rankingflow (DATA PIPLINE PROJECT)
1.start
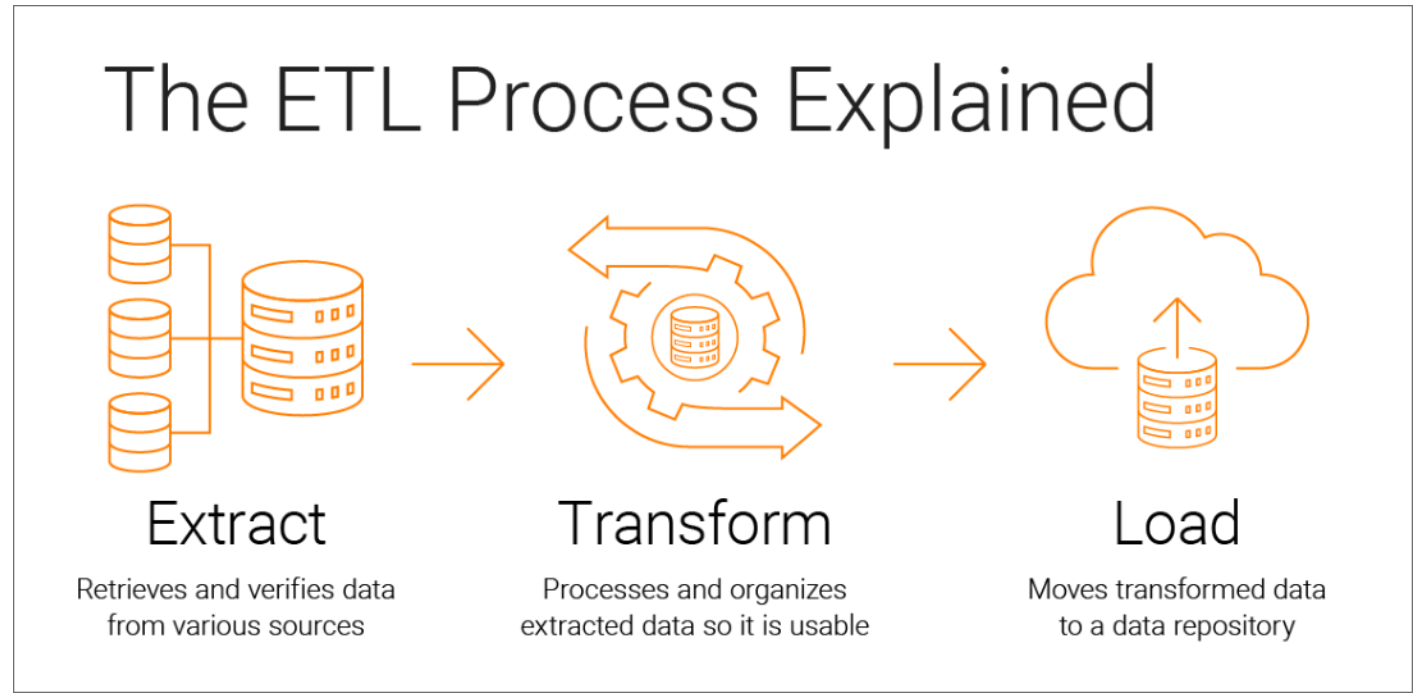
Nexon Open API의 랭킹데이터로 부터 만들 수 있는 데이터 모델과 패치에 따른 변화양상을 한번 확인해 보고 싶었다.ETL 과정을 AIRFLOW를 이용하여 구축해보고 DAG를 개발해볼 예정이다.데이터 처리에는 pyspark, 데이터 저장과 시각화는 elastic
2.Airflow 환경 설정
airflow에서 제공하는 공식 docker-compose.yaml 을 통해 빌드하였다.컨테이너 빌드하는 과정에서 airflow UID를 설정하라는 메세지가 나오면서 처음에 빌드가 되지 않았다. docker compose 파일만 다운받고 빌드하려니 문제가 생겼던것 같다
3.PythonOperator
ETL 과정중 첫번째로 해야할 부분이 데이터를 추출해내는 것이다.내가 즐겨하는 게임사의 OpenAPI를 이용하려고하고 KEY는 사전에 발급을 받았다.데이터를 요청하는 방식은 친절하게 설명이 되어 있었다.https://openapi.nexon.com/ko/Pyt
4.Spark 환경구축 with bash

PythonOperator을 통해 airflow환경에서 외부 데이터를 수집하고 로컬에 저장하는 과정까지 완성이 됐다.ETL 과정중 T에 해당하는 Transform에 해당하는 과정을 수행해야 하는데 apache제단의 pyspark 를 이용하여 데이터를 정제해보려고 한다.
