
앞서 모델에 사용된 변수의 중요도를 구하였는데 이와 비슷하게 변수의 영향력 을 파악할 수 있는 유용한 시각화 그래프 2가지 이다.
ICE (individual conditional expectation)
✔ 개별 행에서 특정 변수의 변화에 따른 예측 값의 변화(영향력)을 시각화 한다.
✔ 데이터의 한 행만 가지고 작업을 한다.
🔺진행방식
1. 분석하고자 하는 feature선택
1. x_train에서 해당 feature 값 모두 추출
2. 선택한 행에(1 row) feature의 값을 추출한 값으로 변경하여 모델 예측값 계산
3. 예측값에 대한 그래프 그리기
🔺수행 코드
def ice_plot(model, x, y, data_1row, var) :
# ① x_train에서 crim 변수의 값들을 뽑습니다.
x_values = x[var].sort_values()
# ② data1의 crim 에 ①의 값을 하나씩 넣으며 예측값을 계산합니다.
pred = []
for v in x_values :
data_1row[var] = v
pred.append(model.predict(data_1row)[0])
# ③ 이를 그래프로 그립니다. x축 : crim, y축 : 예측값
sns.lineplot(x = x_values, y = pred)
plt.ylim(y.min(), y.max()) # 실제 값의 범위 지정
plt.grid()
plt.show()
ice_plot(model, x_train, y_train, data1, 'lstat')🔺그래프 해석
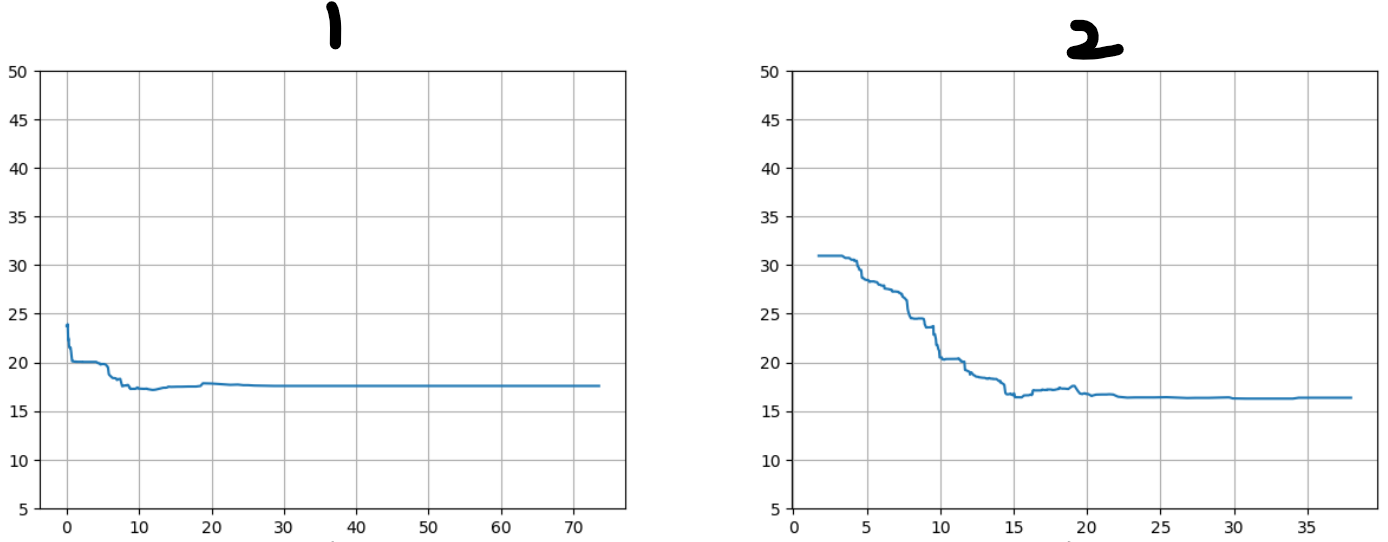
실제 코드를 수행하면 위에와 같은 그래프가 나타난다.
만약 1번과 2번 두 변수에 대한 예측값이 변동이 다음과 같다면,
예측값 변동이 큰 2번 변수의 모델 영향도가 크다는 것을 알수 있다.
PDP (partial dependence plot)
✔ ICE처럼 한 행이 아닌 여러 행에 대한 ICE plot을 그린다.
✔ ICE plot의 평균선이 PDP가 된다.
🔺진행방식
1. 관심 있는 특성을 선택한다.
