🏹 Intro
-
MySQL의 경우 가장 흔하게 사용되는DB이기도 했고, 내가 배웠던SQL을 이용해서 인스턴스가20만개 이상 쌓인 데이터베이스에서 데이터를 추출해보고 싶었다. -
elastic Search의 경우dashboard를 지원해주는kibana가 매력적으로 다가와 선택하게 됐다.index기반으로 데이터를 저장한다고 하는데,elastic search도 배울것이 많은 것 같다.
-
데이터가 잘 저장되기 위한 방법을 고민하고, 무엇보다
sparkdataframe을 어떻게하면 써드파티앱에 저장할 수 있겠는가가 가장 큰 관건이었다.
spark가hadoop기반이다 보니 관련된 해당 문서를 참고해야 했다. -
config를 잘 읽고, 그에 맞는option을 주어 데이터를 저장해야 한다.
참고한
spark,elasticsearch문서
https://spark.apache.org/docs/latest/configuration.html
https://www.elastic.co/guide/en/elasticsearch/hadoop/current/index.html
JDBC는 자바에서 제공하는 DB 접근을 위한 인터페이스로 드라이버라고 불리는 구현체를 사용해서 자바에서 DB에 연결할 수 있다.
참고한
Spark - JDBC문서
https://spark.apache.org/docs/latest/sql-data-sources-jdbc.html
🏹 컨테이너 빌드 & SparkDataFrame 저장하기
🎯 ElasticSearch & Kibana
- 컨테이너를 빌드하는 과정에서
depends_on의 중요성을 체감했다. elasticsearch의 경우 버전을latest로 받아올 수 없다고 한다.
그래서 해당 버전으로 하드코딩 해두었고,kibana와 버전을 맞춰주어야 한다고 한다.
es:
image: docker.elastic.co/elasticsearch/elasticsearch:8.4.3
depends_on:
- airflow-webserver
environment:
- node.name=es
- discovery.type=single-node
- discovery.seed_hosts=es
- xpack.security.enabled=false
- xpack.security.enrollment.enabled=false
- xpack.security.http.ssl.enabled=false
- xpack.security.transport.ssl.enabled=false
- cluster.routing.allocation.disk.threshold_enabled=false
- ELASTIC_PASSWORD=password
mem_limit: 1073741824
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- ./es-data:/usr/share/elasticsearch/data
ports:
- 9200:9200
kibana:
image: docker.elastic.co/kibana/kibana:8.4.3
depends_on:
- es
environment:
- SERVERNAME=kibana
- ELASTICSEARCH_HOSTS=http://es:9200
- ELASTICSEARCH_USERNAME=kibana
- ELASTICSEARCH_PASSWORD=password
ports:
- 5601:5601SparkJob을 통해 생성된 데이터프레임을elasticsearch에 저장하기 위해서는jar파일을 필요로 한다.
elasticsearch-spark-30_2.12-8.xx.jar버전을 사용해야 한다
1) 쿼리 날려보기
- 잘 빌드 되었는가 확인해본다.
$curl -X GET "localhost:9200"{
"name" : "es",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "kFHZl6JeRu-DoXDAnyfqFA",
"version" : {
"number" : "8.4.3",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "42f05b9372a9a4a470db3b52817899b99a76ee73",
"build_date" : "2022-10-04T07:17:24.662462378Z",
"build_snapshot" : false,
"lucene_version" : "9.3.0",
"minimum_wire_compatibility_version" : "7.17.0",
"minimum_index_compatibility_version" : "7.0.0"
},
"tagline" : "You Know, for Search"
}2) 저장 방식
elasticsearch는 기본적으로RDBMS와는 조금 차이가 있다.
