Nextjs 캐싱 전략
Nextjs의 캐싱 메커니즘은 매우 복잡하다.
이로 인해 개발과정에서 의도치 않은 캐싱 결과로 당황한 적이 있을 것이다.
Nextjs 캐싱이 어떻게 작동하는지에 대해 알아보자.
1. Request Memoization
CRA 또는 vite를 이용하여 생성한 react SPA에서 여러 컴포넌트에서 동일한 api요청을 보낼 경우 개발자는 고민하게 된다.
아마도 대부분의 개발자들은 데이터가 필요한 상위 컴포넌트에서 api요청을 한 후에 하위 컴포넌트로 데이터를 props로 전달을 하거나 drilling이 심할 경우 아니면 그냥 동일한 요청을 복수의 컴포넌트에서 실행하여 이 문제를 해결한다.
그러나 이는 당연하게도 좋지 않은 방법이다.
이부분에서 Request Memoization가 등장한다.
Request Memoization은 랜더사이클에서 RSC(리액트서버컴포넌트)에서 수행하는 모든 fetch 요청을 캐싱하는 React의 기능이다.
랜더사이클에서 한 서버컴포넌트에서 발생한 fetch 요청을 다른 서버컴포넌트에서 다시 요청하는 경우 두 번째 요청은 서버에 요청하지 않고 캐싱된 값을 받게된다.
async function getItem() {
// `fetch` 함수는 자동으로 memoized되며 결과값이 캐싱된다.
const res = await fetch('https://.../item/1');
return res.json();
}
// 컴포넌트 A
const item = await getItem(); // cache MISS
// 컴포넌트 B
const item = await getItem(); // cache HIT : getItem 함수의 실행 없이 캐싱된 return값을 받는다.

모든 랜더링과정이 완료되면 메모리는 리셋되고 다음 랜더링과정에서 동일한 요청이 발생할 경우 fetch함수가 실행된다. 따라서 개발자는 랜더사이클마다 일일히 revalidation을 하지 않아도 된다.
Request Memoization은 오직 fetch에서만 가능하다. 흔히 사용하는 axios는 추가적이 작업이 필요하다(아래 fetch함수를 사용하지 않는 요청들)
이는 Nextjs에서 fetch함수를 지들 맘대로 기능을 추가해 확장했기 때문이다.
또한 Request Memoization는 리액트의 기능이므로 RSC에서만 적용된다. 따라서 nextjs에서 제공하는 route handler에서 fetch를 사용해도 Request Memoization되지 않는다.
fetch함수를 사용하지 않는 요청들
fetch 함수를 사용하지 않는 경으, axios를 사용하거나 데이터베이스 요청시 캐싱하고 싶은 경우 어떻게 할까?
이를 위해 React의 cache 함수를 사용할 수 있다.
import { cache } from 'react';
import { queryDatabase } from './databaseClient';
const fetchUserData = cache((userId) => {
const data = queryDatabase('SELECT * FROM users WHERE id = ?', [userId]);
return data;
});
export default async function UserPage({
params,
}: {
params: { user_id: string },
}) {
const { user_id } = params;
const user = fetchUserData(user_id);
return (
<ul>
<li>{user.name}</li>
<li>{user.id}</li>
<li>{user.email}</li>
<li>{user.address}</li>
</ul>
);
}cache 함수로 db 요청 로직을 감싸주면 RSC에서의 fetch와 동일한 기능을 한다.
Opting out
그럴일은 거의 없겠지만 이러한 Request Memoization 기본설정을 해제하기 위해서는 다음과 같이 AbortController를 사용하면 된다.
async function fetchUserData(userId) {
const { signal } = new AbortController();
const res = await fetch(`/api/users/${userId}`, {
signal,
});
return res.json();
}2. Data Cache

Request Memoization는 중복 fetch 요청을 방지하여 앱 성능을 높이는 데 유용하지만, 랜더사이클 마다 캐시가 리셋이 된다.