5.Template 변수 활용 및 Python 모듈경로

기존 DAG에서 PythonOperator에 전달할 함수를 dags에 작성하다 보니 코드길이가 길어지고 가독성 측면에서 좋아보이지 못했다.Airflow가 사용할 common fuction을 작성했다.AirFlow가 인식하는 파일 디렉터리들을 확인하고, common fu
6.BranchPythonOperator 활용한 방어로직
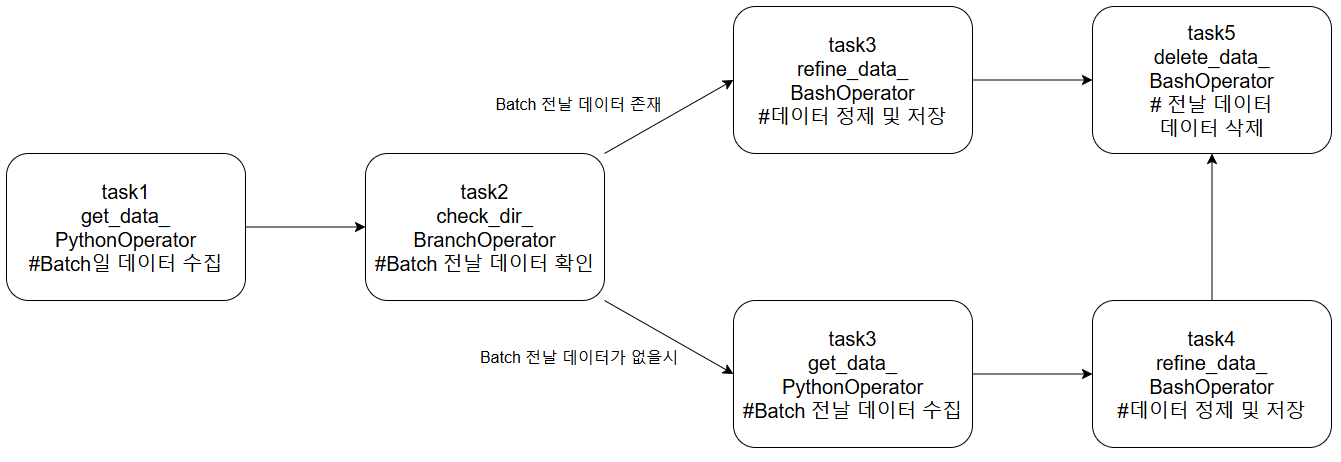
Intro 분석할 데이터를 구상하는 과정에서 어떤 비교를 위해 Batch일의 data와 Batch 전날의 데이터를 동시에 이용해야했다. > >- 일종의 방어로직으로 전날 데이터를 수집하지 못한다해도 DAG가 잘 작동하게 하고 싶었다. > > - 이를 위해 특정 조
7.데이터 모델링(개념적, 논리적 데이터 모델링)
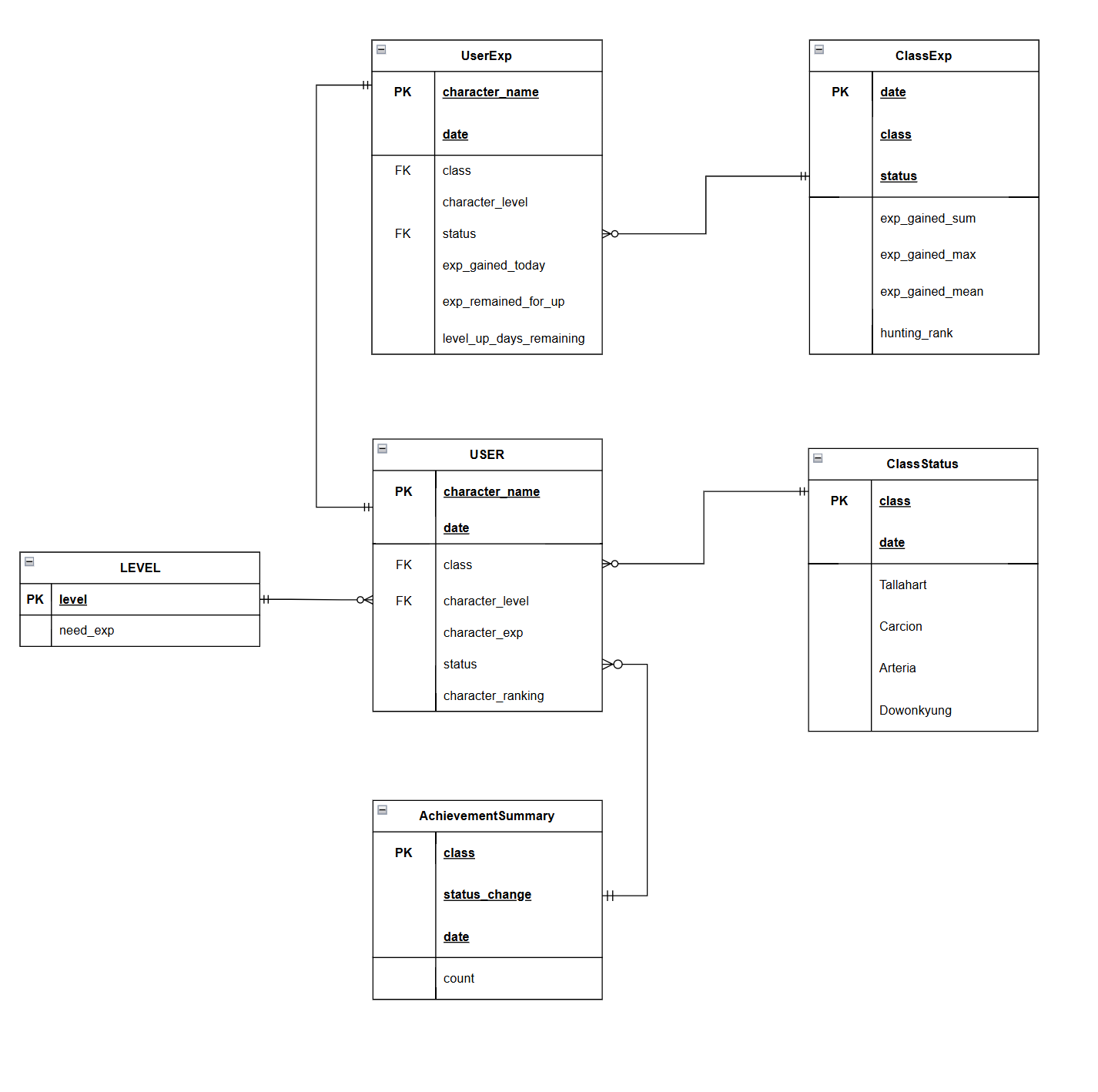
🏹 Intro 다음 두 가지 측면을 고려해서 데이터 모델을 작성했다. SparkJob을 통해 데이터베이스에 데이터를 저장하기 위한 개념적 모델링과 논리적 모델링을 진행한다. SparkJob을 통해 생성한 테이블을 mysql에 저장한후, 서비스를 위한 SQL문을 작성