RDBMS => 데이터베이스 => 표 => 열/행의 방식으로 저장된다고 한다면
Elasticsearch => 클러스터 => 인덱스 => 샤드 => 키-값 쌍이 있는 문서의 방식으로 저장된다고 한다.
sparkdataframe은es.resourceconfig를 이용해 저장하면 된다.
class ElasticSearch:
def __init__(self,host_name,es_port="9200",es_nodes_discovery ="false",es_nodes_wan="true",es_index_auto_create="true"):
self.host_name = host_name
self.es_port = es_port
self.es_nodes_discovery = es_nodes_discovery
self.es_nodes_wan = es_nodes_wan
self.es_index_auto_create = es_index_auto_create
def write(self,df,es_resource):
df.write \
.mode("append") \
.format("org.elasticsearch.spark.sql") \
.option("es.nodes",self.host_name) \
.option("es.port", self.es_port) \
.option("es.nodes.discovery", self.es_nodes_discovery)\
.option("es.nodes.wan.only", self.es_nodes_wan)\
.option("es.index.auto.create", self.es_index_auto_create) \
.option("es.resource", es_resource) \
.save()- 인덱스로 테이블 이름과,
저장일자를 기준으로 저장했다. - 추가적으로 모든 데이터테이블에
date가 들어가 있는데 이를kibana의timestamp로 사용하기로 했다.
# save_data to elasticSearch
save_to_elastic_search=spark_common.ElasticSearch("http://es:9200")
save_to_elastic_search.write(class_status_df,f"class_status_{batch_date}")
save_to_elastic_search.write(achievement_summary_df,f"achievement_summary_{batch_date}")
save_to_elastic_search.write(user_exp_agg_df,f"user_exp_{batch_date}")
save_to_elastic_search.write(class_exp_df,f"class_exp_{batch_date}")🎯 MySQL
MySQL컨테이너는 빌드할때 필수적으로password를 생성해야한다.
mysql:
image: mysql:8.0
depends_on:
- es
environment:
- MYSQL_PASSWORD=${MYSQL_PASSWORD}
- MYSQL_ROOT_PASSWORD=${MYSQL_ROOT_PASSWORD}
ports:
- 3306:3306
volumes:
- ./mysql-db:/var/lib/mysqlSparkDataFrame을MySQL에 저장할때도 마찬가지로jar파일을 필요로 한다.- 버전은
mysql8.0버전으로 빌드했기 때문에mysql-connector-j-8.xx.jar버전을 사용해야 한다고 한다. elasticsearch와는 조금 다른 방식으로MySQL에 저장하는데 그것이 바로jdbc라고 한다. 원리를 이해하는 것은 조금 미뤄두고 해당 방식이 있다는 것만 알아두고 환경을 설정해주었다.
