Intro
-
기존
DAG에서PythonOperator에 전달할 함수를dags에 작성하다 보니 코드길이가 길어지고 가독성 측면에서 좋아보이지 못했다.Airflow가 사용할common fuction을 작성했다.AirFlow가 인식하는 파일 디렉터리들을 확인하고,common fuction을import할 수 있게 디렉토리를 설정했다.
-
datetime을 이용하여 날짜를 전달하는 방식이UTC를 적용하여 한국시간에 맞지 않았다.**kwargs변수에 저장된template변수를 사용해서 해결했다.
🏹 1. DAG 정리하기
🎯Airflow 의 Python_path
-
컨테이너 내부에서
airflow info명령어를 통해 확인할 수 있었다. -
/opt/airflow/plugins경로까지 모듈이 있는지 확인하는 것을 확인할 수 있다. (plugins 까지 참조한다는 뜻) -
common디렉토리를 추가하면 의도대로airflow가dags를parsing할때, 해당common fuction을 찾을 수 있을 것이다.

-
추가적으로 해당
airflow버전과 맞는Providers info버전까지 친절하게 설명해놓았다. 여러가지로 아주 편하지 않지 않을수 없는..
🎯common 디렉터리와 **kwargs
-
의도대로
common디렉터리를 작성하고 그 아래에airflow가 사용할 함수를 위치시켰다. 해당 함수는 추후에spark-submit방어 로직을 설계할 때도 사용할 예정이다!
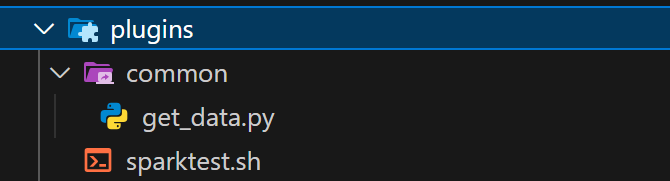
-
get_data함수도 수정을 해주었다.scheduler는 일정 시간마다 dags를 파싱하는데, 함수 내부 내용은 검토하지 않는다. 이는 함수 외부에서import를 해오는 것보다 스케쥴러에 부담을 경감시킬 수 있는 방법이라고 한다.- 해당 함수는
PythonOperator에 전달할 함수이다. 해당 오퍼레이터에 함수를 전달하면 직접 인자로 주지 않아도 기본적으로**kwargs에 여러 변수들을 딕셔너리 형태로 저장해 놓는다. 그중data_interval_end : 배치일자의 한국시간을 그냥 꺼내서 사용할 수 있다.
def get_data(api_key,**kwargs):
# schedule 부하 줄이기
import time
import requests
import json
from pprint import pprint
pprint("common fuction의 데이터 수집 함수를 호출합니다.")
# airflow에서 Batch 시점(data_interval_end)에 한국시간
target_date = kwargs["data_interval_end"].in_timezone("Asia/Seoul").strftime("%Y-%m-%d")🎯수정된 dags와 함수에 전달할 인자
- 함수에 전달할 인자는
op_args에 리스트형태로 전달할 수 있다.api-key는 그대로airflow가 직접 입력하도록 한다.
from common.get_data import get_data
#[ get_data_task ]
get_data_ = PythonOperator(
task_id = "get_data_",
python_callable=get_data,
op_args=[api_key]
)🎯완성된 dags
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.operators.bash import BashOperator
from airflow.models import Variable
import pendulum
from common.get_data import get_data
# params
# api key
api_key = Variable.get("apikey_openapi_nexon")
# DAG
with DAG(
dag_id = "dags_get_data_python_operator",
schedule= "0 6 * * *",
start_date= pendulum.datetime(2024,12,11, tz = "Asia/Seoul"),
catchup=False
) as dag :
#[ get_data_task ]
get_data_ = PythonOperator(
task_id = "get_data_",
python_callable=get_data,
op_args=[api_key]
)
#[ data_Refine_task ]
# sparkjob script
file_name = "/opt/airflow/jobs/sparktest.py"
refine_data_ = BashOperator(
task_id = "refine_data_",
bash_command=f'/opt/airflow/plugins/sparktest.sh {file_name}'
)
# task flow
get_data_ >> refine_data_🎯정리된 디렉터리 구조
.
