
변수 중요도란?
- 알고리즘 별 내부 규칙에서 나온 예측에 대한 변수 별 영향도 측정
- 성능이 낮은 모델에서의 변수 중요도는 의미없다
그 중에서도 트리기반 모델일 때의 변수 중요도를 확인해 본다.
Decision Tree
정보이득 (Information Gain)
: 부모 불순도 - 자식 불순도
: 니지 불순도가 감소하는 정도
👀 Mean Decrease Impurity (MDI)
Tree전체에 대해서, feature별로 information gain의 평균을 계싼
+ 트리 그려보기
plt.figure(figsize = (20, 8))
plot_tree(model, feature_names = x.columns,
filled = True, fontsize = 10)
plt.show()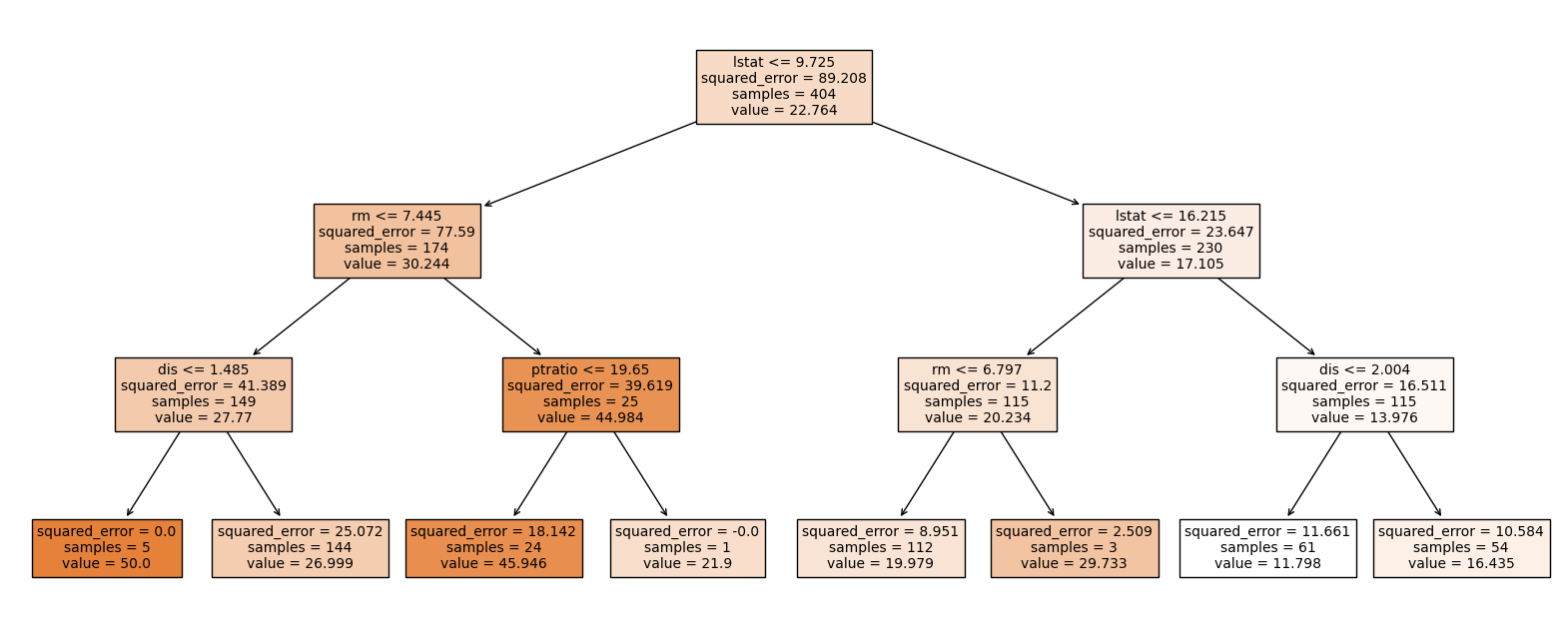
모델 만들기
from sklearn.tree import DecisionTreeRegressor, plot_tree
from sklearn.metrics import *
model = DecisionTreeRegressor(max_depth = 3)
model.fit(x_train, y_train)
###### 모델 최적화 시키기 ######
from sklearn.model_selection import GridSearchCV
params = {'max_depth':range(1, 10)}