2. 해당 특성을 변화시키면서 모델의 예측 결과를 관찰하기 위한 범위를 설정
3. 특성을 변화시킬 때 다른 모든 특성을 고정하고 예측 결과의 평균 또는 중앙값을 계산
4. 시각화하여 특성이 예측 결과에 어떻게 영향을 미치는지 이해
🔺라이브러리
from sklearn.inspection import PartialDependenceDisplay, partial_dependence
PartialDependenceDisplay 함수
- model : 어떤 알고리즘도 상관 없다
- 학습데이터 X
- 분석 변수 (리스트 형태, 1개 이상 가능)
- kind : 'both' / 'average' (Default) / 'individual'
kind='both' : average + individual 둘 다 나온다
kind='average' : Partial Dependence plot
kind='individual' : 여러 ICE plot
🔺수행 코드
PartialDependenceDisplay.from_estimator(model,
x_train,
['rm'],
kind="both")
plt.grid()
plt.show()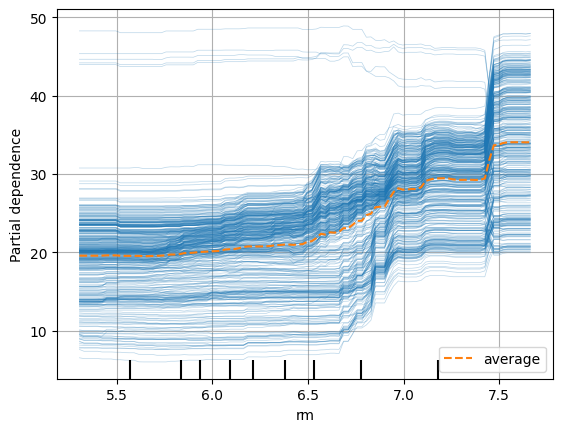
파랑색선이 개별적인 ICE 선이고 (kind를 individual 했을 때 나타남),
주황색 선이 PDP를 나타내며 ICE 선들의 평균이다.
_PartialDependenceDisplay는 시각화를 하고 partial_dependence는 수치로 확인 할 수 있다.
partialdependence 사용예제
var = 'rm'
temp = x_train.iloc[0:2,:]
PartialDependenceDisplay.from_estimator(model, temp, [var], kind ='both')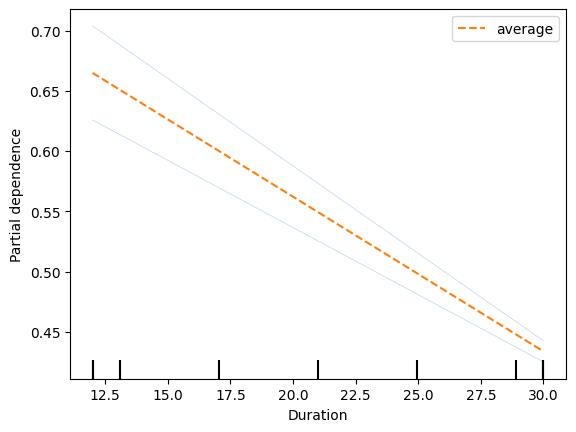
pdp = partial_dependence(model, features = [var], X = temp, kind = 'both')
print(pdp['average'])
print(pdp['individual'])
### 결과 ###
[[0.6648918 0.43375522]]
[[[0.62586814 0.4250094 ]
[0.7039154 0.44250107]]]
[array([12, 30])]
서로 다른 2개의 변수로 PDP 사용
1) 두 feature의 영향력 비교
PartialDependenceDisplay.from_estimator(model, x_train, ['rm','lstat'])
plt.show()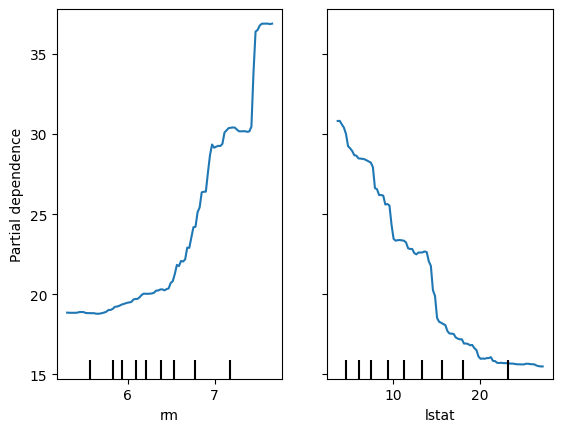
2) 두 feature의 예측값 비교
PartialDependenceDisplay.from_estimator(model, x_train, [('rm','lstat')])
plt.show()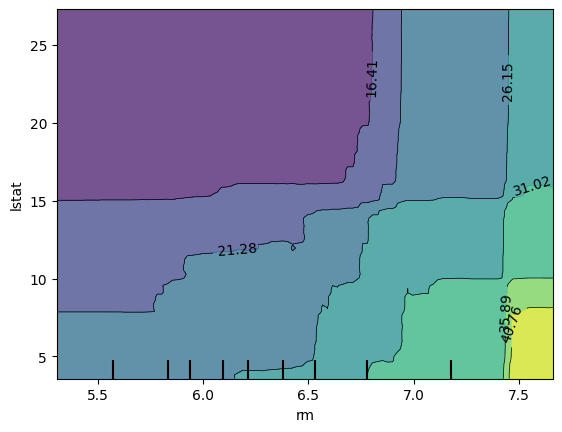
해석
x축 feature와 y축 feature에 따른 검은색 숫자가 모델의 예측 값이다.