├── LICENSE
├── README.md
├── config
│ └── airflow.cfg
├── dags
│ ├── dags_bash_operator_test.py
│ └── datapipline.py
├── data
├── docker-compose.yaml
├── dockerfile
├── jobs
│ ├── spark_common
│ │ └── spark_filter.py
│ └── sparktest.py
├── notebooks
├── plugins
│ ├── common
│ │ └── get_data.py
│ └── sparktest.sh
└── resources-
config:airflow.cfg파일export하고 마운트해서 사용중이다. -
dags:airflow가parsing할 dags들 위치시키는 디렉토리이다. -
data:airflowtask로 수집한 데이터를 위치시키고,spark가 읽어갈 디렉토리 -
jobs:spark의python경로도jobs까지 인식한다. 그래서 해당 경로에sparkjob을 실행할 공통함수들을 작성해둔다.
spark 스크립트에서sys.path로 찍어보면 확인 가능하다.airflow도 처음에 컨테이너 빌드할때/opt/airflow/jobs와 맵핑을 해두었다. 해당경로의python파일을bash커맨드에 전달할 수 있다. 개발하면서 느낀점이지만 해당 부분을 잘 맵핑해두면local의 디렉토리를 컨테이너가연결 통로 처럼사용할 수 있어서 코드짤때 편한것 같다.
opt/airflow/jobs는 기본적으로 컨테이너에 존재하지 않던 디렉토리이다..!
-
plugins:airflow에서 실행할 스크립트들을 모아두는 디렉토리이다. -
resource: 써드파티앱 (elastic search혹은MySQL을 위한.jar파일이 위치할 예정이다.
🏹 2. NEXT?
-
Spark job을 작성하기전 데이터 베이스를 설계해야한다.- 단순한 데이터 시각화역시 데이터모델을 잘 설계해야하고,
- 추후에 해당 데이터들을 이용해서 서비스를 개발할때도 필수적으로 필요하다.
-
대략적인
요구분석을 하는 과정에서
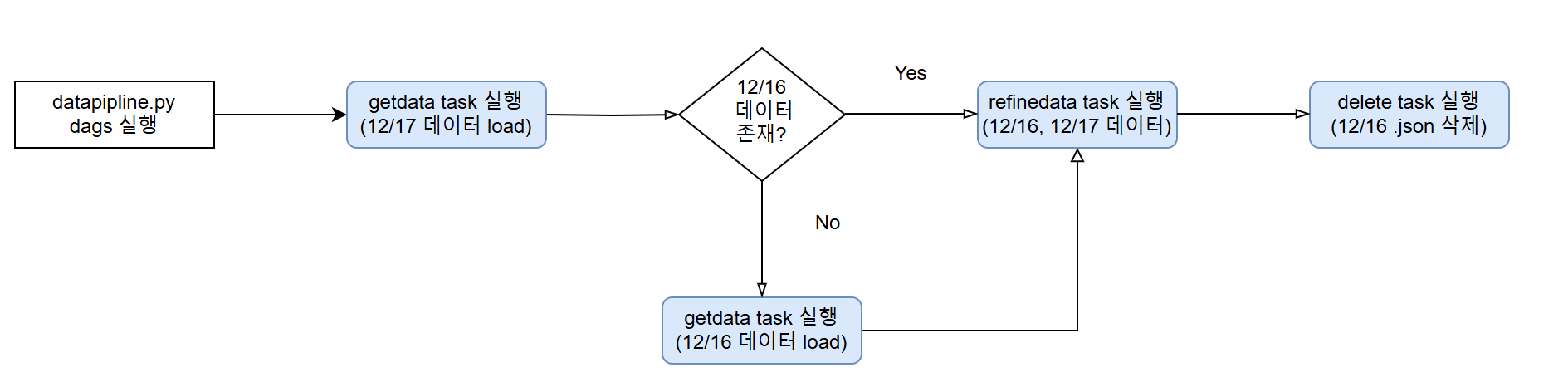
- 1) 정제를 하는 일자의 데이터와 그 전날의 데이터 가 필요하다는 생각이 들었다.
ex)
get_data(12/17 데이터 수집)->refine_data(12/16일 데이터와 12/17데이터 필요)
branch
1) 만약 데이터가 둘다 존재한다면 -> 해당 일자의Batch끝
2) 만약16일데이터가 없다면 ->get_data(12/16 데이터)수집 ->refine_data수행 ->Batch끝 - 2)정제하고 데이터베이스에 저장됐다면 그 전날 데이터는 필요 없게 된다 따라서 전날의 데이터는 삭제해주어야 한다.
ex) 새로운
task = delete_data추가 위에서 실행한Batch가 종료된 후에 로컬에 저장된전날의.json삭제
- 1) 정제를 하는 일자의 데이터와 그 전날의 데이터 가 필요하다는 생각이 들었다.
- 결론 : 할것도 생각할 것도 많다 !