model = DecisionTreeRegressor()
model_gs = GridSearchCV(model, params, cv = 5)
model_gs.fit(x_train, y_train)
모델 시각화
plt.figure(figsize = (20, 8))
plot_tree(model, feature_names = x.columns,
filled = True, fontsize = 10)
plt.show()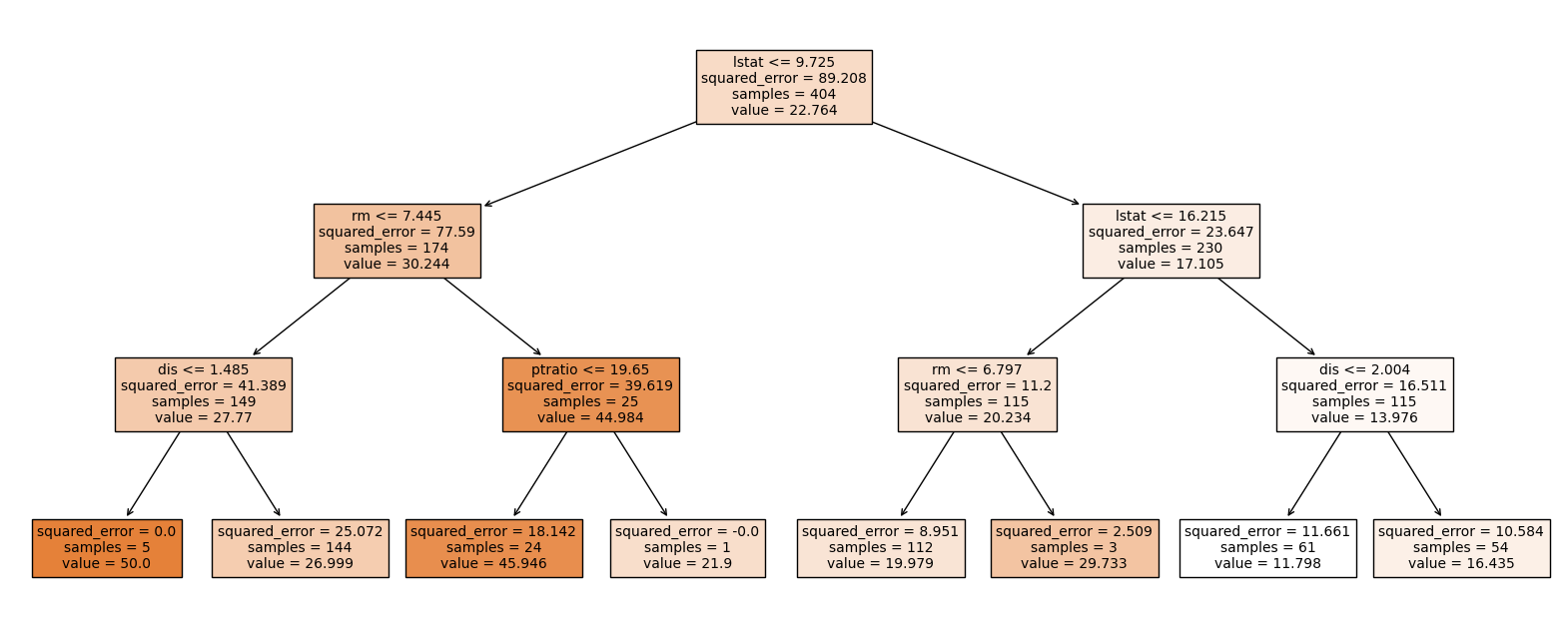
Random Forest
👀 Mean Decrease GINI
개별 트리의 변수 중요도의 평균 값, 여러 개 MDI의 평균
모델 만들기
from sklearn.ensemble import RandomForestRegressor, plot_tree
from sklearn.metrics import *
n_est = 3
model = RandomForestRegressor(n_estimators = n_est, max_depth = 2)
model.fit(x_train, y_train)모델 시각화는 생략
XGBoost
3가지 방법
👀 weight
- 모델을 만들 때 해당 feature가 split될 때 사용된 횟수의 합
plot_importance(model)에서 기본으로 사용 되는 변수 중요도
👀 gain
- feature별 평균 infomation gain
- model.