이부분에서 Data Cache가 등장한다.
만약 데이터의 변화가 거의 발생하지 않는 GET요청의 경우 매번 데이터를 api서버로부터 가져오는 것은 매우 비효율적이다.
기본적으로 RSC의 모든 fetch 요청은 Data Cache(서버에 저장)가 되며 이 후의 모든 요청은 캐싱된 값을 사용한다.
즉, 100명의 사용자가 모두 동일한 데이터를 요청하는 경우 Nextjs는 단 한번의 api요청이 발생하고 다음 100명의 사용자 모두에게 캐싱된 데이터를 사용한다.
Data Cache는 Nextjs에 설정을 해주지 않는 한 캐시가 절대 지워지지 않는다는 점에서 Request Memoization와 다르다.
이 캐싱데이터는 배포한 후에도 지워지지 않기 때문에 적절한 세팅이 반드시 필요하다.
Revalidation
Data Cache는 기본적으로 절대 지워지지 않으므로 Revalidation이 중요하다.
Nextjs에서 이를 수행하는 두 가지 방법이 있다
Time-based Revalidation
시간 기반 revalidation은 일정시간 후에 캐싱을 리셋하는 방법이다.
여기에는 두가지 방법이 있다.
const res = fetch(`api/species`, {
next: { revalidate: 3600 }, // 1시간 후 revalidation
});또는
export const revalidate = 3600;
export default async function Page({ params }) {
const res = await fetch('api/species');
const species = await res.json();
return (
<ul>
{species.map((elemenet) => (
<li key={element.id}>{element.name}</li>
))}
</ul>
);
}
첫 fetch 요청이 이뤄지면 데이터를 가져와서 캐싱한다.
설정한 1시간 재검증 시간 내에 발생하는 각각의 새로운 fetch요청은 캐싱된 데이터를 사용한다.
그런 다음 1시간 후에 첫 fetch 요청의 경우 캐시된 데이터를 반환하고 새로 업데이트된 데이터를 가져와 캐시에 저장한다. (stale-while-revalidate)
이 후의 요청은 새롭게 캐시된 데이터를 사용하게 된다.
On-demand Revalidation
새로운 데이터가 추가 되었거나 특정 이벤트가 발생한 경우에만 캐시를 무효화하고 새로운 데이터를 가져오는 방법이다.
이 역시 두가지 방법이 있다.
import { revalidatePath } from 'next/cache';
export async function addSpecies(newSpecies: string) {
db.species.add(newSpecies); // db에 새로운 종을 더하는 로직
revalidatePath('/api/species'); // addSpecies 이벤트가 발생할 경우 캐싱을 무효화한다.
}또는
// GET요청 부분에서 tag를 달아준다.
// 리액트 쿼리에서 queryKey를 설정해주는 것과 유사하다.
const res = await fetch('api/species', {
next: { tags: ['species'] },
});import { revalidateTag } from 'next/cache';
export async function addSpecies(newSpecies: string) {
db.species.add(newSpecies); // db에 새로운 종을 더하는 로직
revalidateTag('species'); // 특정 태크의 GET요청의 캐시를 무효화
}
Opting out
Nextjs 입문자들은 이 Data Cache의 기본 행동 때문에 당황하곤 한다.(내가 그랬다)
데이터베이스의 변화가 발생했는데 계속 캐싱된 데이터만 전달이 되기 때문이다.
데이터가 실시간으로 바뀌는 경우 이러한 캐싱 전략 자체가 무의미하다.
따라서 적절한 revalidation방법과 기본 행동을 끄는 방법을 알아야 한다.
이역시 다양한 방법이 존재한다.
// RSC 상부에
export const dynamic = 'force-dynamic';export const revalidate = 0;위의 두 경우는 동일하며 해당 컴포넌트에서 발생하는 모든 요청에대해서 캐싱을 하지 않게 된다.
