Intro
- 분석할 데이터를 구상하는 과정에서 어떤 비교를 위해
Batch일의 data와Batch 전날의 데이터를 동시에 이용해야했다.
일종의 방어로직으로 전날 데이터를 수집하지 못한다해도
DAG가 잘 작동하게 하고 싶었다.
- 이를 위해 특정 조건에
task를 진행하는BranchOperator를 이용하면 됐고, 이에 전달할함수를 새로 작성해야 했다.- 함수의 재활용성을 높이고자
Batch일의 데이터 뿐만 아니라Batch전날의 데이터를 수집할 수 있도록 수정해야 한다.
🏹 1. Airflow Task에 전달할 함수 수정
🎯BrachOperator의 callable 함수
glob모듈을 사용해서 데이터를 저장한 디렉터리를 탐색할 예정이라 파일명을 정하기 위해dateutil을 이용한 날짜 계산을 해주었다.
def check_dir(root_dir:str="/opt/airflow/data",**kwargs)->str:
from pprint import pprint
from dateutil.relativedelta import relativedelta
from glob import glob
# kwargs에 저장된 배치일에서 하루 전날을 계산
target_date = kwargs["data_interval_end"].in_timezone("Asia/Seoul") + relativedelta(days=-1)BranchOperator에서 함수의 조건을 세우는 것도 중요한 것은 맞지만,return값을 잘 설정해주어야 한다는 점이다.
target_date = target_date.strftime("%Y-%m-%d")
# 디렉토리에 존재하는 파일 목록을 담을 객체
data_list = glob(f"ranking_{target_date}.json", root_dir = root_dir )
# 하루전날 데이터가 존재하지 않는다면
if not data_list:
print(f"{target_date}-어제의 데이터가 디렉터리에 존재하지 않습니다.")
return "get_yesterday_data"
else:
print(f"{target_date}-어제의 데이터가 디렉터리에 존재합니다!")
return "refine_data_"🎯 API로부터 데이터를 수집하는 함수
-
해당 함수는 원래
Batch일의 데이터만 수집하는 함수였으나, 전날의 데이터까지 수집하는 함수로 재활용하려한다. -
다른 함수를 작성할 수 있었지만,
target_date부분만 잘 전달하면 되기에 다음과같이 함수를 수정했다. -
dags에서 인자로batch일의data를 수집하는지,batch 전일의data를 수집하는지 주어진다면, 해당 부분을 보충하기에 충분했다.
# api 로부터 데이터 수집하는 함수
def get_data(api_key,day:str,**kwargs):
# schedule 부하 줄이기
import time
from dateutil.relativedelta import relativedelta
import requests
import json
from pprint import pprint
pprint("common fuction의 데이터 수집 함수를 호출합니다.")
# airflow에서 Batch 시점(data_interval_end)에 한국시간
# 데이터 수집일 API 호출
if day == "today":
target_date = kwargs["data_interval_end"].in_timezone("Asia/Seoul").strftime("%Y-%m-%d")
# 배치일 6시
pprint(f"{target_date} 의 rankingdata 호출을 시작합니다.")
# 데이터 수집 전날 API 호출
if day == "yesterday":
target_date = kwargs["data_interval_end"].in_timezone("Asia/Seoul") + relativedelta(days=-1)
target_date = target_date.strftime("%Y-%m-%d")🏹 2. DAG파일 수정과 task의 연결
🎯BranchPythonOperator의 활용
- 해당 테스크의
python함수로부터 어떤str이 리턴되며 해당 문자열이 다음에 실행시킬task를 지정한다.
# [ check_dir_task ] - branch !
check_dir_ = BranchPythonOperator(
task_id="check_dir_",
python_callable=check_dir
)get_data함수를 수정해주었고, 인자로 어느 시기의 data를 수집하는지 알려주어야 하기 때문에 다음과같이op_args를 수정했다.
