🏹 Intro
DAG는 최종적으로 다음과 같은flow로 작성이 됐다.

-
API를 호출하는것에 있어서, 데이터를잘수집하기 위해서는 적당히sleep도 걸어야 하고, 호출량을 조절해야 했다.그 과정에서 이미 존재하는 데이터를 또 다시 호출하는 것은 시간적인 측면 그리고 자원적인 부분에서 효율적이지 못하여 디렉토리를 꼼꼼하게 확인하도록 task를 설계했다.
check_today_data_task는 오늘의 데이터가 디렉토리에 존재하는지 먼저 확인을 하는branch operator이다.check_yesterday_data_task는 같은 맥락으로 배치 전날의 데이터를 확인한다.check_data_quality는 중간에 누락된 데이터가 있다면 호출을 다시 하라는 메세지를 전송한다. (bad_request와 같은 데이터 누락이 존재하는 경우)
-
- 작성한 데이터모델을 참고해서
pyspark.sql을 이용한 데이터 테이블을 만들도록 한다.- 효율적인
sparkjob을 위해 다음 사항을 고려해서 작성했다.batch전날과 당일의 데이터를 수집하여join하는 연산을 필요로 한다. 해당 작업은 한번만 이루어지도록 join 하는 함수를 작성하고 리턴된 sparkdataframe 인스턴스를 재활용하는 방향으로 main 스크립트를 작성했다.spark객체를 생성하고read하는 과정에서schema를 추론하도록 했다. 이 과정에서 긴 숫자를string으로 인식을 하여longtype으로cast하도록 했다. 이는 추후에 데이터 조회 및 저장에 있어서 이점을 보일 것으로 생각이 된다.
- 효율적인
🏹 Spark-submit flow & SparkJob
🎯 Spark-submit flow
수집된 데이터를 정제하는 과정을 도식화하면 다음과 같다.
sparkjob함수의 재사용성과 보수를 중심적으로 구성했다.
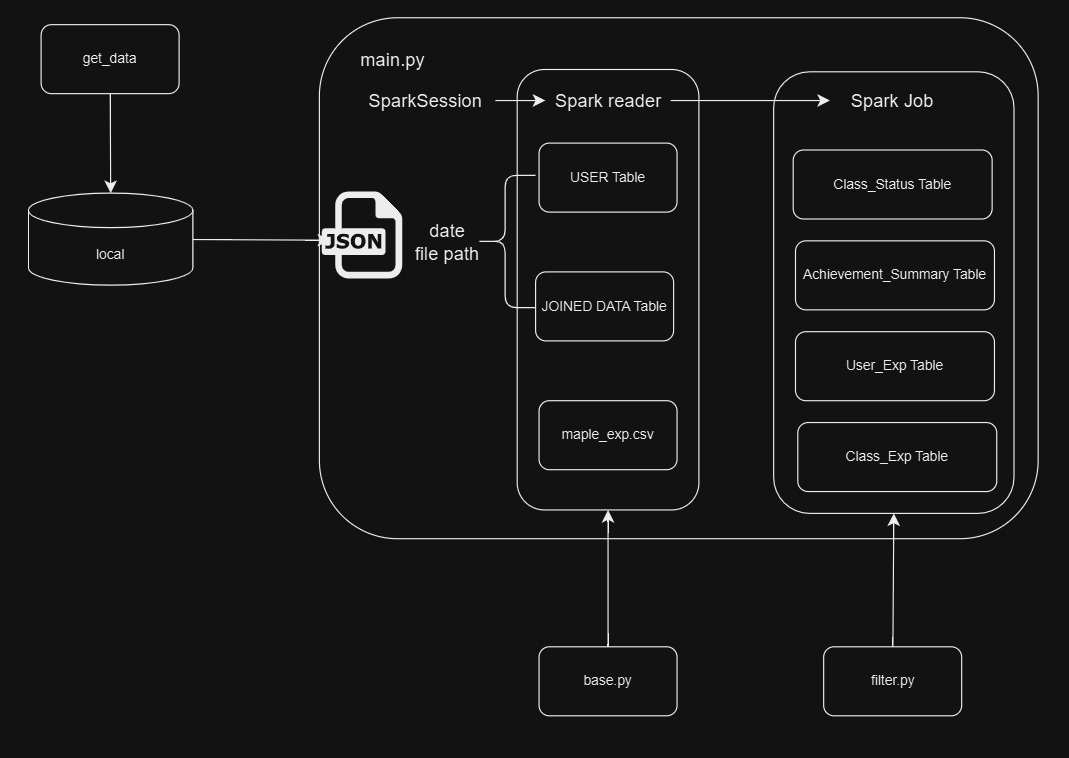
airflow worker가 데이터를 수집해오고 로컬환경에 저장된다.main.py스크립트에서Spark객체를 생성하고, 해당 객체와 데이터 정보를base.py모듈에 작성한 함수에 전달한다.base.py에 함수는spark.reader을 통해spark dataframe을 생성한다.base.py에서 리턴된dataframe은filter.py모듈에 작성한 함수에 의해 정제되고, 사전에 구성한 데이터 모델을 생성한다.