또는
const res = await fetch('api/species', {
cache: 'no-store',
});위의 경우 특정 요청에 대해서만 캐싱을 하지 않겠다 설정이 가능하다
또는
import { unstable_noStore as noStore } from 'next/cache'; // 아직 안정화되지 않음 (14.1기준)
function getSpecies() {
noStore();
const res = await fetch('api/species');
}
fetch함수를 사용하지 않는 요청들
앞서 Request Memoization에서는 react의 cache 함수를 사용하였다.
Data Cache에서는 이와 유사하나 next에서 제공하는 cache함수를 사용한다.
그러나 이 함수는 14.1버전기준 unstable하다.
import { getSpecies } from './data';
import { cache as unstable_cache } from 'next/cache';
const getCachedGuides = cache(() => getSpecies(), ['species']); // 첫번째 인자는 캐싱할 함수, 두번째는 캐싱 키
export default async function Page() {
const species = await getCachedGuides();
// ...
}3. Full Route Cache
세 번째 유형의 캐싱는 Full Route Cache이며, 이름 그대로 해당 route를 캐싱해버리는 기능이다.
Next.js가 빌드 과정에서 static한 html과 RSC payload를 생성하여 캐싱하는 것을 말하며 따로 설정할 필요가 없다. 이는 마치 정적 페이지를 생성하는 것과 유사하다.
import Link from 'next/link';
async function getPosts() {
const res = await fetch('https://jsonplaceholder.typicode.com/posts');
const posts = await res.json();
return posts;
}
export default async function Page() {
const posts = await getPosts();
return (
<div>
<h1>Posts</h1>
<ul>
{posts.map((post) => (
<li key={post.id}>
<Link href={`/posts/${post.id}`}>
<a>{post.title}</a>
</Link>
<p>{post.body}</p>
</li>
))}
</ul>
</div>
);
}위의 코드는 fetch요청을 하지만 해당 api의 url을 보면 동적인 데이터를 포함하지 않는다.
따라서 nextjs는 이를 자동으로 빌드과정에서 캐싱한다.
Data Cache와는 다르게 Full Route Cache는 빌드시에 revalidation이 초기화 된다.
Opting out
Data Cache와 동일하다.
또는 fetch요청에서 동적인 데이터를 포함한 경우 당연히 캐싱이 되지 않는다.
4. Router Cache
지금까지는 모두 서버에서 발생하는 캐싱이였다면 Router Cache는 클라이언트에 발생하는 캐싱이다.
import Link from 'next/link';
async function getPosts() {
const res = await fetch('https://jsonplaceholder.typicode.com/posts');
const posts = await res.json();
return posts;
}
export default async function Page() {
const posts = await getPosts();
return (
<div>
<h1>Posts</h1>
<ul>
{posts.map((post) => (
<li key={post.id}>
<Link href={`/posts/${post.id}`}>
<a>{post.title}</a>
</Link>
<p>{post.body}</p>
</li>
))}
</ul>
</div>
);
}위의 코드에서 "/posts/1", "/posts/2", "/posts/3"... 로 route를 탐색할 때 Next.js는 방문한 route 별로 캐싱하여 다음 해당 route를 방문할 때 캐싱된 데이터를 받는다.
또한 방문하지 않은 route여도 화면에 <Link> 요소가 보인다면 미리 prefetch되어 캐싱된다.

Opting out
위에서 언급한 revalidatePath, revalidateTag를 사용하거나
'use client';
import { useRouter } from 'next/navigation';
export default async function AddPostDialog() {
const router = useRouter();
const onSubmit = async (post) => {
db.post.add(post);
router.refresh();
};
return (
<div>
<h1>Add Post</h1>
...