# [ get_yesterday_data_task ]
get_yesterday_data = PythonOperator(
task_id="get_yesterday_data",
python_callable=get_data,
op_args=[api_key,"yesterday"]
)🎯 추가된task의 연결
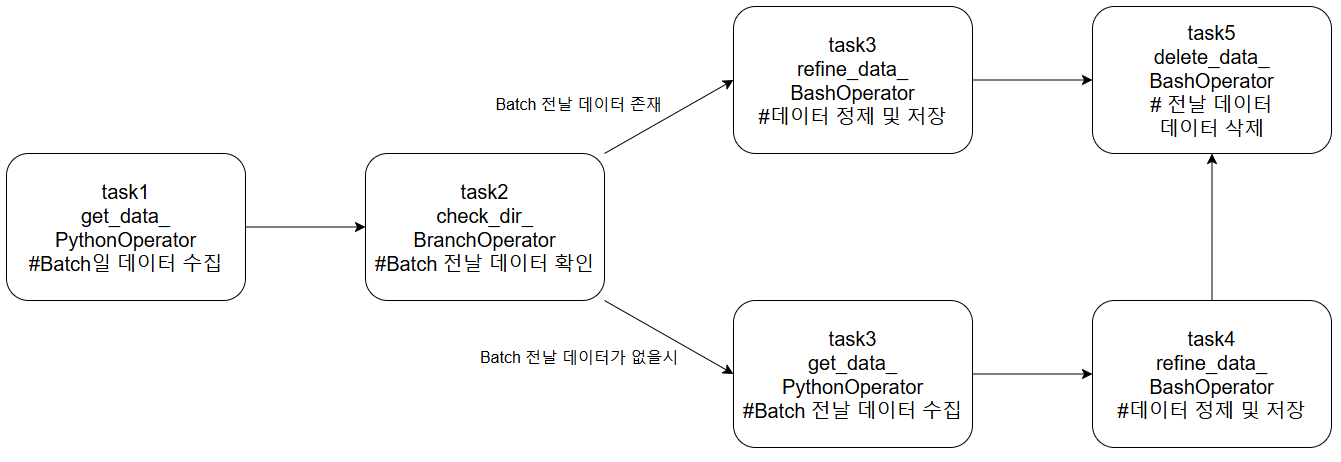
1) DAG에 작성된 task의 흐름
1) Batch일의 data를 수집하고, director에서 batch전일의 data가 존재하는지 확인한다.
2) Batch일의 data가 존재한다면, 데이터를 정제하고 전날의 데이터를 삭제한다.
3) Batch전날의 data가 없다면, Batch전날의 데이터를 수집하고 2)의 과정을 진행한다.
# task flow
get_data_ >> check_dir_ >> get_yesterday_data >> refine_data_ >> delete_data_
get_data_ >> check_dir_ >> refine_data_ >> delete_data_2) trouble 발생
DAG이 의도대로 작동하는지 확인하기 위해 batch 전날의 데이터가 없는경우와 있는경우를 테스트해보았다.- 데이터가 없는 경우에는 의도대로 작동했으나, 데이터가 이미 존재하는 경우에
refine_data_작업을skip하는 것이었다.
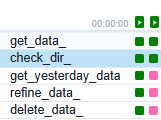
3) trigger_rule과 task를 실행하는 방식
airflow의task상위 스트림의task가 모두 성공해야 다음task를 실행하는 것이 규칙이다.
- 앞선 스트림
get_yesterday_date가success처리가 되지 않아 뒤따르는task가 성공하지 못함
- 앞선 스트림이 모두
success처리가 되어 뒤따르는task가 실행되고 성공함


- 이 경우
trigger_rule파라미터를 이용해 해결했다.
| 값 | 동작 방식 |
|---|---|
| all_success | 모든 상위 Task 실행 성공 |
| all_failed | 모든 상위 Task가 실행 실패, 또는 upstream_failed 상태 |
| all_done | 모든 상위 Task 실행 완료 |
| one_failed | 하나 이상의 상위 Task 실패.모든 상위 Task의 실행 완료를 대기하지 않는다. |
| one_success | 하나 이상의 상위 Task 성공.모든 상위 Task의 실행 완료를 대기하지 않는다. |
| none_failed | 모든 상위 Task가 실패 또는 upstream_failed가 아니다.모든 Task가 성공했거나 건너뛴 경우. |
| none_failed_min_one_success | 모든 상위 Task가 실패 또는 upstream_failed가 아니고 하나 이상의 상위 Task가 성공 . |
| none_skipped | 건너뛴 상위 Task 없음.모든 Task가 성공, 실패 또는 upstream_failed 상태여야 한다. |
| always Task | 종속성 없이 항상 실행 |
- 이중 가장 적합한것이
one_success라 생각이들어 해당 부분을refine_data_테스크의parameter로 지정해주었다.
#[ data_refine_task ]
file_name = "/opt/airflow/jobs/sparktest.py" # sparkjob script
refine_data_ = BashOperator(
task_id = "refine_data_",
bash_command=f'/opt/airflow/plugins/sparktest.sh {file_name}',
trigger_rule="one_success"
)
- 의도대로 잘 실행되는 모습
- 데이터가 이미 존재해서
batch 전일의 데이터를 수집할 필요가 없는 경우에도 잘 작동된다.


🏹 3. Next
DAG를 이용한 데이터의 파이프라인의 틀이 완성됐다. 이제 정말로 필요한것은pyspark를 이용한 데이터 정제Spark의optimization데이터 모델작성third party app의 컨테이너 빌드와 연결이 남았다.