🎯 SparkJob
1) main.py 스크립트
- Spark reader가
Parsing할 데이터 정보를 설정한다.
if __name__ == "__main__":
spark = SparkSession.builder \
.master("local") \
.appName("Spark_Submit") \
.config("spark.jars","/opt/airflow/resources/elasticsearch-spark-30_2.12-8.11.1.jar,/opt/airflow/resources/mysql-connector-j-8.0.33.jar") \
.config("spark.driver.memory","2g")\
.config("spark.executor.memory","4g")\
.getOrCreate()
# batch일자의 data와 batch 전날 data를 load
UTC = datetime.now()
batch_date= UTC + timedelta(hours=9)
batch_yesterday_date=batch_date - timedelta(days=1)
batch_date= batch_date.strftime("%Y-%m-%d")
batch_yesterday_date=batch_yesterday_date.strftime("%Y-%m-%d")
batch_data_path= f"/opt/airflow/data/ranking_{batch_date}.json" # batch일 데이터 경로
batch_y_data_path= f"/opt/airflow/data/ranking_{batch_yesterday_date}.json" # batch전날 데이터 경로
exp_data_path= "/opt/airflow/data/maple_exp.csv"-
base.py에 전달한 spark 객체를 이용해서sparkdataframe으로 데이터를 읽어온다.base.py모듈의 경우@decorator를 사용하면 코드가 조금 보기 좋을것 같아 사용했다.# 생성한 sparkdataframe을 정제해주는 함수(func)에 전달하는 데코레이터 def pass_spark_dataframe(func): def wrapper(spark, file_path): spark_df = read_spark(spark, file_path) return func(spark_df) return wrapper # spark 객체를 이용하여 file_path에 존재하는 데이터를 읽어와 sparkdataframe을 생성하는 함수 def read_spark(spark:object, file_path:str)->object: if ".json" in file_path: spark_df = spark.read \ .format("json") \ .option("multiLine", True) \ .load(file_path) print(f"{file_path} data를 load 합니다.") else: schema = StructType([ StructField("row_number",IntegerType(),True), StructField("level",IntegerType(),True), StructField("need_exp",DoubleType(), True) ]) print("Level 테이블을 생성합니다.") spark_df = spark.read \ .format("csv") \ .schema(schema) \ .option("multiLine", True) \ .load(file_path) return spark_df # maple_exp를 정제하여 `LEVEL` 테이블을 생성하는 함수 @pass_spark_dataframe def make_exp_dataframe(spark_df:object)->object: spark_df = spark_df.dropna() spark_df = spark_df.select("level","need_exp") return spark_df -
base.py함수를 거쳐USER테이블을 비롯한 기본적인 셋팅을 완료한다.
# BATCH일의 USER 테이블 생성
user_batch_df=make_user_dataframe(spark,batch_data_path)
user_batch_df.show(10)
# BATCH전날의 USER 테이블 생성
user_yesterday_df=make_user_dataframe(spark,batch_y_data_path)
# Join된 Dataframe 생성성
joined_df=make_joined_dataframe(user_batch_df,user_yesterday_df)
# LEVEL 테이블 생성
level_df=make_exp_dataframe(spark,exp_data_path)
level_df.show(10)- 생성된
dataframe을filter.py에 작성된 함수로 정제한다.
# // 사용할 데이터 테이블
# [ClassStatus table]
class_status_df = RankingDataModel(user_batch_df)
class_status_df = class_status_df.agg_class_status()
class_status_df.show(10)
# [AchievementSummary table]
achievement_summary_df = RankingDataModel(joined_df)
achievement_summary_df = achievement_summary_df.agg_achive_summary()
achievement_summary_df.show(10)
# [UserExp table]
user_exp_agg_df = RankingDataModel(joined_df)
user_exp_agg_df = user_exp_agg_df.agg_user_exp(level_df)
user_exp_agg_df.show(10)
# [ClassExp table]
class_exp_df = RankingDataModel(user_exp_agg_df)
class_exp_df = class_exp_df.agg_class_exp()
class_exp_df.show(10)2) filter.py
-
spark.sql에서 제공하는 함수들을 이용했다.sql이 붙은 것으로 보아 실제SQL과 비슷한 부분이 많다고 느꼈다. 공식문서를 보면서 원하는 데이터 테이블을 만드는 것은 어렵지 않았다.join된 테이블 만들기 -
해당 데이터프레임에서 리턴된 데이터프레임 인스턴스는 계속 이용되도록 main.py 가 작성되어 있다.