</div>
);
}정리
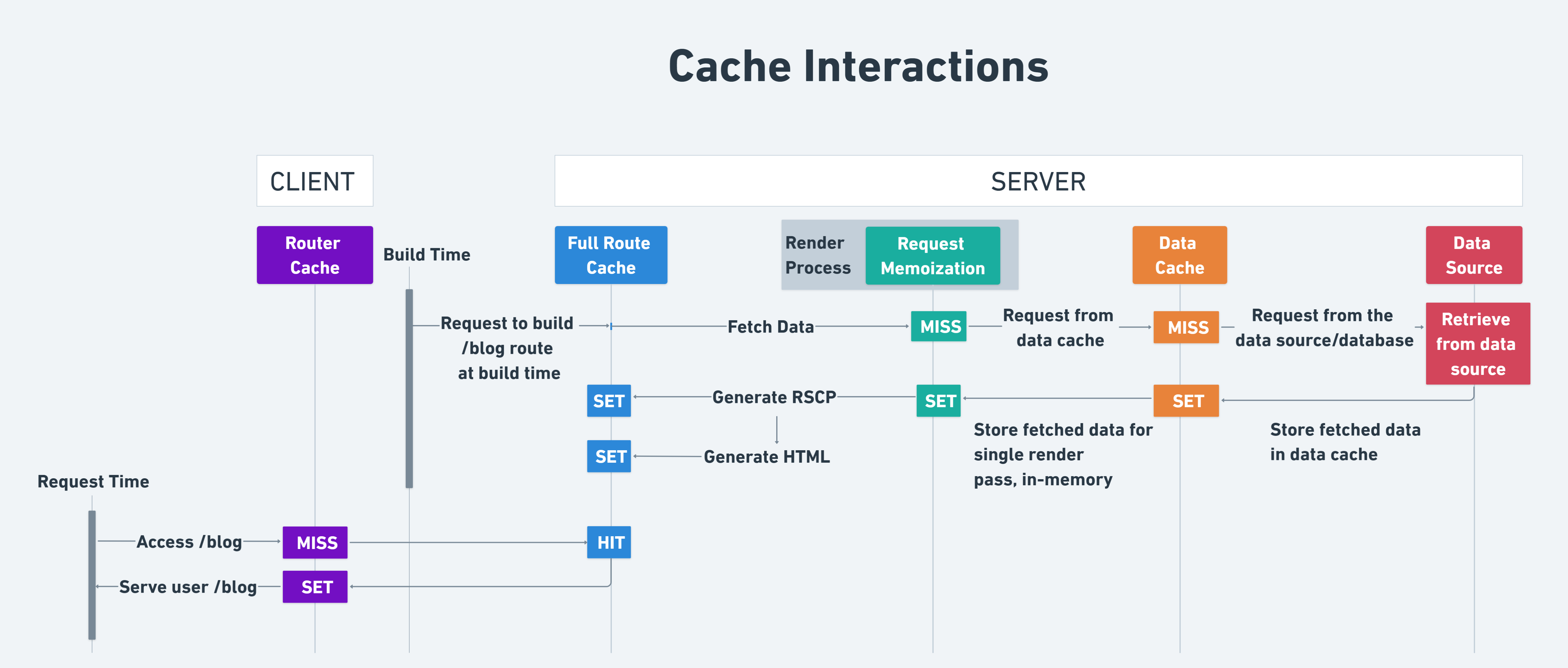
| 캐싱방법 | 캐싱대상 | 설명 | 장소 | revalidation |
|---|---|---|---|---|
| Request Memoization | 함수 리턴값 | Re-use values in same render pass for efficiency | 서버 | only lasts for the lifetime of a server request |
| Data Cache | Data | Stores data across user requests and deployments | 서버 | Time-based or on-demand revalidation |
| Full Route Cache | HTML, RSC payload | Caches static routes at build time to improve performance | 서버 | Revalidated by revalidating Data Cache or redeploying the application |
| Router Cache | RSC payload | Stores navigated routes to optimize navigation epxerience | 클라이언트 | Automatic invalidation after a specific time or when the data cache is cleared |
