
지난 글에서는 트리기반 변수 중요도를 파악하였고 오늘은 일반 모델의 변수 중요도로 활용 가능한 PFI(Permutation Feature Importance) 를 정리해 본다.
Permutation(순열)
A, B, C 3개가 있을 때 나열하는 경우 ex (A,B,C), (A,C,B) 는 다른 경우이다.
순서가 있는 나열
이론
Permutation Feature Importance (순열 변수 중요도)란?
Feature하나의 데이터를 무작위로 섞을 때 model의 성능이 얼마나 감소되는지 차이를 계산하여 변수의 중요도를 파악한다. 성능은 MAE, r-squared, accuracy 등을 의미한다.
이 것을 한 번 수행하지 않고 여러번 수행하여 평균으로 계산된다.
만약 성능이 많이 떨어진다면 그 변수의 중요도는 높다고 볼수 있다.
[공식]
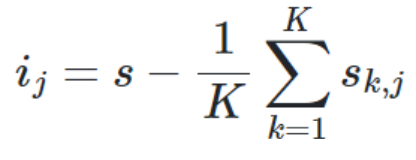
S: Score 예측된 평가 결과
j: Feature
Sk : k번째 예측된 평가 결과
=> 기존 Score에서 여러번 수행하여 평균낸 예측평가를 뺀다.
단점
다중 공산성이 있는 변수가 존재하면 결과가 정확하지 않다. 즉, Score값이 줄어들지 않을 수 있다.
이유는 선택한 변수가 섞이더라도 다른 변수가 그 의미를 갖고 있기 때문이다.
실습
보스턴 집값 데이터 예측하는 회귀문제
✔ permuation_importance 함수
매개변수
- model : 어떤 알고리즘이든 상관없음
- x: 독립변수 평가 데이터
- y: 종속변수 평가 데이터
- n_repeats: 반복하여 수행할 횟수,10이면 한 feature당 총 10번 섞인다.
- scoring : 회귀는 r2, 분류는 accuracy
- Output
- importances: feature별 반복 횟수만큼 계산 된 score값- importances_mean: 변수별 평균
- importances_std: 변수별 표준편차
1) SVM 모델 사용
from sklearn.inspection import permutation_importance
model1 = SVR() #SVM regressor
model1.fit(x_train, y_train)
pfi = permuation_importance(model1, x_val, y_val, n_repeats=10, scoring = 'r2', random_state=11)
pfi💠 리턴 된 pfi 결과 예시

x_val.columns 와 같이 어떤 값이 높은지 시각화하여 볼 수 있다.
🔸kdeplot & boxplot
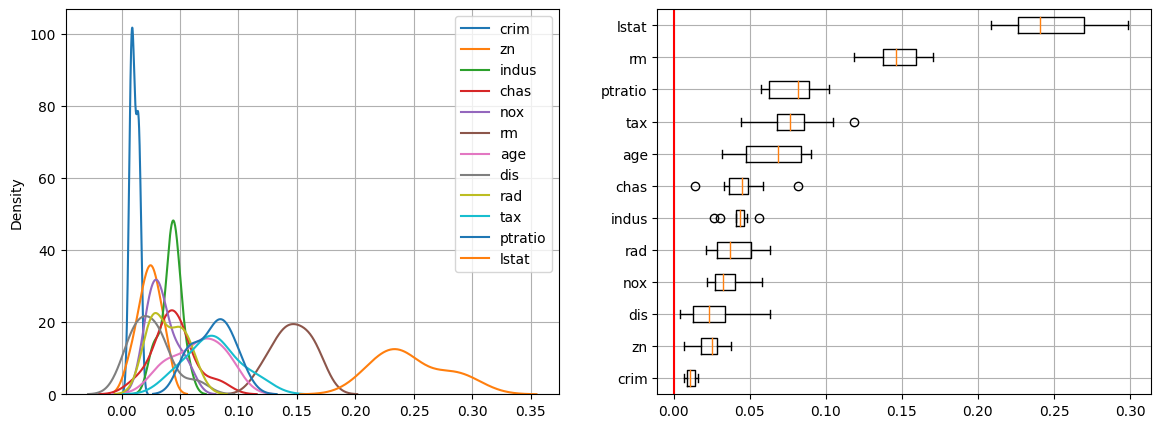
이 차트에서는 lstat, rm 변수 차이가 큼으로 모델 성능 평가에 영향도가 크고 crim은 변수 중요도가 낮다고 해석할 수 있다.