-
.cast()함수는 데이터의 타입을 바꿔주는데,need_exp컬럼이stringtype으로 인식해서 바꿔주었다.
# BATCH 전날과 BATCH 일의 joined된 데이터를 이용해서 user_exp_agg 테이블을 만드는 함수
def agg_user_exp(self,exp_df)->object:
joined_df = self.df
# BATCH 전일 레벨일때 레벨업에 필요했던 경험치 컬럼을 추가
joined_df = joined_df.join(exp_df, joined_df["character_level_yesterday"] == exp_df["level"], how='inner')
joined_df = joined_df.select("*",F.col("need_exp").cast("long").alias("yesterday_need_exp")).drop("need_exp","level")
# BATCH 당일 레벨일때 레벨업에 필요했던 경험치 컬럼을 추가
joined_df = joined_df.join(exp_df, joined_df["character_level_today"] == exp_df["level"], how ='inner')
joined_df = joined_df.select("*",F.col("need_exp").cast("long").alias("today_need_exp")).drop("need_exp","level")
# BATCH 당일과 전일의 레벨이 동일한경우와 그렇지 않은경우를 고려한 획득한 경험치량(exp_gained_today) 계산
joined_df = joined_df.withColumn("exp_gained_today",
# 동일한 경우
F.when(joined_df["character_level_today"] == joined_df["character_level_yesterday"],
(joined_df["character_exp_today"]-joined_df["character_exp_yesterday"]))
# 동일하지 못한 경우
.when(joined_df["character_level_yesterday"] != joined_df["character_level_yesterday"]
,(joined_df["yesterday_need_exp"] - joined_df["character_exp_yesterday"] + joined_df["character_exp_today"])))
# 레벨업에 필요한 경험치량(exp_remained_for_up)을 계산
joined_df = joined_df.withColumn("exp_remained_for_up", joined_df["today_need_exp"] - joined_df["character_exp_today"])
# 레벨업까지 필요한 예상 일자를 계산
joined_df = joined_df.withColumn("level_up_days_remaining", F.when(joined_df["exp_gained_today"] != 0,F.round(joined_df["exp_remained_for_up"]/joined_df["exp_gained_today"]).cast("int"))
.otherwise("we need you T.T"))
# 필요한 컬럼만 선택
user_exp_agg = joined_df.select("character_name",
"date",
"class",
F.col("character_level_today").alias("character_level"),
F.col("status_today").alias("status"),
"exp_gained_today",
"exp_remained_for_up",
"level_up_days_remaining")
return user_exp_agg- 해당 함수 이외에도
Window함수도 사용할 수 있었고 ,SQL과 그 형태가 비슷했다.
🎯 Airflow log
-
Airflow로그를 보니 데이터 프레임이 잘 생성된 것을 확인할 수 있었다. -
Jupyter Notebook으로 데이터가 원하는 방향대로 정제되고 있는지 확인할 수 있어서 확실히 수월했다.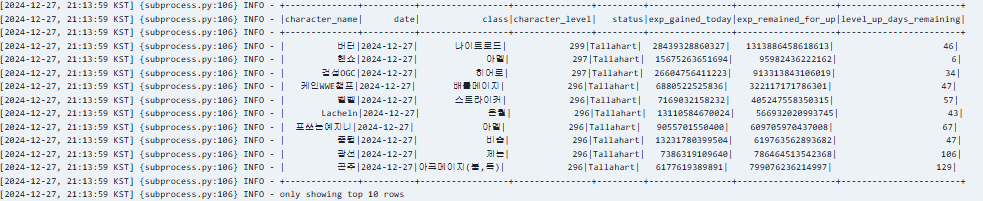
🏹 Next
- 이제 정제된 데이터를 저장할
3rd party컨테이너를 빌드해야한다. elastic Search와 이에 따라오게 되는kibana를 이용해서 데이터 시각화를 진행하고MySQL에 저장하고 필요한 데이터를 뽑고 쿼리 성능을 최적화해볼 계획이다.
