스파크 클러스터
컴퓨터 클러스터는 여러 컴퓨터의 자원을 모아 하나의 컴퓨터처럼 사용할 수 있다.
스파크는 컴퓨터 클러스터에서 작업을 조율할 수 있는 데이터 처리 프레임 워크이다.
스파크 어플리케이션은 Cluster Manager과 Driver Process 그리고 다수의 executor process로 구성된다.
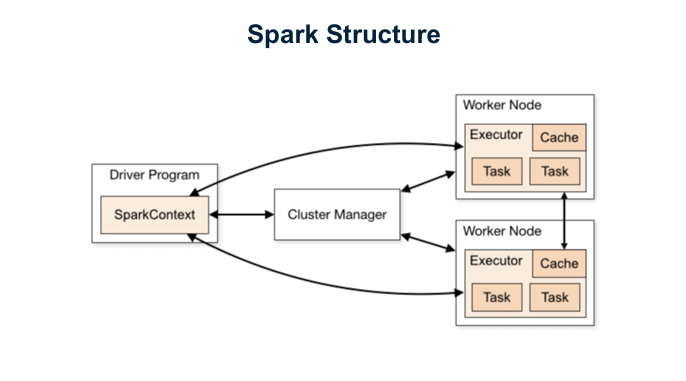
클러스터 매니저
- 스파크가 연산에 사용할 클러스터는
스파크 스탠드 얼론 클러스터 매니저,하둡 YARN,메소스 (Mesos)같은 클러스터 매니저에서 관리한다. - 사용자는 스파크 어플리케이션을 클러스트 매니저에게 제출하고 클러스터 매니저는 실행에 필요한 자원을 할당하며 작업을 처리한다.
드라이버 프로세스
- 드라이버 프로세스는 작업을 완료하기 위해 드라이버 프로그램의 명령을 익스큐터에서 실행할 책임이 있다.
- 드라이버 프로세스는 클러스터 노드중 하나에서 실행되며
main()함수를 실행한다.
이는SparkSession(SparkContext)이라 불리는 인스턴스를 생성하여 사용하게 된다.
익스큐터 프로세스
- 익스큐터 프로세스는 드라이버 프로세스가 할당한 작업을 수행한다.
즉 드라이버가 할당한 코드를 실행하고 진행 상황을 다시 드라이버 노드에 보고하는 두 가지 역할을 수행한다.스파크는 로컬모드도 지원한다.
드라이버와익스큐터는 단순한 프로세스 이므로 같은 머신이나 서로 다른 머신에서 실행할 수 있다.하지만
로컬모드로 실행하면 드라이버와 익스큐터를 단일 머신에서스레드형태로 실행한다.
스파크의 언어 API
스파크는 다양한 언어 API를 제공한다.
사용자는 코드를 실행하기 위해 SparkSession 객체를 진입점으로 사용할 수 있다.
예를들어 python을 이용하여 코드를 작성한다면, 클러스터 머신의 익스큐터의 JVM에서 작동되는 스파크 코드로 변환된다..!
SparkSession
SparkSession이라 불리는 드라이버 프로세스로 스파크 어플리케이션을 제어한다.
SparkSession 인스턴스는 사용자가 정의한 처리 명령을 클러스터에서 실행한다.
하나의 SparkSession은 하나의 스파크 애플리케이션에 대응한다.
DataFrame과 파티션
DataFrame
- DataFrame은 가장 대표적인 구조적 API 이다.
- 스키마를 이용하여 테이블의 데이터를 로우와 컬럼으로 표현한다.
파티션
스파크는 모든 익스큐터가 병렬로 작업을수행할 수 있도록 파티션이라 불리는 청크 단위로 데이터를 분할한다.
파티션은 클러스터의 물리적 머신에 존재하는 로우의 집합을 의미한다.
- 만약 파티션이 1개이고 익스큐터가 수천개 있다면 이때의 병렬성은 1이다.
- 파티션이 수백개 있고 익스큐터가 하나라면 이때도 병렬성은 1이다.
Spark-submit과정에서partition의 수를 조정할 수 있으며 기본적으로 익스큐터 한개당200개의 파티션을 처리한다.
트랜스포메이션
스파크의 핵심 데이터 구조는 기본적으로 불변성을 띄고 있다.
이러한 불변적인 데이터의 구조를 변경하기 위해서는 트랜스포메이션이라는 명령을 통해 DataFrame을 변경할 수 있다!
트랜스포메이션에는 크게 두 가지 유형이 존재한다.
좁은 트랜스포메이션: 각 입력 파티션이 하나의 출력 파티션에만 영향을 미친다.
좁은 트랜스포메이션을 사용하면 스파크에서파이프라이닝(1:1)을 자동으로 수행한다.
넓은 트랜스포메이션: 하나의 입력 파티션이 여러 출력 파티션에 영향을 미친다.
넓은 트랜스포메이션을 사용하면 파티션을 교환하는셔플(1:N)을 수행한다.
셔플의 결과는메모리에서 일어나는 연산과 조금 다른 동작 방식을 가지는데,
셔플의 결과는디스크에 저장하게 된다.
지연 연산
지연연산이란 연산 그래프를 처리하기 직전까지 기다리는 동작 방식을 의미한다.
-
스파크는 특정 연산 명령이 내려진 즉시 데이터를 수정하지 않고 원시 데이터에 적용할 트랜스포메이션의 실행계획을 생성한다.
-
스파크는 코드를 실행하는 마지막 순간까지 대기하다가 원형
DataFrame트랜스포메이션을 간결한물리적 실행 계획으로 컴파일한다.