1) MySQL workbench
-
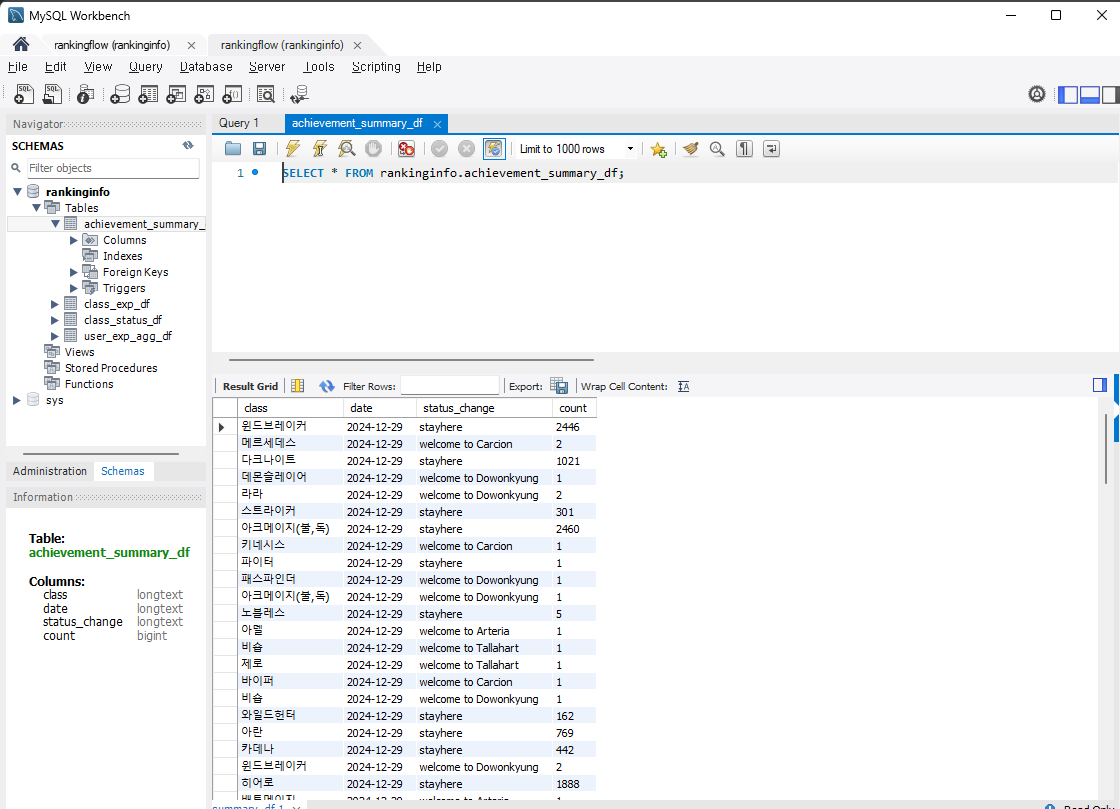
데이터가 제대로 저장되어있는지 확인하기 위해 아래의 링크에서 다운받았다.
-
다운 받은 후에는 connection 을 설정해주었다.
3306포트에 해당 컨테이너를 띄웠으므로 connection을 다음과같이 작성해주었다. -
여기서 아까 설정한 비밀번호를 입력해주면 된다.
2) 저장방식
- 필수적으로 들어가야 하는 부분이
url,user,password,driver이다.
class MySQL:
def __init__(self,url:str,user="root",password="password"):
self.url = url
self.user = user
self.password = password
def write(self,df:object,db_table_name:str):
df.write \
.mode("append")\
.format("jdbc")\
.option("driver","com.mysql.cj.jdbc.Driver")\
.option("url",self.url)\
.option("user",self.user)\
.option("password",self.password)\
.option("dbtable",db_table_name)\
.save()
url부분에 있어서docker의 기능중 하나를 이용하기로 했다.
spark submit할main스크립트에서url의ip대신에host.docker.internal를 적어주게 된다면docker내부에서 자체적으로host로 접근해주는 방식이다.
# save_data to MySQL
schema_name="rankinginfo"
save_to_mysql_db=spark_common.MySQL(url=f"jdbc:mysql://host.docker.internal:3306/{schema_name}")
save_to_mysql_db.write(class_status_df,f"class_status_df")
save_to_mysql_db.write(achievement_summary_df,f"achievement_summary_df")
save_to_mysql_db.write(user_exp_agg_df,f"user_exp_agg_df")
save_to_mysql_db.write(class_exp_df,f"class_exp_df")
🏹 Spark-submit(with jar)
elasticsearch와 MySQL 두 DB에 데이터를 저장하려하고, 각각의 다른 저장방식을함수로 정의해주었다.
이제 필요한 jar파일을 언제 제출하냐인데, SparkSession과정과 spark-submit하는 과정에서 둘다 필요하다고 한다.
🎯 main 스크립트
config에spark.jars파일로 해당jar파일을 컨테이너에서 읽을수 있는 절대경로로 작성했다.
spark = SparkSession.builder \
.master("local") \
.appName("Spark_Submit") \
.config("spark.jars","/opt/airflow/resources/elasticsearch-spark-30_2.12-8.11.1.jar,/opt/airflow/resources/mysql-connector-j-8.0.33.jar") \
.getOrCreate()🎯 shell 스크립트
shell스크립트의 경우--jars플래그를 이용하면 됐다.