🔸importances_mean으로 barplot
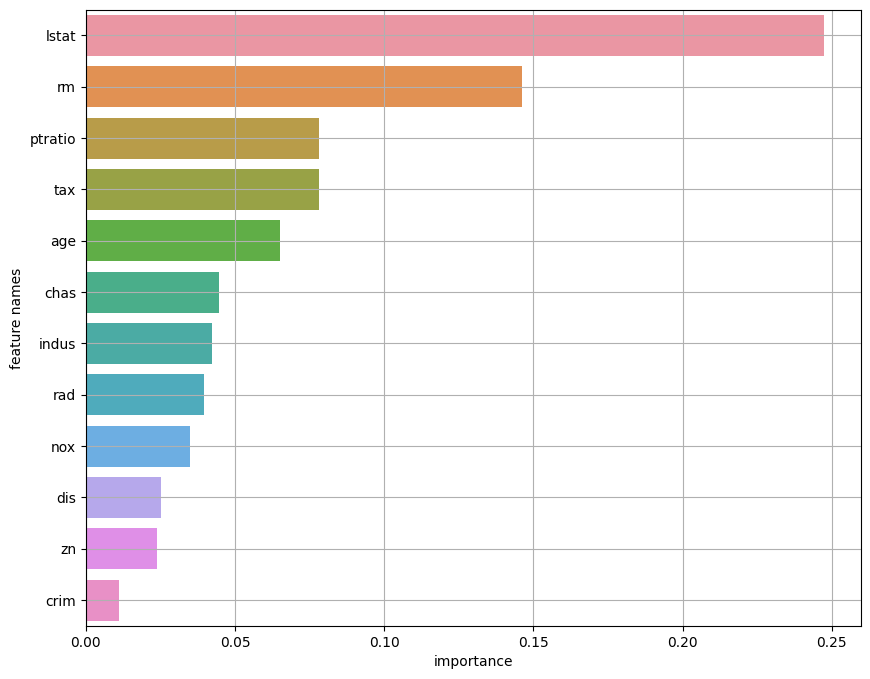
output중에 importances_mean으로 정렬해보면 변수들이 이와 같다.
2) 딥러닝 모델 사용
분류문제 예시
from keras import Input, Model
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.backend import clear_session
from keras.optimizers import Adam
clear_session()
### 1) 함수형 API방식
X = Input(shape=(x_train_s.shape[1])) #shape로 열 길이 가져온다
H = Dense(32, activation='swish')(X)
H = Dense(16, activation='swish')(H)
Y = Dense(1,activation='sigmoid')(H)
model = Model(X,Y)
### 2) 순차 Sequential 방식
model = Sequential([Dense(32, input_shape = [x_train_s.shape[1],], activation = 'swish'),
Dense(16, activation = 'swish'),
Dense(1, activation = 'sigmoid')
])
model.compile(optimizer=Adam(learning_rate=0.0001), loss='binary_crossentropy')
history = model.fit(x_train_s, y_train, epochs=50, validation_split=.2).history
➕ deep learning 모델에 대해서는 분류/회귀 상관없이 명시적으로 scoring = 'r2'을 지정해 줘야한다. 왜냐면 딥러닝은 결과가 회귀/분류의 구분이 명확하지 않고 분류도 확률 값으로 나오기 때문에 오차를 측정하는 r2를 사용한다.
pfi2 = permutation_importance(model, x_val, y_val, n_repeats=10, scoring = 'r2')pred5 = np.where(pred5 >= .5, 1, 0) #.5이상이면 1 아니면 0으로 변경 / 딥러닝은 결과가 0, 1 로 떨어지지 않고 %가 나오기 때문
print(confusion_matrix(y_val, pred5))
print(classification_report(y_val, pred5))딥러닝 모델도 위에 SVM 모델과 동일하게 시각화 할 수 있다.