8.Pyspark & DAG 최종 수정

DAG는 최종적으로 다음과 같은 flow로 작성이 됐다.API를 호출하는것에 있어서, 데이터를 잘수집하기 위해서는 적당히 sleep도 걸어야 하고, 호출량을 조절해야 했다. 그 과정에서 이미 존재하는 데이터를 또 다시 호출하는 것은 시간적인 측면 그리고 자원적인 부분에
9.ElasticSearch & MySQL 컨테이너 빌드
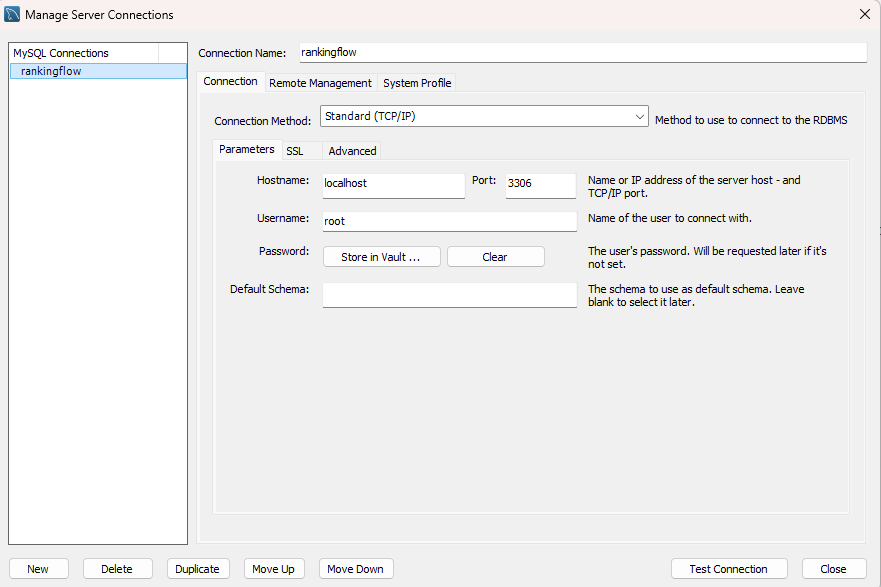
🏹 Intro MySQL의 경우 가장 흔하게 사용되는 DB이기도 했고, 내가 배웠던 SQL을 이용해서 인스턴스가 20만개 이상 쌓인 데이터베이스에서 데이터를 추출해보고 싶었다. elastic Search의 경우 dashboard를 지원해주는 kibana가 매력적으로
10.END!! and.. NEXT 😎
Airflow만 알아서는 데이터엔지니어로서의 직무를 다할 수는 없겠지만, 적어도 airflow라는 Orchestration도구는 다룰 줄 알아야 한다고 생각했다. (Airflow라는 Orchestration도구의 이름과 그것을 대표하는 바람개비 로고가 인상적이기도 해서