#!/bin/bash
script=$@
JOBNAME="RefineData"
echo "Job name is ${JOBNAME}"
echo "submit this job >> ${script}"
echo 'start spark submit with bash operator'
spark-submit \
--name ${JOBNAME} \
--jars /opt/airflow/resources/elasticsearch-spark-30_2.12-8.11.1.jar,/opt/airflow/resources/mysql-connector-j-8.0.33.jar \
--master spark://spark-master:7077 ${script}🏹 Start Datapipline
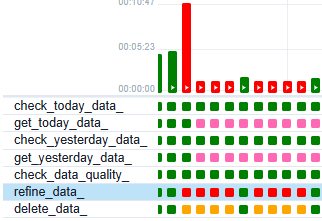
airflow로 돌아와 해당 dags 를 실행하면
처참한 흔적들..
jar파일의 버전과,es의container의환경변수설정에서 애를 먹어 실패를 자주 했으나
결국에는 잘 실행이 되는것을 확인할 수 있었다.
🎯 저장된 data 확인
1) elasticSearch
elastic search의 경우5601포트에 띄워둔 키바나를 통해 확인할 수 있었지만 적당히 쿼리를 날려도elasticsearch에 저장된 데이터를 확인해볼 수 있었다.- 간단하게
shell파일을 작성해서 해당 파일은 파이프라인에 포함되지는 않지만 직접 데이터를 확인해볼때 유용했다.
#!/bin/bash
index=$1
date=$2
echo "저장된 인덱스 목록"
curl -X GET "localhost:9200/_cat/indices?pretty"
echo
echo "${index}_${date}저장된 데이터"
curl -X GET localhost:9200/${index}_${date}/_search?pretty- 쉘파일 실행결과, 인자값 없이 실행했을때 해당데이터들이 잘 저장되어 있는것을 확인할 수 있었다.
yellow상태가 건강한 상태라고 한다.
저장된 인덱스 목록
yellow open achievement_summary_2024-12-29 Q9SqtUAbT2imRAgpzHYH-g 1 1 236 0 30kb 30kb
yellow open achievement_summary_2024-12-27 Hd8ztughToyLL9GHbLN9IQ 1 1 135 0 16.2kb 16.2kb
yellow open user_exp_2024-12-29 r08O67YwTkuFKUPXmf6-eQ 1 1 119484 0 15.5mb 15.5mb
yellow open user_exp_2024-12-27 uy78spyoSiqzMOjA6MtozA 1 1 59739 0 7.8mb 7.8mb
yellow open class_status_2024-12-29 5EtQqCWTSzqVGz6ZbBaxkQ 1 1 102 0 27.5kb 27.5kb
yellow open class_exp_2024-12-27 OWfUHgFUQeWxK90ytcMZ1w 1 1 241 0 43.7kb 43.7kb
yellow open class_exp_2024-12-29 lmueVX6hQHmCjpbz7hYNYw 1 1 482 0 87.1kb 87.1kb
yellow open class_status_2024-12-27 xi-6TfYgSDSEulumPqfKag 1 1 51 0 13.8kb 13.8kb
_저장된 데이터
{
"error" : {
"root_cause" : [
{
"type" : "invalid_index_name_exception",
"reason" : "Invalid index name [_], must not start with '_'.",
"index_uuid" : "_na_",
"index" : "_"
}
],
"type" : "invalid_index_name_exception",
"reason" : "Invalid index name [_], must not start with '_'.",
"index_uuid" : "_na_",
"index" : "_"
},
"status" : 400
}2) MySQL
MySQL역시 main 스크립트에서 지정한 스키마와, table명을 따라서 저장된것을 확인해볼 수 있었다.