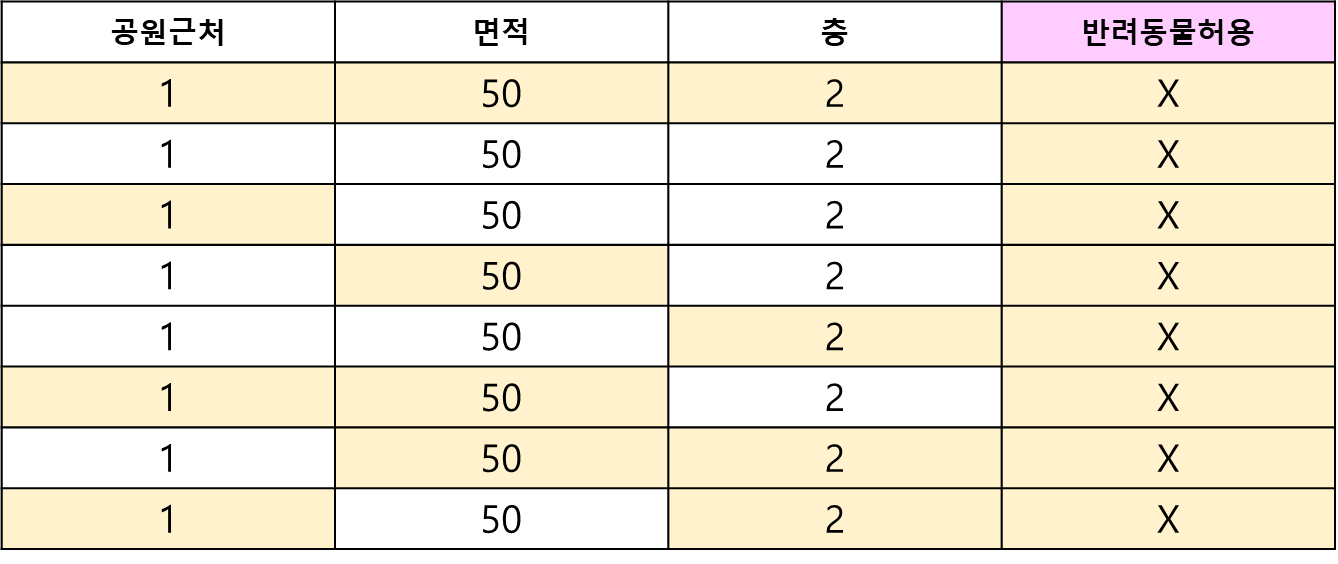
자주 예시로 나오는 집값 예측 하는 테이블의 한 행을 가져왔다.
feature는 다음 4가지이다.
- 공원근처
- 면적
- 층
- 반려동물 허용
-
기여도가 궁금한 feature지정
예시) 반려동물허용 -
궁금한 feature를 고정해 두고 나머지 변수들의 모든 조합을 구성한다.
예시) 나머지 3개의 조합의 갯수는 222 => 8가지이다. (공원근처, 면적, 층) -
선택한 feature의 모든 조합의 기여도를 계산하여 평균을 낸다.
예시) 표 6번째 조합으로 진행
/ 기여도 계산 방법 /
공원근처=1, 면적=50, 반려동물허용=0 => 모델 예측 집값: 50만 유로 (모델 예측은 즉, 가중치*값)
공원근처=1, 면적=50 => 모델 예측 집값: 55만 유로
55만유로 - 50만유로 = 5만유로
즉, 반려동물허용의 기여도는 5만유로
3번의 순서를 8개 모두 반복하여 값의 평균이 반려동물허용 변수의 최종 기여도가 된다. 이를 기여도의 가중평균 이라 한다.
(참고: feature의 수가 많으면 feature의 가중치는 떨어진다.)
SHAP의 알고리즘은?
◻ Tree기반 알고리즘: TreeExplainer
◻ Deep Learning: DeepExplainer
◻ SVM: KernelExplainer
◻ 그 외: Explainer
실습
RandomForest로 Tree기반 알고리즘 TreeExplainer를 사용한다.
먼저 !pip install shap 을 통해 라이브러리를 다운받는다.
#모델 생성
model = RandomForestRegressor()
model.fit(x_train, y_train)
#모델 해석
explainer = shap.TreeExplainer(model) #해석기를 생성
shap_values = explainer.shap_values(x_train) #데이터셋으로 기여도 수치 받음
x_train.shape, shap_values.shape #모든 행에 대해서 기여도가 측정된 것으로 x_train과 shap_values는 크기가 동일하다회귀
id = 0
display(x_val.iloc[id:id+1,:])
display(pd.DataFrame(shap_values1[id:id+1, :], columns = list(x_val)))
# shap 그래프
shap.initjs()
# force_plot(전체평균, shapley_values, input)
shap.force_plot(explainer1.expected_value, shap_values1[id, :], x_val.iloc[id,:])

=> 각 feature의 -/+ 기여도를 모두 더하면 평균 예측값과의 차이가 나온다.
=> 예측 값과, 예측 값들의 전체평균의 차이에 각 feature가 얼마나 기여 했는지 계산한 값

red: 상승요인
blue: 하강요인
base value: 전체평균
f(x): 예측값
분류
explainer1 = shap.TreeExplainer(model)
shap_values1 = explainer1.shap_values(x_val)
# shap_values1: 분류 모델은 hap_values의 결과도 0 관점, 1 관점 각각 나온다
# 값은 부호만 다르고 똑같음
# 1관점에서 기여도를 확인해 보기로 함
shap_values1[0].shape
shap_values1[1].shape #1 관점 id = 0
display(x_val.iloc[id:id+1,:])
display(pd.DataFrame(shap_values1[1][id:id+1, :], columns = list(x_val)))
# shap 그래프
shap.initjs()
# force_plot(전체평균, shapley_values, input)
shap.force_plot(explainer1.expected_value[1], shap_values1[1][id, :], x_val.iloc[id,:])