이 과정에서 전체 데이터 흐름을 최적화하는 엄청난 강점이 있다.
액션
사용자는 트랜스포메이션을 사용해 논리적 실행 계획을 세우지만,
실제로 연산을 수행하려면 액션명령이 존재하여야 한다.
액션 명령은 크게 3가지로 나눌 수 있다.
-
콘솔에서 데이터를 보는 액션 (show, take)
-
각 언어로 된 네이티브 객체에 데이터를 모으는 액션 (collect, aggregate)
-
출력 데이터 소스에 저장하는 액션
액션을 지정하면 job이 시작되고, 좁은 트랜스포메이션을 수행한 후 파티션 별로 넓은 트랜스포 메이션을 수행한다.
그리고 각 언어에 적합한 네이티브 객체에 결과를 모은다.
예제
driver에서 실행되는SparkSession을 생성하는 것으로 시작한다.
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.master("local")\
.appName("test_spark")\
.config("spark.sql.shuffle.partitions","5")\
.getOrCreate()SparkSession의DataFrameReader클래스를 사용해서 읽을 수 있다.
df = spark.read.format("csv").option("header","true").load("/home/jovyan/data/2015-summary.csv")
df.show(10)
>>
+-----------------+-------------------+-----+
|DEST_COUNTRY_NAME|ORIGIN_COUNTRY_NAME|count|
+-----------------+-------------------+-----+
| United States| Romania| 15|
| United States| Croatia| 1|
| United States| Ireland| 344|
| Egypt| United States| 15|
| United States| India| 62|
| United States| Singapore| 1|
| United States| Grenada| 62|
| Costa Rica| United States| 588|
| Senegal| United States| 40|
| Moldova| United States| 1|
+-----------------+-------------------+-----+
only showing top 10 rows-
sort메서드는 트랜스포메이션이기 때문에 데이터에 변화를 일으키지 않는다.
하지만 실행 계획을 만들고 검토하여 클러스터에서 처리할 방법을 알아내야 한다. -
explain()메서드를 이용해 쿼리 실행 계획을 확인해볼 수 있다.
df.sort("count").explain()
>>
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- Sort [count\#873 ASC NULLS FIRST], true, 0
+- Exchange rangepartitioning(count\#873 ASC NULLS FIRST, 5), ENSURE_REQUIREMENTS, [plan_id=1316]
+- Project [DEST_COUNTRY_NAME#850, ORIGIN_COUNTRY_NAME#851, cast(count#852 as int) AS count#873]
+- FileScan csv [DEST_COUNTRY_NAME\#850,ORIGIN_COUNTRY_NAME#851,count#852] Batched: false, DataFilters: [], Format: CSV, Location: InMemoryFileIndex(1 paths)[file:/home/jovyan/data/2015-summary.csv], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<DEST_COUNTRY_NAME:string,ORIGIN_COUNTRY_NAME:string,count:string>-
사용자가 SQL이나 DataFrame으로 비즈니스 로직을 표현하면 스파크에서 실제 코드를 실행하기 전에 그 로직을 기본 실행계획으로 컴파일한다.
explain으로 확인 가능 -
스파크
SQL을사용하면 모든DataFrame을 테이블이나 뷰로 등록한 후SQL쿼리를 그대로 사용할 수 있다. -
SQL쿼리와DataFrame코드와 같은 실행계획으로 컴파일 하므로 둘 사이의 성능 차이는 없다.
1. SQL 쿼리를 사용
view생성
# SQL 을 이용하기 전 VIEW 생성
df.createOrReplaceTempView("df_view_table")SQL쿼리를 이용하여 데이터 추출
sql = spark.sql(
"""
SELECT DEST_COUNTRY_NAME, count(1)
FROM df_view_table
GROUP BY DEST_COUNTRY_NAME
"""
)
sql.explain()
>>>
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- HashAggregate(keys=[DEST_COUNTRY_NAME#461], functions=[count(1)])
+- Exchange hashpartitioning(DEST_COUNTRY_NAME#461, 5), ENSURE_REQUIREMENTS, [plan_id=712]
+- HashAggregate(keys=[DEST_COUNTRY_NAME#461], functions=[partial_count(1)])
+- FileScan csv [DEST_COUNTRY_NAME#461] Batched: false, DataFilters: [], Format: CSV, Location: InMemoryFileIndex(1 paths)[file:/home/jovyan/data/2015-summary.csv], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<DEST_COUNTRY_NAME:string>2. DataFrame SQL을 이용
- 구문도 비슷하고 물리적 실행 계획도 동일하다.
- 따라서 두 코드 사이의 성능차이는 거의 없다고 봐도 무방하다.!
# SQL 구문과 논리적 실행 계획이 동일하다
sparkSQL = df.groupBy("DEST_COUNTRY_NAME").count()
sparkSQL.explain()
>>>
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- HashAggregate(keys=[DEST_COUNTRY_NAME#461], functions=[count(1)])
+- Exchange hashpartitioning(DEST_COUNTRY_NAME#461, 5), ENSURE_REQUIREMENTS, [plan_id=725]
+- HashAggregate(keys=[DEST_COUNTRY_NAME#461], functions=[partial_count(1)])
+- FileScan csv [DEST_COUNTRY_NAME#461] Batched: false, DataFilters: [], Format: CSV, Location: InMemoryFileIndex(1 paths)[file:/home/jovyan/data/2015-summary.csv], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<DEST_COUNTRY_NAME:string>