feature_importance에서 기본으로 사용
- total_gain: feature별 information gain의 총 합
👀 cover
- feature가 split할 때 데이터 개수의 평균
- total_cover : 데이터 수의 총 합
모델 만들기
from xgboost import XGBRegressor, plot_tree, plot_importance
model = XGBRegressor(n_estimators = 10, max_depth = 2, objective='reg:squarederror')
model.fit(x_train, y_train)
## 성능 튜닝한 모델 만들기 ##
params = {'max_depth': range(1,8,2), 'learning_rate':[0.01,0.05,0.1,0.2] , 'n_estimators' : range(50,151,20) }
model3 = GridSearchCV( XGBClassifier(), params, cv=3)
model3.fit(sm_x_train, sm_y_train)트리 그려보기
xgboost.plot_tree
: 트리 하나를 시각화
plt.rcParams['figure.figsize'] = 20,20
plot_tree(model, num_trees = 0, rankdir = 'LR') # num_trees: 트리 index번호 # rankdir : 데이터 순서 왼쪽 -> 오른쪽
plt.show()Example
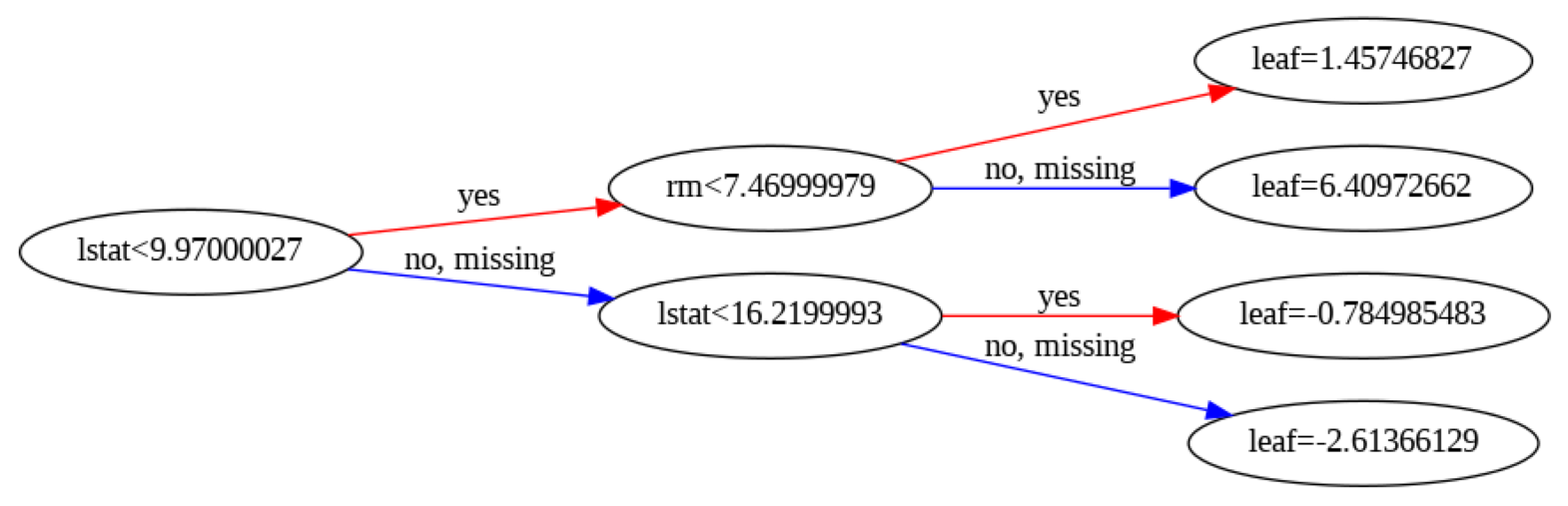
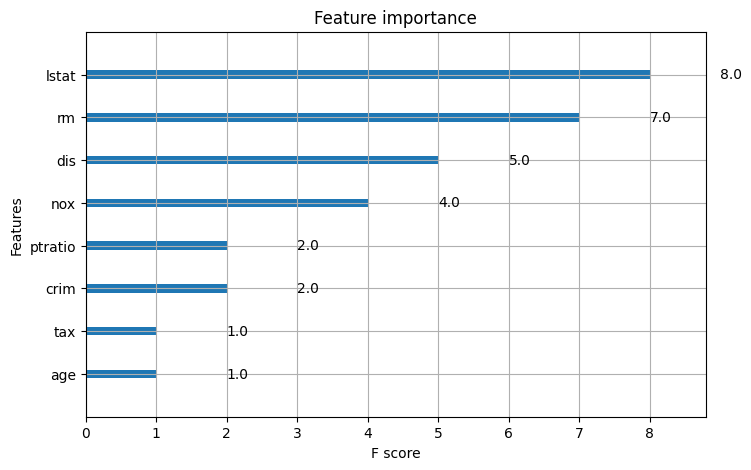
변수 중요도 파악
위의 3가지 모델에서 공통으로 사용 가능하다.
1) plot_importance
plt.rcParams['figure.figsize'] = 8, 5
plot_importance(model)
plt.show()Example
2) featureimportances
단, GridSearchCV/RandomSearchCV 처럼 튜닝한 모델은 model.beste
`model.best_estimator.featureimportances` 를 사용한다.
기타 기본 알고리즘 모델은 model.feature_importances_
여러 개의 트리가 사용된 알고리즘에서 개별 트리에 대한 변수 중요도를 확인하려면 model.estimators_[i].feature_importances_ 을 사용한다.
# 결과 예시 #
array([1.83099407e-02, 2.59194398e-04, 4.81881871e-03, 0.00000000e+00,
8.64670312e-03, 2.64339760e-01, 1.90288097e-03, 9.70646418e-02,
1.75885515e-04, 6.10459669e-03, 2.91424684e-02, 5.69235110e-01])값을 가지고 시각화를 하면 아래와 같이 만들 수 있다.
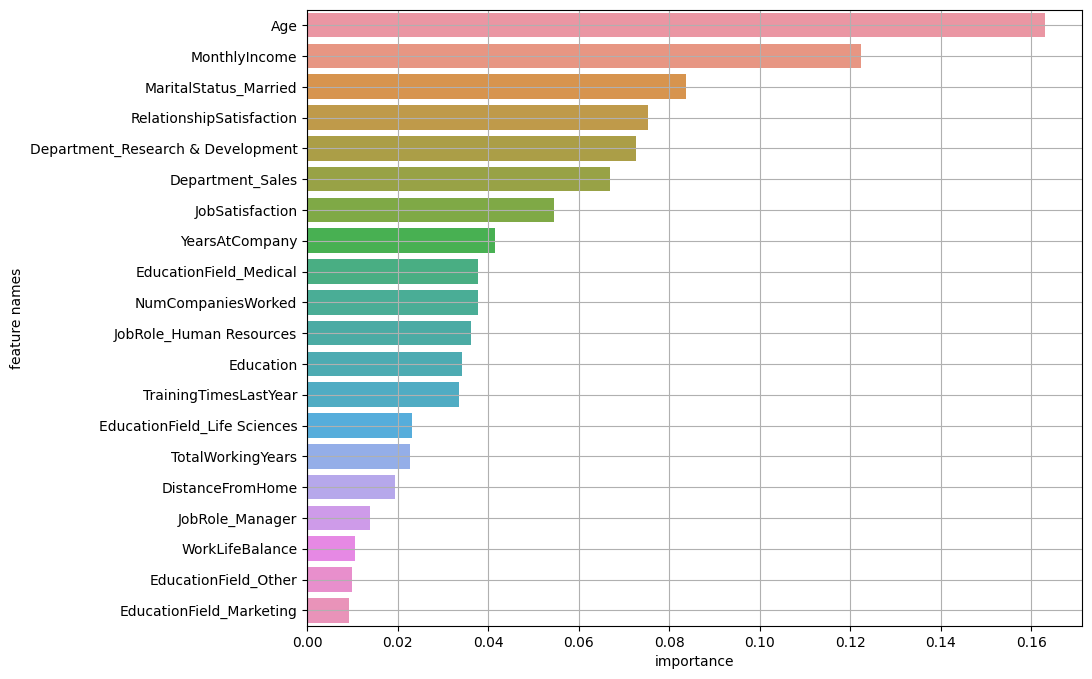

:)